データ取り込み参照アーキテクチャ
このデータ取り込み参照アーキテクチャは、多様なエンタープライズソースからのデータをDatabricks Data Intelligence Platformに効率的に統一的にロードするための簡略化された基盤を提供します。
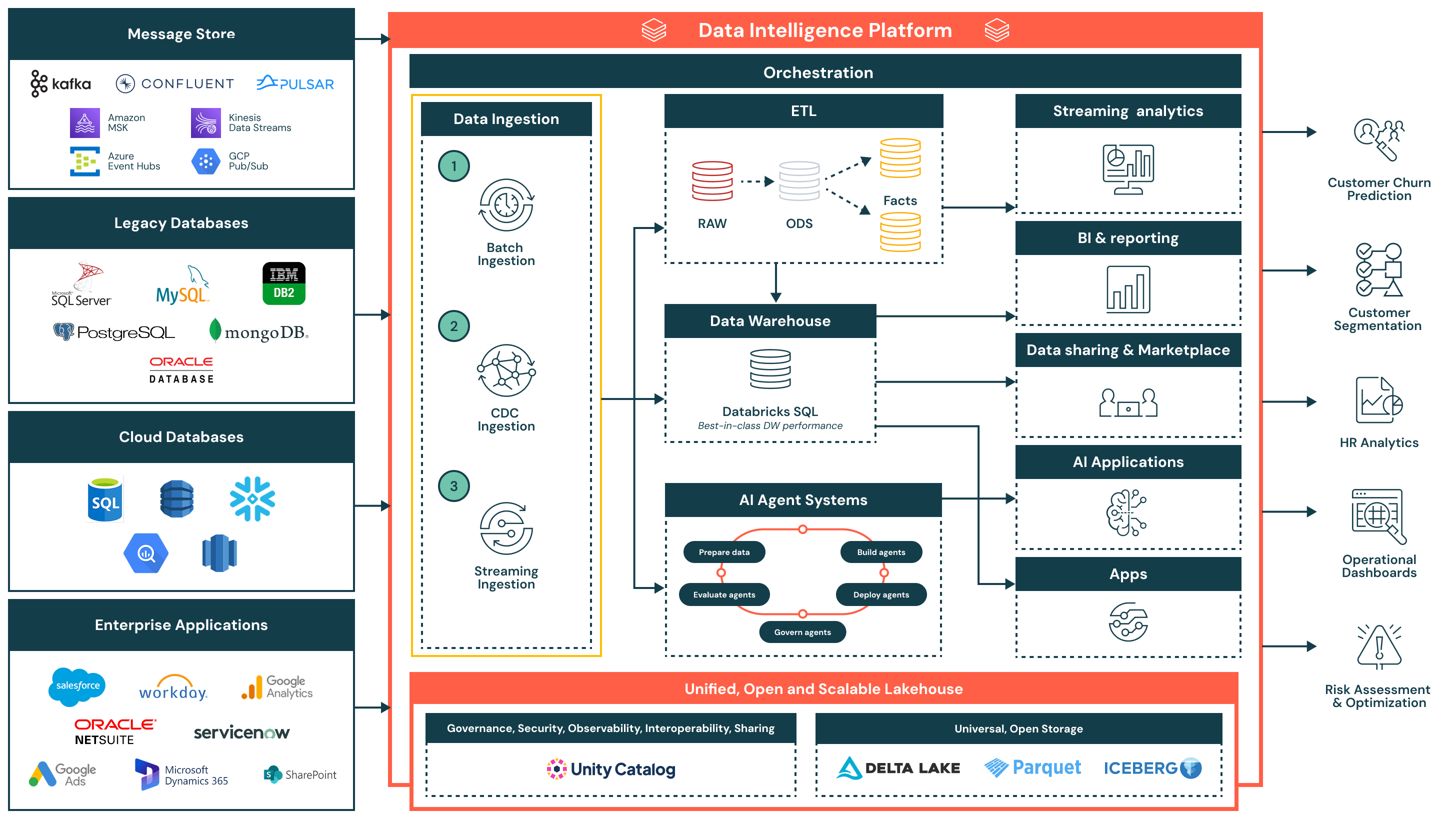
アーキテクチャの概要
データ取り込み参照アーキテクチャは、バッチ、変更データキャプチャ(CDC)、ストリーミングを含む幅広い取り込みパターンをサポートし、ガバナンス、パフォーマンス、相互運用性を確保します。一度取り込まれると、データは精製され、組織全体での分析、AI、安全なデータ共有のために利用可能になります。
このアーキテクチャは、データパイプラインを近代化し、運用化することを目指す組織にとって理想的であり、複雑さと統合のオーバーヘッドを削減します。それは以下の3つの主要な原則を中心に構築されています:
- シンプルで低メンテナンス: 取り込みパイプラインは構築・管理が容易で、価値の早期実現、運用上のボトルネックの減少、チーム間でのデータアクセスの拡大を可能にします
- レイクハウスアーキテクチャとの統一: データはオープンフォーマットを使用して直接レイクハウスに流れ込み、Unity Catalogによって管理されます - BI、AI、運用ユースケース全体での一貫性を確保します
- 効率的なエンドツーエンドのフロー: 取り込みから変換、配信まで、プラットフォームは重複、遅延、リソース使用を最小限に抑える効率的な増分処理をサポートします
ユースケース
技術ユースケース
- 定期的な バッチ取り込み フラットファイル、エクスポート、APIからのステージングゾーンへ
- 変更データキャプチャ(CDC) OracleやPostgreSQLのようなトランザクションシステムからの更新を増分的に同期するための取り込み
- ストリーミング取り込み Kafkaまたはメッセージキューからのリアルタイムイベントをライブダッシュボードやアラートシステムで使用するために
- レガシーシステム、クラウドネイティブデータベースと エンタープライズSaaSアプリケーション 間での取り込みを調整
- キュレーションされ変換されたデータを データウェアハウス、AIアプリケーション、外部APIに供給します
ビジネスユースケース
- 行動、取引、サポートデータを取り込むことによる顧客の離反予測
- ERPおよびCRMシステムからの新鮮な運用指標でエグゼクティブダッシュボードを強化
- キャンペーン、販売、製品使用データを組み合わせて顧客をセグメント化
- Workdayや生産性プラットフォームからのデータを統合してHR分析を行う
- トランザクションとアラートフィードをほぼリアルタイムで分析してリスク評価を行う
データ取り込みフローと主要な機能
- バッチ取り込み
- フラットファイル、API、データベースエクスポートなどのソースからスケジュールされた間隔またはオンデマンドでデータをロードします
- 日常のレポーティング、履歴データのロード、システムのレコードスナップショットに適しています
- SQLまたはPythonを使用したネイティブスケジューリング、リトライロジック、変換を備えた完全なロードと増分ロードの両方をサポートします
- 変更データキャプチャ(CDC)取り込み
- Oracle、PostgreSQL、MySQLなどのトランザクションシステムからの増分変更をキャプチャします
- レイクハウステーブルをフルリロードせずに更新し、効率とデータの新鮮さを向上させます
- ファクトテーブル、監査トレイル、レポーティングレイヤーのほぼリアルタイムのデータ同期を可能にします
- ストリーミング取り込み
- Kafka、Kinesis、Pub/Sub、Event Hubsなどのイベントソースからのデータを連続的に処理します
- リアルタイムダッシュボード、アラートシステム、異常検出に最適
- Structured Streamingは状態、障害耐性、スループットを管理し、運用オーバーヘッドを削減します
追加のプラットフォーム機能
- ガバナンスを統合
- Unity Catalog は統一されたガバナンスを提供し、アクセス制御、系統、監査追跡を含みます
- データは Delta Lake と Apache Iceberg™, を使用してオープンで相互運用可能な形式で保存され、ツールと環境間の柔軟性と相互運用性を確保します
- 中央集権的なオーケストレーション層がパイプラインのスケジューリング、依存関係、監視、復旧を管理します
- レイクハウスアーキテクチャ: 取り込まれたデータはメダリオンアーキテクチャ(ブロンズ、シルバー、ゴールド)に変換・モデル化され、Databricks SQLでの高性能クエリを可能にします
- オーケストレーション: 組み込みのオーケストレーションは、データパイプライン、AIワークフロー、バッチおよびストリーミングワークロードを跨るスケジュールジョブを管理し、依存関係管理とエラーハンドリングのネイティブサポートを提供します
- AIとエージェントシステム: データはエージェントシステムにフィードされ、特徴の準備、モデルの評価、AIパワードアプリケーションのデプロイメントを行います
- 下流の消費:
- ストリーミング分析: キーメトリクスと運用シグナルのリアルタイム可視化
- BI/分析: Power BI、Lakeview、SQLクライアントなどのツールに提供されるキュレーションされたデータセット
- AIアプリケーション: トレーニングパイプラインと推論エンジンによって消費される管理されたデータセット
- データ共有とマーケットプレイス: Delta Sharingを介した安全な内部および外部データ共有
- 運用アプリ: エンタープライズツールに組み込まれた知識と文脈に基づく洞察



