Apache Spark 애플리케이션에 대한 Java 가비지 수집 튜닝
본 글은 인텔의 SSG STO 빅데이터 기술 그룹에 소속된
친구들이 작성한 홍보용 포스트입니다.
Spark Summit에 참여 하여 프로덕션 환경에서 Apache Spark를
배포하는 인텔 및 기타 회사의 이야기를 들어보십시오.
Databricks20 코드를 사용하여 20% 할인을 받으세요!
Apache Spark는 뛰어난 성능, 간단한 인터페이스, 분석 및 계산을 위한
풍부한 라이브러리로 인해 업계에서 널리 채택되고 있습니다.
빅데이터 에코시스템의 많은 프로젝트와 마찬가지로
Spark는 JVM(Java Virtual Machine)에서 실행됩니다.
Spark는 메모리에 많은 양의 데이터를 저장할 수 있기 때문에
Java의 메모리 관리 및 GC(가비지 수집)에 크게 의존합니다.
Project Tungsten 과 같은 새로운 이니셔티브는 향후 Spark 버전에서
메모리 관리를 단순화하고 최적화합니다.
그러나 오늘날 Java의 GC 옵션과 parameter 이해하는 사용자는
Spark 애플리케이션의 성능을 최대한 발휘하도록 조정할 수 있습니다.
이 기사는 Spark에 대한 JVM의 가비지 수집기를 구성하는 방법을
설명하고 Spark의 성능을 향상시키기 위해 GC를 조정하는 방법을
설명하는 실제 사용 사례를 제공합니다. GC를 튜닝할 때 수집 처리량 및
대기 시간과 같은 주요 고려 사항을 살펴봅니다.
Spark 및 가비지 수집 소개
Spark가 업계에서 널리 사용됨에 따라 Spark 애플리케이션의 안정성 및 성능
튜닝 문제가 점점 더 많은 관심을 받고 있습니다. Spark의 메모리 중심
접근 방식으로 인해 100GB 이상의 메모리를 힙 공간으로 사용하는 것이
일반적이며 이는 기존 Java 애플리케이션에서는 거의 볼 수 없습니다.
Spark를 사용하는 대기업과 협력하면서 Spark 애플리케이션을
실행하는 동안 GC를 둘러싼 다양한 문제에 대해 많은 우려를 받습니다.
예를 들어, 가비지 수집은 시간이 오래 걸리므로 프로그��램이 오래 지연되거나
심각한 경우 충돌이 발생할 수 있습니다. 이 기사에서는 특정 문제와 결합된
실제 예제를 사용하여 이러한 문제를 완화할 수 있는 Spark 애플리케이션에 대한
GC 튜닝 방법에 대해 설명합니다.
Java 애플리케이션은 일반적으로 CMS(Concurrent Mark Sweep) 가비지 콜렉션 및
ParallelOld 가비지 콜렉션의 두 가지 가비지 콜렉션 전략 중 하나를 사용합니다.
전자는 더 짧은 대기 시간을 목표로 하고 후자는 더 높은 처리량을 목표로 합니다.
두 전략 모두 성능 병목 현상이 있습니다: CMS GC는 압축을 수행하지 않는 반면[1],
병렬 GC는 전체 힙 압축만 수행하므로 상당한 일시 중지 시간이 발생합니다.
인텔은 고객에게 특정 응용 프로그램의 요구 사항에 가장 적합한 전략을
선택하도록 조언합니다. 실시간 응답이 있는 애플리케이션의 경우 일반적으로
CMS GC를 권장합니다. 오프라인 분석 프로그램의 경우 병렬 GC를 사용합니다.
그렇다면 스트리밍 컴퓨팅과 기존 배치 처리를 모두 지원하는 Spark와 같은
컴퓨팅 프레임워크의 경우 최적의 수집기를 찾을 수 있을까요?
Hotspot JVM 버전 1.6에는 가비지 콜렉션을 위한 세 번째 옵션인
G1 GC(Garbage-First GC)가 도입되었습니다.
G1 수집기는 CMS GC의 장기 대체품으로 Oracle에서 계획하고 있습니다.
가장 중요한 것은 G1 수집기가 높은 처리량과 짧은 대기 시간을 모두
달성하는 것을 목표로 한다는 것입니다. Spark에서 G1 수집기를 사용하는
방법에 대해 자세히 설명하기 전에 Java GC 기본 사항에 대한
몇 가지 배경 지식을 살펴보겠습니다.
Java의 가비지 컬렉터의 작동 방식
전통적인 JVM 메모리 관리에서 ��힙 공간은 젊은 세대와 오래된 세대로 나뉩니다.
젊은 세대는 그림 1에서 볼 수 있듯이 에덴(Eden)이라는 지역과 두 개의 더 작은
생존 공간으로 구성되어 있다. 새로 생성된 오브젝트는 처음에 Eden에 할당됩니다.
마이너 GC 가 발생할 때마다 JVM은 Eden의 활성 오브젝트를 빈 생존자 공간에
복사하고 해당 빈 생존자 공간에 사용 중인 다른 생존 공간의 활성 오브젝트도 복사합니다.
이 접근 방식은 생존 공간 중 하나가 개체를 보유하는 상태로 두고 다른 하나는
다음 컬렉션을 위해 비워 둡니다. 일부 부 컬렉션에서 살아남은 개체는 이전 세대에 복사됩니다.
이전 세대가 꽉 차면 주요 GC 는 전체 GC, 즉 이전 세대의 개체를 구성하거나
제거하기 위해 모든 스레드를 일시 중단합니다. 모든 스레드가 일시 중단될 때
이러한 실행 일시 중지를 STW(Stop-The-World)라고 하며,
대부분의 GC 알고리즘에서 성능이 저하됩니다. [2]
Figure 1 세대별 핫스폿 힙 구조 [2] **
![그림 1세대별 핫스폿 힙 구조 [2] **](https://www.databricks.com/wp-content/uploads/2015/05/Screen-Shot-2015-05-26-at-11.35.50-AM-1024x302.png)
Java의 최신 G1 GC는 기존 접근 방식을 완전히 바꿉니다.
힙은 크기가 같은 힙 영역 집합으로 분할되며, 각 영역에는
가상 메모리의 연속된 범위가 있습니다(그림 2).
특정 지역 세트에는 이전 컬렉터와 동일한 역할(Eden, survivor, old)이
할당되지만 고정된 크기는 없습니다. 이렇게 하면 메모리 사용에 더 큰
유연성이 제공됩니다. 개체가 생성되면 처음에는 사용 가능한 지역에 할당됩니다.
리젼이 꽉 차면 JVM은 �오브젝트를 저장할 새 리젼을 작성합니다.
보조 GC가 발생하면 G1은 힙의 하나 이상의 영역에서 힙의 단일 영역으로
라이브 개체를 복사하고 몇 개의 사용 가능한 새 영역을 Eden 영역으로 선택합니다.
전체 GC는 모든 영역에 활성 개체가 있고 완전히 비어 있는 영역을 찾을 수 없는
경우에만 발생합니다. G1은 살아있는 객체를 표시할 때 기억된 집합(RSet) 개념을 사용합니다.
RSets는 외부 영역을 통해 지정된 영역에 대한 개체 참조를 추적합니다.
힙에는 영역당 하나의 RSet가 있습니다.
RSet은 전체 힙 검색을 방지하고 영역의 병렬 및 독립 수집을 가능하게 합니다.
이러한 맥락에서 G1 GC는 전체 GC가 트리거될 때 힙 점유율을 크게 향상시킬
뿐만 아니라 보조 GC 일시 중지 시간을 보다 제어하기 쉽게 만들어 대용량
메모리 환경에 매우 친숙하다는 것을 알 수 있습니다.
이러한 파괴적인 개선은 GC 성능을 어떻게 변화시킬까요?
여기서는 성능 변화를 관찰하는 가장 쉬운 방법,
즉 이전 GC 설정에서 G1 GC 설정으로 마이그레이션하는 방법을 사용합니다. [3]
그림 2 G1 힙 구조 그림 [3]**
![그림 2G1 힙 구조 그림 [3]**](https://www.databricks.com/wp-content/uploads/2015/05/Screen-Shot-2015-05-26-at-11.38.37-AM.png)
G1은 젊은/오래된 개체에 고정 힙 파티션을 사용하는 접근 방식을 포기하므로
G1 수집기를 사용하여 애플리케이션의 원활한 실행을 보호하기 위해 그에 따라
GC 구성 옵션을 조정해야 합니다. 이전 가비지 컬렉터와 달리 일반적으로
G1 컬렉터의 좋은 시작 점은 튜닝을 수행하지 않는 것입니다.
따라서 default 설정으로만 시작하고 옵션을 통해 -XX:+UseG1GC G1을
활성화하는 것이 좋습니다. 때때로 유용하다고 생각되는 한 가지 조정은
응용 프로그램이 여러 스레드를 사용하는 경우 크기를 조정 PLAB() 하고
많은 수의 스레드 통신으로 인한 성능 저하를 방지하는 데 사용하는
-XX: -ResizePLAB 것이 가장 좋다는 것입니다.
핫스팟 JVM에서 지원하는 GC parameter 의 전체 목록은
parameter -XX: +PrintFlagsFinal 사용하여
목록을 인쇄하거나 Oracle 공식 설명서에서 parameter일부에 대한
설명을 참조하십시오.
Spark의 메모리 관리 이해
RDD(Resilient Distributed Datasets ) 는 Spark의 핵심 추상화입니다.
RDD의 생성 및 캐싱은 메모리 소비와 밀접한 관련이 있습니다.
Spark를 사용하면 사용자가 애플리케이션에서 재사용할 수 있도록 데이터를
영구적으로 캐시할 수 있으므로 반복 컴퓨팅으로 인한 오버헤드를 방지할 수 있습니다.
RDD를 지속하는 한 가지 형태는 JVM 힙에 데이터의 전체 또는 일부를 캐시하는 것입니다.
Spark의 실행기는 JVM 힙 공간을 두 부분으로 나눕니다:
한 부분은 Spark 애플리케이션에 의해 메모리에 영구적으로
캐시된 데이터를 저장하는 데 사용됩니다.
나머지 부분은 JVM 힙 공간으로 사용되며 RDD 변환 중
메모리 소비를 담당합니다.
다음을 사용하여 이 두 분수의 비율을 조정할 수 있습니다.
spark.storage.memoryFraction parameter Spark가
RDD 힙 공간 볼륨에 이 parameter값을 곱한 값을 초과하지 않도록 하여
캐시된 RDD의 총 크기를 제어하도록 합니다.
RDD 캐시 부분의 사용되지 않은 부분도 JVM에서 사용할 수 있습니다.
따라서 Spark 애플리케이션에 대한 GC 분석은 두 메모리 비율의
메모리 사용량을 모두 다루어야 합니다.
GC 대기 시간으로 인한 효율성 저하가 관찰되면 먼저
Spark 애플리케이션이 제한된 메모리 공간을 효과적인 방식으로
사용하는지 확인해야 합니다. RDD가 차지하는 메모리 공간이 적을수록
프로그램 실행을 위한 힙 공간이 더 많이 남게 되어 GC 효율성이 높아집니다.
반대로 RDD의 과도한 메모리 소비는 이전 세대에서 많은 수의
버퍼링된 개체로 인해 상당한 성능 손실을 초래합니다.
여기서는 사용 사례를 통해 이 점을 확장합니다.
예를 들어 사용자는 간단한 반복 컴퓨팅을 수행하는 Spark의 Bagel
구성 요소를 기반으로 하는 애플리케이션을 가지고 있습니다.
한 수퍼 스텝(반복)의 결과는 이전 수퍼 스텝의 결과에 따라 달라지므로
각 수퍼 스텝의 결과는 메모리 공간에 유지됩니다.
프로그램 실행 중에 반복 횟수가 증가하면 진행에 사용되는 메모리 공간이
빠르게 증가하여 GC가 악화되는 것을 관찰했습니다.
Bagel을 자세히 살펴보았을 때, Bagel은 각 슈퍼스텝의 RDD가
한 번의 반복 후에 사용되지 않더라도 시간이 지남에 따라 해제되지 않고
메모리에 캐시된다는 것을 발견했습니다.
이로 인해 메모리 사용량이 증가하여 더 많은 GC 시도가 트리거됩니다.
SPARK-2661에서 이 불필요한 캐싱을 제거했습니다.
이 수정 캐시 후 RDD 크기는 세 번의 반복 후에 안정화되고
이제 캐시 공간이 효과적으로 제어됩니다(표 1 참조).
그 결과 GC 효율성이 크게 향상되어 프로그램의 총 실행 시간이
10%~20% 단축되었습니다.
표 1: 최적화 전후의 Bagel 애플리케이션의 RDD 캐시 크기 비교
| 반복 횟수 | 각 반복의 캐시 크기 | 총 캐시 크기(최적화 전) | 총 캐시 크기(최적화 후) |
|---|---|---|---|
| 초기화 | 4.3기가바이트 | 4.3기가바이트 | 4.3기가바이트 |
| 1개 | 8.2기가바이트 | 12.5기가바이트 | 8.2기가바이트 |
| 2 | 98.8 기가바이트 | 111.3 기가바이트 | 98.8 기가바이트 |
| 3 | 90.8 기가바이트 | 202.1 기가바이트 | 90.8 기가바이트 |
결론:
GC가 너무 자주 또는 오래 지속되는 것으로 관찰되면 Spark 프로세스 또는
애플리케이션에서 메모리 공간을 효율적으로 사용하지 않음을 나타낼 수 있습니다.
캐시된 RDD가 더 이상 필요하지 않은 후 명시적으로 정리하여 성능을 향상시킬 수 있습니다.
가비지 수집기 선택
응용 프로그램이 메모리를 최대한 효율적으로 사용하는 경우
다음 단계는 가비지 수집기 선택을 조정하는 것입니다.
SPARK-2661을 구현한 후 4노드 clusters설정하고,
각 실행기에 88GB 힙을 할당하고, 독립 실행형 모드에서
Spark를 시작하여 Experiment수행합니다.
default Spark 병렬 GC로 시작했는데, Spark 애플리케이션의
메모리 오버헤드가 상대적으로 크고 대부분의 개체를 비교적 짧은
수명 주기 내에 회수할 수 없기 때문에 병렬 GC가 전체 GC에
갇히는 경우가 많아 발생할 때마다 성능이 저하된다는 것을 발견했습니다.
설상가상으로 병렬 GC는 성능 튜닝을 위한 매우 제한된 옵션을 제공하므로
각 세대의 크기 비율 및 개체가 이전 세대로 승격되기 전의 복사본 수와 같은
몇 가지 기본 parameter 만 사용하여 성능을 조정할 수 있습니다.
이러한 튜닝 전략은 전체 GC만 연기하기 때문에 병렬 GC 튜닝은 장기 실행
애플리케이션에 거의 도움이 되지 않습니다.
따라서 이 기사에서는 병렬 GC 튜닝을 진행하지 않습니다.
표 2는 병렬 GC의 운영을 보여주며, 전체 GC가 실행될 때
가장 낮은 CPU 사용률이 발생합니다.
표 2: 병렬 GC 실행 상태(튜닝 전)
| 구성 옵션 | -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -Xms88g -Xmx88g |
| 무대* | 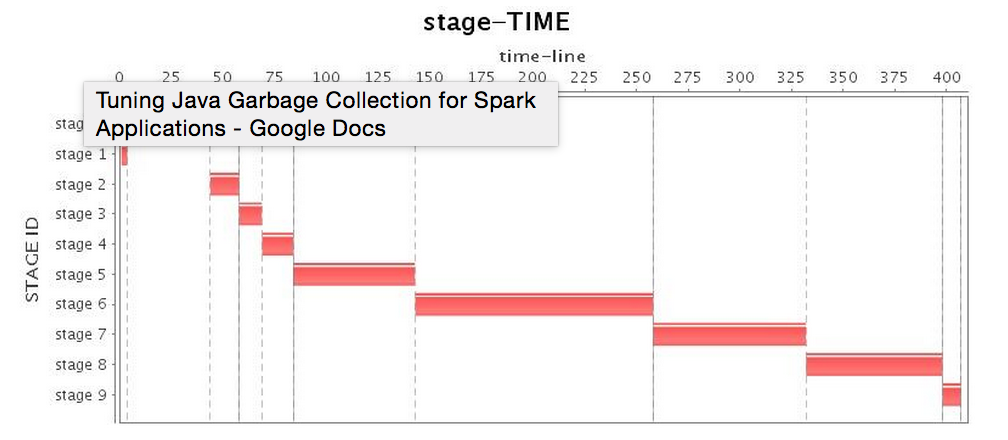 |
| 과업* | 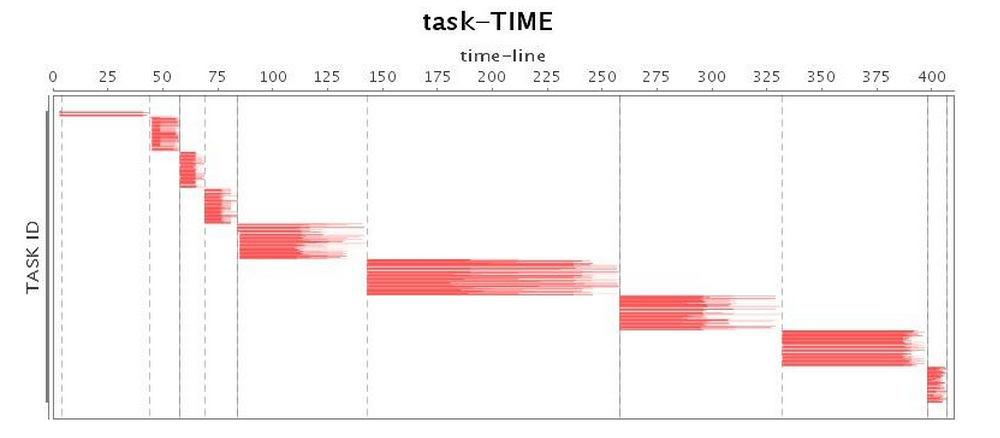 |
| CPU* (중부 표준시) | 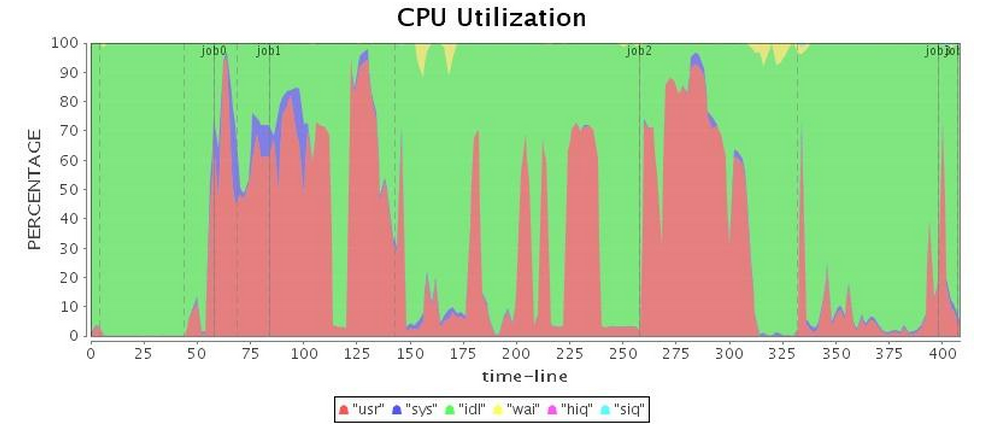 |
| 메모리* | 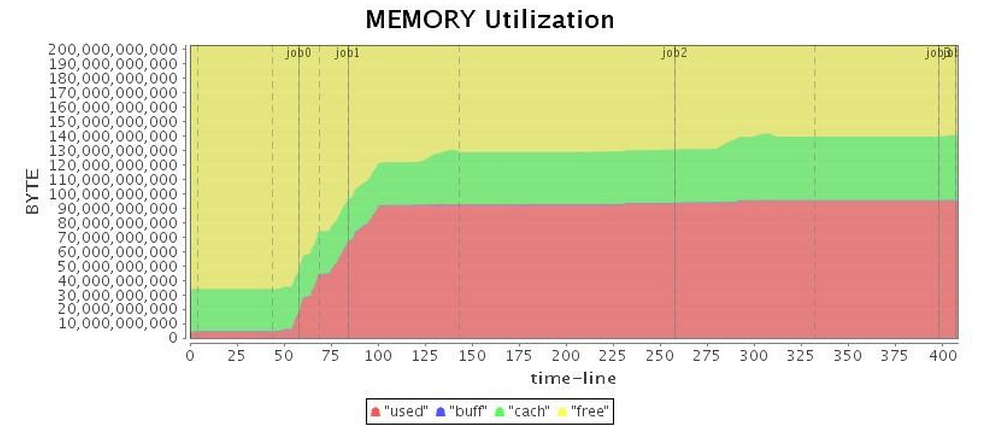 |
CMS GC는 이 Spark 애플리케이션에서 전체 GC를 제거하기 위해 아무 작업도
수행할 수 없습니다. 또한 CMS GC는 병렬 GC보다 전체 GC 일시 중지 시간이
훨씬 길기 때문에 애플리케이션의 처리량이 크게 줄어듭니다.
다음으로, G1 GC 구성 default 사용하여 애플리케이션을 실행했습니다.
놀랍게도 G1 GC는 용납할 수 없는 전체 GC를 제공했으며
(표 3의 "CPU 사용률" 참조, 작업 3은 거의 100초 동안 일시 중지됨)
긴 일시 중지 시간으로 인해 전체 애플리케이션 운영이 크게 지연되었습니다.
표 4에서 볼 수 있듯이 총 실행 시간은 Parallel GC보다 약간 더 길지만
G1 GC의 성능은 CMS GC보다 약간 우수했습니다.
표 3: G1 GC 실행 상태(튜닝 전)
| 구성 옵션 | -XX:+UseG1GC -XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -Xms88g -Xmx88g |
| 무대* | 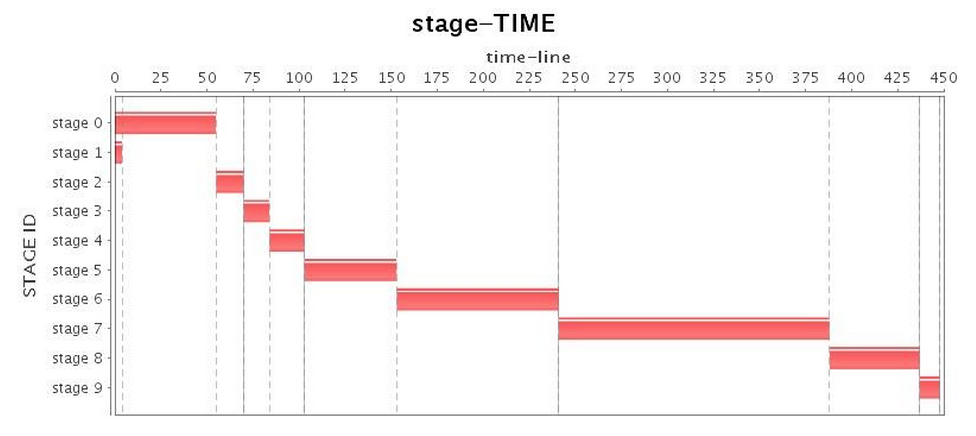 |
| 과업* | 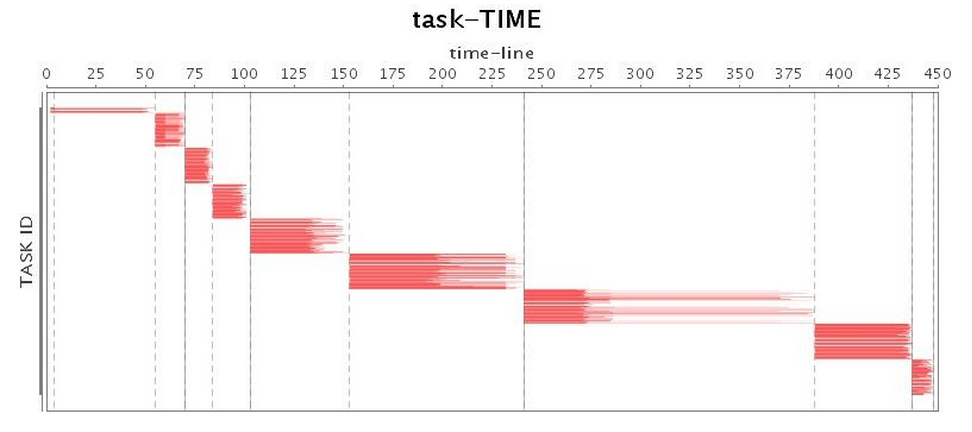 |
| CPU* (중부 표준시) | 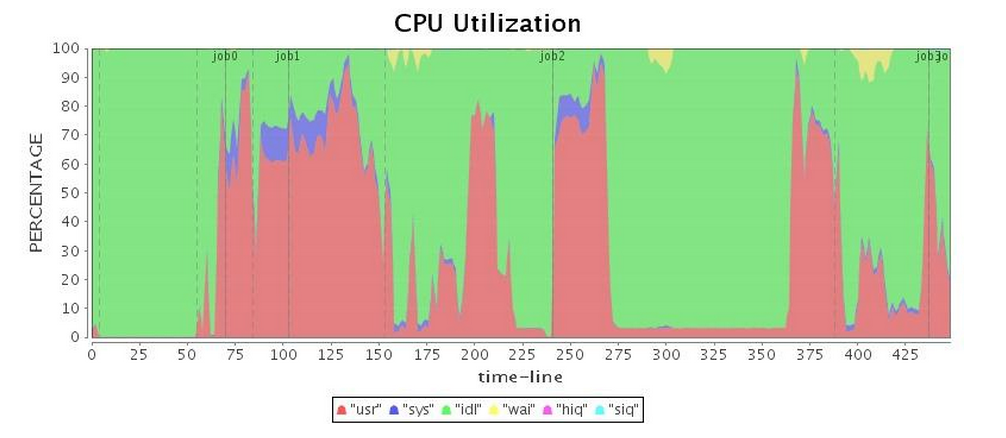 |
| 메모리* | 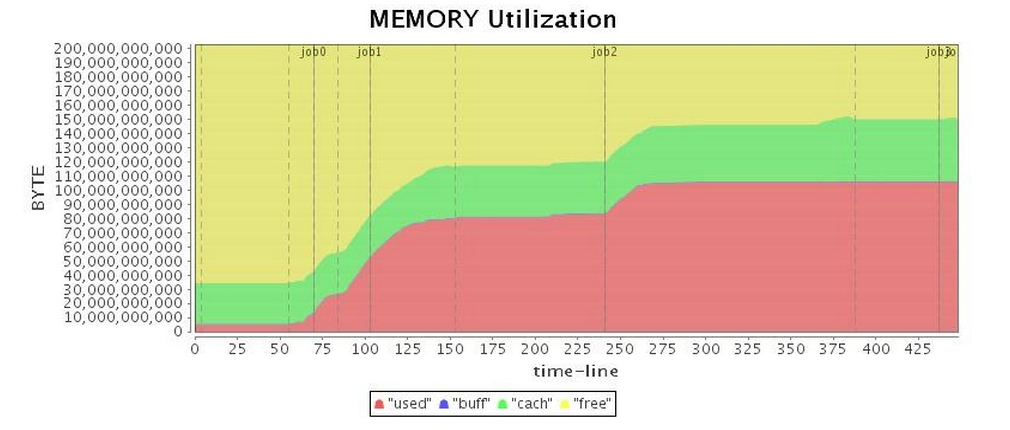 |
표 4 세 가비지 수집기의 프로그램 실행 시간 비교(튜닝 전 88GB 힙)
| 가비지 컬렉터 | 88GB 힙의 실행 시간 |
|---|---|
| 병렬 GC | 6.5분 |
| CMS GC | 9분 |
| G1 GC | 7.6분 |
로그 기반 G1 컬렉터 튜닝[4][5]
G1 GC를 설정한 후 다음 단계는 GC 로그를 기반으로 수집기 성능을 추가로 조정하는 것입니다.
우선, JVM이 GC 로그에 더 자세한 내용을 기록하기를 원합니다. 따라서 Spark의 경우
"spark.executor.extraJavaOptions"를 설정합니다. 추가 플래그를 포함합니다.
일반적으로 다음과 같은 옵션을 설정해야 합니다.
-XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark
이러한 옵션을 정의하면 Spark의 실행기 로그(각 작업자 노드에서 출력)에서 자세한 GC 로그 및
유효 GC 옵션을 추적합니다 $SPARK_HOME/work/$ app_id/$executor_id/stdout .
다음으로 GC 로그에 따라 문제의 근본 원인을 분석하고 프로그램 성능을
향상시키는 방법을 배울 수 있습니다. 예를 들어 G1 GC에서 혼합 GC를
사용하는 G1 GC 로그의 구조를 다음과 같이 살펴보겠습니다.
이 로그에서 G1 GC 로그의 계층 구조가 매우 명확하다는 것을 알 수 있습니다.
로그에는 일시 중지가 발생하는 시기와 이유가 나열되고 다양한 스레드의 시간 소비와
평균 및 최대 CPU 시간의 등급이 매겨집니다.
마지막으로 G1 GC는 이 일시 중지 후의 정리 결과와 총 시간 소비를 나열합니다.
현재 G1 GC 실행 로그에서 다음과 같은 특수 블록을 찾을 수 있습니다.
보시다시피 가장 큰 성능 저하는 이러한 전체 GC로 인해 발생했으며 To-space Exhausted,
To-space Overflow 또는 이와 유사한 로그로 로그에 출력되었습니다.
(다양한 JVM 버전의 경우 출력이 약간 다르게 보일 수 있음)
원인은 G1 GC 수집기가 특정 지역에 대한 가비지를 수집하려고 할 때 활성 개체를
복사할 수 있는 사용 가능한 영역을 찾지 못하기 때문입니다.
이러한 상황을 Evacuation Failure(대피 실패)라고 하며
전체 GC로 이어지는 경우가 많습니다.
그리고 분명히 G1 GC의 전체 GC는 병렬 GC보다 훨씬 더 나쁘기 때문에
더 나은 성능을 얻으려면 전체 GC를 피해야 합니다.
G1 GC에서 전체 GC를 방지하기 ��위해 일반적으로 사용되는 두 가지 접근 방식이 있습니다.
옵션값(default 값은 45)을 줄여 InitiatingHeapOccupancyPercent G1 GC가
더 이른 시간에 초기 동시 표시를 시작하도록 하여 전체 GC를 방지할 가능성이 더 높습니다.- 동시 마킹을 위한 더 많은 스레드를 갖도록 옵션의 값을 늘리
ConcGCThreads면
동시 마킹 단계의 속도를 높일 수 있습니다. 이 옵션은 워크로드 CPU 사용률에 따라
일부 효과적인 작업자 스레드 리소스를 차지할 수도 있습니다.
이 두 옵션을 조정하면 전체 GC가 발생할 가능성을 최소화할 수 있습니다.
전체 GC가 제거된 후 성능이 크게 향상되었습니다.
그러나 GC 중에 여전히 긴 일시 중지가 발견되었습니다.
추가 조사 결과 로그에서 다음과 같은 문제가 발견되었습니다.
여기서 우리는 거대한 물체 (표준 영역의 50 % 이상의 물체 )를 볼 수 있습니다.
G1 GC는 이러한 각 개체를 인접한 영역 집합에 배치합니다.
그리고 이러한 개체를 복사하는 것은 많은 리소스를 소비하기 때문에 거대한
개체는 이전 세대에서 직접 할당되고(모든 젊은 GCS우회) 거대한 영역으로
분류됩니다[4]. 1.8.0_u40하기 전에 거대한 영역을 회수하기 위해 완전한
힙 활동성 분석이 필요합니다[JDK-8027959].
이런 종류의 오브젝트가 많으면 힙이 매우 빨리 채워지고
이를 회수하는데 비용이 너무 많이 듭니다.
수정 사항에도 불구하고(거대한 개체를 회수하는 효율성을 크게 증가시킴)
연속 영역을 할당하는 것은 여��전히 더 비싸므로(특히 심각한 힙 조각화를 충족할 때)
이 크기의 개체를 만들지 않으려고 합니다.
거대한 영역을 만들 가능성을 줄이기 위해 값을 G1HeapRegionSize
늘릴 수 있지만 비교적 큰 힙을 사용하는 경우 default 값은 이미
최대 크기인 32M에 있습니다.
즉, 이러한 개체를 찾고 생성을 최소화하기 위해서만 프로그램을
분석할 수 있습니다. 그렇지 않으면 더 많은 동시 마킹 단계로 이어질 수 있으며,
그 후에는 믹스 GC 관련 노브
예 -XX:G1HeapWastePercent -XX:G1MixedGCLiveThresholdPercent: )를
신중하게 조정하여 긴 믹스 GC 일시 중지(많은 거대한 물체로 인해 발생)를 방지해야 합니다.
다음으로, 주기 시작부터 혼합 GC가 끝날 때까지의
단일 GC 주기 간격을 분석할 수 있습니다.
시간이 너무 길면 의 값을 ConcGCThreads늘리는 것을 고려할 수 있지만
이렇게 하면 CPU 리소스가 더 많이 사용됩니다.
G1 GC에는 가비지 수집의 동시 단계에서 더 많은 작업을
수행하는 대가로 STW 일시 중지 길이를 줄이는 방법도 있습니다.
위에서 언급했듯이 G1 GC는 각 영역에 대한 기억된 집합(RSet)을
유지 관리하여 외부 영역별로 지정된 영역에 대한 개체 참조를 추적하고,
G1 수집기는 STW 단계와 동시 단계 모두에서 RSet를 업데이트합니다.
G1 GC를 사용하여 STW 일시정지 길이를 줄이려는 경우 의 값을
G1RSetUpdatingPauseTimePercent 줄이면서 의 값을
G1ConcRefinementThreads늘릴 수 있습니다.
이 옵션은 G1RSetUpdatingPauseTimePercent
총 STW 시간에서 RSet 갱신 시간의 원하는 비율(10% x default)을
지정하는 데 사용되며, G1ConcRefinementThreads ��프로그램 실행 중에
RSet를 유지 관리하기 위한 스레드 수를 정의하는 데 사용됩니다.
이 두 가지 옵션을 조정하면 RSet 업데이트의 더 많은 워크로드를
STW 스테이지에서 동시 스테이지로 이동할 수 있습니다.
또한 장기 실행 응용 프로그램의 경우 이 옵션을 사용
AlwaysPreTouch 하므로 JVM은 시작 시 OS에 필요한
모든 메모리를 적용하고 동적 응용 프로그램을 방지합니다.
이렇게 하면 시작 시간이 연장되는 대신 런타임 성능이 향상됩니다.
결국, GC parameter 튜닝을 여러 차례 거친 후 표 5의 결과에 도달했습니다.
이전 결과와 비교했을 때, 우리는 마침내 더 만족스러운 실행 효율성을 얻었습니다.
표 5 G1 GC 실행 상태(튜닝 후)
| 구성 옵션 | -XX:+UseG1GC -XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions -XX:+G1요약 표시 -Xms88g -Xmx88g -XX:InitiatingHeapOccupancyPercent=35 -XX:ConcGCThread=20 |
| 무대* | 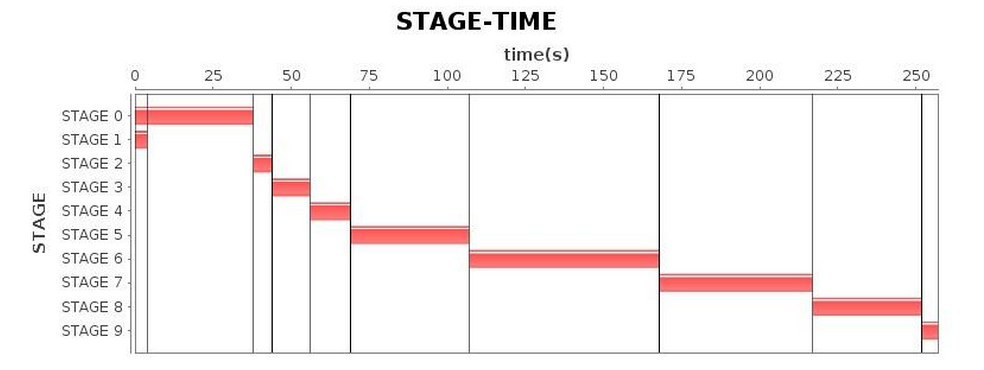 |
| 과업* | 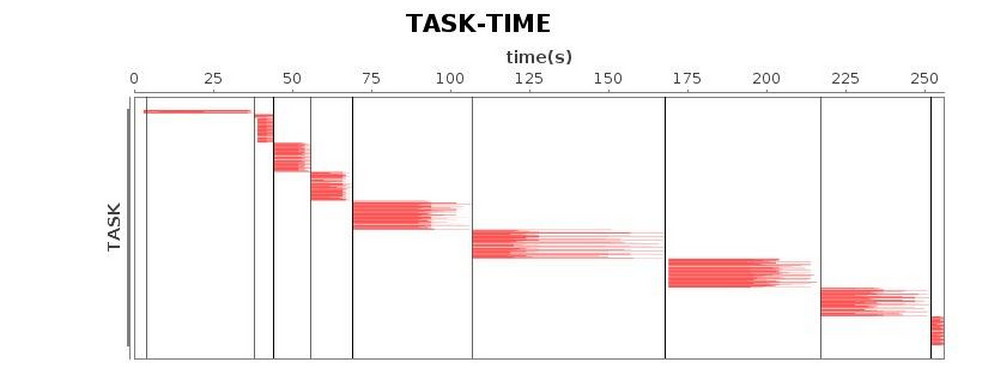 |
| CPU* (중부 표준시) | 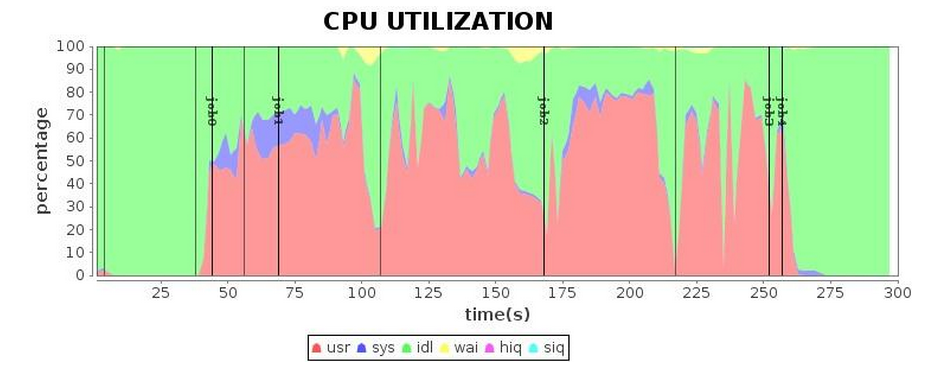 |
| 메모리* | 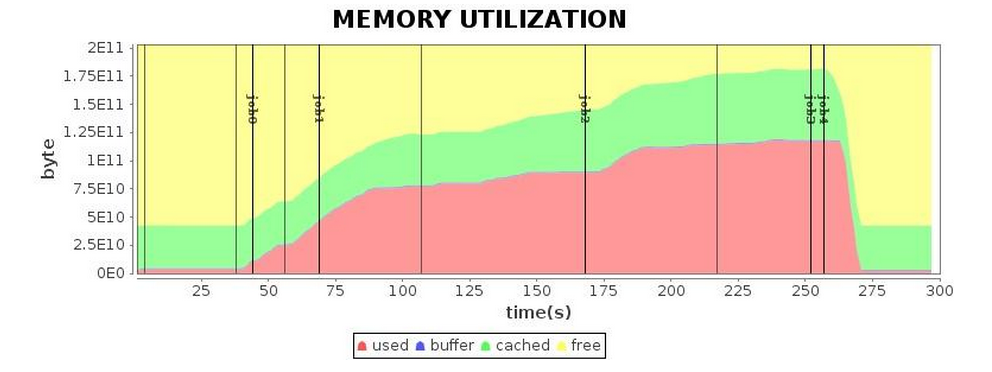 |
결론:
Spark 애플리케이션에 대한 대안과 비교하여 G1 GC를 시도하는 것이 좋습니다.
GC 로그 분석을 통해 보다 세분화된 최적화를 얻을 수 있습니다.
튜닝 후 애플리케이션 실행 시간을 4.3분으로 단축하는 데 성공했습니다.
튜닝 전 실행 시간과 비교하여 1.7배의 성능 향상을 달성했습니다.
병렬 GC와 비교하면 1.5배 정도 증가한 수치입니다.
요약
메모리 컴퓨팅에 크게 의존하는 Spark 애플리케이션의 경우 GC 튜닝이 특히 중요합니다.
GC에 문제가 발생하면 GC 자체를 디버깅하기 위해 서두르지 마십시오.
먼저 캐시에서 RDD를 유지하고 해제하는 것과 같은 Spark 프로그램의
메모리 관리의 비효율성을 고려합니다. 가비지 수집기를 튜닝할 때는 먼저
G1 GC를 사용하여 Spark 애플리케이션을 실행하는 것이 좋습니다.
G1 수집기는 Spark에서 자주 볼 수 있는 증가하는 힙 크기를
처리할 준비가 되어 있습니다. G1을 사용하면 더 높은 처리량과
더 짧은 대기 시간을 제공하기 위해 더 적은 옵션이 필요합니다.
물론 GC 튜닝에 대한 고정된 패턴은 없습니다.
다양한 응용 프로그램은 서로 다른 특성을 가지고 있으며
예측할 수 없는 상황을 해결하려면 로그 및 기타 포렌식에 따라
GC 튜닝 기술을 마스터해야 합니다.
마지막으로, 중간 객체 생성 또는 복제 감소,
대형 객체 생성 제어, 수명이 긴 객체를 오프 힙에 저장하는 등
프로그램의 논리와 코드를 통한 최적화를 잊을 수 없습니다.
G1 GC를 사용함으로써 Spark 애플리케이션의 성능이 크게 향상되었습니다.
Spark의 향후 작업은 메모리 관리 책임을 Java의 가비지 수집기에서
Spark 자체로 옮길 것입니다. 이렇게 하면 Spark 애플리케이션에 대한
튜닝 요구 사항이 대부분 완화됩니다. 그럼에도 불구하고 오늘날 가비지 수집기를
선택하면 중요 업무용 Spark 애플리케이션의 성능을 향상시킬 수 있습니다.
승인
튜닝을 연습하고 이 기사를 작성하는 동안 Intel Java Runtime 팀의 선임 엔지니어인
Ms. Yanping Wang의 지침과 지원을 받았습니다.
* 인텔 빅데이터 팀이 개발한 내부 성능 분석 도구를 사용하여 생성된 그래프를 나타냅니다.
** Oracle 설명서의 이미지를 나타냅니다. 자세한 내용은 참조 [2] [3]을 참조하십시오.
참조
- https://docs.oracle.com/cd/E13150_01/jrockit_jvm/jrockit/geninfo/diagnos/garbage_collect.html#wp1086917
- https://www.oracle.com/webfolder/technetwork/tutorials/obe/java/gc01/index.html
- https://www.oracle.com/webfolder/technetwork/tutorials/obe/java/G1GettingStarted/index.html
- https://www.infoq.com/articles/tuning-tips-G1-GC/
- https://blogs.oracle.com/
저자 소개:
Daoyuan Wang, SSG STO, 빅데이터 기술, Intel Asia-Pacific Research & Development Ltd.의 소프트웨어 엔지니어, Apache 커뮤니티에서 활발한 Spark 기여자이기도 합니다.
Jie Huang, SSG STO 빅데이터 테크놀로지 엔지니어링 매니저,
인텔 아시아 태평양 리서치 & 개발
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.