Spark SQL에서의 윈도우 함수 소개
작성자: Yin Huai , Michael Armbrust
O'Reilly의 새로운 전자책 미리 보기에서 Delta Lake 사용법을 단계별로 안내해 드립니다.
이 블로그 게시물에서는 Apache Spark에 추가된 새로운 윈도우 함수 기능에 대해 소개합니다. 윈도우 함수를 사용하면 Spark SQL 사용자가 특정 행의 순위나 입력 행 범위에 대한 이동 평균과 같은 결과를 계산할 수 있습니다. 이는 Spark SQL 및 DataFrame API의 표현력을 크게 향상시킵니다. 이 블로그에서는 먼저 윈도우 함수의 개념을 소개한 다음 Spark SQL 및 Spark DataFrame API에서 윈도우 함수를 사용하는 방법을 설명합니다.
윈도우 함수란 무엇인가요?
1.4 이전에는 Spark SQL에서 단일 반환 값을 계산하는 데 사용할 수 있는 두 가지 종류의 함수가 지원되었습니다. 내장 함수 또는 UDF는 substr 또는 round와 같이 단일 행의 값을 입력으로 받아 각 입력 행에 대해 단일 반환 값을 생성합니다. 집계 함수는 SUM 또는 MAX와 같이 여러 행에 대해 작동하고 각 그룹에 대해 단일 반환 값을 계산합니다.
이 두 가지 모두 실제 사용에 매우 유용하지만, 이러한 유형의 함수만으로는 표현할 수 없는 광범위한 작업이 여전히 존재합니다. 특히, 여러 행에 대해 작동하면서도 각 입력 행에 대해 단일 값을 반환하는 방법이 없었습니다. 이러한 제한으로 인해 이동 평균 계산, 누적 합계 계산 또는 현재 행 이전의 행 값 액세스와 같은 다양한 데이터 처리 작업을 수행하기 어렵습니다. 다행히 Spark SQL 사용자를 위해 윈도우 함수가 이 간극을 메웁니다.
핵심적으로 윈도우 함수는 프레임이라고 하는 행 그룹을 기반으로 테이블의 각 입력 행에 대한 반환 값을 계산합니다. 각 입력 행에는 고유한 프레임이 연결될 수 있습니다. 윈도우 함수의 이러한 특성은 다른 함수보다 더 강력하게 만들고 사용자가 윈도우 함수 없이는 표현하기 어렵거나 불가능한 다양한 데이터 처리 작업을 간결하게 표현할 수 있도록 합니다. 이제 두 가지 예시를 살펴보겠습니다.
아래와 같이 productRevenue 테이블이 있다고 가정해 보겠습니다.
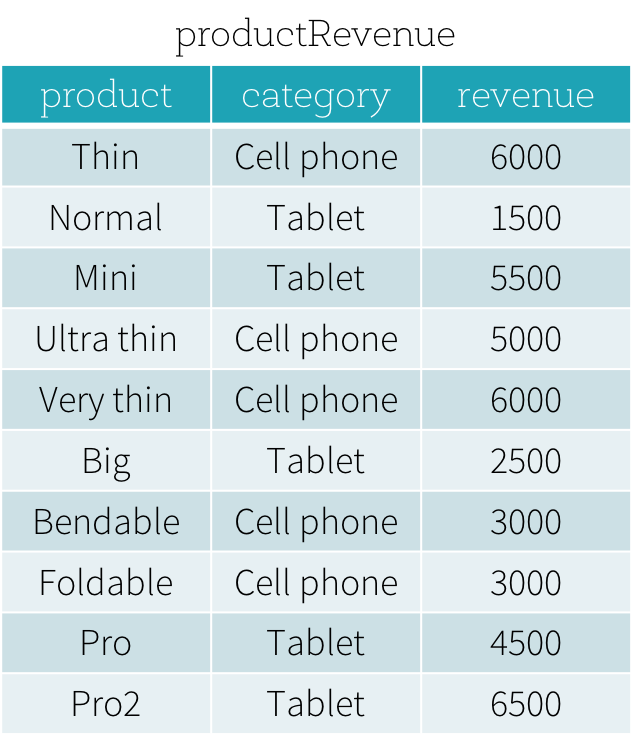
두 가지 질문에 답하고 싶습니다.
- 각 카테고리에서 가장 많이 팔린 제품과 두 번째로 많이 팔린 제품은 무엇인가요?
- 각 제품의 매출과 해당 제품과 동일한 카테고리에 있는 가장 많이 팔린 제품의 매출 간의 차이는 얼마인가요?
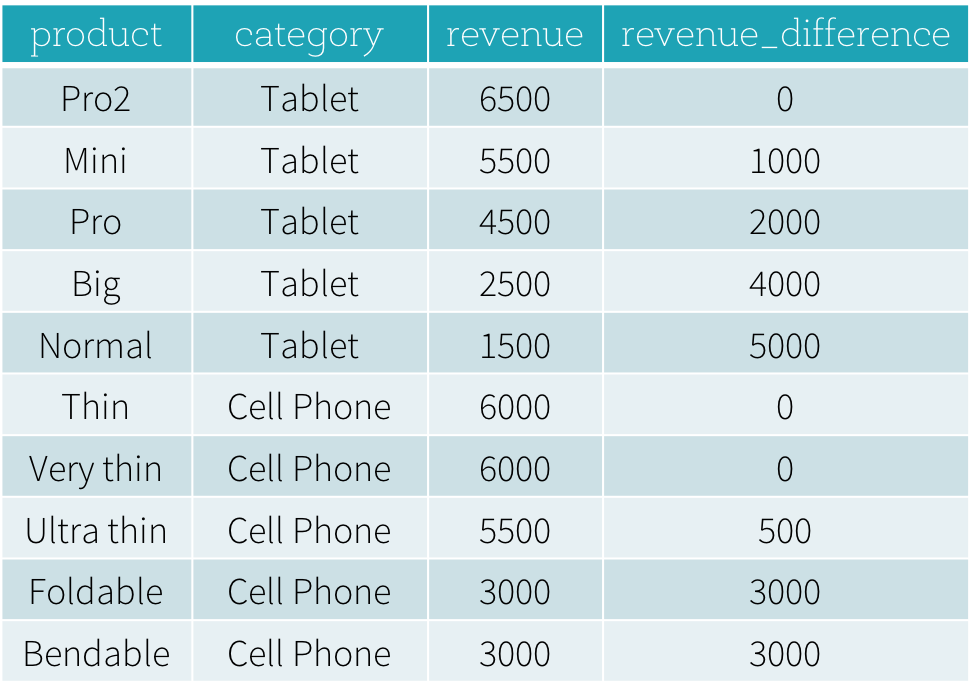
첫 번째 질문인 “각 카테고리에서 가장 많이 팔린 제품과 두 번째로 많이 팔린 제품은 무엇인가요?”에 답하기 위해 매출을 기준으로 카테고리별 제품 순위를 매기고 순위에 따라 가장 많이 팔린 제품과 두 번째로 많이 팔린 제품을 선택해야 합니다. 다음은 윈도우 함수 dense_rank를 사용하여 이 질문에 답하는 데 사용되는 SQL 쿼리입니다(다음 섹션에서 윈도우 함수 구문 설명).
이 프로그램의 결과는 다음과 같습니다. 윈도우 함수를 사용하지 않으면 사용자는 모든 카테고리의 최고 매출 값을 찾아야 하고, 이 파생된 데이터 세트를 원본 productRevenue 테이블과 조인하여 매출 차이를 계산해야 합니다.
윈도우 함수 사용하기
Spark SQL은 순위 함수, 분석 함수 및 집계 함수의 세 가지 종류의 윈도우 함수를 지원합니다. 사용 가능한 순위 함수 및 분석 함수는 아래 표에 요약되어 있습니다. 집계 함수의 경우 기존 집계 함수를 윈도우 함수로 사용할 수 있습니다.
| SQL | DataFrame API | |
| 순위 함수 | rank | rank |
| dense_rank | denseRank | |
| percent_rank | percentRank | |
| ntile | ntile | |
| row_number | rowNumber | |
| 분석 함수 | cume_dist | cumeDist |
| first_value | firstValue | |
| last_value | lastValue | |
| lag | lag | |
| lead | lead |
윈도우 함수를 사용하려면 사용자는 다음 중 하나를 통해 함수가 윈도우 함수로 사용됨을 표시해야 합니다.
- SQL에서 지원되는 함수 뒤에 OVER 절을 추가합니다. 예:
avg(revenue) OVER (...) - DataFrame API에서 지원되는 함수에 over 메서드를 호출합니다. 예:
rank().over(...)
함수가 윈도우 함수로 표시되면 다음 주요 단계는 이 함수와 관련된 윈도우 사양을 정의하는 것입니다. 윈도우 사양은 주어진 입력 행과 관련된 프레임에 어떤 행이 포함되는지 정의합니다. 윈도우 사양은 세 부분으로 구성됩니다.
- 파티셔닝 사양: 주어진 행과 동일한 파티션에 속할 행을 제어합니다. 또한 사용자는 파티셔닝 및 프레임 계산 전에 동일한 카테고리 열 값을 가진 모든 행이 동일한 머신으로 수집되도록 해야 합니다. 파티셔닝 사양이 제공되지 않으면 모든 데이터가 단일 머신으로 수집되어야 합니다.
- 정렬 사양: 파티션 내의 행 순서를 제어하여 파티션 내에서 주어진 행의 위치를 결정합니다.
- 프레임 사양: 현재 입력 행에 대한 프레임에 포함될 행을 현재 행과의 상대적 위치를 기준으로 지정합니다. 예를 들어, "현재 행부터 이전 세 행"은 현재 입력 행과 현재 행 이전에 나타나는 세 행을 포함하는 프레임을 설명합니다.
SQL에서는 PARTITION BY 및 ORDER BY 키워드를 사용하여 각각 파티셔닝 사양에 대한 파티셔닝 표현식과 정렬 사양에 대한 ��정렬 표현식을 지정합니다. SQL 구문은 다음과 같습니다.
OVER (PARTITION BY ... ORDER BY ...)
DataFrame API에서는 윈도우 사양을 정의하기 위한 유틸리티 함수를 제공합니다. Python을 예로 들면, 사용자는 다음과 같이 파티셔닝 표현식과 정렬 표현식을 지정할 수 있습니다.
정렬 및 파티셔닝 외에도 사용자는 프레임의 시작 경계, 프레임의 끝 경계 및 프레임 유형을 정의해야 하며, 이는 프레임 사양의 세 가지 구성 요소입니다.
경계에는 UNBOUNDED PRECEDING, UNBOUNDED FOLLOWING, CURRENT ROW, UNBOUNDED PRECEDING 및 UNBOUNDED FOLLOWING은 각각 파티션의 첫 번째 행과 마지막 행을 나타냅니다. 나머지 세 가지 경계 유형은 현재 입력 행의 위치에서 오프셋을 지정하며, 해당 특정 의미는 프레임 유형에 따라 정의됩니다. 프레임에는 ROW 프레임과 RANGE 프레임의 두 가지 유형이 있습니다.
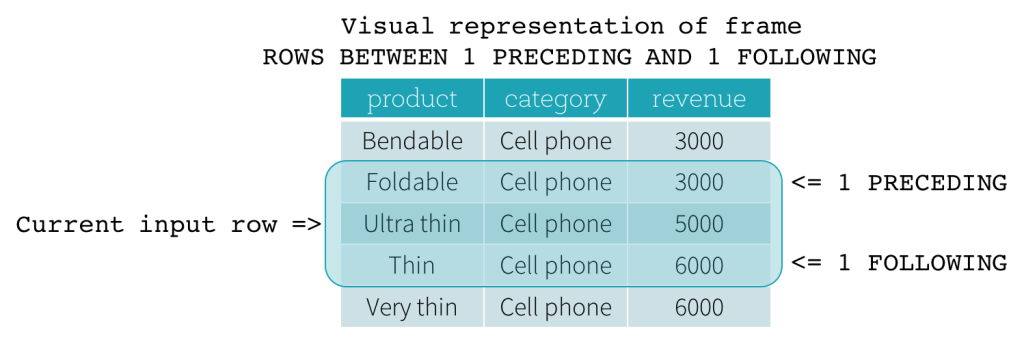
ROW 프레임
ROW 프레임은 현재 입력 행의 위치에서 물리적인 오프셋을 기반으로 하므로, CURRENT ROW, CURRENT ROW가 경계로 사용될 경우 현재 입력 행을 나타냅니다. 1 PRECEDING, 끝 경계로 1 FOLLOWING을 사용하는 ROW 프레임을 보여줍니다 (SQL 구문에서 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING).
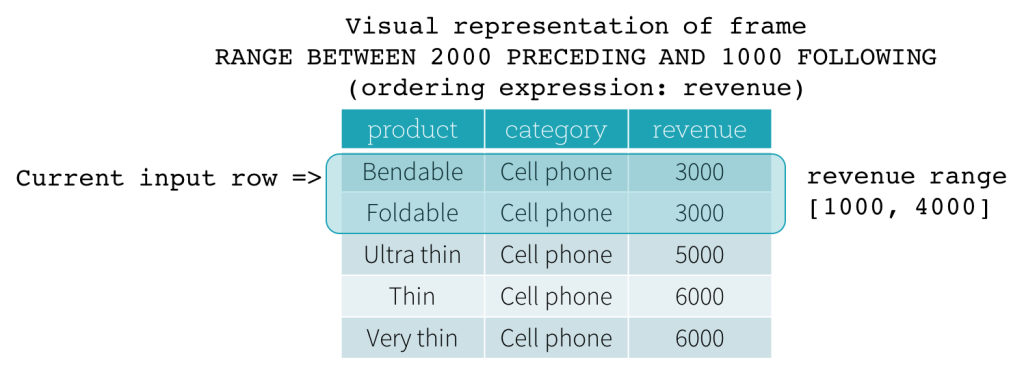
RANGE 프레임
RANGE 프레임은 현재 입력 행의 위치에서 논리적인 오프셋을 기반으로 하며 ROW 프레임과 유사한 구문을 가집니다. 논리적인 오프셋은 현재 입력 행의 정렬 표현식 값과 프레임의 경계 행의 동일한 표현식 값 간의 차이입니다. 이 정의 때문에 RANGE 프레임이 사용될 때는 단 하나의 정렬 표현식만 허용됩니다. 또한 RANGE 프레임의 경우 현재 입력 행과 동일한 정렬 표현식 값을 가진 모든 행은 경계 계산에 있어서 동일한 행으로 간주됩니다.
이제 예제를 살펴보겠습니다. 이 예제에서 정렬 표현식은 revenue이고, 시작 경계는 2000 PRECEDING이며, 끝 경계는 1000 FOLLOWING입니다 (SQL 구문에서 RANGE BETWEEN 2000 PRECEDING AND 1000 FOLLOWING으로 정의됨). 다음 다섯 개의 그림은 현재 입력 행이 업데이트됨에 따라 프레임이 어떻게 업데이트되는지 보여줍니다. 기본적으로 각 현재 입력 행에 대해 revenue 값을 기반으로 revenue 범위 [현재 revenue 값 - 2000, 현재 revenue 값 + 1000]을 계산합니다. 이 범위에 해당하는 revenue 값을 가진 모든 행이 현재 입력 행의 프레임에 포함됩니다.
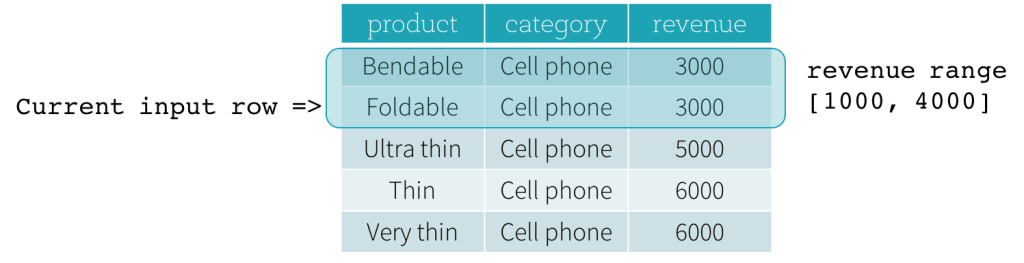
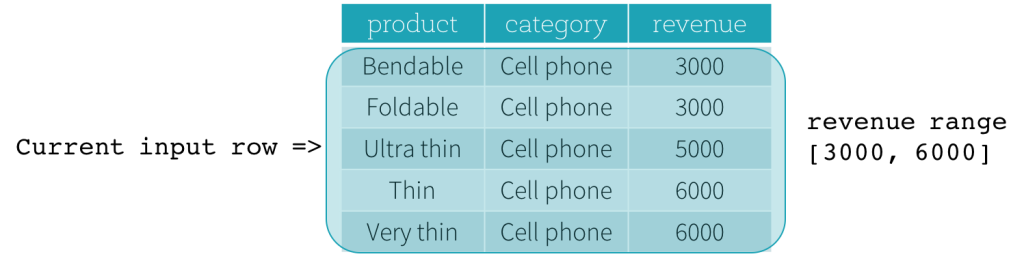
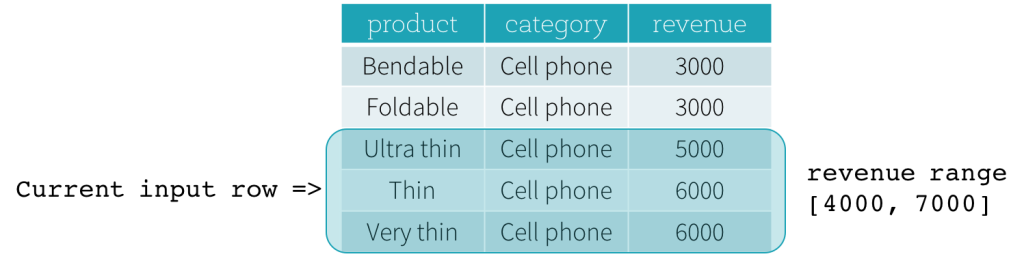
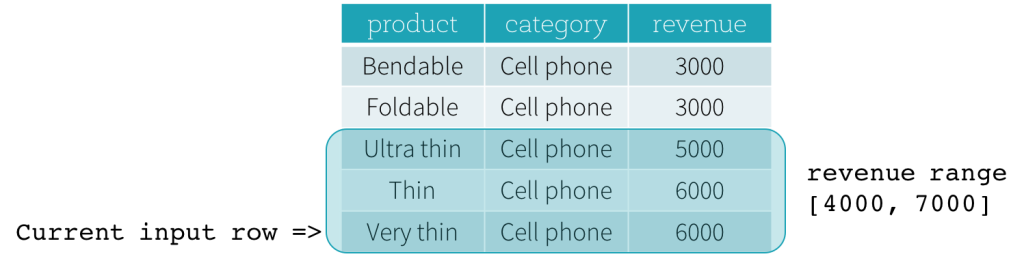
요약하자면, 창 사양을 정의하기 위해 SQL에서 다음 구문을 사용할 수 있습니다.
OVER (PARTITION BY ... ORDER BY ... frame_type BETWEEN start AND end)
여기서 frame_type은 ROWS (ROW 프레임의 경우) 또는 RANGE (RANGE 프레임의 경우)이며, start는 UNBOUNDED PRECEDING, CURRENT ROW, end는 UNBOUNDED FOLLOWING, CURRENT ROW,
Python DataFrame API에서는 다음과 같이 창 사양을 정의할 수 있습니다.
다음 단계
Spark 1.4 출시 이후, 창 함수 평가 연산자의 성능을 개선하고 메모리 소비를 줄이는 최적화에 대해 커뮤니티 회원들과 적극적으로 협력해 왔습니다. 이 중 일부는 Spark 1.5에 추가될 예정이며, 다른 일부는 향후 릴리스에 추가될 것입니다. 성능 개선 작업 외에도 Spark SQL에서 창 함수 지원을 더욱 강력하게 만들기 위해 가까운 미래에 두 가지 기능을 추가할 예정입니다. 첫째, 날짜 및 타임스탬프 데이터 유형에 대한 Interval 데이터 유형 지원을 추가하는 작업을 진행하고 있습니다 (SPARK-8943). Interval 데이터 유형을 사용하면 사용자는 RANGE 프레임의
이러한 Spark 기능을 사용해 보려면 Databricks 무료 평가판을 이용하거나 커뮤니티 에디션을 사용하세요.
감사의 말씀
Spark 1.4에서 창 함수 지원 개발은 Spark 커뮤니티의 많은 회원들의 공동 작업이었습니다. 특히 초기 패치를 기여한 Wei Guo에게 감사를 표합니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.