PySpark용 Pandas UDF 소개
PySpark에서 네이티브 Python 코드를 빠르게 실행하는 방법.
작성자: Li Jin
Free Edition이 Community Edition을 대체하여 향상된 기능을 무료로 제공합니다. 지금 바로 Free Edition 을(를) 사용해 보세요.
참고: Spark 3.0에서 새로운 pandas UDF가 도입되었습니다. 자세한 내용은 다음 블로그 게시물에서 확인할 수 있습니다: Apache Spark 3.0의 새로운 Pandas UDF 및 Python 타입 힌트
이 글은 뉴욕의 Two Sigma Investments, LP에서 소프트웨어 엔지니어로 일하는 Li Jin의 커뮤니티 기고입니다. 이 블로그는 Two Sigma에도 게시되었습니다.
업데이트: 이 블로그는 일부 변경 사항을 포함하기 위해 2018년 2월 22일에 업데이트되었습니다.
이 블로그 게시물은 곧 출시될 Apache Spark 2.3 릴리스의 Pandas UDF(벡터화된 UDF라고도 함) 기능을 소개하며, 이는 Python에서 사용자 정의 함수(UDF)의 성능과 사용성을 크게 향상시킵니다.
지난 몇 년 동안 Python은 데이터 과학자들에게 기본 언어가 되었습니다. pandas, numpy, statsmodel, scikit-learn과 같은 패키지가 널리 채택되어 주류 툴킷이 되었습니다. 동시에 Apache Spark는 빅데이터 처리의 사실상의 표준이 되었습니다. 데이터 과학자들이 빅데이터의 가치를 활용할 수 있도록 Spark는 버전 0.7에서 Python API를 추가했으며, 사용자 정의 함수를 지원합니다. 이러한 사용자 정의 함수는 한 번�에 한 행씩 작동하므로 직렬화 및 호출 오버헤드가 높습니다. 결과적으로 많은 데이터 파이프라인은 Java 및 Scala로 UDF를 정의한 다음 Python에서 호출합니다.
Apache Arrow를 기반으로 구축된 Pandas UDF는 두 세계의 장점을 모두 제공합니다. 즉, Python에서 저오버헤드, 고성능 UDF를 완전히 정의할 수 있습니다.
Spark 2.3에는 스칼라 및 그룹화된 맵의 두 가지 유형의 Pandas UDF가 있습니다. 다음으로 네 가지 예제 프로그램인 Plus One, 누적 확률, 평균 빼기, 최소 제곱 선형 회귀를 사용하여 사용법을 설명합니다.
스칼라 Pandas UDF
스칼라 Pandas UDF는 스칼라 연산을 벡터화하는 데 사용됩니다. 스칼라 Pandas UDF를 정의하려면 단순히 @pandas_udf를 사용하여 pandas.Series를 인수로 받고 동일한 크기의 다른 pandas.Series를 반환하는 Python 함수에 주석을 답니다. 아래에서는 Plus One 및 누적 확률의 두 가지 예제를 사용하여 설명합니다.
Plus One
v + 1을 계산하는 것은 행별 UDF와 스칼라 Pandas UDF 간의 차이를 보여주는 간단한 예입니다. 이 시나리오에서는 내장 열 연산자가 훨씬 더 빠르게 수행될 수 있습니다.
행별 UDF 사용:
Pandas UDF 사용:
위의 예제는 동일한 "plus one" 계산을 수행하는 행별 UDF "plus_one"과 스칼라 Pandas UDF "pandas_plus_one"을 정의합니다. UDF 정의는 함수 데코레이터("udf" 대 "pandas_udf")를 제외하고는 동일합니다.
행별 버전에서는 사용자 정의 함수가 double "v"를 받아 "v + 1"의 결과를 double로 반환합니다. Pandas 버전에서는 사용자 정의 함수가 pandas.Series "v"를 받아 "v + 1"의 결과를 pandas.Series로 반환합니다. "v + 1"은 pandas.Series에서 벡터화되므로 Pandas 버전은 행별 버전보다 훨씬 빠릅니다.
스칼라 pandas UDF를 사용할 때 두 가지 중요한 요구 사항이 있습니다:
- 입력 및 출력 시리즈는 동일한 크기여야 합니다.
- 열이 여러
pandas.Series로 분할되는 방식은 Spark 내부에서 처리되므로 사용자 정의 함수의 결과는 분할과 독립적이어야 합니다.
누적 확률
이 예제는 스칼라 Pandas UDF의 보다 실용적인 사용법을 보여줍니다. 누적 확률을 scipy 패키지를 사용하여 정규 분포 N(0,1)의 값에 대해 계산합니다.
stats.norm.cdf는 스칼라 값과 pandas.Series 모두에서 작동하며, 이 예제는 행별 UDF로도 작성할 수 있습니다. 이전 예와 유사하게 Pandas 버전은 "성능 비교" 섹션에서 볼 수 있듯이 훨씬 빠르게 실행됩니다.
그룹화된 맵 Pandas UDF
Python 사용자는 데이터 분석에서 분할-적용-결합 패턴에 매우 익숙합니다. 그룹화된 맵 Pandas UDF는 이 시나리오를 위해 설계되었으며, 그룹별 모든 데이터에 대해 작동합니다. 예를 들어 "각 날짜별로 이 작업을 적용"합니다.
그룹화된 맵 Pandas UDF는 먼저 groupby 연산자에 지정된 조건에 따라 Spark DataFrame을 그룹으로 분할하고, 각 그룹에 사용자 정의 함수(pandas.DataFrame -> pandas.DataFrame)를 적용하고, 결과를 결합하여 새 Spark DataFrame으로 반환합니다.
그룹화된 맵 Pandas UDF는 스칼라 Pandas UDF와 동일한 함수 데코레이터 pandas_udf를 사용하지만 몇 가지 차이점이 있습니다:
- 사용자 정의 함수의 입력:
- 스칼라:
pandas.Series - 그룹화된 맵:
pandas.DataFrame
- 스칼라:
- 사용자 정의 함수의 출력:
- 스칼라:
pandas.Series - 그룹화된 맵:
pandas.DataFrame
- 스칼라:
- 그룹화 의미론:
- 스칼라: 그룹화 의미론 없음
- 그룹화된 맵: "groupby" 절에 의해 정의됨
- 출력 크기:
- 스칼라: 입력 크기와 동일
- 그룹화된 맵: 모든 크기
- 함수 데코레이터의 반환 유형:
- 스칼라: 반환되는
pandas.Series의 유형을 지정하는DataType - 그룹화된 맵: 반환되는
pandas.DataFrame의 각 열 이름과 유형을 지정하는StructType
- 스칼라: 반환되는
다음으로 그룹화된 맵 Pandas UDF의 사용 사례를 설명하기 위해 두 가지 예제를 살펴보겠습니다.
평균 빼기
이 예제는 그룹화된 맵 Pandas UDF의 간단한 사용법을 보여줍니다. 즉, 그룹 내 각 값에서 평균을 뺍니다.
이 예제에서는 "id"별로 그룹화된 각 그룹에 대해 v의 평균을 v의 각 값에서 뺍니다. 그룹화 의미론은 "groupby" 함수에 의해 정의됩니다. 즉, 사용자 정의 함수에 대한 각 입력 pandas.DataFrame은 동일한 "id" 값을 갖습니다. 이 사용자 정의 함수의 입력 및 출력 스키마는 동일하므로 스키마를 지정하기 위해 데코레이터 pandas_udf에 "df.schema"를 전달합니다.
그룹화된 맵 Pandas UDF는 드라이버에서 독립 실행형 Python 함수로 호출할 수도 있습니다. 이는 예를 들어 디버깅에 매우 유용합니다:
위 예제에서는 먼저 Spark DataFrame의 작은 하위 집합을 pandas.DataFrame으로 변환한 다음, 이를 사용하여 subtract_mean을 독립 실행형 Python 함수로 실행합니다. 함수 논리를 확인한 후 전체 데이터 세트에 대해 Spark와 함께 UDF를 호출할 수 있습니다.
최소 제곱 선형 회귀
마지막 예제는 statsmodels를 사용하여 각 그룹에 대해 OLS 선형 회귀를 실행하는 방법을 보여줍니다. 각 그룹에 대해 통계 모델 Y = bX + c에 따라 X = (x1, x2)에 대한 베타 b = (b1, b2)를 계산합니다.
이 예시는 그룹화된 맵 Pandas UDF를 임의의 파이썬 함수와 함께 사용할 수 있음을 보여줍니다: pandas.DataFrame -> pandas.DataFrame. 반환된 pandas.DataFrame은 입력과 다른 행 및 열 수를 가질 수 있습니다.
성능 비교
마지막으로, 행 단위 UDF와 Pandas UDF 간의 성능 비교를 보여드리고자 합니다. 위 예시 중 세 가지 (누적 확률 및 평균 빼기 추가)에 대한 마이크로 벤치마크를 실행했습니다.
구성 및 방법론
Databricks Community Edition의 단일 노드 Spark 클러스터에서 벤치마크를 실행했습니다.
구성 세부 정보:
데이터: Int 열과 Double 열이 있는 10M 행 DataFrame
클러스터: 6.0 GB 메모리, 0.88 코어, 1 DBU
Databricks runtime 버전: 최신 RC (4.0, Scala 2.11)
벤치마크의 자세한 구현은 Pandas UDF 노트북에서 확인하세요.
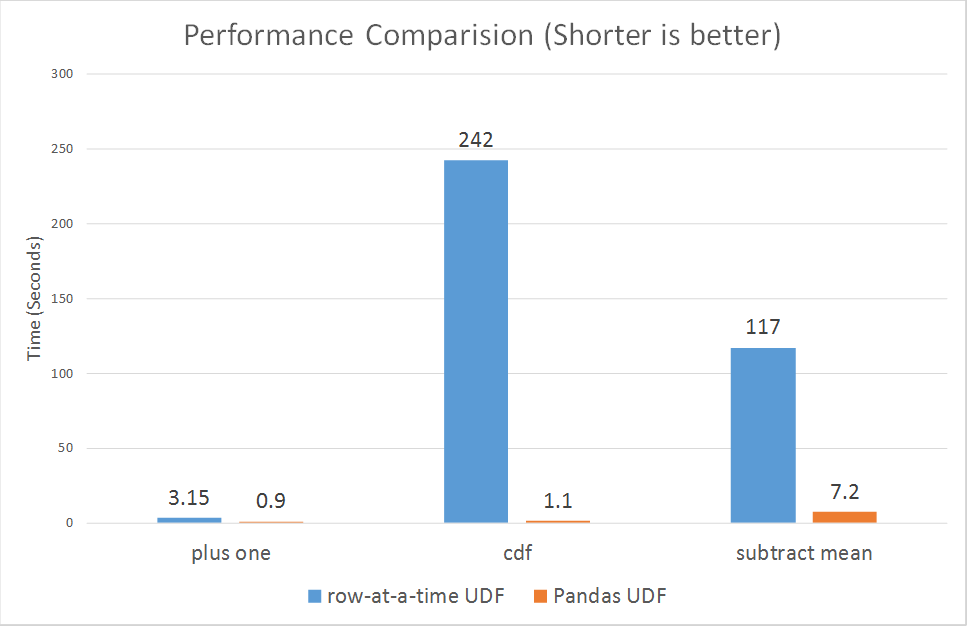
차트에서 볼 수 있듯이 Pandas UDF는 전반적으로 행 단위 UDF보다 훨씬 뛰어난 성능을 보이며, 그 성능 향상은 3배에서 100배 이상에 달합니다.
결론 및 향후 작업
다가오는 Spark 2.3 릴리스는 Python에서 사용자 정의 함수의 기능과 성능을 대폭 향상시킬 수 있는 기반을 마련합니다. 향후에는 집계 및 창 함수에서 Pandas UDF 지원을 도입할 계획입니다. 관련 작업은 SPARK-22216에서 추적할 수 있습니다.
Pandas UDF는 Spark 커뮤니티 노력의 훌륭한 예입니다. Bryan Cutler, Hyukjin Kwon, Jeff Reback, Liang-Chi Hsieh, Leif Walsh, Li Jin, Reynold Xin, Takuya Ueshin, Wenchen Fan, Wes McKinney, Xiao Li 및 다른 많은 분들의 기여에 감사드립니다. 마지막으로, 이 작업을 가능하게 한 Apache Arrow 커뮤니티에 특별한 감사를 전합니다.
다음 단계
Pandas UDF 노트북을 사용해 볼 수 있으며, 이 기능은 이제 Databricks Runtime 4.0 베타의 일부로 제공됩니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.