컨볼루션 신경망 적용: 온디맨드 웨비나 및 FAQ가 공개되었습니다!
작성자: Denny Lee , Cyrielle Simeone
10월 25일, Databricks의 기술 제품 마케팅 관리자인 Denny Lee와 함께 라이브 웨비나합성곱 신경망 적용하기를 개최했습니다. 이 웨비나는 Databricks에서 제공하는 무료 딥 러닝 기본 시리즈의 세 번째 웨비나입니다.

이번 웨비나에서는 입력이 이미지라고 가정하며 이미지 분류 및 객체 인식에 매우 효과적인 것으로 입증된 특정 유형의 신경망인 합성곱 신경망(CNN)에 대해 더 깊이 살펴보았습니다.
특히 다음과 같은 내용에 대해 이야기했습니다.
- 너��비, 높이, 깊이를 갖춘 3D로 배열된 노드를 사용하여 합성곱 필터를 적용하고 특징을 추출하는 CNN 아키텍처.
- 입력 이미지의 픽셀 영역에서 특징을 추출하기 위해 필터 크기, 스트라이드, 패딩을 선택하는 방법을 포함한 컨볼루션 커널(필터)의 작동 방식.
- 풀링 또는 서브샘플링은 이미지 크기를 줄여 매개변수 수를 감소시키고 과적합의 위험을 줄이는 기법입니다.
Databricks에서 Keras(TensorFlow 백엔드)를 사용하여 이러한 개념 중 일부를 시연했으며, 지금 바로 시작할 수 있는 노트북 링크는 다음과 같습니다.
아래에서 Part 1과 Part 2를 시청하실 수 있습니다.


Databricks 통합 분석 플랫폼 에 무료로 액세스하여 노트북을 사용해 보려면 여기에서 무료 체험을 이용할 수 있습니다.
마지막 부분에서는 Q&A를 진행했으며, 아래에 주제별로 분류된 질문과 답변이 나와 있습니다.
기본 사항
Q: 신경망을 사용하려면 신경망의 수학적 원리를 꼭 이해해야 하나요?
신경망을 사용하기 위해 그 기반이 되는 수학을 완전히 이해할 필요는 없지만, 올바른 알고리즘을 선택하고 딥러닝(및 머신러닝) 모델을 최적화, 개선 및 설계하는 방법을 이해하려면 이러한 기본 원리를 이해하는 것이 중요합니다. 이 주제에 대한 좋은 글은 Wale Akinfaderin의 The Mathematics of Machine Learning입니다.
컨볼루셔널 신경망
Q: 일반적인 신경망 대신 CNN을 사용하는 이유는 무엇인가요? 그리고 실생활에서 CNN을 어떻게 사용하나요? 이에 대한 적용 사례를 공유해 주실 수 있나요?
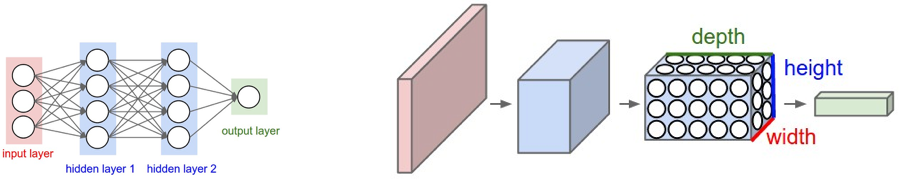
출처: https://cs231n.github.io/convolutional-networks/
신경망 훈련에서 더 자세히 설명했듯이, 컨볼루션 신경망(CNN)은 일반적인 인공 신경망 과 유사하지만, CNN은 입력이 이미지라는 명시적인 가정을 합니다. 문제는 (왼쪽 그래픽에서 시각화된 것처럼) 완전 연결 인공 신경망이 이미지에 잘 확장되지 않는다는 것입니다. 예를 들어 200픽셀 x 200픽셀 x 3 컬러 채널(예: RGB)은 120,000개의 가중치가 됩니다. 이미지가 (채��널별로) 더 크거나 복잡할수록 더 많은 가중치가 필요합니다. CNN의 경우, 노드는 3D(너비, 높이, 깊이)로 구성된 이전 레이어의 작은 영역에만 연결됩니다. 노드가 완전 연결되어 있지 않기 때문에 가중치 수(즉, 카디널리티)가 줄어들어 네트워크가 더 빨리 패스를 완료할 수 있게 됩니다.
Q: CNN은 계층, 크기, 유형으로 구성된 네트워크입니다. 어떻게 선택해야 하나요? 무엇을 기준으로요? 즉, 아키텍처는 어떻게 설계해야 하나요?
'신경망 입문 온디맨드 웨비나 및 FAQ 공개'에서 언급했듯이, 시작점에 대한 일반적인 경험 법칙이 있지만(예: 하나의 은닉층으로 시작하여 그에 따라 확장하고, 입력 노드 수는 특징의 차원과 같게 하는 등) 핵심은 테스트가 필요하다는 것입니다. 즉, 모델을 훈련한 다음 해당 모델에 대해 테스트 및/또는 검증을 실행하여 정확도(높을수록 좋음)와 손실(낮을수록 좋음)을 파악해야 합니다. 아키텍처 설계 측면에서, 더 잘 이해되고 연구된 아키텍처로 시작하는 것이 가장 좋습니다(예: AlexNet, LeNet-5, Inception, VGG, ResNet 등). 여기에서 실험을 실행하면서 레이어의 수, 크기, 유형을 조정할 수 있습니다.
Q: 완전 연결 레이어에 소프트맥스를 사용하는 이유는 무엇인가요?
로지스틱 회귀로 작업할 때, 이는 이진 분류에 대한 베르누이 분포를 가정합니다. 두 개 이상의 분류기에 적용해야 할 경우(예: MNIST 분류 문제) 베르누이 분포의 일반화인 다항 분포가 필요합니다. 다항 분포(다중 분류기)에 적용되는 회귀 유형은 소프트맥스 회귀라��고 합니다. MNIST의 경우 완전 연결 계층에서 0, ..., 9 사이의 값에 대한 손글씨 숫자를 분류하므로 softmax를 사용합니다.
Q: 필터 크기는 항상 홀수인가요?
필터 크기에 대한 일반적인 접근 방식은 f x f 이며, 여기서 f 는 홀수입니다. 명시적으로 언급되지는 않았지만 Applying 신경망의 39번 슬라이드에서 목표는 소스 픽셀과 주변 픽셀을 합성곱하는 것이므로 f 는 홀수입니다. 최소 필터 크기는 3 x 3 이 되는데, 이는 2D 공간에서 소스 픽셀 + 바깥쪽 1픽셀에 해당하기 때문입니다.

f 크기가 짝수이면 소스 픽셀 주위 픽셀의 절반도 채 안 되는 부분을 합성곱하게 됩니다. 더 자세히 알아보려면 https://datascience.stackexchange.com/questions/23183/why-convolutions-always-use-odd-numbers-as-filter-size/23186에서 이 질문에 대한 좋은 SO 답변을 확인할 수 있습니다.
Q: 가변 입력 길이를 사용하는 CNN을 어떻게 구현할 수 있나요? 즉, 크기가 다양한 이미지를 가진 학습 데이터에 대한 제안이 있으신가요?
일반적으로 CNN의 모든 입력 이미지 크기가 동일하도록 이미지 크기를 조정하거나 제로 패딩을 해야 합니다. 가변 크기 입력을 처리할 수 있는 LSTM, RNN 또는 재귀 신경망(특히 텍스트 데이터의 경우)을 포함하는 몇 가지 접근 방식이 있지만, 이는 종종 간단하지 않은 작업이라는 점에 유의하세요.
ML 환경 & 리소스
Q: 저는 Databricks 유료 사용자입니다. 제 PC에서 Keras를 실행하는 방법은 알지만 Databricks 내에서는 아직 모릅니다.
Databricks를 사용하는 경우 Keras, TensorFlow, XGBoost, Horovod, scikit-learn 등을 포함하는 Databricks Runtime for Machine Learning 클러스터를 시작하세요. 자세한 정보는 Announcing Databricks Runtime for Machine Learning을 참조하세요.
Q: ML에 대해 비슷한 세션이 있었나요?
훌륭한 Databricks 웨비나 가 많이 있으며, Machine Learning에 초점을 맞춘 웨비나는 다음과 같습니다(이에 국한되지 않음):
- MLflow 소개: 완전한 머신러닝 수명 주기를 위한 인프라
- Apache® Spark를 사용한 R 코드 병렬화
- 실시간 예측 서빙을 위한 Apache Spark™ MLlib 모델 프로덕션화
- Databricks와 머신 러닝이 유전체학의 미래를 어떻게 주도하는가
- GraphFrames: Apache® Spark™용 DataFrame 기반 그래프
- Apache® Spark™ MLlib: 빠른 시작부터 Scikit-Learn까지
리소스
- Machine Learning 101
- Andrej Karparthy의 ConvNetJS MNIST 데모
- 신경망에서 역전파란 무엇인가요?
- CS231n: 영상 인식을 위한 합성곱 신경망
- 신경망과 딥러닝
- TensorFlow
- 딥 시각화 툴박스
- TensorFlow를 사용한 역전파
- TensorFrames: Apache Spark와 함께 사용하는 Google TensorFlow
- 딥 러닝 라이브러리를 Apache Spark와 통합
- 딥러닝 파이프라인을 손쉽게 구축, 확장 및 배포
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.