Delta Lake에서 병합 작업 시 스키마 진화 및 운영 지표
Delta Lake 0.6.0은 병합 및 테이블 기록의 운영 메트릭에서 스키마 진화와 성능 개선을 도입합니다.
작성자: Tathagata Das , Denny Lee
지금 바로 O'Reilly의 새 전자책을 미리 보고 Delta Lake 사용을 시작하는 데 필요한 단계별 안내를 받아보세요.
아래 설명된 단계를 재현하려면 이 노트북을 사용해 보세요.
최근 저희는 스키마 진화와 merge 작업의 성능 개선 및 테이블 기록에 대한 운영 메트릭을 도입한 Delta Lake 0.6.0을 출시한다고 발표했습니다. 이번 릴리스의 주요 기능은 다음과 같습니다.
- merge 작업에서의 스키마 진화 지원(#170) - 이제 merge 작업을 통해 테이블의 스키마를 자동으로 진화시킬 수 있습니다. 이는 테이블에 변경 데이터를 upsert하려는 시나리오에서 데이터 스키마가 시간이 지남에 따라 변경될 때 유용합니다. upsert 전에 스키마 변경을 감지하고 적용하는 대신, merge는 스키마를 진화시키고 변경 사항을 동시에 upsert할 수 있습니다.
- 자동 재분할을 통한 merge 성능 향상(#349) - 분할된 테이블에 merge할 때 테이블에 쓰기 전에 분할 열을 기준으로 데이터를 자동으로 재분할하도록 선택할 수 있습니다. 분할된 테이블에 대한 merge 작업이 너무 많은 작은 파일을 생성하여 느린 경우(#345), 자동 재분할(spark.delta.merge.repartitionBeforeWrite)을 활성화하면 성능을 개선할 수 있습니다.
- insert 절이 없는 경우 성능 향상(#342) - 이제 insert 절이 없는 merge 작업에서 더 나은 성능을 얻을 수 있습니다.
- DESCRIBE HISTORY의 작업 메트릭(#312) - 이제 테이블 기록에서 Delta 테이블에 대한 모든 쓰기, 업데이트 및 삭제 작업에 대한 작업 메트릭(예: 파일 수 및 변경된 행 수)을 볼 수 있습니다.
- 모든 파일 시스템에서 Delta 테이블 읽기 지원(#347) - 이제 Hadoop FileSystem 구현이 있는 모든 스토리지 시스템에서 Delta 테이블을 읽을 수 있습니다. 그러나 Delta 테이블에 쓰려면 여전히 스토리지 시스템에 필요한 보증을 제공하는 LogStore 구현을 구성해야 합니다.
Merge 작업에서의 스키마 진화
Delta Lake의 이전 릴리스에서 언급했듯이, Delta Lake는 merge 작업을 실행하여 단일 원자 작업으로 insert/update/delete 작업을 단순화하고 스키마를 적용하고 진화할 수 있는 기능을 포함합니다(이 기술 토크에서도 자세한 내용을 확인할 수 있습니다). Delta Lake 0.6.0 릴리스를 통해 이제 merge 작업 내에서 스키마를 진화시킬 수 있습니다.
이를 보여주기 위해 시기적절한 예제를 사용해 보겠습니다. 원본 코드 샘플은 이 노트북에서 찾을 수 있습니다. Johns Hopkins CSSE의 2019 Novel Coronavirus COVID-19 (2019-nCoV) 데이터 리포지토리의 작은 하위 집합으로 시작하겠습니다. 이 데이터셋은 연구원과 분석가가 전 세계 COVID-19 사례 수를 파악하는 데 일반적으로 사용됩니다. 이 데이터의 문제점 중 하나는 스키마가 시간이 지남에 따라 변경된다는 것입니다.
예를 들어, 3월 1일부터 3월 21일까지의 COVID-19 사례를 나타내는 파일(2020년 4월 30일 기준)은 다음과 같은 스키마를 가집니다.
그러나 3월 22일 이후의 파일(2020년 4월 30일 기준)에는 FIPS, Admin2, Active, Combined_Key를 포함한 추가 열이 있었습니다.
샘플 코드에서는 의미상 동일한 열(예: Long_ -> Longitude, Province/State -> Province_State 등)의 이름을 변경했습니다. 테이블 스키마를 진화시키는 대신 열 이름을 변경했습니다.
스키마를 단순히 병합하는 것이 주요 관심사였다면, 다음 문에서 볼 수 있듯이 DataFrame.write()의 “mergeSchema” 옵션을 사용하여 Delta Lake의 스키마 진화 기능을 사용할 수 있습니다.
하지만 기존 값을 업데이트하고 동시에 스키마를 merge해야 하는 경우에는 어떻게 될까요? Delta Lake 0.6.0을 사용하면 merge 작업을 위한 스키마 진화를 통해 이를 달성할 수 있습니다. 이를 시각화하기 위해 먼저 한 행인 old_data를 검토해 보겠습니다.
다음으로 new_data 스키마를 따르는 업데이트 항목을 시뮬레이션해 보겠습니다.
simulated_update와 new_data를 합쳐 총 40개 행으로 만듭니다.
자동 스키마 진화를 위해 환경을 구성하는 다음 매개변수를 설정합니다.
이제 다음 문을 사용하여 값을 업데이트하고(2020년 3월 21일 기준) 새 스키마를 merge하는 단일 원자 작업을 실행할 수 있습니다.
다음 문을 사용하여 Delta Lake 테이블을 검토해 보겠습니다.
운영 지표
Spark UI에서 Delta Lake 테이블 기록(operationMetrics 열)을 확인하여 운영 지표를 더 자세히 살펴볼 수 있습니다. 다음 문을 실행하여 확인할 수 있습니다.
위 명령의 축약된 결과는 다음과 같습니다.
테이블의 두 가지 버전, 즉 이전 스키마 버전과 새 스키마 버전이 있음을 알 수 있습니다. 아래 운영 지표를 검토하면 39개의 행이 삽입되고 1개의 행이 업데이트되었음을 알 수 있습니다.
Spark UI의 SQL 탭으로 이동하여 이러한 운영 지표에 대한 자세한 내용을 이해할 수 있습니다.
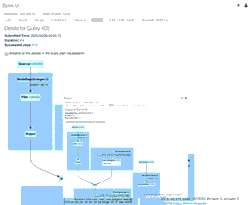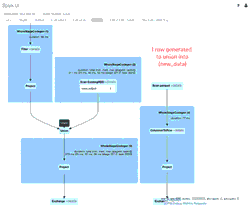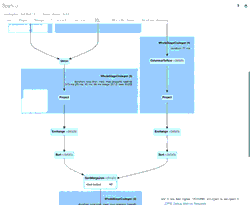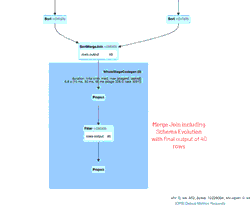
애니메이션 GIF는 검토를 위해 Spark UI의 주요 구성 요소를 보여줍니다.
- 초기 새_데이터 DataFrame을 생성한 하나의 파일(2020년 4월 11일, 새 스키마)의 39개 초기 행
- 새_데이터 DataFrame과 union될 시뮬레이션된 업데이트 행 1개
- 초기 오래된_데이터 DataFrame을 생성한 하나의 ��파일(2020년 3월 21일, 이전 스키마)의 1개 행
- Delta Lake 테이블에 유지될 두 DataFrame을 union하기 위해 사용된 SortMergeJoin
이러한 운영 지표에 대한 자세한 해석은 Diving into Delta Lake Part 3: How do DELETE, UPDATE, and MERGE work tech talk에서 확인할 수 있습니다.

Delta Lake 0.6.0 시작하기
Apache Spark 2.4.5(이상) 인스턴스(Databricks에서는 DBR 6.6 이상으로 시도)에서 위의 코드 조각을 사용하여 Delta Lake를 사용해 보세요. Delta Lake는 데이터 레이크를 더 안정적으로 만듭니다(새로운 데이터 레이크를 생성하거나 기존 데이터 레이크를 마이그레이션하는 경우). 자세한 내용은 https://delta.io/를 참조하고 Slack 및 Google 그룹을 통해 Delta Lake 커뮤니티에 참여하세요. GitHub 마일스톤에서 예정된 릴리스 및 계획된 기능을 추적할 수 있습니다. 무료 계정으로 Databricks에서 관리형 Delta Lake를 사용해 볼 수도 있습니다.
크레딧
Delta Lake 0.6.0의 업데이트, 문서 변경 및 기여에 대해 다음 기여자들에게 감사드립니다: Ali Afroozeh, Andrew Fogarty, Anurag870, Burak Yavuz, Erik LaBianca, Gengliang Wang, IonutBoicuAms, Jakub Orłowski, Jose Torres, KevinKarlBob, Michael Armbrust, Pranav Anand, Rahul Govind, Rahul Mahadev, Shixiong Zhu, Steve Suh, Tathagata Das, Timothy Zhang, Tom van Bussel, Wesley Hoffman, Xiao Li, chet, Eugene Koifman, Herman van Hovell, hongdd, lswyyy, lys0716, Mahmoud Mahdi, Maryann Xue
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.