적응형 쿼리 실행: 런타임 시 Spark SQL 속도 향상
작성자: Wenchen Fan, Herman van Hövell , MaryAnn Xue
데이터 레이크하우스의 부상을 읽고 데이터 웨어하우스의 아버지인 Bill Inmon과 함께 레이크하우스가 미래의 데이터 아키텍처인 이유를 알아보세요.
이것은 Databricks Apache Spark 엔지니어링 팀(Wenchen Fan, Herman van Hovell, MaryAnn Xue)과 Intel 엔지니어링 팀(Ke Jia, Haifeng Chen, Carson Wang) 간의 공동 엔지니어링 노력입니다.
아래에서 다루는 솔루션을 시연하는 AQE 노트북 보기 또는 Databricks Lakehouse Platform의 내부 작동 방식에 대해 자세히 알아보세요
수년에 걸쳐 Spark SQL의 쿼리 옵티마이저 및 플래너를 개선하여 고품질 쿼리 실행 계획을 생성하기 위한 광범위하고 지속적인 노력이 있었습니다. 가장 큰 개선 사��항 중 하나는 다양한 데이터 통계(예: 행 수, 고유 값 수, NULL 값, 최대/최소 값 등)를 수집하고 활용하여 Spark가 더 나은 계획을 선택하도록 돕는 비용 기반 최적화 프레임워크입니다. 이러한 비용 기반 최적화 기법의 예로는 올바른 조인 유형(브로드캐스트 해시 조인 대 정렬 병합 조인) 선택, 해시 조인에서 올바른 빌드 측 선택 또는 다중 조인에서 조인 순서 조정이 있습니다. 그러나 오래된 통계와 불완전한 카디널리티 추정은 최적이 아닌 쿼리 계획으로 이어질 수 있습니다. 쿼리 실행 중에 수집된 런타임 통계를 기반으로 쿼리 계획을 재최적화하고 조정하는 Adaptive Query Execution은 곧 출시될 Apache SparkTM 3.0 릴리스에 새로 추가되었으며 Databricks Runtime 7.0에서 사용할 수 있습니다.
Adaptive Query Execution (AQE) 프레임워크
Adaptive Query Execution에서 가장 중요한 질문 중 하나는 언제 재최적화할 것인가입니다. Spark 연산자는 종종 파이프라인되고 병렬 프로세스에서 실행됩니다. 그러나 셔플 또는 브로드캐스트 교환은 이 파이프라인을 중단합니다. 이를 재료화 지점이라고 부르며 쿼리에서 이러한 재료화 지점으로 경계가 지정된 하위 섹션을 나타내기 위해 "쿼리 단계"라는 용어를 사용합니다. 각 쿼리 단계는 중간 결과를 재료화하며 다음 단계는 재료화를 실행하는 모든 병렬 프로세스가 완료된 경우에만 진행될 수 있습니다. 이는 데이터 통계가 모든 파티션에 대해 사용 가능하고 후속 작업이 아직 시작되지 않았기 때문에 재최적화의 자연스러운 기회를 제공합니다.
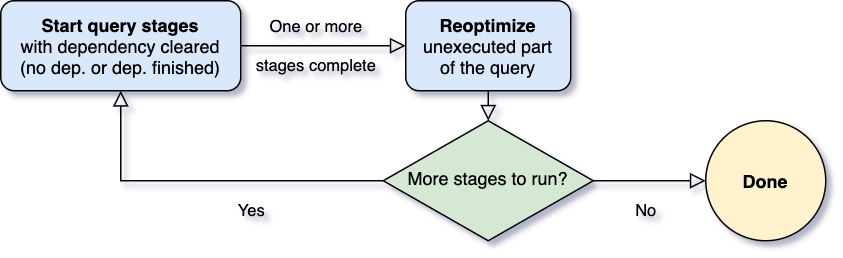
쿼리가 시작되면 Adaptive Query Execution 프레임워크는 먼저 모든 리프 단계를 시작합니다. 즉, 다른 단계에 의존하지 않는 단계입니다. 이러한 단계 중 하나 이상이 재료화를 완료하는 즉시 프레임워크는 물리적 쿼리 계획에서 완료로 표시하고 완료된 단계에서 검색된 런타임 통계를 사용하여 논리적 쿼리 계획을 적절하게 업데이트합니다. 이러한 새 통계를 기반으로 프레임워크는 옵티마이저(선택된 논리적 최적화 규칙 목록 포함), 물리적 플래너 및 파티션 병합, 스큐 조인 처리 등과 같은 정규 물리적 규칙 및 적응형 실행별 규칙을 포함하는 물리적 최적화 규칙을 실행합니다. 이제 일부 완료된 단계를 포함하는 새로 최적화된 쿼리 계획이 있으므로 적응형 실행 프레임워크는 모든 하위 단계가 재료화된 새 쿼리 단계를 검색하고 실행하며 전체 쿼리가 완료될 때까지 위의 실행-재최적화-실행 프로세스를 반복합니다.
Spark 3.0에서는 AQE 프레임워크에 세 가지 기능이 포함되어 있습니다.
- 셔플 파티션 동적 병합
- 조인 전략 동적 전환
- 스큐 조인 동적 최적화
다음 섹션에서는 이 세 가지 기능에 대해 자세히 설명합니다.
셔플 파티션 동적 병합
매우 큰 데이터로 Spark에서 쿼리를 실행할 때 셔플은 다른 많은 것들 중에서 쿼리 성능에 매우 중요한 영향을 미칩니다. 셔플은 데이터를 네트워크를 통해 이동해야 하므로 다운스트림 연산자가 요구하는 방식으로 데이터가 재분배되기 때문에 비용이 많이 드는 연산자입니다.
셔플의 한 가지 주요 속성은 파티션 수입니다. 최적의 파티션 수는 데이터에 따라 다르지만 데이터 크기는 단계마다, 쿼리마다 크게 다를 수 있으므로 이 숫자를 조정하기 어렵습니다.
- 파티션 수가 너무 적으면 각 파티션의 데이터 크기가 매우 커질 수 있으며, 이러한 큰 파티션을 처리하는 작업은 디스크에 데이터를 스필해야 할 수 있습니다(예: 정렬 또는 집계가 포함된 경우). 결과적으로 쿼리가 느려집니다.
- 파티션 수가 너무 많으면 각 파티션의 데이터 크기가 매우 작아질 수 있으며, 셔플 블록을 읽기 위해 많은 작은 네트워크 데이터 가져오기가 발생하여 비효율적인 I/O 패턴으로 인해 쿼리가 느려질 수도 있습니다. 또한 많은 수의 작업은 Spark 작업 스케줄러에 더 많은 부담을 줍니다.
이 문제를 해결하기 위해 처음에 비교적 많은 수의 셔플 파티션을 설정한 다음 셔플 파일 통계를 보고 런타임에 인접한 작은 파티션을 더 큰 파티션으로 결합할 수 있습니다.
예를 들어, SELECT max(i)FROM tbl GROUP BY j 쿼리를 실행한다고 가정해 보겠습니다. 입력 데이터 tbl은 매우 작으므로 그룹화 전에 파티션이 두 개만 있습니다. 초기 셔플 파티션 수는 다섯 개로 설정되므로 로컬 그룹화 후 부분적으로 그룹화된 데이터는 다섯 개의 파티션으로 셔플됩니다. AQE 없이 Spark는 최종 집계를 수행하기 위해 다섯 개의 작업을 시작합니다. 그러나 여기에는 세 개의 매우 작은 파티션이 있으며 각각에 대해 별도의 작업을 시작하는 것은 낭비입니다.
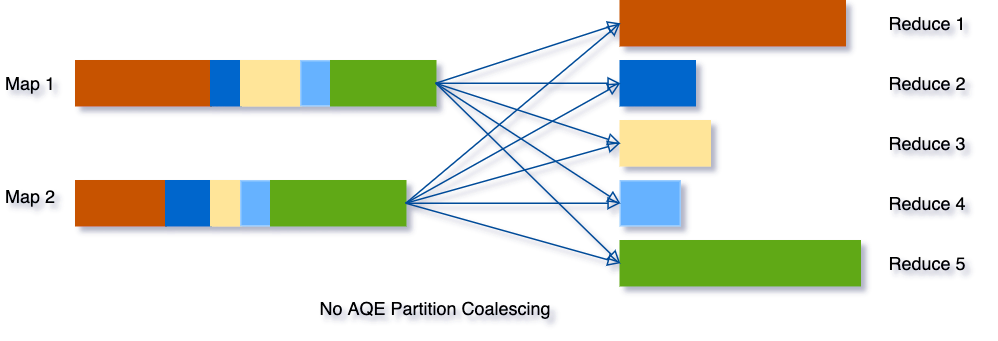
대신 AQE는 이 세 개의 작은 파티션을 하나로 병합하므로 최종 집계는 다섯 개가 아닌 세 개의 작업만 수행하면 됩니다.

조인 전략 동적 전환
Spark는 여러 조인 전략을 지원하며, 그중 브로드캐스트 해시 조인은 한쪽 조인 측이 메모리에 잘 맞으면 일반적으로 가장 성능이 좋습니다. 이러한 이유로 Spark는 추정된 조인 관계 크기가 브로드캐스트 크기 임계값보다 작으면 브로드캐스트 해시 조인을 계획합니다. 그러나 매우 선택적인 필터의 존재 또는 스캔이 아닌 복잡한 연산자 시리즈인 조인 관계와 같이 이 크기 추정을 잘못하게 만드는 여러 가지 요인이 있을 수 있습니다.
이 문제를 해결하기 위해 AQE는 이제 가장 정확한 조인 관계 크기를 기반으로 런타임에 조인 전략을 다시 계획합니다. 다음 예에서 볼 수 있듯이 조인의 오른쪽이 추정보다 훨씬 작고 브로드캐스트하기에 충분히 작다고 판단되므로 AQE 재최적화 후 정적으로 계획된 정렬 병합 조인은 브로드캐스트 해시 조인으로 변환됩니다.
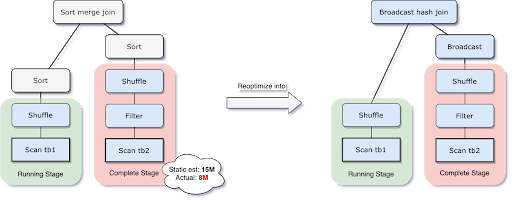
런타임에 변환된 브로드캐스트 해시 조인의 경우 네트워크 트래픽을 줄이기 위해 일반 셔플을 로컬화된 셔플(즉, 리듀서당이 �아닌 매퍼당 읽는 셔플)로 추가로 최적화할 수 있습니다.
스큐 조인 동적 최적화
데이터 스큐는 클러스터의 파티션 간에 데이터가 고르지 않게 분포될 때 발생합니다. 심각한 스큐는 특히 조인에서 쿼리 성능을 크게 저하시킬 수 있습니다. AQE 스큐 조인 최적화는 셔플 파일 통계에서 이러한 스큐를 자동으로 감지합니다. 그런 다음 스큐된 파티션을 더 작은 하위 파티션으로 분할하여 해당 파티션이 다른 쪽의 해당 파티션에 조인되도록 합니다.
테이블 A가 테이블 B를 조인하는 이 예제를 들어 보겠습니다. 테이블 A에는 다른 파티션보다 훨씬 큰 파티션 A0이 있습니다.
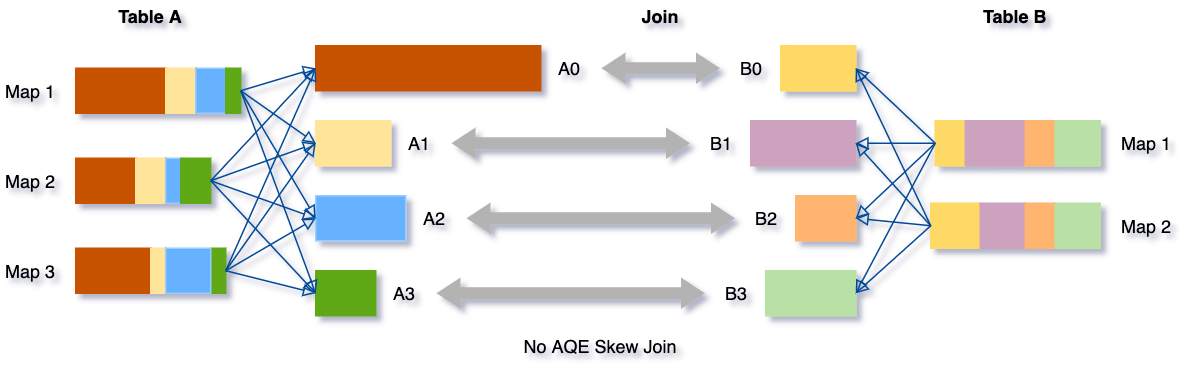
스큐 조인 최적화는 파티션 A0을 두 개의 하위 파티션으로 분할하고 각각을 테이블 B의 해당 파티션 B0에 조인합니다.
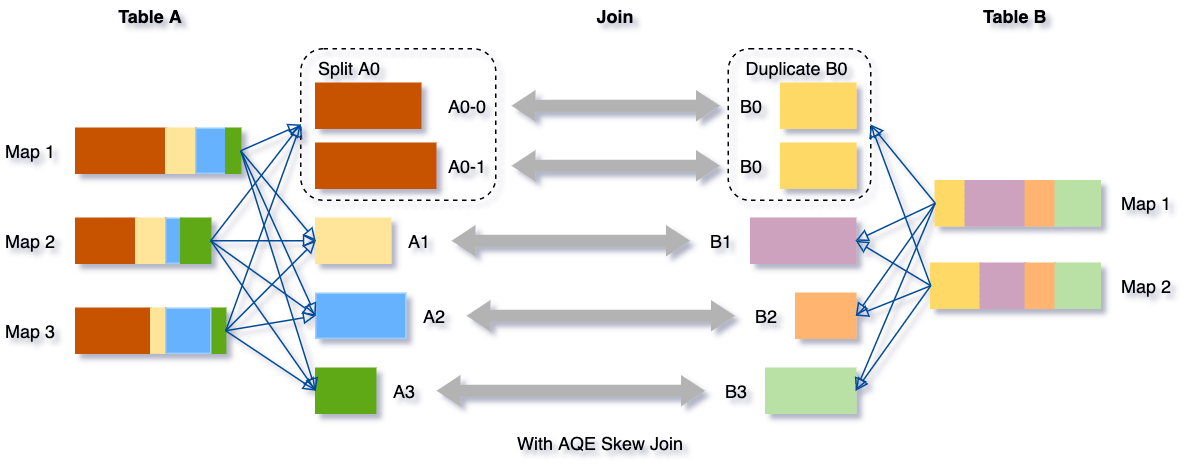
이 최적화가 없다면, 네 개의 태스크가 sort merge join을 실행하며 한 태스크가 훨씬 더 오래 걸렸을 것입니다. 이 최적화 후에는 다섯 개의 태스크가 join을 실행하지만, 각 태스크는 대략 같은 시간이 걸릴 것이며, 이는 전반적으로 더 나은 성능으로 이어집니다.
TPC-DS 성능 향상 (AQE 사용 시)
TPC-DS 데이터와 쿼리를 사용한 실험에서, Adaptive Query Execution은 쿼리 성능을 최대 8배까지 향상시켰으며 32개의 쿼리는 1.1배 이상의 성능 향상을 보였습니다. 아래는 AQE에 의해 성능이 가장 많이 향상된 10개의 TPC-DS 쿼리 차트입니다.
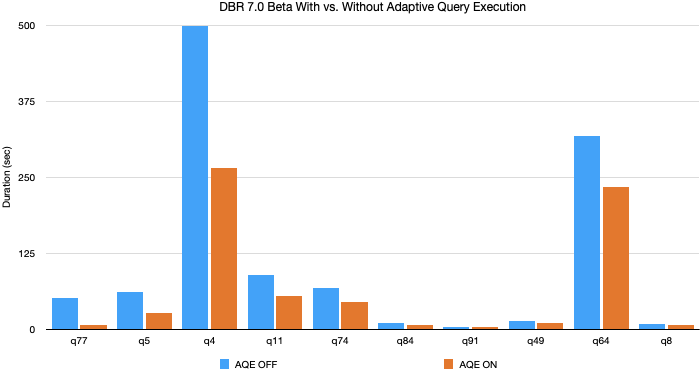
이러한 성능 향상의 대부분은 동적 파티션 병합과 동적 조인 전략 전환에서 비롯되었습니다. 무작위로 생성된 TPC-DS 데이터는 데이터 편중(skew)이 없기 때문입니다. 하지만 세 가지 AQE 기능을 모두 활용하는 실제 워크로드에서는 훨씬 더 큰 성능 향상을 보였습니다.
AQE 활성화하기
AQE는 SQL 설정 spark.sql.adaptive.enabled를 true로 설정하여 활성화할 수 있습니다 (Spark 3.0에서는 기본값 false). 다음 기준을 충족하는 쿼리에 적용됩니다:
- 스트리밍 쿼리가 아닐 것
- 최소 하나의 exchange (일반적으로 join, aggregate 또는 window 연산자가 있을 때) 또는 하나의 하위 쿼리를 포함할 것
쿼리 최적화가 정적 통계에 덜 의존하게 함으로써, AQE는 Spark 비용 기반 최적화의 가장 큰 어려움 중 하나인 통계 수집 오버헤드와 추정 정확도 간의 균형 문제를 해결했습니다. 최상의 추정 정확도와 계획 결과를 얻으려면, 컬럼 히스토그램과 같이 선택도 및 카디널리티 추정치를 개선하거나 데이터 편중을 감지하는 데 사용될 수 있는 상세하고 최신 통계를 유지해야 하며, 일부는 수집하는 데 비용��이 많이 듭니다. AQE는 이러한 통계의 필요성과 수동 튜닝 노력을 크게 줄여주었습니다. 또한, AQE는 SQL 쿼리 최적화를 임의의 UDF 및 예측 불가능한 데이터셋 변경(예: 데이터 크기의 갑작스러운 증가 또는 감소, 빈번하고 무작위적인 데이터 편중 등)의 존재에 더 탄력적으로 만들었습니다. 데이터를 미리 '알 필요'가 더 이상 없습니다. AQE는 쿼리가 실행되는 동안 데이터를 파악하고 쿼리 계획을 개선하여 쿼리 성능을 높여 더 빠른 분석과 시스템 성능을 제공합니다.
Spark 3.0에 대한 자세한 내용은 저희 미리 보기 웨비나에서 확인하세요. Databricks Runtime 7.0의 일부로 Databricks에서 무료로 Spark 3.0의 AQE를 오늘 사용해 보세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.