Apache Spark™ 3.0의 날짜 및 타임스탬프 종합 분석
작성자: Maxim Gekk, Wenchen Fan , Hyukjin Kwon
Apache Spark는 구조화된 데이터와 비구조화된 데이터를 처리하는 데 매우 인기 있는 도구입니다. 구조화된 데이터를 처리할 때 정수, 긴 정수, 배정밀도 부동 소수점 수, 문자열 등과 같은 많은 기본 데이터 유형을 지원합니다. Spark는 또한 개발자가 이해하기 어려운 Date 및 Timestamp와 같은 더 복잡한 데이터 유형도 지원합니다. 이 블로그 게시물에서는 Date 및 Timestamp 유형을 자세히 살펴보고 동작을 완전히 이해하고 일반적인 문제를 피하는 방법을 알아보겠습니다. 요약하자면, 이 블로그는 네 부분으로 구성됩니다.
- Date 유형과 관련된 달력의 정의입니다. 또한 Spark 3.0의 달력 전환에 대해서도 다룹니다.
- Timestamp 유형의 정의와 시간대와의 관계입니다. 또한 시간대 오프셋 확인의 세부 정보와 Spark 3.0에서 사용하는 Java 8의 새 시간 API에서의 미묘한 동작 변경 사항에 대해서도 설명합니다.
- Spark에서 날짜 및 타임스탬프 값을 구성하는 일반적인 API입니다.
- Spark 드라이버에서 날짜 및 타임스탬프 객체를 수집하는 일반적인 함정과 모범 사례입니다.
Date 및 달력
Date의 정의는 매우 간단합니다. (year=2012, month=12, day=31)과 같이 연도, 월, 일 필드의 조합입니다. 그러나 연도, 월, 일 필드의 값에는 제약 조건이 있어 날짜 값이 실제 세계의 유효한 날짜가 되도록 합니다. 예를 들어, 월의 값은 1에서 12 사이여야 하고, 일의 값은 1에서 28/29/30/31(연도 및 월에 따라 다름) 사이여야 합니다.
이러한 제약 조건은 여러 가능한 달력 중 하나에 의해 정의됩니다. 일부는 음력 달력과 같이 특정 지역에서만 사용됩니다. 일부는 �율리우스력과 같이 역사적으로만 사용됩니다. 현재 그레고리력은 사실상의 국제 표준이며 민간 목적으로 전 세계 거의 모든 곳에서 사용됩니다. 1582년에 도입되었으며 1582년 이전 날짜도 지원하도록 확장되었습니다. 이 확장된 달력을 전향 그레고리력이라고 합니다.
버전 3.0부터 Spark는 pandas, R 및 Apache Arrow와 같은 다른 데이터 시스템에서 이미 사용 중인 전향 그레고리력을 사용합니다. Spark 3.0 이전에는 율리우스력과 그레고리력의 조합을 사용했습니다. 1582년 이전 날짜에는 율리우스력을 사용했고, 1582년 이후 날짜에는 그레고리력을 사용했습니다. 이는 1582년 이후에는 java.time.LocalDate로 대체된 레거시 java.sql.Date API에서 상속된 것으로, 이 역시 전향 그레고리력을 사용합니다.
주목할 점은 Date 유형은 시간대를 고려하지 않는다는 것입니다.
Timestamp 및 시간대
Timestamp 유형은 시간, 분, 초(소수점 부분이 있을 수 있음) 필드와 전역(세션 범위) 시간대를 추가하여 Date 유형을 확장합니다. 지구상의 특정 시간 인스턴스를 정의합니다. 예를 들어, 세션 시간대 UTC+01:00을 사용한 (year=2012, month=12, day=31, hour=23, minute=59, second=59.123456)입니다. Parquet와 같은 비텍스트 데이터 소스로 타임스탬프 값을 내보낼 때 값은 시간대 정보가 없는 인스턴스(UTC 타임스탬프와 같음)입니다. 다른 세션 시간대로 타임스탬프 값을 읽고 쓰면 시간/분/초 필드의 값이 다르게 보일 수 있지만, 실��제로는 동일한 특정 시간 인스턴스입니다.
시간, 분, 초 필드는 표준 범위: 시간은 0–23, 분과 초는 0–59입니다. Spark는 최대 마이크로초 정밀도로 소수 초를 지원합니다. 소수의 유효 범위는 0에서 999,999 마이크로초입니다.
특정 시간 인스턴스에서 시간대에 따라 다양한 벽시계 값을 관찰할 수 있습니다.
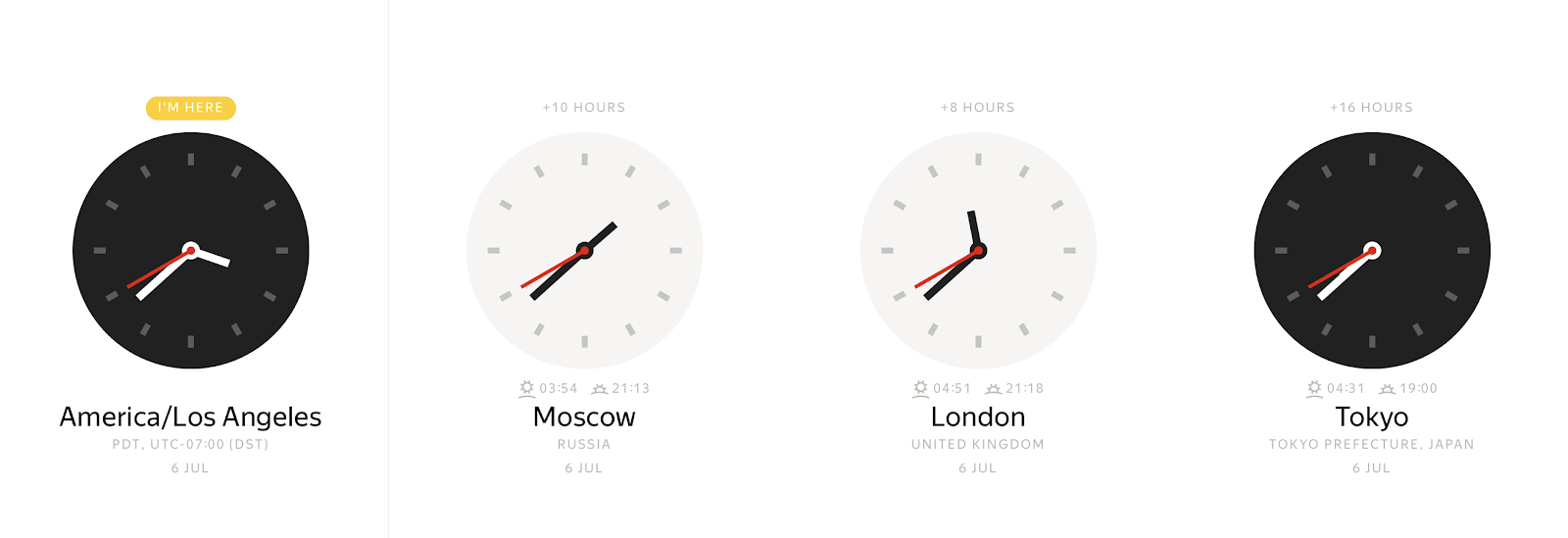
반대로 벽시계의 모든 값은 여러 다른 시간 인스턴스를 나타낼 수 있습니다. 시간대 오프셋을 사용하면 로컬 타임스탬프를 시간 인스턴스에 명확하게 바인딩할 수 있습니다. 일반적으로 시간대 오프셋은 그리니치 평균시(GMT) 또는 UTC+0(협정 세계시)에서 시간 단위의 오프셋으로 정의됩니다. 시간대 정보를 이러한 방식으로 표현하면 모호함이 제거되지만 최종 사용자에게는 불편합니다. 사용자는 America/Los_Angeles 또는 Europe/Paris와 같이 지구상의 위치를 지정하는 것을 선호합니다.
영역 오프셋에서 이러한 추가 추상화 계층은 삶을 더 쉽게 만들지만 자체적인 문제를 야기합니다. 예를 들어, 시간대 이름을 오프셋에 매핑하기 위해 특�수 시간대 데이터베이스를 유지 관리해야 합니다. Spark는 JVM에서 실행되므로 매핑을 Java 표준 라이브러리에 위임하며, 이 라이브러리는 IANA 시간대 데이터베이스(IANA TZDB)에서 데이터를 로드합니다. 또한 Java 표준 라이브러리의 매핑 메커니즘에는 Spark의 동작에 영향을 미치는 몇 가지 미묘한 차이가 있습니다. 이러한 미묘한 차이 중 일부에 대해 아래에서 집중적으로 살펴보겠습니다.
Java 8부터 JDK는 날짜-시간 조작 및 시간대 오프셋 확인을 위한 새로운 API를 노출했으며, Spark는 버전 3.0에서 이 새 API로 마이그레이션했습니다. 시간대 이름을 오프셋에 매핑하는 데 동일한 소스인 IANA TZDB를 사용하지만, Java 8 이상과 Java 7에서 구현 방식이 다릅니다.
예를 들어, 
America/Los_Angeles 시간대에서 1883년 이전의 타임스탬프인 1883-11-10 00:00:00을 살펴보겠습니다. 이 해는 다른 해와 구별되는 이유는 1883년 11월 18일에 모든 북미 철도가 새로운 표준 시간 시스템으로 전환하여 이후 시간표를 관리했기 때문입니다.
Java 7 시간 API를 사용하면 로컬 타임스탬프의 시간대 오프셋을 -08:00으로 얻을 수 있습니다.
Java 8 API 함수는 다른 결과를 반환합니다.
1883년 11월 18일 이전에는 시간은 지역적인 문제였고 대부분의 도시와 마을은 잘 알려진 시계(예: 교회 첨��탑의 시계 또는 보석상 창문의 시계)로 유지되는 지역 태양시의 형태를 사용했습니다. 그렇기 때문에 이러한 이상한 시간대 오프셋을 볼 수 있습니다.
이 예는 Java 8 함수가 더 정확하고 IANA TZDB의 과거 데이터를 고려한다는 것을 보여줍니다. Java 8 시간 API로 전환한 후 Spark 3.0은 자동으로 개선 사항의 이점을 누렸으며 시간대 오프셋을 확인하는 방식이 더 정확해졌습니다.
앞서 언급했듯이 Spark 3.0은 Date 유형에 대해서도 전향 그레고리력으로 전환했습니다. Timestamp 유형에도 동일하게 적용됩니다. ISO SQL:2016 표준은 타임스탬프의 유효 범위를 0001-01-01 00:00:00부터 9999-12-31 23:59:59.999999까지로 선언합니다. Spark 3.0은 이 표준을 완전히 준수하며 이 범위 내의 모든 타임스탬프를 지원합니다. Spark 2.4 및 이전 버전과 비교할 때 다음 하위 범위를 강조해야 합니다.
0001-01-01 00:00:00..1582-10-03 23:59:59.999999. Spark 2.4는 율리우스력을 사용하며 표준을 준수하지 않습니다. Spark 3.0은 이 문제를 해결하고 연도, 월, 일 등을 가져오는 것과 같은 타임스탬프에 대한 내부 작업에 전향 그레고리력을 적용합니다. 다른 달력으로 인해 Spark 2.4에는 있지만 Spark 3.0에는 없는 날짜가 있습니다. 예를 들어, 1000-02-29는 그레고리력에서 1000년이 윤년이 아니기 때문에 유효한 날짜가 아닙니다. 또한 Spark 2.4는 이 타임스탬프 범위에 대해 시간대 이름을 시간대 오프셋으로 잘못 확인합니다.1582-10-04 00:00:00..1582-10-14 23:59:59.999999. Spark 2.4에서는 이러한 타임스탬프가 존재하지 않았던 것과 달리 Spark 3.0에��서는 유효한 로컬 타임스탬프 범위입니다.1582-10-15 00:00:00..1899-12-31 23:59:59.999999. Spark 3.0은 위 예에서 보여준 것처럼 IANA TZDB의 과거 데이터를 사용하여 시간대 오프셋을 올바르게 확인합니다. Spark 3.0과 비교할 때 Spark 2.4는 일부 경우 시간대 이름을 시간대 오프셋으로 잘못 확인할 수 있습니다.1900-01-01 00:00:00..2036-12-31 23:59:59.999999. Spark 3.0 및 Spark 2.4 모두 ANSI SQL 표준을 따르며 월별 날짜와 같은 날짜-시간 연산에 그레고리력을 사용합니다.2037-01-01 00:00:00..9999-12-31 23:59:59.999999. Spark 2.4은 JDK 버그 #8073446으로 인해 시간대 오프셋과 특히 일광 절약 시간 오프셋을 잘못 해석할 수 있습니다. Spark 3.0은 이 결함이 없습니다.
시간대 이름을 오프셋에 매핑하는 또 다른 측면은 일광 절약 시간(DST) 또는 다른 표준 시간대 오프셋으로 전환하여 발생할 수 있는 로컬 타임스탬프의 중첩입니다. 예를 들어, 2019년 11월 3일 02:00:00에 시계가 1시간 뒤로 조정되어 01:00:00이 되었습니다. 로컬 타임스탬프 
2019-11-03 01:30:00 America/Los_Angeles는 2019-11-03 01:30:00 UTC-08:00 또는 2019-11-03 01:30:00 UTC-07:00으로 매핑될 수 있습니다. 오프셋을 지정하지 않고 시간대 이름만 설정하는 경우(예: '2019-11-03 01:30:00 America/Los_Angeles'), Spark 3.0은 일반적으로 "여름"에 해당하는 이전 오프셋을 사용합니다. 이 동작은 "겨울" 오프셋을 사용하는 Spark 2.4과 다릅니다. 간격이 있어 시계가 앞으로 점프하는 경우 유효한 오프셋이 없습니다. 일반적인 1시간 일광 절약 시간 변경의 경우 Spark는 이러한 타임스탬프를 "여름" 시간에 해당하는 다음 유효한 타임스탬프로 이동합니다.
위의 예에서 볼 수 있듯이 시간대 이름을 오프셋에 매핑하는 것은 모호하며 일대일이 아닙니다. 가능한 경우 타임스탬프를 만들 때 정확한 시간대 오프셋을 지정하는 것이 좋습니다. 예를 들어 timestamp '2019-11-03 01:30:00 UTC-07:00'입니다.
시간대 이름 대 오프셋 매핑에서 벗어나 ANSI SQL 표준을 살펴보겠습니다. 두 가지 유형의 타임스탬프를 정의합니다.
TIMESTAMP WITHOUT TIME ZONE또는TIMESTAMP- (YEAR, MONTH, DAY, HOUR, MINUTE, SECOND) 형식의 로컬 타임스탬프입니다. 이러한 종류의 타임스탬프는 시간대에 구속되지 않으며 실제로 벽시계 타임스탬프입니다.TIMESTAMP WITH TIME ZONE- (YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TIMEZONE_HOUR, TIMEZONE_MINUTE) 형식의 시간대 타임스탬프입니다. 타임스탬프는 UTC 시간대의 인스턴스에 각 값과 관련된 시간대 오프셋(시간 및 분)을 더한 값을 나타냅니다.
TIMESTAMP WITH TIME ZONE의 시간대 오프셋은 타임스탬프가 나타내는 실제 시간 지점에 영향을 미치지 않습니다. 이는 다른 타임스탬프 구성 요소에서 제공하는 UTC 시간 인스턴스로 완전히 표현되기 때문입니다. 대신 시간대 오프셋은 표시, 날짜/시간 구성 요소 추출(예: EXTRACT) 및 월을 타임스탬프에 추가하는 것과 같이 시간대를 알아야 하는 기타 작업에 대한 타임스탬프 값의 기본 동작에만 영향을 미칩니다.
Spark SQL은 타임스탬프 유형을 TIMESTAMP WITH SESSION TIME ZONE으로 정의합니다. 이는 (YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, SESSION TZ) 필드의 조합이며, YEAR부터 SECOND까지의 필드는 UTC 시간대의 시간 인스턴스를 식별하고 SESSION TZ는 SQL 구성 spark.sql.session.timeZone에서 가져옵니다. 세션 시간대는 다음과 같이 설정할 수 있습니다.
- 시간대 오프셋
'(+|-)HH:mm'. 이 형식은 물리적 시간 지점을 모호하지 않게 정의할 수 있습니다. - 지역 ID
'area/city'형식의 시간대 이름, 예를 들어'America/Los_Angeles'. 이 형식의 시간대 정보는 위에서 설명한 로컬 타임스탬프 중첩과 같은 일부 문제의 영향을 받습니다. 그러나 각 UTC 시간 인스턴스는 지역 ID를 기반으로 하는 시간대에 대해 하나의 시간대 오프셋과 모호하지 않게 연결되므로, 지역 ID 기반 시간대가 있는 각 타임스탬프는 시간대 오프셋이 있는 타임스탬프로 모호하지 않게 변환될 수 있습니다.
기본적으로 세션 시간대는 Java 가상 머신의 기본 시간대로 설정됩니다.
Spark의 TIMESTAMP WITH SESSION TIME ZONE은 다음과 다릅니다.
TIMESTAMP WITHOUT TIME ZONE과 다릅니다. 이 유형의 값은 여러 물리적 시간 인스턴스에 매핑될 수 있지만,TIMESTAMP WITH SESSION TIME ZONE의 모든 값은 구체적인 물리적 시간 인스턴스입니다. SQL 유형은 모든 세션에서 하나의 고정 시간대 오프셋을 사용하여 에뮬레이션할 수 있습니다. 예를 들어 UTC+0입니다. 이 경우 UTC의 타임스탬프를 로컬 타임스탬프로 간주할 수 있습니다.TIMESTAMP WITH TIME ZONE과 다릅니다. SQL 표준에 따라 이 유형의 열 값은 다른 시간대 오프셋을 가질 수 있습니다. Spark SQL은 이를 지원하지 않습니다.
전역(세션 범위) 시간대와 연결된 타임스탬프가 Spark SQL에서 새로 발명된 것이 아니라는 점에 유의해야 합니다. Oracle과 같은 RDBMS도 타임스탬프에 대해 유사한 유형을 제공합니다. TIMESTAMP WITH LOCAL TIME ZONE입니다.
날짜 및 타임스탬프 구성
Spark SQL은 날짜 및 타임스탬프 값을 구성하는 몇 가지 방법을 제공합니다.
- 매개변수 없는 기본 생성자:
CURRENT_TIMESTAMP()및CURRENT_DATE(). INT,LONG,STRING과 같은 다른 기본 Spark SQL 유형에서- Python
datetime또는 Java 클래스java.time.LocalDate/Instant와 같은 외부 유형에서 - CSV, JSON, Avro, Parquet, ORC 또는 기타 데이터 소스에서 역직렬화.
Spark 3.0에 도입된 MAKE_DATE 함수는 YEAR, MONTH, DAY 세 개의 매개변수를 사용하여 DATE 값을 만듭니다. 모든 입력 매개변수는 가능한 경우 암시적으로 INT 유형으로 변환됩니다. 이 함수는 결과 날짜가 Proleptic Gregorian 달력에서 유효한 날짜인지 확인하고, 그렇지 않으면 NULL을 반환합니다. 예를 들어 PySpark에서는 다음과 같습니다.
DataFrame 내용을 출력하려면 show() 작업을 호출합니다. 이 작업은 실행기에서 날짜를 문자열로 변환하고 문자열을 드라이버로 전송하여 콘솔에 출력합니다.
마찬가지로 MAKE_TIMESTAMP 함수를 통해 타임스탬프 값을 만들 수 있습니다. MAKE_DATE와 마찬가지로 날짜 필드에 대해 동일한 유효성 검사를 수행하고 추가로 시간 필드 HOUR (0-23), MINUTE (0-59) 및 SECOND (0-60)를 허용합니다. 초는 마이크로초 정밀도까지 소수 부분을 전달할 수 있으므로 SECOND는 Decimal(정밀도 = 8, 스케일 = 6) 유형입니다. 예를 들어 PySpark에서는 다음과 같습니다.
날짜의 경우와 마찬가지로 ts DataFrame의 내용을 show() 작업으로 출력해 보겠습니다. 유사한 방식으로 show()는 타임스탬프를 문자열로 변환하지만 이제 SQL 구성 spark.sql.session.timeZone에 의해 정의된 세션 시간대를 고려합니다. 다음 예에서 이를 볼 수 있습니다.
Spark는 이 날짜가 유효하지 않기 때문에(2019년은 윤년이 아님) 마지막 타임스탬프를 만들 수 없습니다.
위 예에서는 시간대 정보를 제공하지 않았다는 점을 알 수 있습니다. 이 경우 Spark는 SQL 구성 spark.sql.session.timeZone에서 시간대를 가져와 함수 호출에 적용합니다. MAKE_TIMESTAMP의 마지막 매개변수로 전달하여 다른 시간대를 선택할 수도 있습니다. 다음은 PySpark 예입니다.
보시다시피, Spark는 지정된 시간대를 고려하지만 모든 로컬 타임스탬프를 세션 시간대로 조정합니다. MAKE_TIMESTAMP 함수��에 전달된 원래 시간대는 손실됩니다. 왜냐하면 TIMESTAMP WITH SESSION TIME ZONE 타입은 모든 값이 하나의 시간대에 속한다고 가정하며, 값마다 시간대를 저장하지도 않기 때문입니다. TIMESTAMP WITH SESSION TIME ZONE의 정의에 따르면, Spark는 로컬 타임스탬프를 UTC 시간대에 저장하고, 날짜-시간 필드를 추출하거나 타임스탬프를 문자열로 변환할 때 세션 시간대를 사용합니다.
또한, LONG 타입을 캐스팅하여 타임스탬프를 생성할 수도 있습니다. LONG 컬럼이 1970-01-01 00:00:00Z 이후의 초를 포함하는 경우, Spark SQL의 TIMESTAMP로 캐스팅할 수 있습니다.
안타깝게도 이 방법으로는 초의 소수 부분을 지정할 수 없습니다. 향후 Spark SQL에서는 epoch 이후의 초, 밀리초, 마이크로초로부터 타임스탬프를 생성하는 특별한 함수인 timestamp_seconds(), timestamp_millis(), timestamp_micros()를 제공할 예정입니다.
다른 방법으로는 STRING 타입의 값으로부터 날짜와 타임스탬프를 생성하는 것입니다. 특별한 키워드를 사용하여 리터럴을 만들 수 있습니다.
또는 컬럼의 모든 값에 적용할 수 있는 캐스팅을 통해 가능합니다.
입력 타임스탬프 문자열은 지정된 시간대의 로컬 타임스탬프로 해석되거나, 입력 문자열에 시간대가 생략된 경우 세션 시간대로 해석됩니다. 특이한 패턴의 문자열은 to_timestamp() 함수를 사용하여 타임스탬프로 변환할 수 있습니다. 지원되는 패턴은 날짜-시간 형식 및 구문 분석 패턴에서 설명합니다.
패턴을 지정하지 않으면 이 함수는 CAST와 유사하게 작동합니다.
편의를 위해 Spark SQL은 문자열을 받아 타임스탬프와 날짜를 반환하는 위의 모든 메서드에서 특수 문자열 값을 인식합니다.
- epoch는 date '1970-01-01' 또는 timestamp
'1970-01-01 00:00:00Z'의 별칭입니다. - now는 세션 시간대의 현재 타임스탬프 또는 날짜입니다. 단일 쿼리 내에서는 항상 동일한 결과를 생성합니다.
- today는
TIMESTAMP타입의 경우 현재 날짜의 시작이고,DATE타입의 경우 현재 날짜입니다. - tomorrow는 타임스탬프의 경우 다음 날의 시작이고,
DATE타입의 경우 다음 날입니다. - yesterday는 현재 날짜의 하루 전 또는
TIMESTAMP타입의 경우 그 날의 시작입니다.
예를 들어:
Spark의 뛰어난 기능 중 하나는 드라이버 측의 기존 외부 객체 컬렉션에서 Datasets를 생성하고 해당 타입의 컬럼을 만드는 것입니다. Spark는 외부 타입의 인스턴스를 의미론적으로 동등한 내부 표현으로 변환합니다. PySpark를 사용하면 Python 컬렉션에서 DATE 및 TIMESTAMP 컬럼을 가진 Dataset를 생성할 수 있습니다. 예를 들어:
PySpark는 시스템 시간대를 사용하여 Python datetime 객체를 드라이버 측의 내부 Spark SQL 표현으로 변환합니다. 이 시스템 시간대는 Spark의 세션 시간대 설정 spark.sql.session.timeZone과 다��를 수 있습니다. 내부 값에는 원래 시간대에 대한 정보가 포함되지 않습니다. 병렬화된 날짜 및 타임스탬프 값에 대한 향후 작업은 TIMESTAMP WITH SESSION TIME ZONE 타입 정의에 따라 Spark SQL 세션 시간대만 고려합니다.
위에서 Python 컬렉션에 대해 보여준 것과 유사하게, Spark는 Java/Scala API에서 다음과 같은 타입을 외부 날짜-시간 타입으로 인식합니다.
- Spark SQL의 DATE 타입에 대한 외부 타입으로 java.sql.Date 및 java.time.LocalDate
- TIMESTAMP 타입에 대해 java.sql.Timestamp 및 java.time.Instant
java.sql.*와 java.time.* 타입 사이에는 차이가 있습니다. java.time.LocalDate 및 java.time.Instant는 Java 8에 추가되었으며, 이 타입들은 Spark 3.0 버전부터 Spark에서 사용하는 것과 동일한 Proleptic Gregorian 달력을 기반으로 합니다. java.sql.Date 및 java.sql.Timestamp는 그 아래에 다른 달력 시스템(1582-10-15 이후 Julian + Gregorian)을 가지고 있으며, 이는 Spark 3.0 이전 버전에서 사용하던 레거시 달력과 동일합니다. 다른 달력 시스템으로 인해 Spark는 내부 Spark SQL 표현으로 변환하는 동안 추가 작업을 수행해야 하며, 입력 날짜/타임스탬프를 한 달력에서 다른 달력으로 리베이스해야 합니다. 리베이스 작업은 1900년 이후의 최신 타임스탬프에 대해서는 약간의 오버헤드가 있으며, 오래된 타임스탬프의 경우 더 클 수 있습니다.
아래 예시는 Scala 컬렉션에서 타임스탬프를 생성하는 방법을 보여줍니다. 첫 번째 예시에서는 문자열로부터 java.sql.Timestamp 객체를 생성합니다. valueOf 메서드는 입력 문자열을 기본 JVM 시간대의 로컬 타임스탬프로 해석하는데, 이는 Spark 세션 시간대와 다를 수 있습니�다. 특정 시간대의 java.sql.Timestamp 또는 java.sql.Date 인스턴스를 생성해야 하는 경우, java.text.SimpleDateFormat (및 해당 메서드 setTimeZone) 또는 java.util.Calendar를 살펴보는 것이 좋습니다.
마찬가지로 java.sql.Date 또는 java.LocalDate 컬렉션에서 DATE 컬럼을 만들 수 있습니다. java.LocalDate 인스턴스의 병렬화는 Spark 세션 시간대나 JVM 기본 시간대와 완전히 독립적이지만, java.sql.Date 인스턴스의 병렬화에 대해서는 그렇게 말할 수 없습니다. 몇 가지 주의할 점이 있습니다.
java.sql.Date인스턴스는 드라이버의 기본 JVM 시간대에서 로컬 날짜를 나타냅니다.- Spark SQL 값으로 올바르게 변환하려면 드라이버와 실행기의 기본 JVM 시간대가 동일해야 합니다.
달력 및 시간대 관련 문제를 피하려면 Java/Scala 컬렉션의 타임스탬프 또는 날짜 병렬화 시 외부 타입으로 Java 8 타입인 java.LocalDate/Instant를 사용하는 것이 좋습니다.
날짜 및 타임스탬프 수집
병렬화의 반대 작업은 실행자로부터 드라이버로 날짜와 타임스탬프를 수집하여 외부 타입의 컬렉션을 반환하는 것입니다. 위 예시에서 collect() 액션을 통해 DataFrame을 드라이버로 다시 가져올 수 있습니다.
Spark는 실행기(executor)에서 드라이버로 날짜 및 타임스탬프 열의 내부 값을 UTC 시간대의 시간 인스턴트로 전송하고, Spark SQL 세션 시간대를 사용하지 않고 드라이버에서 시스템 시간대로 Python datetime 객체로 변환합니다. collect()는 이전 섹션에서 설명한 show() 액션과 다릅니다. show()는 타임스탬프를 문자열로 변환할 때 세션 시간대를 사용하고, 결과 문자열을 드라이버에 수집합니다.
Java 및 Scala API에서 Spark는 기본적으로 다음 변환을 수행합니다:
- Spark SQL의
DATE값은java.sql.Date인스턴스로 변환됩니다. - 타임스탬프는
java.sql.Timestamp인스턴스로 변환됩니다.
이 두 변환은 드라이버의 기본 JVM 시간대에서 수행됩니다. 따라서 Date.getDay(), getHour() 등과 Spark SQL 함수 DAY, HOUR를 통해 얻을 수 있는 것과 동일한 날짜-시간 필드를 얻으려면 드라이버의 기본 JVM 시간대와 실행기의 세션 시간대가 동일해야 합니다.
java.sql.Date/Timestamp에서 날짜/타임스탬프를 만드는 것과 유사하게, Spark 3.0은 Proleptic Gregorian 달력에서 하이브리드 달력(Julian + Gregorian)으로 리베이스를 수행합니다. 이 작업은 최신 날짜(1582년 이후) 및 타임스탬프(1900년 이후)의 경우 거의 무료이지만, 오래된 날짜 및 타임스탬프의 경우 약간의 오버헤드가 발생할 수 있습니다.
이러한 달력 관련 문제를 피하고 Spark가 Java 8 이후에 추가된 java.time 유형을 반환하도록 요청할 수 있습니다. SQL 구성 spark.sql.datetime.java8API.enabled를 true로 설정하면 Dataset.collect() 액션은 다음을 반환합니다:
- Spark SQL의
DATE유형의 경우java.time.LocalDate - Spark SQL의
TIMESTAMP유형의 경��우java.time.Instant
이제 Java 8 유형과 Spark SQL 3.0 모두 Proleptic Gregorian 달력을 기반으로 하므로 변환 시 달력 관련 문제가 발생하지 않습니다. collect() 액션은 더 이상 기본 JVM 시간대에 의존하지 않습니다. 타임스탬프 변환은 시간대에 전혀 의존하지 않습니다. 날짜 변환의 경우 SQL 구성 spark.sql.session.timeZone의 세션 시간대를 사용합니다. 예를 들어, DATE 및 TIMESTAMP 열이 있는 Dataset을 살펴보고 기본 JVM 시간대를 Europe/Moscow로 설정하지만 세션 시간대는 America/Los_Angeles로 설정해 보겠습니다.
show() 액션은 세션 시간인 America/Los_Angeles에서 타임스탬프를 출력하지만, Dataset을 수집하면 java.sql.Timestamp로 변환되어 toString 메서드에 의해 Europe/Moscow에서 출력됩니다:
실제로 로컬 타임스탬프 2020-07-01 00:00:00은 UTC에서 2020-07-01T07:00:00Z입니다. Java 8 API를 활성화하고 Dataset을 수집하면 이를 확인할 수 있습니다:
java.time.Instant 객체는 전역 JVM 시간대와 독립적으로 나중에 모든 로컬 타임스탬프로 변환될 수 있습니다. 이것이 java.time.Instant가 java.sql.Timestamp보다 유리한 점 중 하나입니다. 전자는 전역 JVM 설정을 변경해야 하며, 이는 동일한 JVM의 다른 타임스탬프에 영향을 미칩니다. 따라서 애플리케이션이 다른 시간대의 날짜 또는 타임스탬프를 처리하고 애플리케이션이 Java/Scala Dataset.collect() API를 통해 드라이버로 데이터를 수집하는 동안 서로 충돌해서는 안 되는 경우, SQL 구성 spark.sql.datetime.java8API.enabled를 사용하여 Java 8 API로 전환하는 것이 좋습니다.
결론
이 블로그 게시물에서는 Spark SQL DATE 및 TIMESTAMP 유형에 대해 설명했습니다. 다른 기본 Spark SQL 유형 및 외부 Java 유형에서 날짜 및 타임스탬프 열을 구성하는 방법과 날짜 및 타임스탬프 열을 외부 Java 유형으로 드라이버에 수집하는 방법을 보여주었습니다. 버전 3.0부터 Spark는 Julian 및 Gregorian 달력을 결합한 하이브리드 달력에서 Proleptic Gregorian 달력으로 전환했습니다(자세한 내용은 SPARK-26651 참조). 이를 통해 Spark는 이전에 보여드린 많은 문제를 해결할 수 있었습니다. 이전 버전과의 호환성을 위해 Spark는 여전히 collect와 같은 액션에서 하이브리드 달력(java.sql.Date 및 java.sql.Timestamp)으로 타임스탬프와 날짜를 반환합니다. Java/Scala의 collect 액션을 사용할 때 달력 및 시간대 확인 문제를 피하려면 SQL 구성 spark.sql.datetime.java8API.enabled를 통해 Java 8 API를 활성화할 수 있습니다. Databricks Runtime 7.0의 일부로 Databricks에서 오늘 무료로 사용해 보세요.

O'Reilly Learning Spark Book
무료 2판에는 새로운 Pandas UDF용 Python 유형 힌트, 새로운 날짜/시간 구현 등을 포함하여 Spark 3.0 업데이트가 포함되어 있습니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.