Delta Lake의 변경 데이터 피드로 CDC를 간소화하는 방법
Databricks에서 이 노트북을 사용해 보세요
변경 데이터 캡처(CDC) 는 많은 고객이 Databricks에서 구현하는 사용 사례이며,
이 주제에 대한 이전 심층 분석 은 여기에서 확인할 수 있습니다. 일반적으로 CDC는
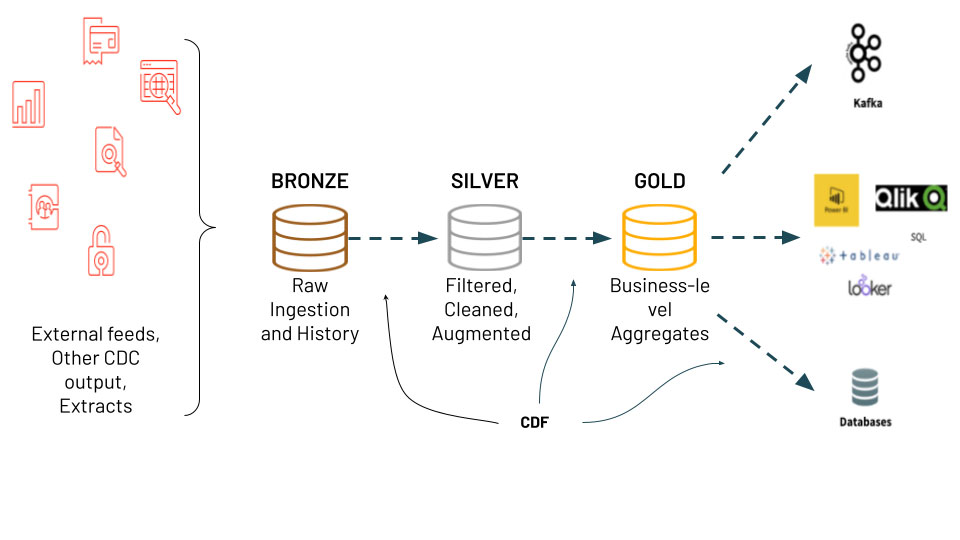
medallion 아키텍처라고 하는 분석 아키텍처에 대한 수집에 사용됩니다.
소스 시스템에서 가져온 가공되지 않은 데이터를 가져와서 브론즈, 실버, 골드
테이블을 통해 데이터를 구체화하는 medallion 아키텍처입니다.
CDC 및 medallion 아키텍처는 변경되거나 추가된 데이터만 처리하면 되므로
사용자에게 여러 가지 이점을 제공합니다. 또한 아키텍처의 서로 다른 테이블을 통해
데이터 사이언티스트 및 BI 애널리스트와 같은 다양한 가상 사용자가 필요에 맞는 올바른
최신 데이터를 사용할 수 있습니다. 이 아키텍처를 더 간단하게 구현하고 Delta Lake의
MERGE 운영 및 로그 버전 관리를 가능하게 하는 Delta Lake의 흥미로운 새로운
CDF(변경 데이터 피드) 기능을 발표하게 되어 기쁩니다!
Delta Lake 사용을 시작하는 데 필요한 단계별 지침을 보려면 O'Reilly의 새로운 ebook
미리 보기를 확인하세요.
CDF 기능이 필요한 이유는 무엇입니까?
다른 빅데이터 기술에 비해 Delta Lake로 구현하는 것이 더 간단하기 때문에 많은 고객이
Databricks를 사용하여 CDC를 수행합니다. 그러나 올바른 도구를 사용하더라도 CDC는
여전히 실행하기 어려울 수 있습니다. CDF는 코딩을 더욱 간단하게 만들고 다음과 같은
CDC의 가장 큰 문제점을 해결하기 위해 설계했습니다.
- 품질 관리 - 버전 간에 행 수준 변경을 수행하기가 어렵습니다.
- 비효율성 - 현재 버전 변경 내용이 행 수준이 아닌 파일에 있으므로 변경되지 않는
행을 고려하는 것은 비효율적일 수 있습니다.
CDF(변경 데이터 피드) 구현이 위의 문제를 해결하는 데 도움이 되는 방법은 다음과 같습니다.
- 단순성 및 편의성 - 변경 사항을 식별하기 위해 일반적이고 사용하기 쉬운 패턴을 사용하여
코드를 간단하고 편리하며 이해하기 쉽게 만듭니다. - 효율성 - 버전 간에 변경된 행만 가질 수 있는 기능은 Merge, Update 및 Delete 운영의
다운스트림 사용을 매우 효율적으로 만듭니다.
CDF는 테이블 에서만 변경 사항을 캡처하며 활성화된 후 Delta 에만 미래 지향적입니다.
Change Data Feed의 작동 방식!
일반적인 사용 사례인 재무 예측에 대한 CDF의 예를 살펴보겠습니다.
이 블로그의 맨 위에 참조된 노트북은 재무 데이터를 수집합니다.
추정 주당순이익(EPS)은 회사의 분기별 주당순이익을 예측하는
애널리스트의 재무 데이터입니다. 가공되지 않은 데이터는 다양한 소스와
여러 주식에 대한 여러 애널리스트로부터 가져올 수 있습니다.
CDF 기능을 사용하면 데이터가 브론즈 테이블에 삽입(원시 수집)된 다음 실버 테이블에서
필터링, 정리 및 보강되고, 마지막으로 실버 테이블의 변경된 데이터를 기반으로 골드 테이블에
집계 값이 compute 됩니다.
이러한 변환은 복잡해질 수 있지만, 다행히도 이제 행 기반 CDF 기능은 간단하고 효율적입니다.
하지만 어떻게 사용합니까? 파헤쳐 보자!
참고: 이 예제는 CDF의 SQL 버전과 운영을 사용하는 특정 방법에 중점을 두고 있으며,
변형을 평가하려면 여기 설명서를 참조하십시오.
Delta Lake Table에서 CDF 사용
테이블에서 CDF 기능을 사용할 수 있도록 하려면 먼저 해당 테이블에서 기능을
활성화해야 합니다. 다음은 테이블 생성 시 브론즈 테이블에 대해 CDF를 활성화하는
예입니다. 테이블에 대한 업데이트로 테이블에서 CDF를 활성화할 수도 있습니다.
또한 clusters 에서 만든 모든 테이블에 대해 clusters에서 CDF를 활성화할 수 있습니다. 이러한 변형에 대해서는 여기에서 설명서를 참조하세요.

테이블 속성이 설정되고 이전이 아닌 후에 변경 내용을 캡처합니다
변경 데이터 쿼리
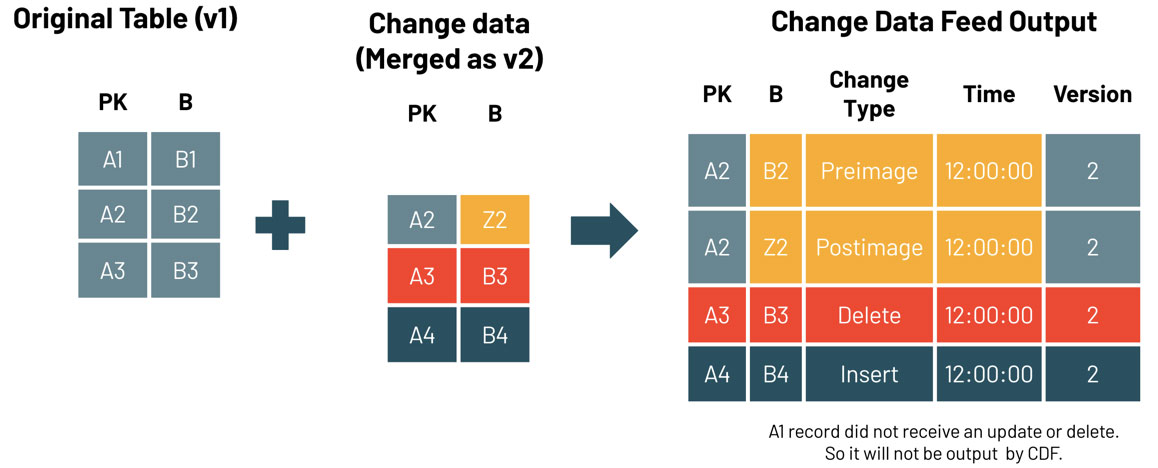
변경 사항을 query 하려면 데이터를 사용하여 table_changes 운영.
아래 예제에는 삽입된 행과 업데이트된 행의 사전 및 사후 이미지를 나타내는
두 개의 행이 포함되어 있으므로 필요한 경우 변경 내용의 차이점을 평가할 수 있습니다.
삭제된 행에 대해 반환되는 삭제 변경 유형도 있습니다.
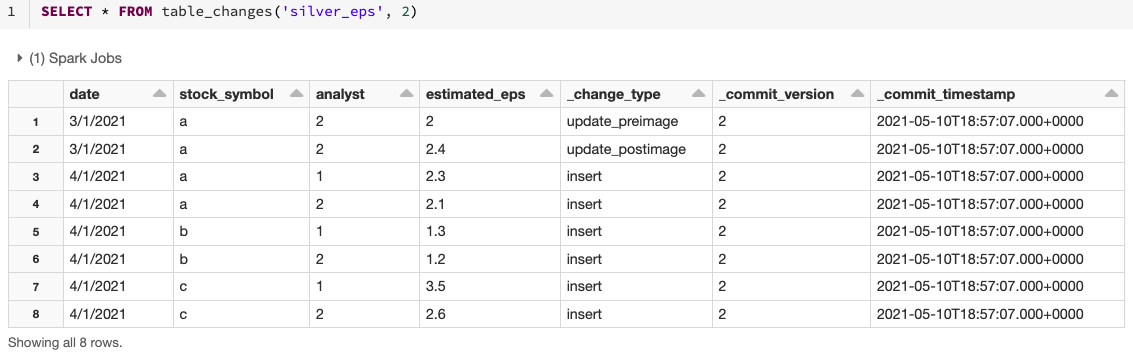
이 예제에서는 시작 버전을 기준으로 변경된 레코드에 액세스하지만, 필요한 경우 시작 및 종료
타임스탬프 를 기준으로 버전을 제한할 수도 있습니다. 이 예제는 SQL에 중점을 두지만
Python, Scala, Java 및 R에서 이 데이터에 액세스하는 방법도 있습니다.
이러한 변형에 대해서는 여기에서 설명서를 참조하세요.
MERGE문에서 CDF 행 데이터 사용
골드 테이블로의 병합과 같은 집계 MERGE 문은 본질적으로 복잡할 수 있지만
CDF 기능을 사용하면 이러��한 문을 더 간단하고 효율적으로 코딩할 수 있습니다.
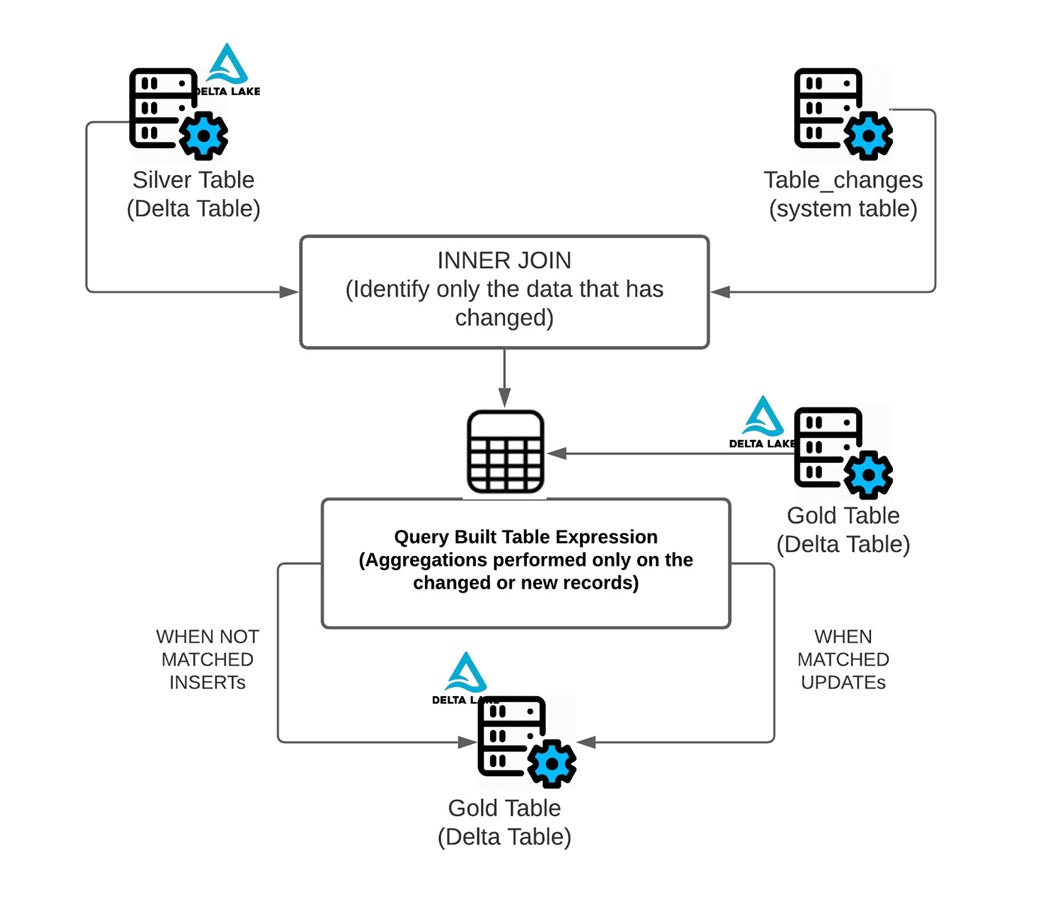
위의 다이어그램에서 볼 수 있듯이 CDF는 table_changes 운영을 사용하여 변경되었거나
새로 추가된 데이터에 대해 필요한 집계만 수행하므로 변경된 행을 쉽게 도출할 수 있습니다 .
아래에서 변경된 데이터를 사용하여 변경된 날짜 및 주식 기호를 확인하는 방법을 확인할 수 있습니다.
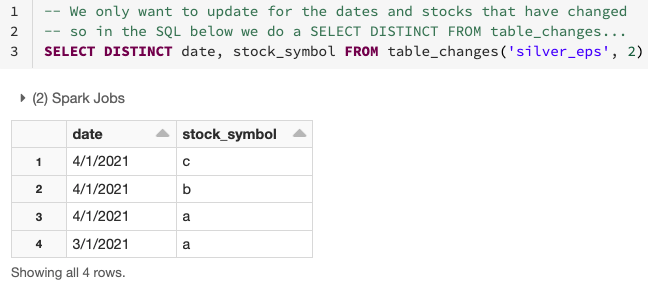
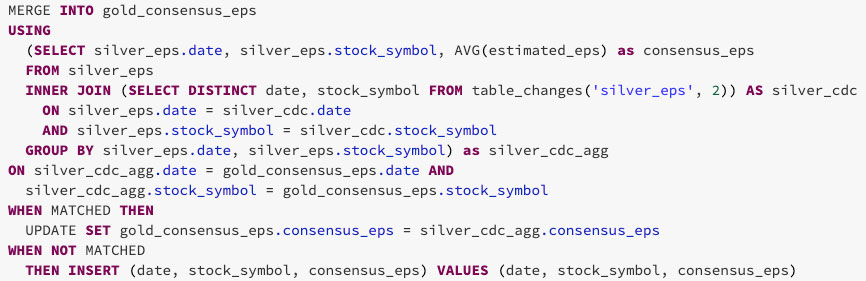
아래와 같이 실버 테이블에서 변경된 데이터를 사용하여 골드 테이블에 업데이트하거나
삽입해야 하는 행의 데이터만 집계할 수 있습니다. 이렇게 하려면 table_changes( ' table_name ' , 'version')에서 INNER JOIN을 사용합니다.
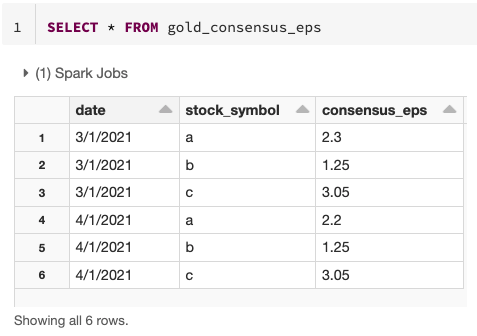
최종 결과는 시간이 지남에 따라 점진적으로 변경될 수 있는
골드 테이블의 명확하고 간결한 버전입니다!
일반적인 사용 사례
다음은 새로운 CDF 기능의 몇 가지 일반적인 사용 사례와 이점입니다.
실버 & 골드 테이블
ETL/ELT 운영을 가속화하고 단순화하기 위해 초기 MERGE 비교 후 변경 사항만 처리하여 Delta 성능을 개선합니다.
구체화 뷰
BI 및 분석에서 사용할 수 있도록 집계된 최신 정보 보기를 생성하고, 대신 전체 기본 테이블을
다시 처리할 필요 없이 변경 사항이 적용된 위치만 업데이트할 수 있습니다.
변경 내용 전송
변경 데이터 피드를 Kafka 또는 RDBMS와 같은 다운스트림 시스템으로 전송하여
데이터 파이프라인의 이후 단계에서 증분 처리하는 데 사용할 수 있습니다.
감사 추적 테이블
변경 데이터 피드 출력을 Delta 테이블로 캡처하면 영구 스토리지와 효율적인 query
기능을 제공하여 삭제가 발생한 시기 및 업데이트된 내용을 포함하여 시간 경과에 따른 모든 변경 내용을 볼 수 있습니다.
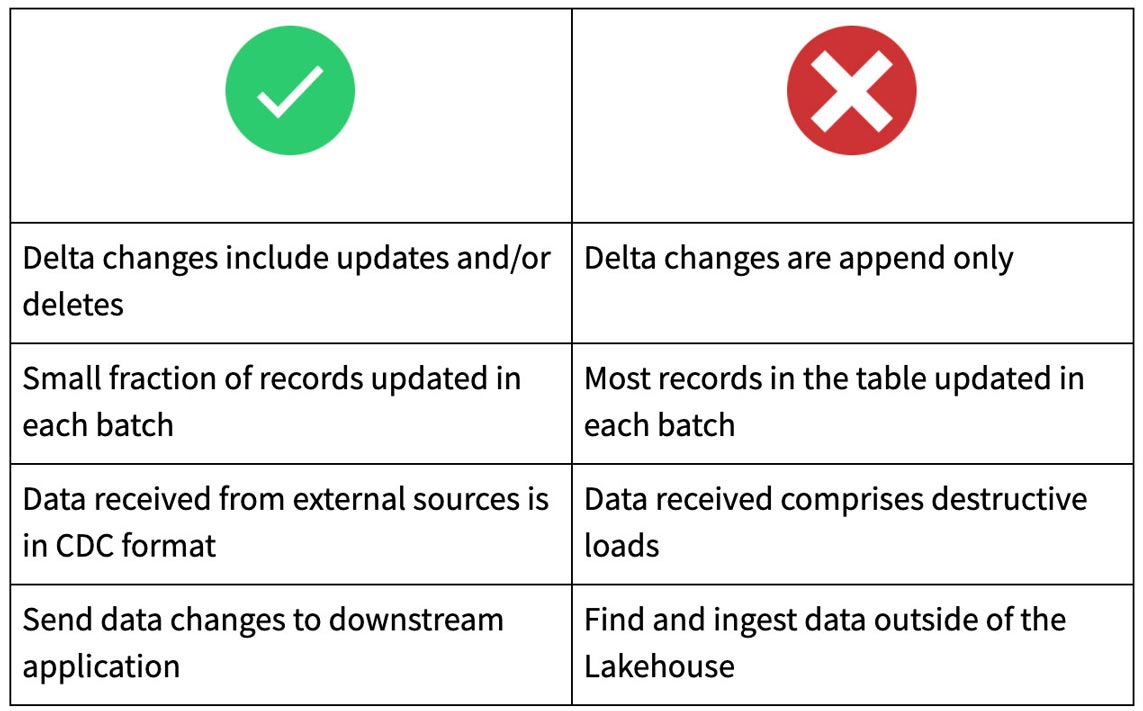
변경 데이터 피드를 사용하는 경우
결론
Databricks는 불가능을 가능하게, 어려운 것을 단순하게 만들기 위해 노력합니다. CDC,
로그 버전 관리 및 MERGE 구현은 Delta Lake가 생성되기 전까지는 대규모로 사실상 불가능했습니다. 이제 흥미로운 변경 데이터 피드(CDF) 기능을 통해 더 간단하고 효율적으로 만들 수 있습니다!
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.