Databricks, 공식 데이터 웨어하우징 성능 신기록 달성
작성자: Reynold Xin , 모스타파 목타르
(원문 보기)
오늘, Databricks SQL이 데이터 웨어하우징의 표준 성능 벤치마크인 100TB TPC-DS에서 신기록을 달성했음을 알려드립니다. Databricks SQL이 이전 기록보다 2.2배 향상되었습니다. 대부분의 다른 벤치마크 뉴스와는 달리 이 결과는 TPC 위원회에서 감사하고 검토를 마쳤습니다.
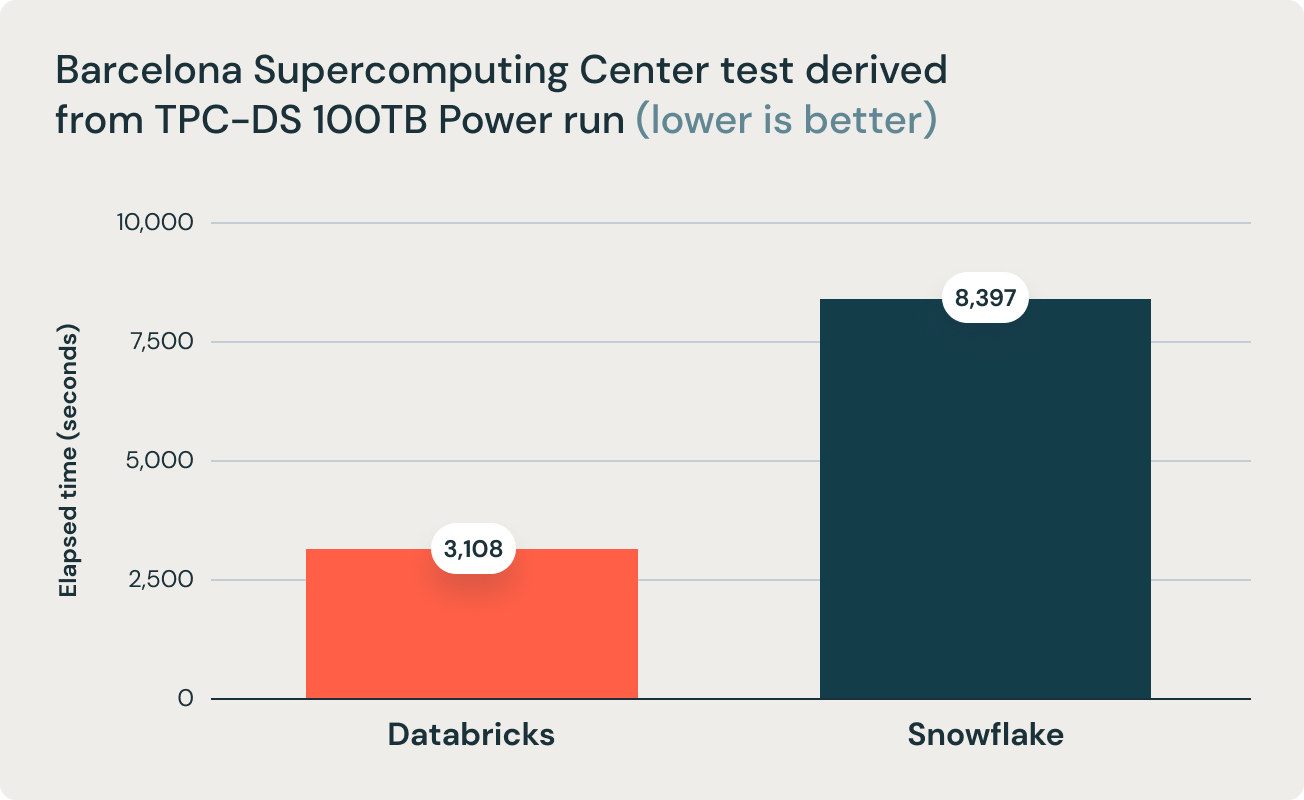
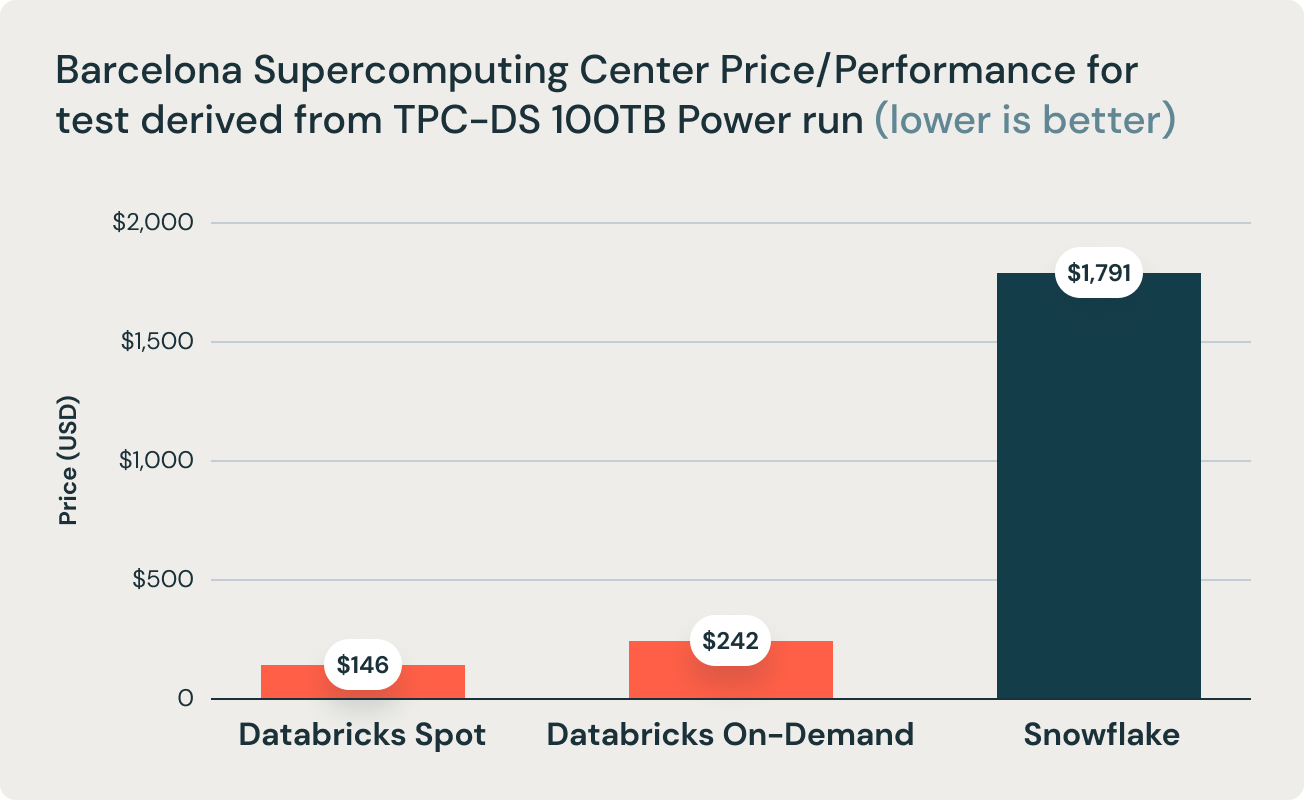
These results were corroborated by research from Barcelona Supercomputing Center, which frequently runs benchmarks that are derivative of TPC-DS on popular data warehouses. Their latest research benchmarked Databricks and Snowflake, and found that Databricks was 2.7x faster and 12x better in terms of price performance. This result validated the thesis that data warehouses such as Snowflake become prohibitively expensive as data size increases in production.
Databricks는 데이터 레이크에서 직접 완전한 데이터 웨어하우징 기술을 빠르게 개발함으로써, 데이터 레이크하우스라는 데이터 아키텍처 하나에 두 가지의 장점을 모두 결합했습니다. 2020년 11월에 데이터 웨어하우징 기능 일체를 Databricks SQL라는 이름으로 출시했습니다. 그 이후로 레이크하우스 기반의 개방적 아키텍처가 기존 데이터 웨어하우스의 성능, 속도, 비용을 제공할 수 있는지 의문이 있었습니다. 레이크하우스 아키텍처가 실현 가능한 목표라는 것을 여실히 보여주는 결과입니다.
단지 결과를 공유하는 데 그치지 않고 이 기회를 빌려 레이크하우스 아키텍처의 성능을 이 수준으로 끌어올리기 위해 어떤 노력을 기울였는지 스토리를 공유하고자 합니다. 하지만 먼저 결과부터 설명하겠습니다.
TPC-DS 신기록
Databricks SQL은 32,941,245 QphDS @ 100TB를 달성했습니다. Alibaba의 맞춤형 시스템(14,861,137 QphDS @ 100TB)이 세웠던 기록을 2.2배나 넘어서는 것입니다. (Alibaba는 세계 최대 규모의 전자상거래 플랫폼을 지원하는 엄청난 시스템을 보유하고 있습니다.) Databricks SQL은 이전 기록을 큰 폭으로 향상했을 뿐만 아니라, 총소유비용까지 10%나 낮추었습니다(할인을 적용하지 않은 공식 정가 기준).
QphDS 단위를 몰라도 괜찮습니다. (저희도 공식을 봐야 겨우 알 수 있습니다.) QphDS는 TPC-DS에서 사용하는 기본 지표로, (1) 데이터 세트 로딩, (2) 쿼리 시퀀스 처리(파워 테스트), (3) 다수의 동시 쿼리 스트림 처리(처리량 테스트), (4) 데이터를 입력하고 삭제하는 데이터 유지관리 함수 실행을 포함한 여러 가지 워크로드의 성능을 나타냅니다.
The aforementioned conclusion is further supported by the research team at Barcelona Supercomputing Center (BSC) that recently ran a different benchmark derived from TPC-DS comparing Databricks SQL and Snowflake, and found that Databricks SQL was 2.7x faster than a similarly sized Snowflake setup.
TPC-DS란 무엇인가요?
TPC-DS는 TPC(Transaction Processing Performance Council)에서 정의한 데이터 웨어하우징 벤치마크입니다. TPC는 80년대 말에 데이터베이스 커뮤니티에서 시작한 비영리 조직으로, 실제 시나리오를 에뮬레이션하는 벤치마크를 만들어서 데이터베이스 시스템 성능을 객관적으로 측정하는 데 사용하도록 합니다. TPC는 데이터베이스 분야에 큰 영향을 미쳤습니다. 이 분야는 Oracle, Microsoft, IBM 등의 기존 공급업체 사이에서 10여 년간 '벤치마크 전쟁'이 벌어져 큰 발전을 이루었습니다.
TPC-DS에서 'DS'는 '결정 지원'을 나타냅니다. 여기에는 매우 간단한 집계에서부터 복잡한 패턴 마이닝까지 복잡성이 다양한 99개 쿼리가 포함됩니다. 점점 복잡해지는 분석을 반영한 (2000년대 중반에 시작된) 비교적 새로운 벤치마크입니다. 최근 10년 사이에 TPC-DS는 사실상 모든 공급업체가 도입한 표준 데이터 웨어하우징 벤치마크로 자리 잡았습니다.
그러나 복잡성으로 인해 많은 데이터 웨어하우스 시스템, 심지어 매우 유명한 공급업체에서 구축한 시스템조차도 자사 시스템이 우수한 성능을 내도록 공식 벤치마크를 조정했습니다. (롤업 등의 특정 SQL 기능을 제거하거나, 데이터 분포를 변경해 왜곡을 제거하는 등의 조정이 일반적입니다.) 그래서 인터넷에 TPC-DS에 대한 자료가 400만 페이지 이상 떠돌아 다니는 데도 불구하고 공식 TPC-DS 벤치마크에 제출되는 자료는 매우 적은 편입니다. 또한, 이런 조정으로 인해 대부분 공급업체가 자체 벤치마크를 기준으로 경쟁사보다 우수한 것처럼 보이게 됩니다.
Databricks는 어떻게 했을까요?
앞서 말씀드렸듯이, Databricks SQL가 SQL 성능에서 데이터 웨어하우스보다 뛰어난 성능을 발휘할 수 있을지 알기 어려웠습니다. 대부분의 문제는 다음의 4가지 이슈로 귀결됩니다.
- 데이터 웨어하우스는 독점적 데이터 형식��을 사용하기 때문에 매우 빠르게 발전할 수 있지만, Databricks(Lakehouse 기반)는 오픈 형식(예: Apache Parquet, Delta Lake)을 사용해서 그만큼 빠르게 변경할 수 없습니다. 그래서 기본적으로 EDW가 우위에 서게 됩니다.
- 우수한 SQL 성능에는 MPP(대규모 병렬 처리) 아키텍처가 필요하지만, Databricks와 Apache Spark는 MPP가 아닙니다.
- 본래 처리량과 지연 사이에는 상충 관계가 존재해서 시스템은 대량의 쿼리를 처리하거나(처리량 중심), 소량의 쿼리를 처리할 수는 있어도(지연 중심) 두 가지 모두는 불가능했습니다. Databricks는 대량 쿼리에 초점을 맞추기 때문에 소량 쿼리에서는 성능이 떨어질 수밖에 없었습니다.
- 소량 쿼리를 처리할 수 있다고 하더라도 데이터 웨어하우스 시스템을 구축하는 데 10여 년이 필요하다는 것이 일반적 생각이었습니다. 빠르게 발전할 방법은 없었습니다.
이제 나머지 블로그 게시물에서는 그 내용을 하나씩 설명할 것입니다.
독점적 형식 vs 개방적 데이터 형식
Lakehouse 아키텍처의 핵심적 원칙은 오픈 스토리지 형식입니다. '개방성'은 공급업체 종속 효과를 없애줄 뿐만 아니라 공급업체와 관계없이 도구 에코시스템을 독립적으로 개발할 수 있습니다. 오픈 형식의 주요 특징 중 하나가 표준화입니다. 이런 표준화 덕분에 대부분 엔터프라이즈 데이터가 오픈 데이터 레이크에 저장되고 Apache Parquet는 명실상부한 데이터 저장의 표준이 되었습니다. Databricks는 데이터 웨어하우스 등급 성능을 개방적 형식에 적용함으로써 데이터 이동을 최소화하고 BI 및 AI 워크로드에 대한 데이터 아키텍처를 단순화하고자 했습니다.
'개방성'에 대해 주로 지적하는 단점은 개방적 형식을 변경하기 어렵고, 따라서 개선도 어렵다는 것입니다. 이론적으로는 이 주장에 일리가 있지만 실제로 꼭 그런 것은 아닙니다.
첫째, 개방적 형식도 충분히 발전할 수 있습니다. 대규모 데이터 스토리지에 가장 많이 사용하는 개방적 형식인 Parquet는 여러 번의 반복을 거친 개선을 했습니다. Databricks에서 Delta Lake를 도입한 이유는 Parquet 계층에서 실행하기 어려운 추가적 기능을 도입하기 위해서이기도 했습니다. Delta Lake는 Parquet에 추가적 인덱싱과 통계를 제공했습니다.
둘째, Databricks 시스템은 개체 스토어를 로컬 NVMe SSD로 로드할 때 원본 Delta Lake 및 Parquet 데이터를 자동으로 변환합니다(사용자 개입 없음). 따라서 추가적인 최적화가 가능합니다.
그러나 Delta Lake 및 Parquet는 데이터 웨어하우스에서 사용하는 독점적 형식과 비교했을 때 대부분 데이터 웨어하우징 워크로드에 대해 이미 충분한 최적화를 제공하고 있습니다. 이러한 워크로드의 경우, 최적화 기회는 주로 더 많은 데이터를 빠르게 스캔하는 것이 아니라, 쿼리를 더욱 빠르게 처리하는 데서 비롯됩니다. 사실, TPC-DS의 경우 더욱 최적화된 내부 형식으로 캐싱된 데이터를 쿼리하는 것은 S3에서 콜드 데이터를 쿼리하는 것보다 불과 10% 빠를 뿐입니다(벤치마크 데이터 웨어하우스와 Databricks 모두에서 이 사실을 확인했습니다).
MPP 아키텍처
일반적으로 데�이터 웨어하우스가 SQL 성능에 좋은 MPP 아키텍처를 사용하고 Databricks는 그렇지 않다는 오해를 합니다. MPP 아키텍처는 여러 개의 노드를 활용해서 하나의 쿼리를 처리하는 능력을 나타냅니다. Databricks SQL이 바로 그런 식으로 설계되었습니다. Apache Spark가 아니라 Photon(현대적 SIMD 하드웨어를 위해 C++로 처음부터 구축하여 완전히 새롭게 작성한 엔진)에 기반하므로, 대량의 병렬 쿼리 처리가 가능합니다. 따라서 Photon은 MPP 엔진입니다.
처리량 vs. 지연의 상충 관계
처리량과 지연은 컴퓨터 시스템에서 원래부터 존재하던 상충 관계로, 시스템은 높은 처리량과 낮은 지연을 동시에 달성할 수 없다는 의미입니다. 설계에서 처리량(예: 데이터 일괄 처리)을 우선할 경우 지연이 커집니다. 데이터 시스템에서는 시스템이 대량의 쿼리와 소량의 쿼리를 동시에 효율적으로 처리할 수 없다는 의미입니다.
이런 상충 관계가 존재한다는 것은 부인하지 않겠습니다. 사실, 우리 기술 설계 문서에서도 자주 등장하는 문제입니다. 하지만 Databricks나 다른 인기 있는 웨어하우스를 비롯한 첨단 시스템은 처리량과 지연 면에서 최적화가 많이 발전했습니다.
따라서 처리량과 지연을 동시에 개선할 수 있는 새로운 설계와 구현을 개발하는 것도 꿈이 아닙니다. Databricks는 바로 그런 방식으로 최근 2년 동안 모든 주요 지원 기술을 구축했습니다. Photon, Delta Lake 등의 첨단 기술로 대량 및 소량 쿼리의 성능을 개선하였고 새로운 성능 기록을 세울 수 있는 밑받침이 되었습니다.
시간과 집중
마지막으로, 데이터베이스 시스템이 안정화되려면 적어도 10년은 걸리는 것이 상식입니다. Databricks는 최근 레이크하우스(SQL 워크로드 지원 목적)에 초점을 맞추었기 때문에 SQL이 적절한 성능을 내려면 추가적인 노력이 필요했습니다. 맞는 이야기이기는 하지만, Databricks에서 어떻게 예상보다 빠르게 목표를 달성할 수 있었는지 설명하겠습니다.
무엇보다도 이런 투자가 1~2년 전에 시작된 것은 아닙니다. Databricks를 인수한 이후로 Databricks의 AI 워크로드에도 도움이 될 SQL 워크로드를 지원하는 다양한 기반 기술에 투자를 했습니다. 여기에는 완전한 기능을 갖춘 비용 기반 쿼리 최적화 도구, 네이티브 벡터화 실행 엔진, window 함수와 같은 다양한 기능이 포함됩니다. Databricks의 워크로드 대부분은 Spark DataFrame API 덕분에 이런 기술을 통해 실행되며, SQL 엔진으로 매핑되어서 몇 년 간 테스트와 최적화를 거쳤습니다. 대신 Databricks는 SQL 워크로드에 대한 집중을 줄였습니다. 최근 레이크하우스에 대한 비중을 높인 이유는 Databricks의 고객이 데이터 아키텍처를 단순화하기를 원했기 때문입니다.
둘쨰, SaaS 모델이 소프트웨어 개발 사이클을 단축했습니다. 예전에는 대부분 공급업체의 릴리스 사이클은 1년이었고 고객이 소프트웨어를 설치하고 도입하기까지는 추가로 몇 년의 간격이 필요했습니다. SaaS에서 Databricks 엔지니어링팀은 며칠 내로 새로운 설계를 개발해서, 구현하고, 일부 고객에게 릴리스합니다. 이렇게 개발 주기가 단축된 덕분에 피드백을 빨리 받고, 빠르게 혁신할 수 있었습니다.
셋째, Databricks는 훨씬 더 많은 경영진의 관심과 자본을 모두 이 문제에 집중할 수 있었습니다. 예전에는 새로운 데이터 웨어하우스 시스템을 구축하는 작업은 스타트업이 진행하거나 대기업 내에 새로운 팀을 꾸려서 진행했습니다. Databricks만큼 충분한 자금력을 갖추고($35억 이상 출자) 아키텍처 구축에 필요한 인재를 유치할 역량을 지닌 데이터베이스 스타트업은 존재하지 않았습니다. 대기업 내의 새로운 노력은 그저 노력을 추가할 뿐이고, 경영진에게 온전한 관심을 받기 어렵습니다.
Databricks의 상황은 특별합니다. Databricks는 처음에는 데이터 웨어하우징이 아니라 공통적인 기술 문제를 공유하는 관련 분야(데이터 사이언스와 AI)에 대한 사업을 설립하는 데 치중했습니다. 이렇게 초기에 성공을 거둔 덕분에 유례없이 공격적으로 SQL 팀을 구축할 자금을 마련할 수 있었고, 광범위한 데이터 웨어하우스 지식을 갖춘 팀을 구성했습니다. 다른 기업에서 달성하려면 10년은 족히 걸렸을 만한 성과입니다. 그중에는 Amazon Redshift; Google BigQuery, F1(Google 내부 데이터 웨어하우스 시스템), Procella(Youtube 내부 데이터 웨어하우스 시스템), Oracle, IBM DB2, Microsoft SQL Server 등의 가장 성공적인 데이터 시스템에서 일한 수석 엔지니어와 설계자도 있습니다.
요컨대 SQL 성능을 우수하게 높이려면 여러 해가 걸립니다. Databricks는 우리 회사의 독특한 상황을 이용해 그 기간을 단축했을 뿐만 아니라 이 계획을 광고할 수단이 없던 시절에 이미 투자를 시작했습니다.
실제 고객 워크로드
고객 여러분이 벤치마크 결과를 검증해주신 것에 감사드립니다. 5,000개 이상의 글로벌 조직이 Databricks 레이크하우스 플랫폼을 활용하여 세계적인 난제를 해결하고 있습니다. 예를 들어, 다음과 같은 사례가 있습니다.
- Bread Finance는 빅데이터 사용 사례(예: 재무 보고, 사기 탐지, 신용 위험, 손실 추정, 완전한 퍼널 추천 엔진)를 적용한 기술 중심 결제 플랫폼입니다. 이들은 Databricks 레이크하우스 플랫폼을 사용하고 나서 야간에 하던 일괄 작업을 거의 실시간에 가까운 입력으로 바꾸었고, 데이터 처리 시간을 90% 단축했습니다. 게다가 이 데이터 블랫폼은 약 1.5배의 비용만으로 데이터 볼륨을 140% 확장할 수 있습니다.
- Shell은 레이크하우스 플랫폼을 사용하여 수백 명의 데이터 애널리스트가 표준 BI 도구로 페타바이트 규모의 데이터 세트에 대해 쿼리를 빠르게 실행합니다. 데이터 애널리스트들에게는 '혁신적 도구'로 찬사를 받고 있습니다.
- Regeneron은 약물 타겟 식별 기간을 단축하고, 전체 데이터세트에서 쿼리를 실행하는 데 걸리는 시간을 30분에서 3초로 줄여(600배 성능 향상) 컴퓨팅 생물학자에게 인사이트를 빠르게 제공합니다.
요약
레이크하우스 아키텍처를 기반으로 한 Databricks SQL은 업계에서 가장 빠른 데이터 웨어하우스이고 최고의 가성비를 제공합니다. 이제 다른 시스템으로 데이터를 내보내지 않아도 새로운 데이터가 입력되자마자 낮은 지연으로 모든 데이터를 우수한 성능으로 실행할 수 있습니다.
이는 세계적 수준의 데이터 웨어하우징 성능을 데이터 레이크에 제공하겠다는 레이크하우스의 비전이 실현되었다는 증거이기도 합니다. 물론, 데이터 웨어하우스만 구축한 것은 아닙니다. 레이크하우스 아키텍처는 웨어하우징에서 데이터 사이언스, 머신 러닝에 이르기까지 모든 데이터 워크로드를 처리할 수 있는 기능을 제공합니다.
하지만 이게 끝이 아닙니다. Databricks는 업계 최고의 팀을 구성하여 성능을 더욱 혁신적으로 향상하기 위해 부단한 노력을 기울입니다. 성능뿐만 아니라 편의성, 거버넌스 측면에서도 여러 가지로 개선하고자 합니다. 앞으로 전해드릴 새로운 소식을 기다려 주세요.
The TPC does not audit or validate results of benchmarks derived from the TPC-DS and does not consider results of derived benchmarks to be comparable to published TPC-DS results.
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.