Databricks 노트북의 데이터 프로파일 소개
탐색적 데이터 분석 간소화
작성자: Edward Gan, Moonsoo Lee , 오스틴 포드
데이터 과학자가 분석에 대한 보고서를 작성하거나 머신러닝(ML) 모델을 훈련하기 전에 데이터의 구조와 내용을 이해해야 합니다. 이 탐색적 데이터 분석은 반복적이며, 각 단계는 종종 동일한 기본 기술을 포함합니다. 즉, 데이터 분포를 시각화하고 행 수, null 수, 평균, 항목 빈도 등과 같은 요약 통계를 계산하는 것입니다. 안타깝게도 이러한 시각화 및 통계를 수동으로 생성하는 것은 특히 대규모 데이터셋의 경우 번거롭고 오류가 발생하기 쉽습니다. 이 문제를 해결하고 탐색적 데이터 분석을 단순화하기 위해 Databricks 노트북에 데이터 프로파일링 기능을 도입합니다.
노트북에서 데이터 프로파일링
DBR 9.1 이상을 실행하는 클러스터에서 작업하는 데이터 팀은 노트북에서 데이터 프로파일을 생성하는 두 가지 방법을 사용할 수 있습니다. 셀 출력 UI와 dbutils 라이브러리를 통해서입니다. Databricks display 함수(AWS|Azure|Google) 또는 SQL 쿼리 결과를 사용하여 데이터 프레임의 내용을 볼 때, 사용자는 셀 출력의 "Table" 탭 오른쪽에 있는 "Data Profile" 탭을 보게 됩니다. 이 탭을 클릭하면 데이터 프레임의 데이터를 프로파일링하는 새 명령이 자동으로 실행됩니다. 프로파일에는 숫자, 문자열 및 날짜 열에 대한 요약 통계와 각 열의 값 분포 히스토그램이 포함됩니다. 이 명령은 테이블에 표시된 부분(잘릴 수 있음)뿐만 아니라 데이터 프레임 또는 SQL 쿼리 결과의 전체 데이터 세트를 프로파일링한다는 점에 유의하십시오.
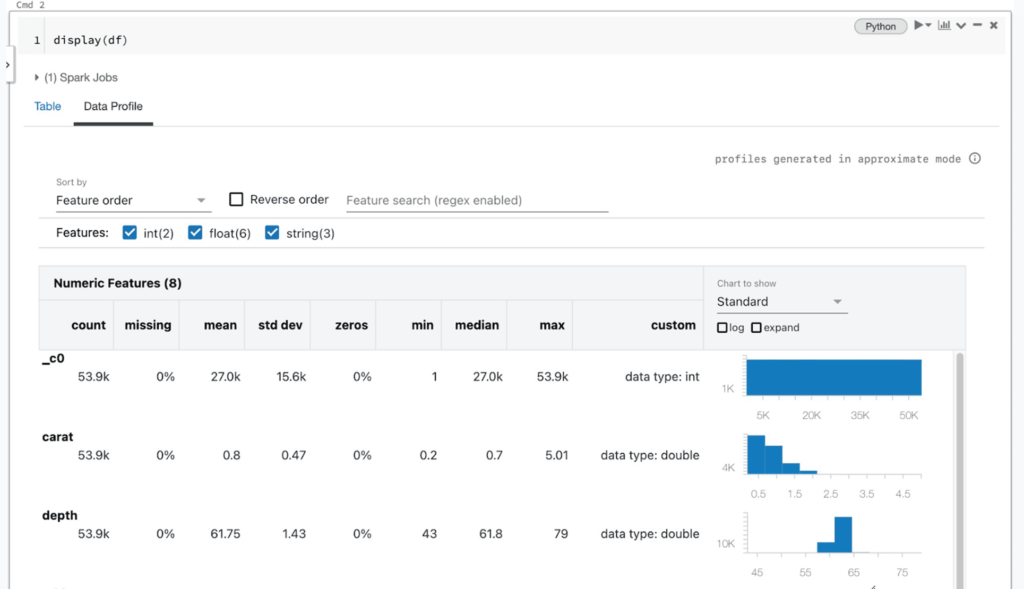
내부적으로 노트북 UI는 데이터 프로파일을 계산하기 위해 새 명령을 발행하며, 이는 각 데이터 세트에 대해 자동으로 생성된 Apache Spark™ 쿼리를 통해 구현됩니다. 이 기능은 Python, Scala 및 R의 dbutils API를 통해서도 사용할 수 있으며, dbutils.data.summarize(df) 명령을 사용합니다. 자세한 내용은 설명서(AWS|Azure|Google)를 참조하십시오.
지금 바로 Databricks 노트북에서 데이터 프레임을 미리 볼 때 데이터 프로파일을 사용해 보세요!
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.