Apache Spark 및 Photon, SIGMOD Awards 수상
작성자: Reynold Xin , Matei Zaharia
2년간의 ��가상 회의를 마치고 이번 주 데이터 관리 커뮤니티의 가장 영향력 있는 많은 엔지니어와 연구원들이 ACM SIGMOD 콘퍼런스가 열리는 필라델피아에 직접 모입니다. 이번 행사에서는 다음과 같은 두 가지 상을 발표하게 되어 매우 기뻤습니다:
- Apache Spark는 SIGMOD Systems Award를 수상했습니다.
- Databricks Photon이 최우수 산업 논문상을 수상했습니다
이번 기회에 저희는 이 배경과 어떻게 여기까지 오게 되었는지에 대해 논의하고자 합니다.
ACM SIGMOD란 무엇이며 어떤 상들이 있나요?
ACM SIGMOD는 컴퓨터 학회(Association of Computing Machinery)의 데이터 관리 특별 연구 그룹(Special Interest Group in the Management of Data)의 약자입니다. 네, 이름이 길죠. 모두 그냥 SIGMOD라고 합니다. 이 컨퍼런스는 데이터베이스 연구원 및 엔지니어에게 가장 권위 있는 학회로, 열 저장소부터 쿼리 최적화에 이르기까지 데이터베이스 분야의 가장 중추적인 아이디어 다수가 이곳에서 발표되었습니다.
SIGMOD Systems Award 는 "대규모 데이터 관리 시스템의 이론이나 실제에 미친 기술적 기여의 영향이 지대한 시스템" 하나에 매년 수여됩니다. 이러한 시스템은 대규모 실제 애플리케이션에 사용되는 경향이 있으며 미래 데이터베이스 시스템이 설계되는 방식에도 영향을 미쳤습니다. 역대 수상자로는 Postgres, SQLite, BerkeleyDB, Aurora가 있습니다.
최우수 산업 논문상은 실질적인 영향력, 혁신성, 발표의 완성도를 종합적으로 평가하여 매년 한 편의 논문에 수여됩니다.
Apache Spark의 데이터 및 AI 기원
약 10년 전, Netflix는 Netflix Prize라는 대회를 시작하여 방대한 사용자 영화 평점 모음을 익명화하고 참가자들에게 사용자가 영화를 어떻게 평가할지 예측하는 알고리즘을 제안하도록 요청했습니다. 100만 달러의 트로피는 최고의 머신 러닝 모델을 가진 팀에게 돌아갈 것입니다.
UC Berkeley의 박사 과정 학생 그룹이 대회에 참가하기로 결정했습니다. 그들이 처음 마주한 문제는 툴링이 충분히 좋지 않다는 점이었습니다. 더 나은 모델을 구축하기 위해 그들은 (학생용 노트북으로는 감당할 수 없는) 대량의 데이터를 빠르고 반복적으로 정리, 분석, 처리할 방법이 필요했고 실험적인 ML 알고리즘을 구성하기에 충분히 표현력이 좋은 프레임워크도 필요했습니다.
엔터프라이즈 데이터의 표준이었던 데이터 웨어하우스는 비정형 데이터를 처리할 수 없었고 표현력도 부족했습니다. 그들은 이 문제에 대해 또 다른 박사 과정 학생인 Matei Zaharia와 논의했습니다. 그들은 함께 RDD라는 새롭고 혁신적인 분산 데이터 구조를 갖춘 Spark라는 새로운 병렬 컴퓨팅 프레임워크를 설계했습니다. Spark는 사용자가 데이터 병렬 연산을 빠르고 간결하게 실행할 수 있도록 했습니다.
달리 말하면 코드 작성이 빠르고 실행도 빠릅니다. 작성 속도가 빠르면 프로그램을 더 쉽게 이해할 수 있고, 이를 통해 더 복잡한 알고리즘을 쉽게 구성할 수 있기 때문에 중요합니다. 실행 속도가 빠르기 때문에 사용자는 계속 증가하는 데이터를 사용해 더 신속하게 피드백을 받고 모델을 구축할 수 있습니다.

알고 보니 학생들은 혼자가 아니었습니다. 당시는 산업에서 데이터와 AI 애플리케이션을 사용하던 초창기였고 모두가 비슷한 문제에 직면했습니다. 뜨거운 성원에 힘입어 이 프로젝트는 Apache Software Foundation으로 이전하여 대규모 커뮤니티로 성장했습니다.
오늘날 Spark는 데이터 처리의 사실상 표준이며 계속 성장하고 있습니다.
- 지난달 PyPI와 Maven Central에서만 4,500만 번 다운로드되었습니다. 이는 다운로드 수가 전년 대비 90% 증가했음을 나타냅니다.
- 최소 204개 국가 및 지역에서 사용됩니다.
- Stack Overflow의 2021년 개발자 설문조사에서 최고 연봉 기술 분야 1위로 선정되었습니다.
SIGMOD 시스템상은 이 프로젝트가 널리 채택되었을 뿐만 아니라, 미래 세대의 시스템이 데이터와 AI를 통합된 패키지로 생각하도록 영향을 미친다는 것을 입증합니다.
Photon: 새로운 워크로드와 레이크하우스
Apache Spark의 인기가 높아지면서 저희는 조직들이 대규모 데이터 처리와 머신 러닝을 넘어 Spark를 더 다양하게 활용하고 싶어 한다는 사실을 발견했습니다. 즉, 비즈니스의 다른 영역에서 사용 중인 동일한 데이터세트에서 기존의 대화형 데이터 웨어하우징 애플리케이션을 실행하여 여러 데이터 시스템을 관리할 필요가 없게 만들고 싶어 한 것입니다. 이는 데이터 웨어하우스와 데이터 레이크 시스템의 장점을 결합하여 대규모 처리와 대화형 SQL 쿼리를 수행할 수 있는 단일 데이터 저장소인 레이크하우스 시스템이라는 개념으로 이어졌습니다.
이러한 유형의 사용 사례를 지원하기 위해 당사는 Spark의 기존 프로그래밍 인터페이스 뒤에서 실행되는 Spark 및 SQL 워크로드용 고속 C++ 벡터화 실행 엔진인 Photon을 개발했습니다. Photon은 SQL, Python, Java 애플리케이션을 비롯한 동일한 API와 워크로드를 지원하면서도 Spark보다 훨씬 더 빠른 대화형 쿼리와 훨씬 더 높은 동시성을 구현합니다. 당사는 작년 대규모 TPC-DS 데이터 웨어하우스 벤치마크에서 세계 기록을 세운 것 부터 소규모 동시 쿼리에서 3배 더 높은 성능을 제공하는 것에 이르기까지 모든 규모의 워크로드에서 Photon을 통해 훌륭한 결과를 확인했습니다.
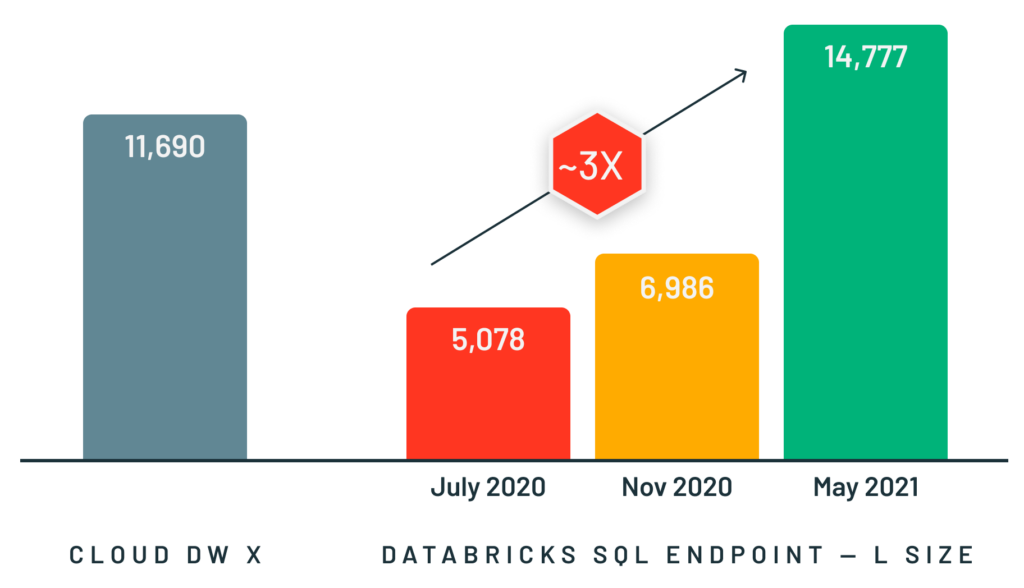
Photon을 설계하고 구현하는 것은 어려운 일이었습니다. 엔진이 (광범위한 애플리케이션을 지원하기 위해) Spark의 표현력과 유연성을 유지하고, (성능 저하를 방지하기 위해) 절대 느려지지 않으며, 목표 워크로드에서 훨씬 더 빨라야 했기 때문입니다. 또한 모든 데이터가 독점적인 형식으로 로드되었다고 가정하는 기존의 데이터 웨어하우스 엔진과 달리, Photon은 수집 프로세스(예: 인덱스 또는 데이터 통계의 가용성)에 대한 가정을 최소화하면서 Delta Lake 및 Apache Parquet과 같은 개방형 형식으로 데이터를 처리하며 lakehouse 환경에서 작동해야 했습니다. 저희의 SIGMOD paper 는 이러한 과제를 어떻게 해결했는지와 Photon 구현의 많은 기술적 세부 사항을 설명합니다.
저희는 이 연구가 최우수 산업 논문으로 인정받게 되어 매우 기뻤으며, 이 새로운 lakehouse 시스템 모델의 어려운 점에 대해 데이터베이스 엔지니어와 연구원들에게 좋은 아이디어를 주기를 바랍니다. 물론 저희는 지금까지 고객들이 Photon으로 이룬 성과에 대해 매우 기쁘게 생각합니다. 이 새로운 엔진은 이미 저희 워크로드의 상당 부분을 차지할 정도로 성장했습니다.
SIGMOD에 참석하신다면 Databricks 부스에 들러 인사해주세요. 데이터 시스템의 미래에 대해 함께 이야기 나누고 싶습니다. 그 보답으로 “the best 데이터 웨어하우스 is a lakehouse” 티셔츠를 드립니다!

최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.