신약 개발 가속화: Databricks에서 FASTA 파일로부터 GenAI 인사이트 얻기
Databricks Platform에서 데이터 엔지니어링, 단백질 언어 모델, GenAI를 결합하여 엔드투엔드 파��이프라인을 구축하는 방법
- Lakeflow 선언적 파이프라인을 사용하여 대규모 생물학적 데이터를 처리하고 원시 FASTA 단백질 서열을 Unity Catalog의 분석 준비 테이블로 변환합니다.
- 단백질 언어 모델인 ProtBERT를 활용하여 트랜스포머 모델로 단백질을 분류하고, 핵심 신약 표적인 막수송 단백질��을 식별합니다.
- LLM을 데이터에 직접 연결하는 AI Functions를 통해 자연어로 단백질 인사이트를 query하여 연구자들이 유망한 신약 후보를 대화형으로 탐색할 수 있도록 지원합니다.
신약 개발은 느리고 비용이 많이 드는 것으로 악명이 높습니다. 평균 연구 개발(R&D) 수명 주기는 10~15년이며, 상당수의 후보 물질이 임상 시험 중에 실패합니다. 과정 초기에 적절한 단백질 표적을 식별하는 것이 주요 병목 현상이었습니다.
단백질은 생물체의 "일꾼 분자"로, 반응을 촉매하고, 분자를 운반하며, 대부분의 현대 약물의 표적으로 작용합니다. 단백질을 신속하게 분류하고, 그 특성을 이해하며, 연구가 덜 된 후보를 식별하는 능력은 발견 프로세스를 획기적으로 가속화할 수 있습니다(예: Wozniak 등, 2024, Nature Chemical Biology).
바로 이 지점에서 데이터 엔지니어링, 머신러닝(ML), 생성형 AI의 융합이 혁신을 이룹니다. 실제로 이 전체 파이프라인을 단일 플랫폼인 Databricks 데이터 인텔리전스 플랫폼에서 구축할 수 있습니다.
구축 내용
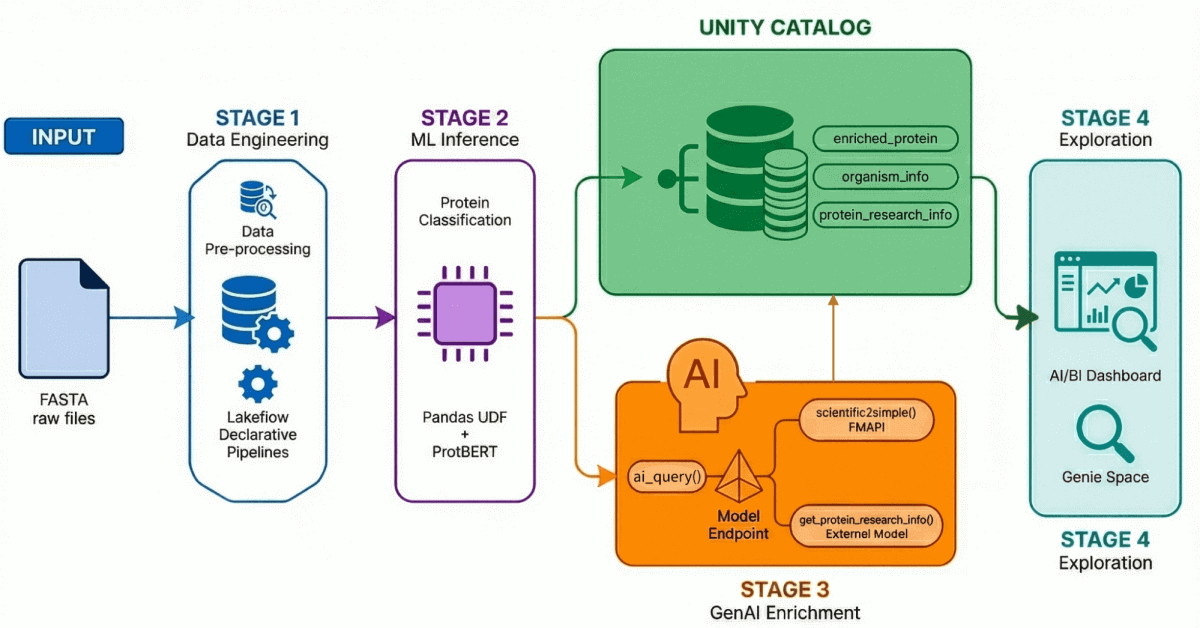
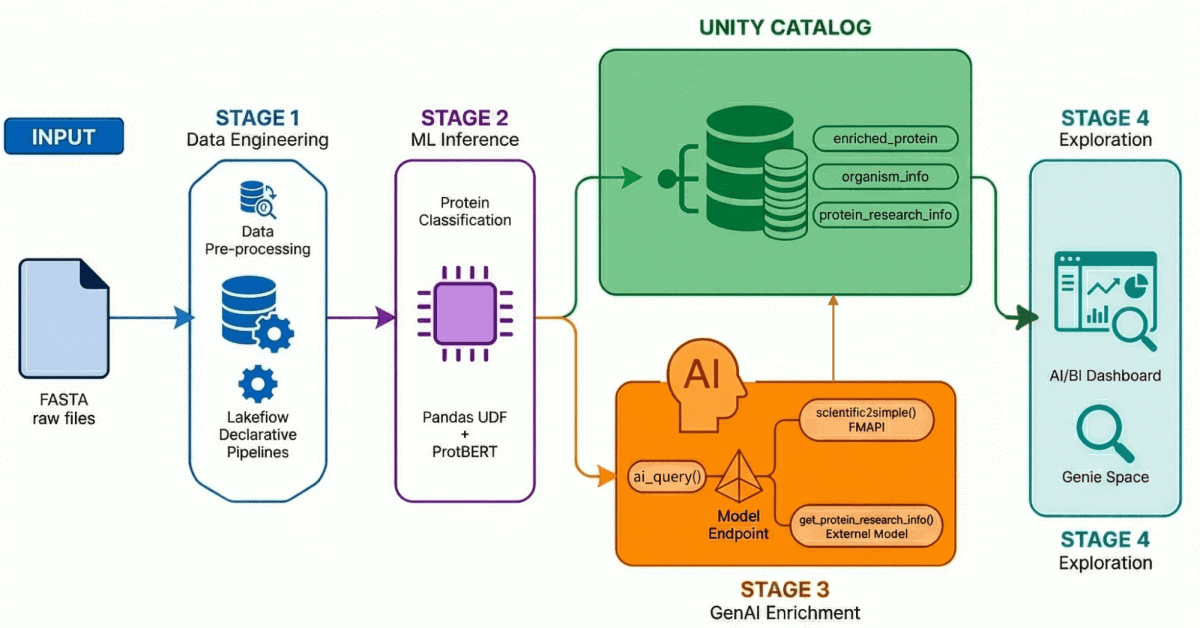
당사의 AI 기반 신약 개발 솔루션 가속기 는 네 가지 주요 프로세스를 통해 엔드투엔드 워크플로를 시연합니다:
- 데이터 수집 및 처리: UniProt에서 500,000개 이상의 단백질 서열을 수집하고 처리합니다.
- AI 기반 분류: 트랜스포머 모델을 사용하여 이러한 단백질을 수용성 또는 막 수송 단백질로 분류합니다.
- 인사이트 생성: 단백질 데이터는 LLM이 생성한 연구 인사이트로 보강됩니다.
- 자연어 탐색: 자연어 쿼리를 지원하는 AI 기반 대시보드와 환경을 통해 처리 및 강화된 모든 데이터에 액세스할 수 있습니다.
각 단계를 살펴보겠습니다:
{kind=link}
1단계: Lakeflow 선언적 파이프라인을 사용한 데이터 엔지니어링
원시 생물학적 데이터는 깨끗하고 분석 준비가 된 형식으로 제공되는 경우가 거의 없습니다. 소스 데이터는 단백질 서열을 나타내는 표준 형식인 FASTA 파일로 제공되며, 다음과 같이 보입니다.
비전문가의 눈에는 이 시퀀스 데이터가 단일 문자 아미노산 코드로 이루어진 빽빽한 문자열이어서 해석하기가 거의 불가능합니다. 하지만 이 파이프라인��이 끝나면 연구원들은 "분류 신뢰도가 높은 인간의 막 단백질 중 연구가 덜 된 것을 보여줘" 와 같이 자연어로 이 동일한 데이터를 쿼리하여 실행 가능한 인사이트를 얻을 수 있습니다.
Lakeflow Declarative 파이프라인을 사용하여 이 데이터를 점진적으로 정제하는 메달리온 아키텍처 를 구축합니다.
- 브론즈 레이어: BioPython을 사용하여 FASTA 파일을 원시 수집하고 ID와 서열을 추출합니다.
- 실버 레이어: 파싱 및 구조화 - 정규식 변환을 사용하여 단백질 이름, 유기체 정보, 유전자 이름 및 기타 메타데이터를 추출합니다.
- 골드/보강 계층: 분자량과 같은 파생 메트릭으로 보강된 큐레이션된 분석 준비 데이터로, 대시보드, ML 모델 및 다운스트림 연구에 바로 사용할 수 있습니다. 이 계층은 애널리스트와 과학자가 직접 쿼리하는 신뢰할 수 있는 계층입니다.
결과: Unity Catalog에 있는 정제되고 관리되는 단백질 데이터로, 다운스트림 ML 및 분석에 사용할 수 있습니다. 무엇보다도, 이 단계를 넘어 아래에 강조 표시된 다른 단계까지 확장되는 데이터 리니지는 과학적 재현성에 엄청난 가치를 제공합니다.
2단계: 트랜스포머 모델을 이용한 단백질 분류
신약 개발에 있어서 모든 단백질이 동등하게 생성되는 것은 아닙니다. 세포막에 내장된 막 수송 단백질은 세포 안팎의 물질 출입을 제어하므로 특히 중요한 약물 표적입니다.
막 단백질 분류를 위해 특별히 미세 조정된 Rostlab의 BERT 기반 단백질 언어 모델인 ProtBERT-BFD를 활용합니다. 이 모델은 아미노산 서열을 언어처럼 처리하여 잔기 간의 문맥적 관계를 학습하고 단백질 기능을 예측합니다.
모델은 분류(막 또는 수용성)를 신뢰도 점수와 함께 출력하며, 다운스트림 필터링 및 분석을 위해 이를 Unity Catalog에 다시 씁니다.
3단계: GenAI를 사용한 데이터 강화
분류는 단백질이 무엇 인지 알려줍니다. 하지만 연구자들은 그것이 왜 중요한지, 즉 최신 연구는 무엇인지 알아야 합니다. 연구의 공백은 어디에 있나요? 이것은 충분히 연구되지 않은 약물 표적인가요?
여기서 LLM을 도입합니다. Databricks의 Foundational Model API와 External Model 엔드포인트를 모두 활용하여 연구 컨텍스트로 단백질 기록을 보강하는 등록된 AI Functions를 생성합니다.
4단계: 자연어 탐색
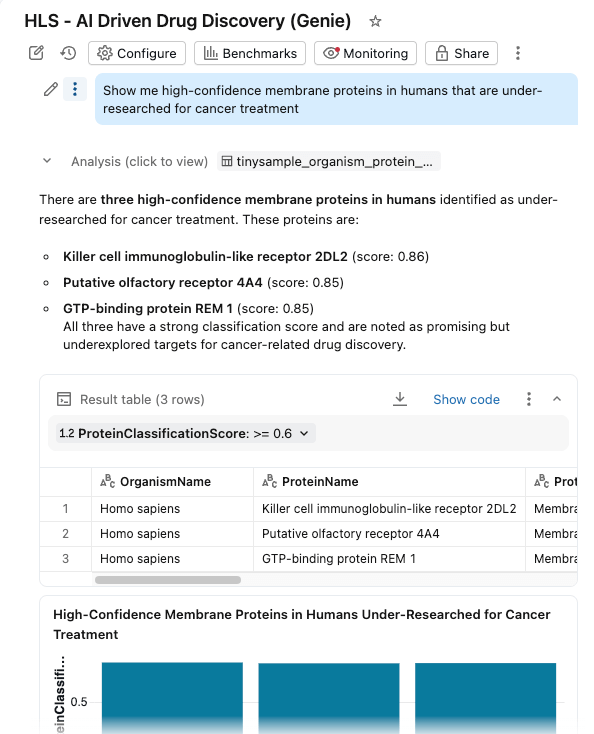
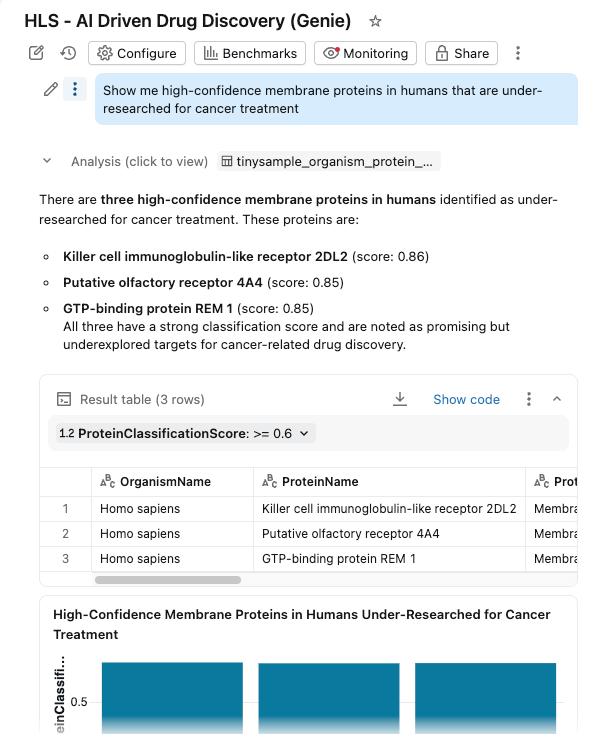
Genie Space가 활성화된 AI/BI 대시보드에 모든 것을 통합했습니다.
이제 연구원은 다음을 수행할 수 있습니다.
- 유기체, 분류 점수 및 단백질 유형별로 단백질 필터링
- 분자량 및 분류 신뢰도의 분포 탐색
- 자연어로 질문하기: "암 치료에 대한 연구가 부족한 인간의 고신뢰도 막단백질을 보여주세요"
{kind=link}
대시보드는 Unity Catalog의 동일한 거버넌스 테이블을 쿼리하며, AI Functions는 주문형(또는 배치 처리) 보강을 제공합니다.
통합 플랫폼의 힘
이 솔루션이 매력적인 이유는 어느 한 구성 요소 때문이 아니라, 모든 것이 하나의 플랫폼에서 실행된다는 점입니다.
| 역량 | Databricks 기능 |
|---|---|
| 데이터 수집 및 ETL | Lakeflow 선언적 파이프라인 |
| 데이터 거버넌스 | Unity Catalog |
| ML 추론 | GPU 컴퓨팅 |
| LLM 통합 | FMAPI + 외부 모델 + AI 함수 |
| 분석 | Databricks SQL |
| 탐색 | AI/BI 대시보드 + AI/BI Genie Space |
중요한 것은 시스템 간 데이터 이동이 없다는 점입니다. 별도의 MLOps 인��프라가 필요 없습니다. 분리된 BI 도구가 필요 없습니다. 파이프라인에 들어가는 단백질 서열은 변환, 분류, 강화를 거쳐 자연어로 쿼리할 수 있게 되며, 이 모든 과정이 동일한 관리형 환경 내에서 이루어집니다.
전체 솔루션 가속기는 GitHub에서 사용할 수 있습니다:
github.com/databricks-industry-solutions/ai-driven-drug-discovery
다음 단계
이 가속기는 무엇이 가능한지를 보여줍니다. 프로덕션 환경에서는 다음과 같이 확장할 수 있습니다:
- 프로비저닝된 throughput Endpoint로 전체 UniProt 데이터베이스 처리
- 다양한 단백질 특성을 위한 더 많은 (오픈 소스 또는 맞춤형) 분류 모델 추가
- 더 근거 있는 LLM 응답을 위해 과학 문헌에 RAG 파이프라인 구축
- 다운스트림 분자 시뮬레이션 워크플로와 통합
- 단백질 구조 예측(AlphaFold/ESMFold)에 연결하여 분류된 단백질에 3D 구조 컨텍스트 추가
- Glow를 사용하여 대규모 시퀀싱 및 변이 분석을 위해 다른 유전체 형식(FASTQ, VCF, BAM)으로 확장하세요.
기반이 마련되어 있습니다. 플랫폼은 통합되어 있습니다. 유일한 한계는 여러분이 가속화하고자 하는 과학뿐입니다. 지금 시작해 보세요!
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.