Databricks 스토리지 생태계 발표: 어디에 있든 기업 데이터 자산 거버넌스
오픈 소스 OpenSharing을 기반으로 하는 새로운 스토리지 파트너 에코시스템은 단 1바이트도 복사하지 않고 온프레미스 및 하이브리드 인프라에 Databricks 데이터 인텔리전스 플랫폼을 직접 제공합니다.
작성자: Rupal Jain , Denis Dubeau
- 과제: 기업은 엄격한 데이터 주권 및 규제 요구 사항을 충족하고, 에지에서 낮은 지연 시간을 유지하거나, 방대한 데이터 중력(data gravity)을 처리하기 위해 온프레미스, 프라이빗 클라우드, 에지 환경에 방대한 양의 데이터를 유지해야 합니다. 동시에 이러한 환경에 현대적인 클라우드 AI 및 거버넌스를 도입해야 합니다.
- 정의: Databricks Storage Ecosystem은 OpenSharing 프로토콜을 사용하여 하이브리드 및 온프레미스 스토리지 플랫폼을 Databricks에 네이티브하게 연결합니다. 이를 통해 기업은 중앙 집중식 데이터 거버넌스를 구축하고 전체 하이브리드 인프라에서 GenAI를 확장할 수 있습니다.
- 결과: 제로 카피 아키텍처를 통해 기업은 단 하나의 파일도 복사하지 않고 온프레미스 데이터 세트에서 직접 Databricks Serverless Compute, Genie 및 LLM을 실행할 수 있습니다. 이를 통해 고립된 데이터를 분류된 엔지니어링 데이터 기반의 모델 학습이나 즉각적인 네트워크 텔레메트리 분석과 같은 고급 사용 사례를 위해 즉시 사용 가능한 활성 AI 지원 자산으로 전환할 수 있습니다.
이동할 수 없는 데이터
수년 동안 엔터프라이즈 데이터 전략은 간단했습니다. 모든 것을 클라우드로 이동하는 것이었죠. 데이터 레이크와 웨어하우스를 클라우드로 마이그레이션하면 거버넌스가 자연스럽게 뒤따라왔습니다. 문제가 생기기 전까지는 아주 깔끔한 이야기였습니다.
오늘날 세계에서 가장 정교한 기술을 보유한 일부 기업들은 우리에게 분명히 말하고 있습니다. 그들은 자신들의 모든 데이터를 클라우드로 이동할 수 없으며, 이동하지도 않을 것이라고 말이죠. 선도적인 반도체 제조업체들은 사내(on-premises)를 절대 벗어나서는 안 되는 엔지니어링 기밀 데이터 세트로 모델을 학습시키고 있습니다. 글로벌 거래 기업들은 클라우드 송출(egress) 비용 문제로 인해 마이그레이션이 불가능한 막대한 양의 과거 틱 데이터를 보유하고 있습니다. 일류 은행들은 엄격한 데이터 주권을 유지하면서 온프레미스 스토리지를 현대화하는 "Hybrid Forever" 전략을 채택했습니다. 주요 제약 회사들은 엄격한 규제 제어 대상인 페타바이트 규모의 온프레미스 데이터 자산을 대상으로 매일 수백만 건의 약물 실험을 수행하고 있습니다.
이것들은 특이 케이스(edge cases)가 아닙니다. 기업들이 데이터를 바라보는 방식이 "모든 데이터 마이그레이션"에서 "모든 데이터 거버넌스"로 구조적으로 전환되고 있음을 나타냅니다.
이러한 변화를 이끄는 요인들은 실재하며 복합적입니다.
- 데이터 주권 및 규제: 금융 서비스, 의료, 정부 기관은 데이터가 특정 관할 구역이나 에어갭(air-gapped) 환경 내에 머물도록 요구하는 GDPR, HIPAA, NIS2, 부문별 데이터 레지던시 규칙 등의 법적 명령에 따라 운영됩니다. 클라우드 마이그레이션은 선택 사항이 아니며, 특정 데이터 세트의 경우 법적으로 금지되어 있습니다.
- 데이터 중력 및 비용: 페타바이트 및 엑사바이트 규모에서는 클라우드 마이그레이션의 경제성이 완전히 무너집니다. 송출 수수료, 스토리지 비용, 그리고 엄청난 데이터 양으로 인해 "한 번 이동하기" 모델은 재정적으로 지속 불가능합니다. 세계 최대의 일부 소매업체들은 바로 이러한 이유로 클라우드에서 온프레미스 인프라로 분석 워크로드를 적극적으로 송환(repatriating)하고 있습니다.
- 지연 시간 및 에지 워크로드: 소매, 제조, 통신 워크로드는 온프레미스 및 에지 데이터에 대한 저지연 액세스를 필요로 합니다. 통신 제공업체는 클라우드 왕복을 감당할 수 없는 AI 기반 네트워크 운영을 지원하기 위해 매일 온프레미스에서 방대한 양의 네트워크 텔레메트리를 수집합니다.
- 다크 데이터 기반 AI: 기업 전반에 걸쳐 수백 엑사바이트에 달하는 방대한 백업 데이터, 비정형 아카이브, 보조 데이터 세트에는 거버넌스가 미치지 못해 지금까지 활용되지 못한 엄청난 AI 가치가 담겨 있습니다.
신호는 확실합니다. 당사는 수백 명의 고객으로부터 Unity Catalog에 대한 온프레미스 및 하이브리드 스토리지 연결을 명시적으로 요청하는 문의를 받았습니다. 소프트웨어 정의 스토리지(SDS) 시장은 2026년에 수천억 달러 규모에 달하며, 총 2제타바이트 이상의 데이터를 관리하고 있는 엔터프라이즈 파트너들이 당사와 함께 구축해 나가고 있습니다.
Databricks 스토리지 에코시스템 소개
오늘 당사는 온프레미스, 프라이빗 클라우드, 에지 환경 등 엔터프라이즈 데이터가 있는 곳 어디에서나 Databricks Intelligence Platform을 제공하기 위해 특별히 구축된 새로운 파트너 카테고리인 Databricks 소프트웨어 정의 스토리지(SDS) 에코시스템을 발표하게 되어 기쁩니다. 현재 이러한 플랫폼에서 페타바이트 규모의 데이터를 운영 중인 기업이라면, 이제 기존의 비클라우드 스토리지 인프라와 Databricks AI 중 하나를 선택해야 하는 고민을 하지 않으셔도 됩니다.
너무 오랫동안 기업들은 자신들이 의존하는 온프레미스 스토리지 인프라와 구축하고자 하는 클라우드 네이티브 AI 사이에서 선택을 강요받아야 했습니다. 단지 인텔리전스를 활용하기 위해 복잡한 파이프라인을 사용하여 방대한 양의 데이터를 마이그레이션하도록 고객에게 강요하는 것은 잘못된 모델입니다. 업계를 선도하는 이러한 파트�너들을 하나로 묶음으로써, 당사는 그러한 타협을 끝내고 엔터프라이즈 데이터가 있는 곳으로 직접 Databricks 인텔리전스를 제공하고 있습니다. 하지만 이번 출시는 시작에 불과합니다. 당사는 머지않아 정형이든 비정형이든 모든 하이브리드 데이터가 단 1바이트도 복사할 필요 없이 생성형 AI에 즉시 활용될 수 있도록 기반을 다지고 있습니다. —Stephen Orban, SVP, Product Partnerships & Ecosystem, Databricks
이 에코시스템의 핵심은 안전하고 거버닝된 데이터 공유를 위한 오픈 소스 프로토콜인 OpenSharing입니다. 당사의 스토리지 파트너들은 자신들의 데이터 자산을 Databricks Serverless Compute에 직접 노출하기 위해 OpenSharing 서버를 구현하고 있습니다. 방법은 간단합니다. 스토리지 파트너가 OpenSharing 엔드포인트를 설정하면, 이를 Unity Catalog에 연결하여 데이터 마이그레이션 없이 Databricks에 있는 온프레미스 데이터에 안전하고 거버닝된 액세스를 즉시 확보할 수 있습니다.
이 통합은 전체 하이브리드 환경에 걸쳐 단일화된 통합 카탈로그를 제공합니다. 이제 고객은 Databricks Serverless Compute, Genie, AgentBricks 및 모델 학습을 사용하여 사내를 절대 벗어나지 않는 데이터를 쿼리하고 추론할 수 있습니다. 그 결과는 어떨까요? 데이터 이동 제�로, 데이터 중복 없음, 컴플라이언스 리스크 제로입니다.
이것은 로드맵상의 희망 사항이 아닙니다. 고객들은 지금 바로 이러한 통합을 시도해 볼 수 있습니다. 이러한 통합을 구축하는 파트너들은 아키텍처, 보안 및 인증 기준을 다루는 기술 청사진인 Partner Well-Architected Framework를 따릅니다.
고객들은 데이터 사일로를 허물고 여전히 온프레미스에 존재하는 대량의 데이터를 포함하여 모든 데이터 및 AI 자산을 통합하고자 합니다. 오픈 소스 Open Sharing 프로토콜을 활용하는 온프레미스 스토리지 파트너 덕분에, 이제 고객은 Databricks Unity Catalog에서 모든 데이터 자산을 원활하게 통합, 거버닝 및 분석할 수 있게 되었으며, Databricks Data Intelligence Platform에서 데이터의 모든 가치를 실현할 수 있습니다. —Jonathan Keller, VP, Product Management, Databricks
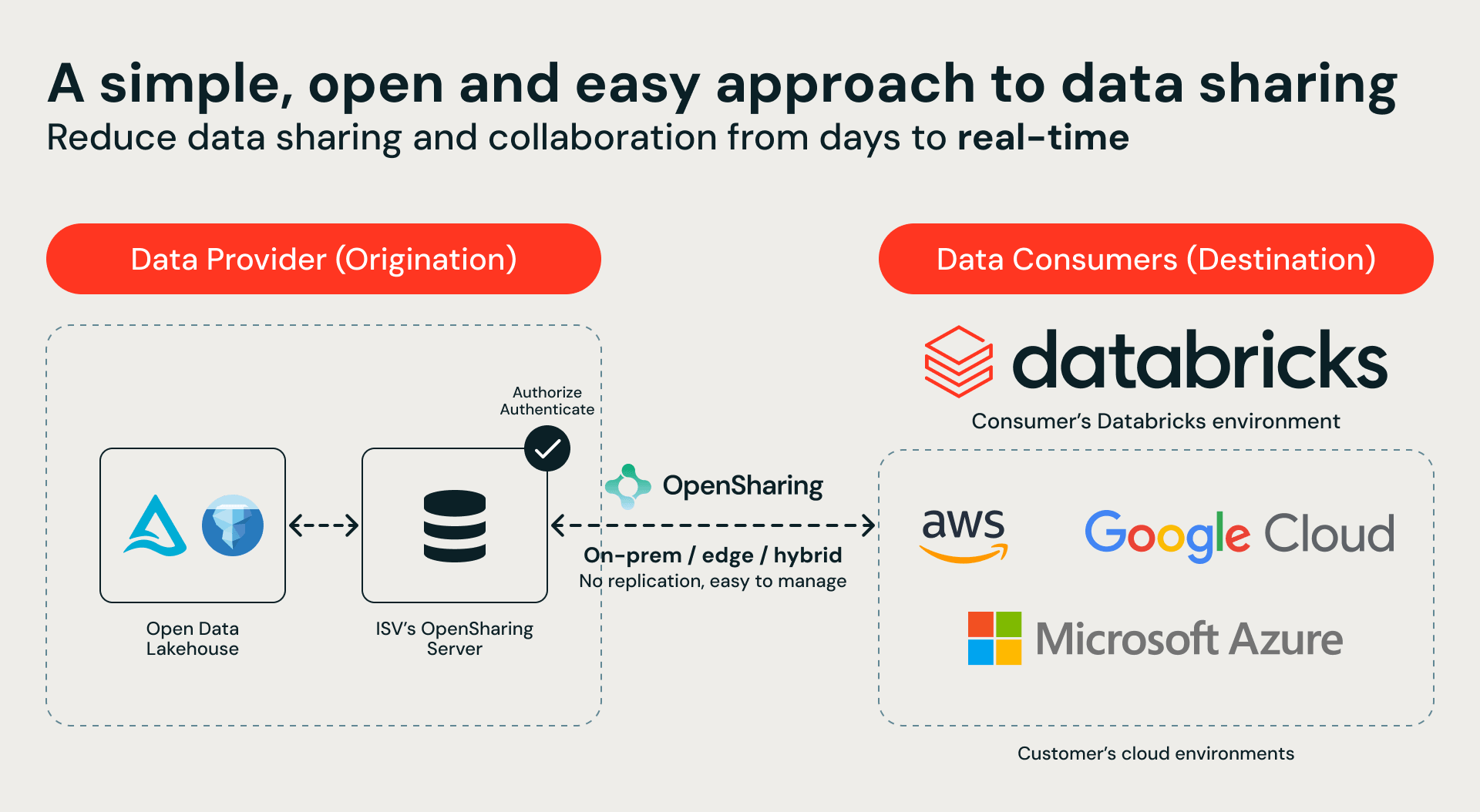
출시 파트너사 소개
업계를 선도하는 다음 스토리지 제공업체들과의 통합을 발표하게 되어 자랑스럽게 생각합니다.

MinIO — 정식 출시(GA) (데모, 블로그)
MinIO AIStor는 클라우드로 이동할 수 없는 엔터프라이즈 데이터와 Databricks Data Intelligence Platform을 원활하게 연결하는 가교 역할을 합니다. 스토리지 레이어에서 개방형 Open Sharing 프로토콜을 기본적으로 구현함으로써, AIStor는 복잡성을 제거하고 Databricks 고객이 완전한 Unity Catalog 거버넌스 하에 라이브 온프레미스 Apache Iceberg™️ 및 Delta 테이블을 효율적으로 쿼리할 수 있도록 지원합니다. 또한 Serverless Compute, Genie, Agent Bricks를 온프레미스 데이터로 확장하여 Databricks 플랫폼의 모든 강력한 기능을 기업의 가장 중요한 데이터에 제공합니다.
AI 및 분석 이니셔티브는 데이터가 어디에 있는지에 따라 제약을 받는 경우가 많으며, 특히 보안, 주권 또는 운영 요구 사항이 엄격한 환경에서 더욱 그렇습니다. AIStor에 기본 OpenSharing을 도입함으로써, 당사는 조직이 데이터가 있는 곳에서 안전하게 데이터를 노출하는 동시에 개방형 표준을 통해 Databricks에 원활한 액세스를 제공할 수 있도록 지원하고 있습니다. 이는 엔터프라이즈 데이터와 AI 사이의 주요 장벽을 제거하여, 조직이 통제력을 손상시키지 않으면서 AI, 분석 및 에�이전트 기반 애플리케이션을 위해 이전에 액세스할 수 없었던 데이터를 활성화할 수 있도록 합니다. —Ugur Tigli, Chief Technology Officer, MinIO
Everpure (구 Pure Storage) — 비공개 미리 보기(Private Preview) (데모, 블로그)
Everpure와 Databricks는 조직이 데이터 복제나 중복 없이 온프레미스 데이터를 클라우드에서 직접 사용할 수 있도록 지원합니다. 이는 오브젝트 스토리지의 데이터와 Databricks 핵심 워크스페이스를 안전하고 통제된 방식으로 연결하는 OpenSharing 커넥터를 통해 제공됩니다.
Everpure와 Databricks는 조직이 복제나 중복 없이 클라우드에서 직접 온프레미스 데이터에 액세스하고 분석할 수 있도록 지원합니다. 환경 간에 데이터를 지속적으로 이동하는 것은 비용이 많이 들고 대규모 환경에서는 지속 불가능합니다. 고객들은 운영 복잡성을 줄이면서 비용, 컴플라이언스, 데이터 주권의 균형을 맞추는 더 간단한 접근 방식을 찾고 있습니다. —Chadd Kenney, VP of Product Management, Everpure
Qumulo — 2026년 7월 비공개 미리 보기(Private Preview) 예정 (블로그)
Qumulo는 자사의 새로운 NeuralSearch에 OpenSharing을 통합하여, 고객이 복제, 추가 비용 또는 복잡성 없이 코어, 클라우드 및 에지 환경 전반에서 Qumulo에 저장된 데이터를 Databricks와 안전하게 공유할 수 있도록 지원합니다. 사용자는 NeuralSearch를 통해 자연어 질의로 비정형 콘텐츠를 포함한 관련 데이터 세트를 검색하고, 큐레이션된 테이블을 OpenSharing을 통해 Databricks와 원활하게 공유할 수 있습니다.
기업들은 이제 단지 AI와 분석을 지원하기 위해 환경 전반에 걸쳐 대규모 데이터 세트를 복사하는 데 드는 비용, 복잡성 및 지연을 더 이상 감당할 수 없습니다. Qumulo NeuralSearch와 Databricks OpenSharing을 결합함으로써, 고객은 데이터를 직접 이동하지 않고도 코어 데이터 센터, 에지 위치 및 퍼블릭 클라우드 전반에서 정형 및 비정형 데이터를 실시간으로 안전하게 검색, 거버넌스 제어 및 공유할 수 있습니다. 우리는 기업이 단일 진실 공급원(single source of truth)을 유지하면서 AI 이니셔티브를 가속화하고, 거버넌스를 통합하며, 전 세계에 분산된 데이터로부터 더 빠르게 인사이트를 확보할 수 있도록 함께 지원하고 있습니다. —Brandon Whitelaw, Qumulo SVP 겸 제품 총괄
VAST Data — 2026년 8월 비공개 프리뷰
VAST Data��는 대규모 데이터 이동이나 마이그레이션 없이 기업이 온프레미스 및 하이브리드 인프라에 있는 데이터와 Databricks 워크플로를 연결할 수 있도록 OpenSharing 지원을 통해 VAST AI Operating System을 확장하고 있습니다. 이번 통합을 통해 고객은 현대적인 하이브리드 AI 및 분석 워크로드를 지원하는 동시에 클라우드, 데이터 센터 및 새로운 AI 인프라 환경 전반에서 데이터를 액세스, 처리 및 운영할 수 있는 더 큰 유연성을 얻게 됩니다.
AI 인프라는 근본적으로 하이브리드화되고 있습니다. 고객은 환경 전반에서 원활한 액세스를 유지하면서도 경제적, 운영적으로 가장 합리적인 곳에서 데이터를 처리할 수 있는 기능을 점점 더 원하고 있습니다. OpenSharing 지원은 현대적인 AI 및 분석 애플리케이션을 위해 클라우드 및 온프레미스 인프라에 걸쳐 있는 데이터와 Databricks 워크플로를 연결하는 VAST AI Operating System의 기능을 확장합니다. 기존 스토리지 플랫폼과 달리 VAST는 데이터 서비스, 분산 처리 및 AI 인프라 오케스트레이션을 대규모 AI 데이터를 위한 단일 운영 체제로 결합합니다. —John Mao, VAST Data 글로벌 기술 얼라이언스 부사장
향후 계획
출시 예정 통합 기능
출시 파트너 외에도 스토리지 생태계 전반의 모멘텀이 계속해서 가속화되고 있습니다. 당사는 올해 말까지 네이티브 통합을 구축하기 위해 Cohesity, Commvault, HPE, NetApp, Nutanix, Rubrik으로부터 협력을 약속받았습니다.
이들 파트너는 출시 파트너와 함께 고성능 비정형 미디어, 보조 백업 아카이브, 비용 효율적인 클라우드 스토리지, 하이퍼컨버지드 프라이빗 클라우드 자산에 이르기까지 수백 엑사바이트에 달하는 기업 데이터를 공동으로 관리하고 있습니다.
비정형 데이터의 가치 실현
오늘 출시를 통해 정형 및 테이블 형식의 데이터가 이 생태계 전반에서 완전히 거버넌스 제어되고 액세스 가능해졌습니다. 하지만 우리는 비정형 데이터에 더 흥미로운 기회가 있다는 것을 알고 있습니다. 이미지, PDF, 비디오, 의료 스캔, 엔지니어링 시뮬레이션, 백업 아카이브 등은 관리 대상 기업 데이터의 대부분을 차지하며, 차세대 RAG 파이프라인과 미세 조정(fine-tuned) 모델의 원천 자료가 됩니다.
당사는 GenAI 워크로드를 위해 온프레미스 스토리지의 비정형 파일을 Databricks에 직접 노출하는 Volumes API로 OpenSharing 프로토콜을 확장하기 위해 적극적으로 노력하고 있습니다. 이 기능이 도입되면 미디어 및 이미지 아카이브부터 기업 백업 리포지토리에 이르기까지 대규모 비정형 자산을 관리하는 파트너들이 고객을 위한 완전히 새로운 차원의 AI 사용 사례를 실현할 수 있게 됩니다.
이것이 바로 모든 것을 거버넌스 제어한다는 것의 의미입니다.
생태계 참여하기
OpenSharing 통합 구축에 관심이 있는 스토리지 벤더이시라면, Partner Well Architected Framework를 방문하거나 Databricks 파트너 팀에 문의하여 시작해 보세요.
온프레미스 스토리지 자산을 Databricks�에 연결하고자 하는 기업 고객이시라면, 담당 어카운트 팀에 문의하여 자세히 알아보세요.
"모든 것을 마이그레이션"하는 시대는 끝났습니다. "모든 것을 거버넌스 제어"하는 시대가 오늘 시작됩니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.