Announcing the General Availability of the Databricks SQL Statement Execution API
작성자: Adriana Ispas, 크리스 스티븐스, Christian Stuart , Sander Goos
오늘, AWS와 Azure에서 Databricks SQL 명령문 실행 API를 사용할 수 있게 되었음을 알려드리게 되어 기쁘게 생각하며, GCP에 대한 지원은 내년 초에 공개 프리뷰로 제공될 예정입니다. 이 API를 사용하면 REST API를 통해 Databricks SQL 웨어하우스에 연결하여 Databricks 레이크하우스 플랫폼에서 관리하는 데이터에 액세스하고 조작할 수 있습니다.
이 블로그에서는 API의 기본 사항을 살펴보고, GA 릴리스에서 새롭게 제공되는 주요 기능에 대해 논의하며, Databricks Python SDK와 함께 명령문 실행 API를 사용하여 데이터 애플리케이션을 구축하는 방법을 보여드립니다. Databricks 워크스페이스에서 코드를 실행하여 직접 따라해 볼 수도 있습니다. 추가 예제로, 이전 블로그에서는 명령문 실행 API와 JavaScript를 사용하여 스프레드시트에서 데이터를 활용하는 방법을 보여드렸습니다.
Statement Execution API, in brief
BI 애플리케이션은 데이터 웨어하우스의 주요 소비자 중 하나이며, 데이터브릭스 SQL은 드라이버, 커넥터, 기존 BI 도구와의 기본 통합으로 구성된 풍부한 연결 에코시스템을 제공합니다. 그럼에도 불구하고, 데이터브릭스 레이크하우스 플랫폼에서 관리되는 데이터는 전자상거래 플랫폼, CRM 시스템, SaaS 애플리케이션, 고객이 자체 개발한 맞춤형 데이터 애플리케이션 등 BI 이외의 애플리케이션 및 사용 사례와도 관련이 있습니다. 이러한 도구는 표준 데이터베이스 인터페이스와 드라이버를 통해 쉽게 연결할 수 없는 경우가 많지만, 거의 모든 도구와 시스템은 REST API와 통신할 수 있습니다.
데이터브릭스 SQL 문 실행 API를 사용하면 표준 SQL over HTTP를 사용하여 다양한 애플리케이션, 기술 및 컴퓨팅 장치와의 통합을 구축할 수 있습니다. 이 API는 실행을 위해 SQL 문을 SQL 웨어하우스에 제출하고 결과를 검색할 수 있는 일련의 엔드포인트를 제공합니다. 아래 이미지는 일반적인 데이터 흐름에 대한 개략적인 개요를 제공합니다.
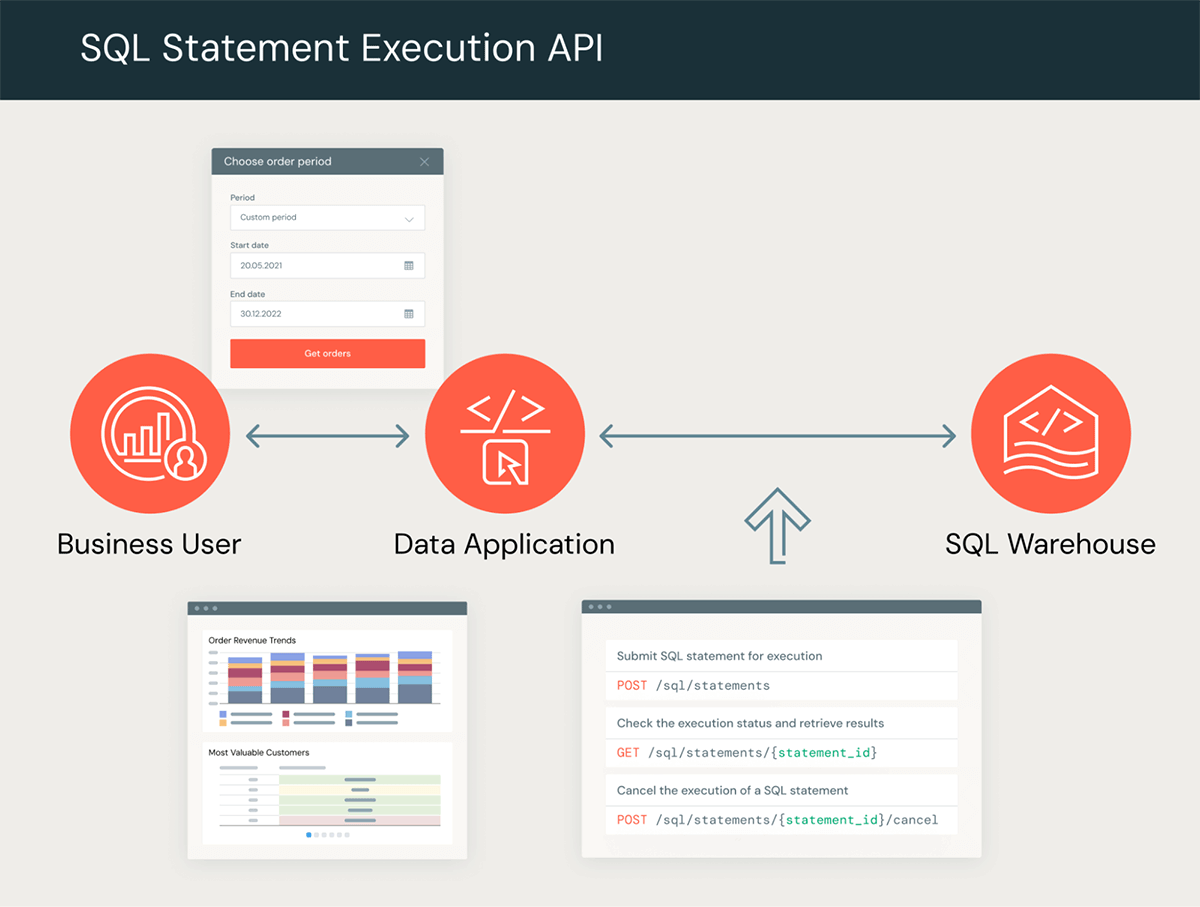
API를 사용해 원하는 도구와 언어로 맞춤형 데이터 앱을 구축할 수 있습니다. 예를 들어, 비즈니스 사용자가 사용자 인터페이스를 통해 일련의 쿼리 기준을 제공하고 시각화, 다운로드 또는 추가 분석을 위한 결과를 다시 제공받는 웹 애플리케이션을 구축할 수 있습니다. 또한 API를 사용하여 특정 사용 사례 및 마이크로서비스에 적합한 특수 목적의 API를 구현하거나 원하는 프로그래밍 언어로 사용자 지정 커넥터를 구축할 수도 있습니다. 이러한 시나리오에서 API를 사용할 때 중요한 장점 중 하나는 드라이버를 설치하거나 데이��터베이스 연결을 관리할 필요 없이 HTTP를 통해 서버에 연결하고 비동기 데이터 교환을 관리하기만 하면 된다는 것입니다.
New features available in the GA release
AWS 및 Azure에서 API가 일반에 공개됨에 따라 몇 가지 새로운 기능과 개선 사항이 추가되었습니다.
- 매개변수화된 쿼리문 - 유형 안전 매개변수를 사용하여 SQL 쿼리에 동적 리터럴 값을 안전하게 적용할 수 있습니다. 리터럴 값은 SQL 코드와 별도로 처리되므로, 데이터브릭스 SQL은 사용자가 제공한 변수와 독립적으로 코드의 로직을 해석하여 일반적인 SQL 인젝션 공격을 방지할 수 있습니다.
- 결과 보존 - 한 문에 대한 결과를 최대 1시간 동안 여러 번 다시 가져올 수 있습니다. 이전에는 마지막 청크를 읽은 후에는 더 이상 결과를 사용할 수 없었기 때문에 청크를 병렬로 가져올 때 마지막 청크를 특별히 처리해야 했습니다.
- 여러 결과 형식 - 이제 EXTERNAL_LINKS 처리를 통해 JSON_ARRAY 및 CSV 형식을 사용할 수 있습니다. 최적의 성능을 위해 여전히 Arrow를 사용할 수 있지만, 도구와 프레임워크에서 JSON과 CSV를 더 많이 지원하므로 상호 운용성이 향상됩니다.
- 바이트 및 행 제한 - 결과에 제한을 적용하여 예기치 않은 대용량 출력을 방지할 수 있습니다. API는 지정된 제한을 초과할 때마다 잘림 플래그를 반환합니다.
다음 섹션에서는 이러한 새로운 기능을 사용하여 문 실행 API 위에 사용자 지정 API를 구축하는 방법에 대해 자세히 살펴보겠습니다.
Along with the general availability of the API on AWS and Azure, we are enabling some new features and improvements.
- Parameterized statements - Safely apply dynamic literal values to your SQL queries with type-safe parameters. Literal values are handled separately from your SQL code, which allows Databricks SQL to interpret the logic of the code independently from user-supplied variables, preventing common SQL injection attacks.
- Result retention - Refetch the results for a statement multiple times for up to one hour. Previously, results were no longer available after the last chunk was read, requiring special treatment of the last chunk when fetching chunks in parallel.
- Multiple result formats - JSON_ARRAY and CSV formats are now available with the EXTERNAL_LINKS disposition. While you can still use Arrow for optimal performance, JSON and CSV are more ubiquitously supported by tools and frameworks, improving interoperability.
- Byte and row limits - Apply limits to your results to prevent unexpected large outputs. The API will return a truncation flag whenever the specified limit is exceeded.
In the next section, we will go into more detail as we use these new features to build a custom API on top of the Statement Execution API.
Build your special-purpose API
올해 데이터+AI 서밋에서는 이 새로운 명령문 실행 API를 사용하여 데이터브릭스 레이크하우스 플랫폼 위에 커스텀 API를 구축하는 과정을 안내했습니다. 그 과정을 놓치신 분들을 위해 Acme, Inc라는 가상의 회사를 위한 간단한 웹사이트와 서비스 백엔드를 개발하는 과정을 지금 다시 보여드리겠습니다. 첫 번째 단계로 `setup.sh` 스크립트를 실행하여 여기에서 코드를 따라할 수 있습니다.
Acme, Inc.는 다양한 종류의 기계 부품을 판매하는 100개의 매장을 보유한 중소기업입니다. 이 회사는 데이터브릭스 레이크하우스를 활용하여 각 매장에 대한 정보를 추적하고 메달리온 아키텍처로 판매 데이터를 처리합니다. 매장 관리자가 금 판매 데이터와 매장 정보를 쉽게 검색할 수 있는 웹 애플리케이션을 만들고자 합니다. 또한 매장 관리자가 일반 POS를 거치지 않은 판매량을 입력할 수 있도록 하려고 합니다. 이 시스템을 구축하기 위해 사용자 지정 데이터 API와 해당 API를 호출하여 데이터를 읽고 쓰는 HTML/JQuery 프런트엔드를 노출하는 Python 플라스크 애플리케이션을 만들겠습니다.
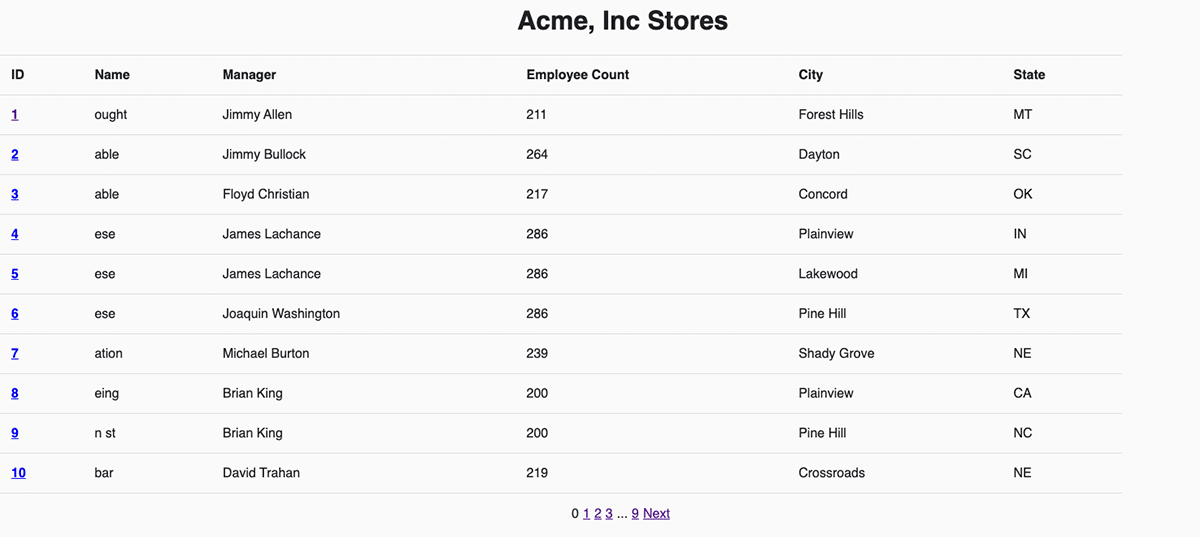
모든 스토어를 나열하는 사용자 정의 API 엔드포인트와 이것이 백엔드의 문 실행 API에 어떻게 매핑되는지 살펴보겠습니다. 인수를 받지 않는 간단한 GET 요청입니다. 백엔드는 정적 SELECT 문을 사용하여 SQL 웨어하우스로 호출하여 `stores` 테이블을 읽습니다.
| Acme Inc's API Request | Statement Execution API Request | |
|---|---|---|
| GET /stores | → | POST /sql/statements statement: "SELECT * FROM stores" wait_timeout: "50s" on_wait_timeout: "CANCEL" |
| Acme Inc's API Response | Statement Execution API Response | |
| state: "SUCCEEDED" stores: [ ["123", "Acme, Inc", …], ["456", "Databricks", …] ] |
← | statement_id: "ID123" status: { state: "SUCCEEDED" } manifest: { ... } result: { data_array: [ ["123", "Acme, Inc", …], ["456", "Databricks", …] ] } |
Acme에는 100개의 스토어만 있기 때문에 빠른 쿼리와 작은 데이터 세트가 응답에 포함될 것으로 예상됩니다. 따라서 데이터브릭스에 동기식 요청을 하고 스토어 데이터 행을 인라인으로 반환받기로 결정했습니다. 동기화하기 위해 `wait_timeout`을 설정하여 응답을 최대 50초까지 기다리도록 하고 `on_wait_timeout` 매개 변수를 설정하여 더 오래 걸리는 경우 쿼리를 취소하도록 했습니다. 데이터브릭스의 응답을 보면 기본 결과인 `disposition`과 `format`이 데이터를 인라인으로 JSON 배열로 반환한다는 것을 알 수 있습니다. 그러면 Acme의 백엔드 서비스가 해당 페이로드를 리패키징하여 사용자 지정 API의 호출자에게 반환할 수 있습니다.
이 사용자 지정 엔드포인트의 전체 백엔드 코드는 여기에서 확인할 수 있습니다. 프론트엔드에서는 사용자 지정 `/api/1.0/stores` 엔드포인트를 호출하여 스토어 목록을 가져오고 여기에 있는 JSON 배열을 반복하여 표시합니다. 이 두 가지를 통해 Acme는 데이터브릭스 SQL로 뒷받침되는 새로운 홈페이지를 갖게 되었습니다!
각 스토어에 대해 가장 최근 매출을 표시하는 페이지가 있고 스토어 관리자가 전체 스토어 데이터 세트를 다운로드할 수 있기를 원합니다. 한 가지 주목할 점은 스토어당 판매 거래의 수가 스토어 수보다 몇 배나 많을 수 있다는 것입니다. 이 사용자 지정 API 엔드포인트의 요구 사항은 다음과 같습니다:
- 제한된 출력 - 호출자가 항상 모든 데이터를 가져올 필요가 없도록 반품된 판매 수를 제한할 수 있어야 합니다.
- 다중 형식 - 웹 페이지에 쉽게 표시하거나 Excel과 같은 도구에서 오프라인 처리를 위해 다운로드할 수 있도록 결과를 여러 형식으로 검색할 수 있어야 합니다.
- 비동기 - 스토어의 판매 정보를 가져오는 데 시간이 오래 걸릴 수 있으므로 비동기식이어야 합니다.
- 효율적인 추출 - 성능과 안정성을 위해 대량의 판매 데이터를 백엔드 웹 서버를 통해 가져오지 않아야 합니다.
아래에서 이러한 요구 사항을 충족하기 위해 Python용 데이터브릭스 SDK를 사용하여 문 실행 API를 호출하는 방법을 확인할 수 있습니다. 전체 코드는 여기에서 확인할 수 있습니다.
처음 두 가지 요구 사항을 충족하기 위해 사용자 지정 API에서 `row_limit` 및 `format` 매개 변수를 노출하고 이를 문 실행 API에 전달합니다. 이렇게 하면 호출자가 쿼리에서 생성되는 총 행 수를 제한하고 결과 형식(CSV, JSON 또는 Arrow)을 선택할 수 있습니다.
사용자 지정 API를 비동기식으로 만들기 위해, 문 실행 API의 `wait_timeout` 매개변수를 0초로 설정하면, 데이터브릭스가 문 ID와 쿼리 상태로 즉시 응답하게 됩니다. 호출자에 대한 응답에서 상태와 함께 해당 문 ID를 `request_id`로 패키징합니다. 클라이언트가 요청 ID와 상태를 받으면 동일한 사용자 지정 API 엔드포인트를 폴링하여 실행 상태를 확인할 수 있습니다. 엔드포인트는 `get_statement` 메서드를 통해 요청을 데이터브릭스 SQL 웨어하우스로 전달합니다. 쿼리가 성공하면 API는 결국 'chunk_count'와 함께 `SUCCEEDED` 상태를 반환합니다. 청크 카운트는 결과가 몇 개의 파티션으로 분할되었는지를 나타냅니다.
효율적인 추출(네 번째 요구 사항)을 달성하기 위해 EXTERNAL_LINKS 처리를 사용했습니다. 이를 통해 각 청크에 대해 미리 서명된 URL을 가져올 수 있으며, 사용자 정의 API는 'request_id'와 'chunk_index'가 주어질 때 이를 반환합니다.
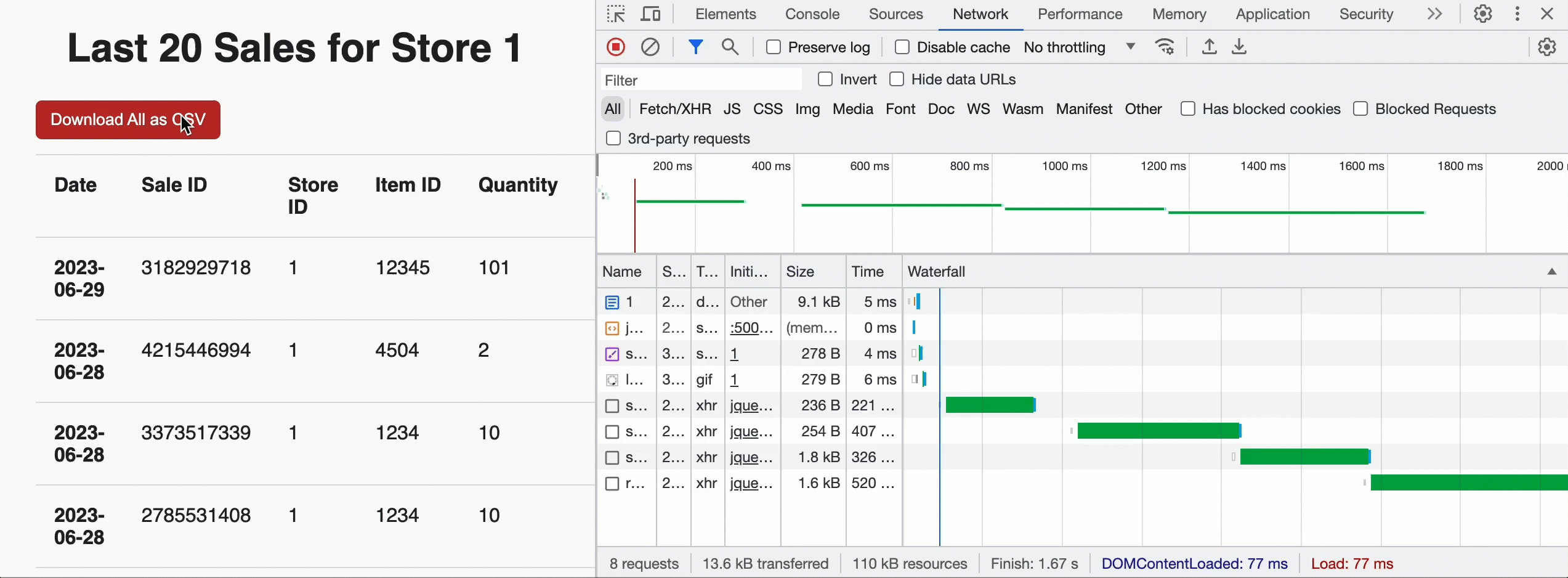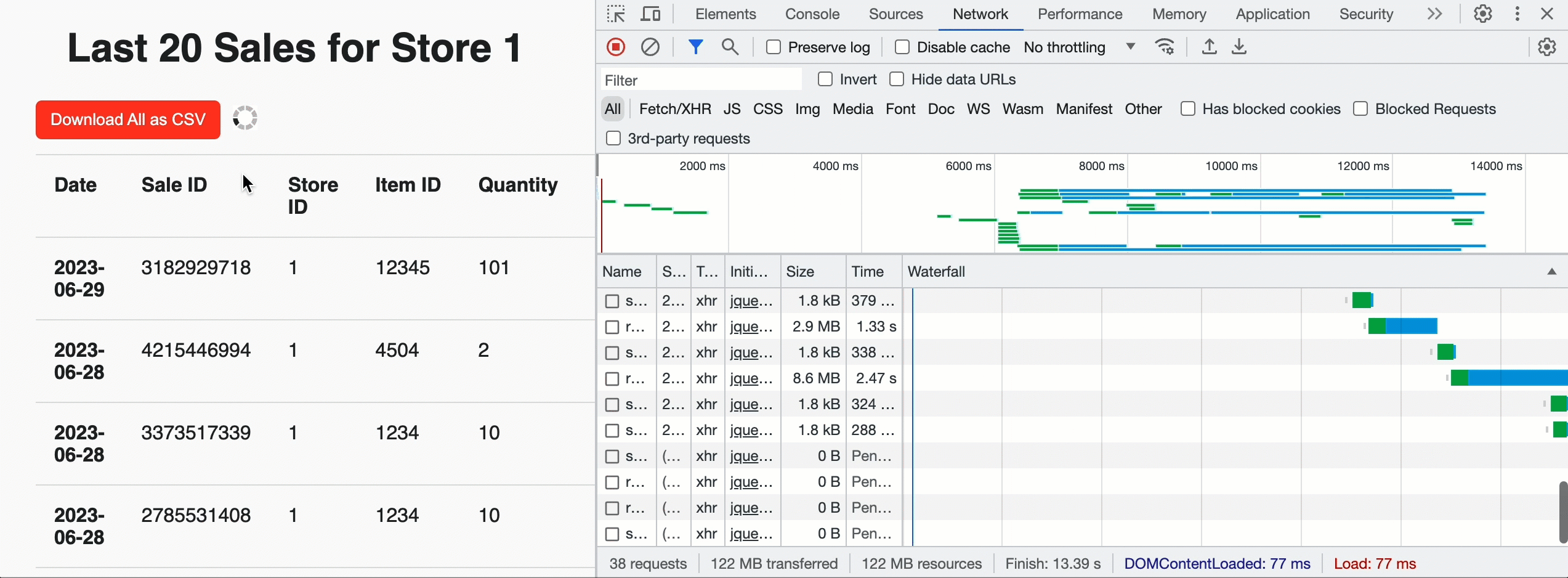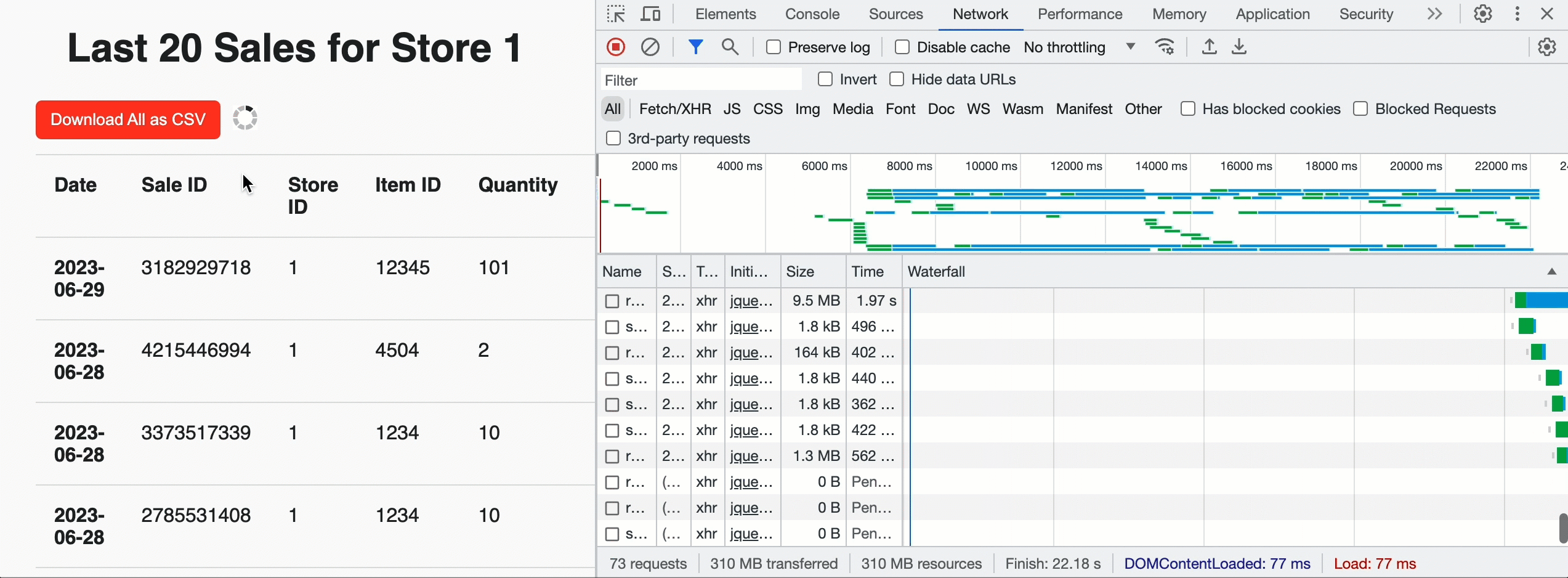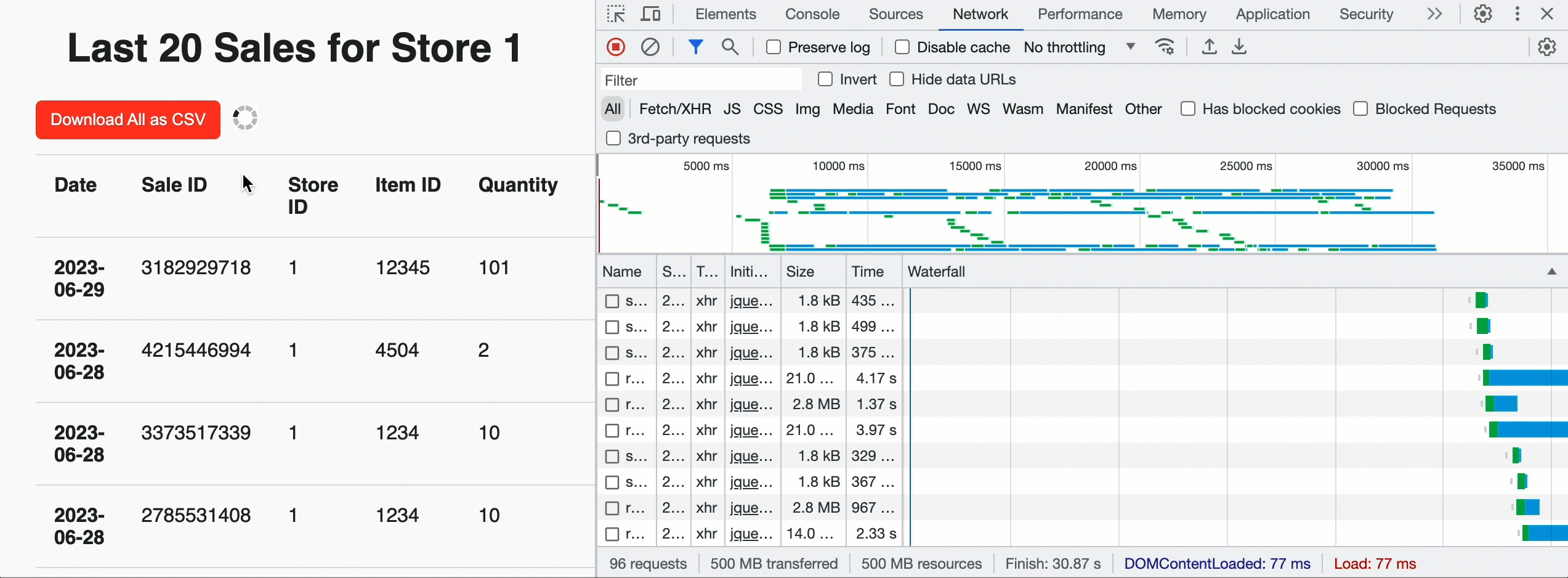
이를 사용하여 행 제한 20개와 자바스크립트 친화적인 JSON_ARRAY 결과 형식을 제공하여 각 스토어에 대해 가장 최근 매출을 표시하는 랜딩 페이지를 구축할 수 있습니다. 하지만 페이지 상단에 '다운로드' 버튼을 추가하여 스토어 관리자가 모든 판매에 대한 기록 데이터를 가져올 수 있도록 할 수도 있습니다. 이 경우, 스토어 관리자가 선택한 분석 도구로 쉽게 수집할 수 있도록 제한을 두지 않고 CSV 형식을 활용합니다. 브라우저에서 쿼리가 성공하고 총 청크 수를 확인하면 사용자 지정 API를 병렬로 호출하여 미리 서명된 URL을 가져오고 클라우드 스토리지에서 직접 CSV 데이터를 다운로드합니다. 내부적으로 EXTERNAL_LINKS 처리는 순차적 인라인 읽기에 비해 추출 처리량이 12배 향상된 것으로 입증된 Cloud Fetch 기술을 활용합니다. 아래 예시에서는 약 160Mbps로 500MB를 병렬로 다운로드했습니다.
이제 매장의 매출을 볼 수 있게 되었으니, Acme 팀은 새로운 매출 정보를 레이크하우스에 삽입할 수 있어야 합니다. 이를 위해 /api/1.0/stores/storeId/sales 엔드포인트에 대한 POST 요청으로 뒷받침되는 간단한 웹 양식을 만들 수 있습니다. 양식 데이터를 레이크하우스로 가져오기 위해 매개변수화된 SQL 문을 사용합니다:
그리고 각 매개변수의 이름, 값, 유형과 함께 `parameters` 목록 인수를 사용하여 웹 양식의 입력을 문 실행 API에 제공합니다:
SQL Warehouse 엔진은 SQL 코드를 파싱한 후 제공된 매개변수를 쿼리 계획에 리터럴로 안전하게 대체합니다. 이렇게 하면 악의적으로 삽입된 SQL 구문이 SQL로 해석되는 것을 방지할 수 있습니다. 각 매개변수의 '유형' 필드는 제공된 '값'의 유형 정확성을 검사하여 추가적인 안전 계층을 제공합니다. 악의적인 사용자가 수량 필드의 입력으로 "100); drop table sales"와 같은 값을 제공하면 INSERT INTO 문은 다음과 같은 오류를 발생시키고 실행되지 않습니다:
[INVALID_PARAMETER_MARKER_VALUE.INVALID_VALUE_FOR_DATA_TYPE] An invalid parameter mapping was provided: the value '100); drop table sales' for parameter 'quantity' cannot be cast to INT because it is malformed.
여기에서 `POST /api/1.0/stores/store_id/sales` 엔드포인트의 일부로 사용할 매개 변수를 넣는 방법을 확인할 수 있습니다. 웹 양식의 입력이 올바른 유형으로 유효하면 사용자가 '제출'을 클릭한 후 판매 테이블이 성공적으로 업데이트됩니다.
이제 이 사용자 정의 API를 반복하거나 데이터브릭스 레이크하우스 플랫폼 위에 자신만의 사용자 정의 데이터 애플리케이션을 구축하기 위한 디딤돌로 사용할 수 있습니다. 이 글 전체에서 사용한 샘플 코드와 자체 데이터브릭스 환경에서 샘플 테이블을 생성하는 `setup.sh` 스크립트를 사용하는 것 외에도, 아래 동영상에서 데이터+AI 서밋의 라이브 설명을 시청할 수 있습니다.
Getting started with the Databricks SQL Statement Execution API
The Databricks SQL Statement Execution API is available with the Databricks Premium and Enterprise tiers. If you already have a Databricks account, follow our tutorial (AWS | Azure), the documentation (AWS | Azure), or check our repository of code samples. If you are not an existing Databricks customer, sign up for a free trial.
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.