Databricks SQL Statement Execution API – Announcing the Public Preview
by Adriana Ispas, Bogdan Ionut Ghit, Ben Fleis and Pearl Ubaru
Today, we are excited to announce the public preview of the Databricks SQL Statement Execution API, available on AWS and Azure. You can now connect to your Databricks SQL warehouse over a REST API to access and manipulate data managed by the Databricks Lakehouse Platform.
The Databricks SQL Statement Execution API simplifies access to your data and makes it easier to build data applications tailored to your needs. The API is asynchronous, which removes the need to manage connections like you do with JDBC or ODBC. Moreover, you can connect to your SQL warehouse without having to first install a driver. You can use the Statement Execution API to connect your traditional and Cloud-based applications, services and devices to Databricks SQL. You can also create custom client libraries for your programming language of choice.
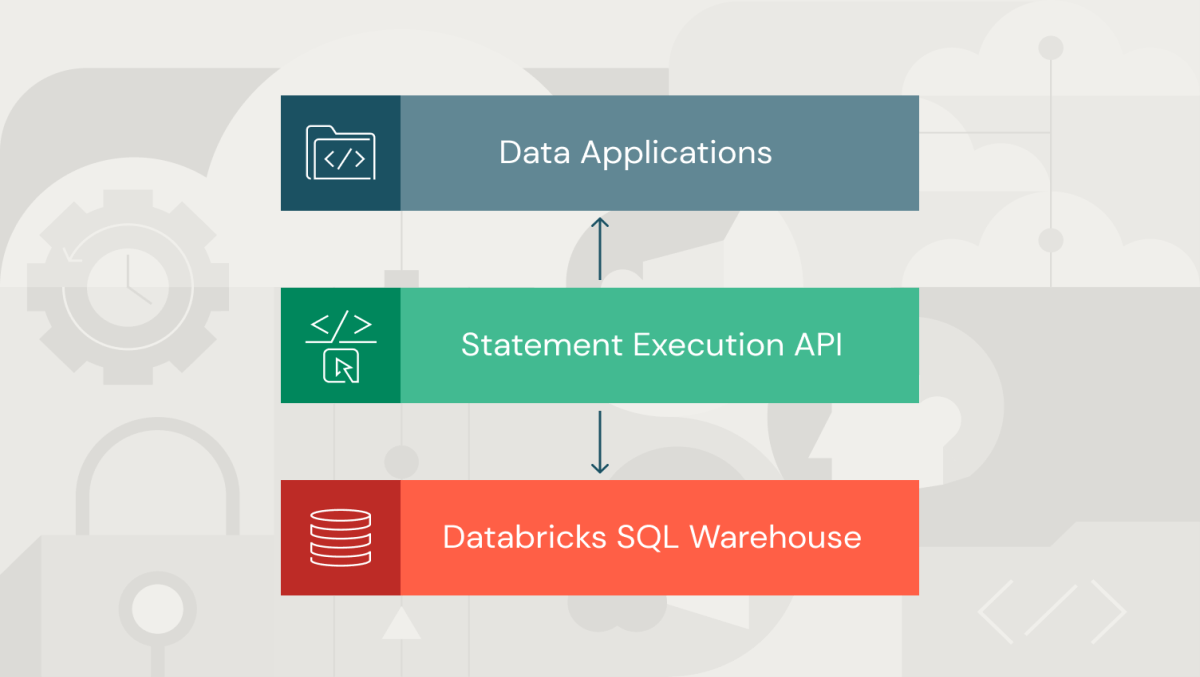
In this blog, we review some key features available in the public preview and show how to leverage your data in a spreadsheet using the Statement Execution API and JavaScript.
Statement Execution API in brief
The Statement Execution API manages the execution of SQL statements and fetching of result data on all types of Databricks SQL warehouses via HTTP endpoints for the following operations:
| Submit a SQL statement for execution | POST /sql/statements |
| Check the status and retrieve results | GET /sql/statements/{statement_id} |
| Cancel a SQL statement execution | POST /sql/statements/{statement_id}/cancel |
For example, let's assume we want to retrieve the monthly order revenue for the current year for display in our data application. Assuming data on orders is already managed by our Lakehouse, a SQL statement could be as shown below:
We can initiate the execution of our SQL statement by sending a POST request to the /api/2.0/sql/statements endpoint. The string representing the SQL statement is provided as a request body payload, along with the ID of a SQL warehouse to be used for executing the statement. The HTTP request must also contain the host component of your Databricks workspace URL and an access token for authentication.
If the statement completes quickly, the API returns the results as a direct response to the POST request. Below is an example response:
If the statement takes longer, the API continues asynchronously. In this case, the response contains a statement ID and a status.
You can use the statement ID to check the execution status and, if ready, retrieve the results by sending a GET request to the /api/2.0/sql/statements/{statement_id} endpoint:
You can also use the statement ID to cancel the request by sending a POST request to the /api/2.0/sql/statements/cancel endpoint.
The API can be configured to behave synchronously or asynchronously by further configuring your requests. To find out more, check the tutorial (AWS | Azure) and the documentation (AWS | Azure).
Using the Databricks SQL Statement Execution API in JavaScript
You can send Databricks SQL Statement Execution API requests from any programming language. You can use methods like the Fetch API in JavaScript; Python Requests in Python; the net/http package in Go, and so on.
We show how you can use the Statement Execution API to populate a Google Sheet using the JavaScript Fetch API from a Spreadsheet App.
Example Spreadsheet app
Let's imagine we want to build a Google Spreadsheet App that populates a spreadsheet with data on orders. Our users can fetch monthly order revenue data based on predefined criteria, such as the monthly order revenue for the current month, the current year, or between a start and an end date. For each criterion, we can write corresponding SQL statements, submit them for execution, fetch and handle the results using the Statement Execution API.
In the next section, we outline the main building blocks to implement this example. To follow along, you can download the spreadsheet from GitHub.
Building the Spreadsheet App
Given a statement that we want to execute using the SQL Statement API, the executeStatement function below captures the overall logic for handling the default mode of the API. In this mode, statement executions start synchronously and continue asynchronously after a default timeout of 10 seconds.
We start by submitting a statement for execution using the submitStatement function. If the statement completes within the defined timeout, we fetch the results by calling the handleResult function. Otherwise, the execution proceeds asynchronously, which means we need to poll for the execution status until completion – the checkStatus function covers the required logic. Once finished, we retrieve the results using the same handleResult function.
The submitStatement function defines the request body where we set execution parameters such as the wait timeout of 10 seconds (default), the execution mode and the SQL statement. It further invokes a generic fetchFromUrl function for submitting an HTTP request. We also define a HTTP_REQUEST_BASE constant to pass in the access token for the Databricks workspace user. We will reuse this constant for all HTTP requests we will be making.
The fetchFromUrl function is a generic function for submitting HTTP requests with minimal error handling, as shown below.
In the checkStatus function, if the wait timeout is exceeded, we poll the server to retrieve the status of the statement execution and determine when the results are ready to fetch.
In the handleResult function, if the statement has completed successfully and the results are available, a fetch response will always contain the first chunk of rows. The function handles the result and attempts to fetch the subsequent chunks if available.
All that is left is to connect the executeStatement function to JavaScript event handlers for the various user interface widgets, passing in the SQL statement corresponding to the user selection. The Google Apps Script documentation provides instructions on populating the spreadsheet with the returned data.
Getting started with the Databricks SQL Statement Execution API
The Databricks SQL Statement Execution API is available with the Databricks Premium and Enterprise tiers. If you already have a Databricks account, follow our tutorial (AWS | Azure), the documentation (AWS | Azure), or check our repository of code samples. If you are not an existing Databricks customer, sign up for a free trial.
The Databricks SQL Statement Execution API complements the wide range of options to connect to your Databricks SQL warehouse. Check our previous blog post to learn more about native connectivity to Python, Go, Node.js, the CLI, and ODBC/JDBC. Data managed by the Databricks Lakehouse Platform can truly be accessed from anywhere!
Join us at the Data + AI Summit 2023 to learn more about the Databricks SQL Statement Execution API and to get updates on what is coming next.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.