Python 데이터 소스 API 정식 출시
Python의 단순함으로 사용자 지정 데이터 연결을 활용해 보세요
작성자: Allison Wang, Jules Damji, 라이언 닌하우스 , Huanli Wang
- 이제 개발자는 풍부한 Python 생태계를 통해 다양한 데이터 소스와 통합하면서 Python을 사용하여 맞춤형 Spark 커넥터를 구축할 수 있습니다.
- Python 데이터 소스 API는 배치 및 스트리밍 워크로드를 지원하여 정형 및 비정형 소스 전반에서 데이터를 실시간으로 수집하고 목적지에 쓰는 파이프라인을 구현할 수 있습니다.
- Databricks의 Unity Catalog 통합을 통해 개발자는 데이터 리니지, 액세스 제어, 감사 기능을 사용하여 외부 데이터를 거버넌스, 보호 및 운영할 수 있습니다.
- Python 데이터 소스로 구현된 Declarative Pipeline 싱크를 사용하여 Declarative Pipelines를 통해 외부 서비스로 레코드를 스트리밍할 수 있습니다.
Databricks Runtime(DBR) 15.4 LTS 이상에서 실행되는 Apache Spark™ 4.0용 PySpark의 데이터 소스 API가 정식 출시(GA)되었음을 알려드리게 되어 기쁩니다. 이 강력한 기능은 개발자가 순수 Python을 사용하여 Spark로 사용자 지정 데이터 커넥터를 빌드할 수 있도록 지원합니다. 외부 및 Spark 네이티브가 아닌 데이터 소스와의 통합을 간소화하여 데이터 파이프라인 및 머신러닝 워크플로에 새로운 가능성을 열어줍니다.
이것이 중요한 이유
오늘날 데이터는 정형, 비정형, 그리고 이미지와 동영상과 같은 멀티모달 데이터 등 다양한 소스에서 수집됩니다. Spark는 Delta, Iceberg, Parquet, JSON, CSV, JDBC와 같은 데이터 소스 v1(DSv1) 및 데이터 소스 v2(DSv2) 표준 형식을 기본적으로 지원합니다. 하지만 Google Sheets, REST API, HuggingFace 데이터 세트, X의 트윗 또는 독점적인 내부 시스템과 같은 다른 많은 소스에 대한 내장 지원은 제공하지 않습니다. DSv1/DSv2를 기술적으로 확장하여 이러한 소스를 구현할 수는 있지만, 경량 사용 사례의 경우 그 과정이 지나치게 복잡하고 불필요한 경우가 많습니다.
사용 사례를 위해 다른 맞춤형 데이터 소스에서 읽거나 써야 하는 경우, 또는 머신 러닝 사용 사례를 위한 ETL 파이프라인에서 모델 학습을 위해 이 데이터를 사용해야 하는 경우는 어떻게 해야 할까요? Python 데이터 소스 API가 바로 이러한 격차를 해소합니다.
이 블로그에서는 PySpark에서 사용자 지정 데이터 소스를 작성하는 방법을 살펴봅니다. 이 API를 사용하면 특정 사용 사례에 맞게 Spark에 내장되지 않은 다양한 데이터 세트를 데이터 처리 파이프라인으로 쉽게 가져올 수 있습니다. 또한 사용자 지정 데이터 소스의 몇 가지 예시도 살펴볼 것입니다. 하지만 먼저 그 이유와 내용에 대해 알아보겠습니다.
Python 데이터 소스 API란 무엇인가요?
Python으로 작성하는 것에 대한 사람들의 애정과 pip를 통해 패키지를 쉽게 설치할 수 있다는 점에서 영감을 받은 Python 데이터 소스 API는 Python을 사용하여 Spark용 맞춤형 리더 및 라이터를 쉽게 빌드할 수 있게 해줍니다. 이 API는 모든 데이터 소스에 대한 액세스를 지원하므로, 이전에는 맞춤형 커넥터에 필요했던 복잡한 DSv1 및 DSv2 개발이나 Spark 내부에 대한 지식이 필요하지 않습니다.
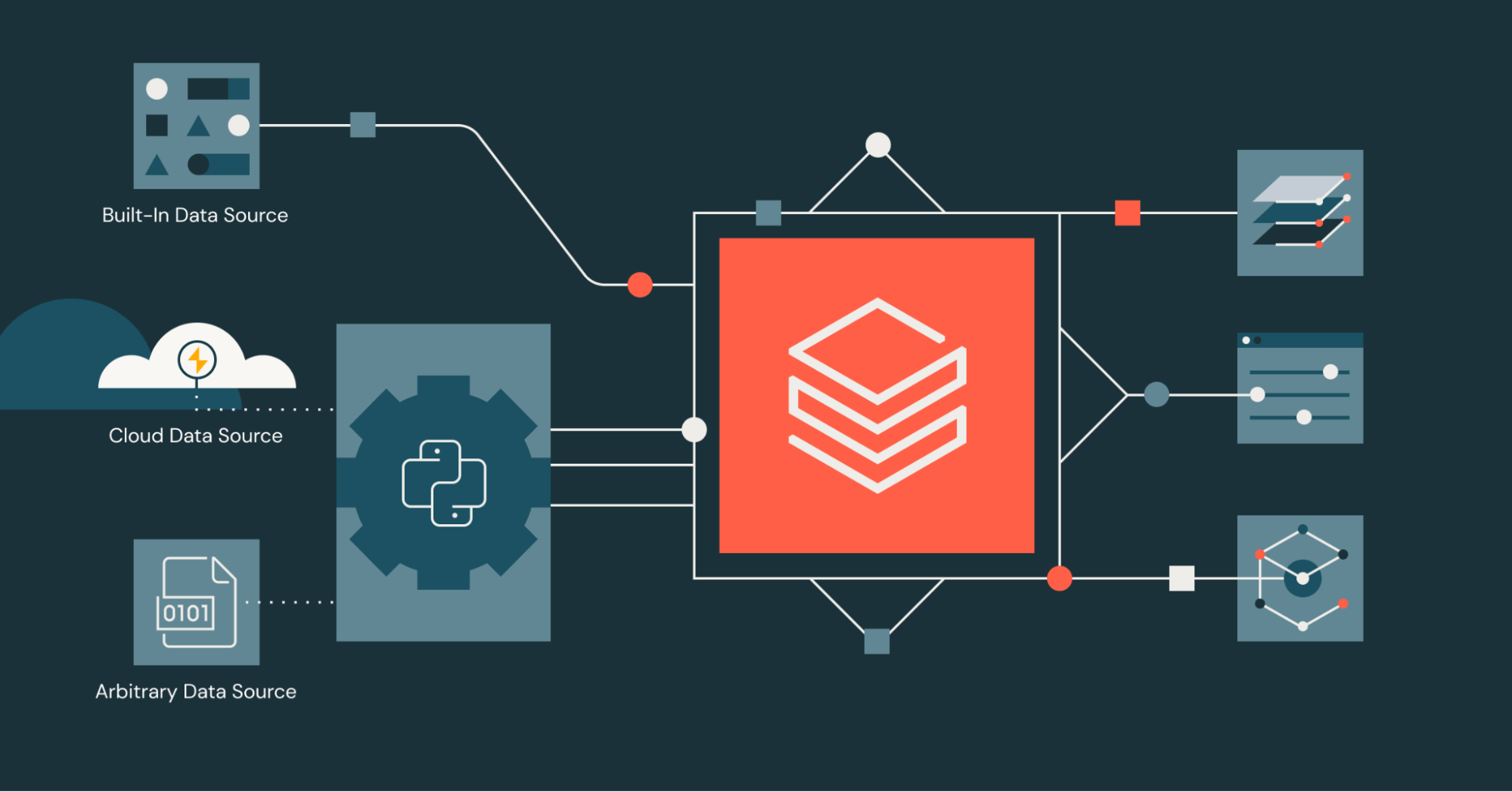
주요 기능 및 이점은 무엇인가요?
Python 데이터 소스를 사용하면 몇 가지 주요 이점이 있습니다.
1. 순수 Python 구현
Pythonic한 느낌을 먼저 고려하세요. Python 데이터 소스 API는 더 복잡한 JVM 기반 커넥터 개발의 장벽을 제거합니다. Python에서 수많은 데이터 소스를 사용하여 복잡한 ETL 파이프라인을 구축하는 데이터 엔지니어는 이제 Spark의 내부 복잡성에 대해 깊이 파고들지 않고도 기존 Python 기술을 활용하여 맞춤형 커넥터를 만들 수 있습니다.
2. 배치 및 스트리밍 작업 모두 지원
API는 배치 및 스트리밍 읽기를 모두 지원하므로 여러 데이터 액세스 패턴을 처리하는 커넥터를 빌드할 수 있습니다.
- 배치 읽기: 단일 작업으로 API, 데이터베이스 또는 기타 소스에서 데이터를 가져옵니다.
- 스트림 읽기: 이벤트 기반 또는 실시간 소스에서 데이터를 지속적으로 수집합니다
- 배치 및 스트림 쓰기: 선언적 파이프라인 싱크를 포함하여 데이터 싱크에 씁니다.
3. SQL에서의 접근성
Spark SQL에서 지원되는 모든 데이터 소스와 마찬가지로 사용자 지정 Python 데이터 소스에도 Spark SQL을 통해 동일하게 쉽게 액세스할 수 있습니다. 데이터 소스가 DataFrame으로 로드되면 임시 뷰 또는 영구적인 Unity Catalog 관리형 테이블로 저장할 수 있습니다. 이를 통해 다운스트림 SQL 분석에 사용자 지정 데이터 소스를 통합할 수 있습니다.
4. 외부 ��서비스와의 간소화된 통합
DataFrame API를 사용하여 API 키, 엔드포인트 또는 기타 구성과 같은 맞춤형 옵션을 전달함으로써 외부 시스템에 쉽게 연결할 수 있습니다. 이를 통해 커넥터의 작동 방식을 완전히 제어할 수 있습니다. 자세한 내용은 아래의 실제 사례를 참조하세요.
5. 커뮤니티 주도 커넥터 생태계
미리보기 출시 이후 커뮤니티는 이미 Python 데이터 소스 API를 사용하여 가치 있는 커넥터를 구축하기 시작했습니다.
- 예시 커넥터: REST API, CSV 변형 등에 대한 참조 구현 (GitHub 리포지토리)
- HuggingFace 커넥터: HuggingFace의 데이터 세트에 직접 액세스 (GitHub 리포지토리)
6. 복잡성 없이 빠른 속도
Python 데이터 소스 API는 사용 편의성뿐만 아니라 속도도 고려하여 설계되었습니다. 빠른 데이터 처리에 최적화된 인메모리 데이터 형식인 Apache Arrow를 기반으로 구축되었습니다. 이는 사용자 지정 커넥터와 Spark 간에 데이터를 최소한의 오버헤드로 이동할 수 있어 수집 및 쓰기 속도가 훨씬 빨라진다는 것을 의미합니다.
Python 데이터 소스의 실제 사용 사례
Python 데이터 소스를 사용하여 파이프라인에 데이터를 공급하는 실제 사용 사례를 살펴보겠습니다.
맞춤형 API 통합
먼저 REST API를 통합하여 얻�을 수 있는 이점을 살펴보겠습니다.
많은 데이터 엔지니어링 팀이 REST API에서 데이터를 가져와 다운스트림 변환에 사용하기 위해 사용자 지정 커넥터를 구축하고 있습니다. 데이터를 가져와 디스크나 메모리에 저장한 다음 Spark에 로드하기 위해 사용자 지정 코드를 작성하는 대신, Python 데이터 소스 API를 사용하여 이러한 단계를 건너뛸 수 있습니다.
사용자 지정 데이터 소스를 사용하면 API에서 Spark DataFrame으로 데이터를 직접 읽을 수 있으며 중간 저장소가 필요하지 않습니다. 예를 들어, 다음은 REST API 호출에서 전체 출력을 가져와 Spark로 바로 로드하는 방법입니다.
REST API 데이터 소스와 전체 구현은 참조 예시로 여기 에 있습니다.
Unity Catalog 통합
두 번째 통합은 데이터 카탈로그와의 통합입니다. 점점 더 많은 기업 개발자들이 중앙 집중식 데이터 거버넌스 및 보안을 위해 Unity Catalog와 같은 데이터 카탈로그를 사용하여 AI 및 데이터 자산을 중앙 리포지토리에 저장하고 있습니다. 이러한 두 번째 트렌드가 계속됨에 따라, 데이터 파이프라인 작업은 안전하고 통제된 방식으로 이러한 데이터 자산을 읽고 쓸 수 있어야 합니다.
이러한 맞춤형 데이터 소스에서 직접 데이터를 읽고 Unity Catalog 테이블에 쓸 수 있으며, 이를 통해 모든 소스의 데이터에 거버넌스, 보안 및 검색 가능성을 부여할 수 있습니다.
이 통합을 통해 특화된 소스의 데이터를 Unity Catalog를 통해 적절하게 관리하고 보안할 수 있습니다.
머신러닝 파이프라인 통합
세 번째 통합은 머신러닝 외부 데이터 세트와의 통합입니다. 데이터 과학자는 Python Data Source API 를 사용하여 특화된 Machine Learning(ML) 데이터 세트 및 모델 리포지토리에 직접 연결합니다. HuggingFace에는 고전적인 ML 모델의 훈련 및 테스트를 위해 특별히 큐레이션된 수많은 데이터 세트가 있습니다.
이 데이터 세트를 Spark DataFrame으로 가져오려면 HuggingFace 커넥터를 사용할 수 있습니다. 이 커넥터는 Python 데이터 소스 API의 강력한 기능을 활용하여 데이터 파이프라인에 통합할 수 있는 ML 자산을 쉽게 가져옵니다.
가져온 후에는 적절한 Spark DataFrame을 관련 머신러닝 알고리즘과 함께 사용하여 모델을 훈련, 테스트 및 평가할 수 있습니다. 심플
더 많은 예시는 HuggingFace DataSource Connector를 확인하세요.
사용자 지정 소스를 사용한 스트림 처리
또한 네 번째 통합 지점으로서 스트리밍 데이터 소스는 스토리지의 정적 소스만큼이나 일일 ETL 파이프라인의 중요한 부분입니다. 데이터를 지속적으로 수집하는 커스텀 소스로 스트리밍 애플리케이션을 구축할 수도 있습니다.
다음은 OpenSky Network API에서 실시간 항공기 ��추적 데이터를 스트리밍하기 위한 맞춤형 Spark 데이터 소스 코드 스니펫입니다. 커뮤니티 기반 수신기 네트워크인 OpenSky Network는 항공 교통 감시 데이터를 수집하여 연구자와 애호가들에게 오픈 데이터로 제공합니다. 이 스트리밍 맞춤형 데이터 소스의 전체 구현을 보려면 여기 GitHub 소스를 확인하세요.
선언적 파이프라인 통합
마지막으로, 데이터 엔지니어는 Python 데이터 소스를 선언적 파이프라인 통합(Declarative Pipeline Integration)과 쉽게 통합할 수 있습니다.
사용자 지정 데이터 원본에서 읽기
Declarative Pipeline에서 맞춤형 데이터 소스로부터 데이터를 수집하는 것은 일반적인 Databricks 작업에서와 동일한 방식으로 작동합니다.
사용자 정의 데이터 소스를 통해 외부 서비스에 쓰기
이 예제 블로그에서 Alex Ott는 새로운 선언적 파이프라인 싱크 API를 통해 외부 Delta 테이블이나 Kafka 같은 다른 스트리밍 대상을 가리키는 싱크 객체 를 내장 데이터 소스로 사용하는 방법을 보여줍니다.
하지만 Python 데이터 소스로 구현된 맞춤형 싱크에 쓸 수도 있습니다. 아래 코드의 맞춤형 Python 데이터 소스에서, 저희는 싱크 API를 사용하여 싱크를 만들고 그것을 'sink' 객체로 사용합니다. 정의하고 개발한 후에는 플로우를 추가할 수 있습니다. 이 코드의 전체 구현은 여기에서 살펴보실 수 있습니다.
나만의 맞춤형 커넥터 구축하기
Python 데이터 소스 API를 사용하여 맞춤형 커넥터 빌드를 시작하려면 다음 네 단계를 따르세요.
- Spark 4.0 또는 Databricks Runtime 15.4 LTS 이상 버전이 있는지 확인하세요: Python 데이터 소스 API는 DBR 15.4 LTS 이상 버전 또는 Databricks Serverless Generic Compute에서 사용할 수 있습니다.
- 구현 템플릿 사용: pyspark.sql.datasource 모듈의 기본 클래스를 참조하세요.
- 커넥터 등록: Databricks 작업 공간에서 커넥터를 검색할 수 있도록 설정합니다.
커넥터 사용: 커넥터를 내장된 데이터 원본과 동일하게 사용할 수 있습니다.
Python 데이터 소스 API를 사용한 고객 성공 사례
Shell에서는 데이터 엔지니어들이 Apache Kafka와 같은 내장 Spark 소스의 데이터와 REST API 또는 SDK를 통해 액세스하는 외부 소스의 데이터를 결합해야 하는 경우가 많았습니다. 이로 인해 유지 관리가 어렵고 팀 간에 일관성이 없는 일회성 또는 맞춤형 코드가 만들어졌습니다. Shell의 최고 디지털 기술 책임자는 이로 인해 시간이 낭비되고 복잡성이 가중된다고 �언급했습니다.
“저희는 스트리밍 사용 사례를 포함하여 멋진 REST API를 많이 작성하는데, 모든 연결 코드를 직접 작성하는 대신 Databricks에서 데이터 소스로 바로 사용하고 싶습니다.” — Bryce Bartmann, Shell 최고 디지털 기술 고문.
Shell 데이터 엔지니어들은 멋진 REST API를 활용하기 위해 새로운 Python 사용자 지정 데이터 소스 API를 사용하여 자사의 REST API를 데이터 소스로 구현했습니다. 이를 통해 개발자는 API 및 기타 비표준 소스를 일급 Spark 데이터 소스로 취급할 수 있었습니다. 객체 지향 추상화를 통해 사용자 지정 로직을 깔끔하게 추가하기가 더 쉬워졌으며 더 이상 지저분한 글루 코드가 필요 없습니다.
결론
요약하자면, PySpark의 Python 데이터 소스 API를 사용하면 Python 개발자는 Spark 내부에 대한 깊은 지식이 없어도 친숙하고 멋진 Python을 사용하여 Apache Spark™에 사용자 정의 데이터를 가져올 수 있으며, 단순성과 성능을 결합할 수 있습니다. REST API에 연결하거나 HuggingFace와 같은 머신러닝 데이터 세트에 액세스하거나 소셜 플랫폼에서 데이터를 스트리밍하는 등 어떤 경우든 이 API는 깔끔한 Pythonic 인터페이스로 사용자 정의 커넥터 개발을 단순화합니다. JVM 기반 커넥터의 복잡성을 우회하고 데이터 팀이 PySpark 및 SQL에서 직접 소스를 구축, 등록, 사용할 수 있는 유연성을 제공합니다.
API는 배치 및 스트리밍 워크로드를 지원하고 Unity Catalog와 통합하여 외부 데이터에 대한 거버넌스와 액세스를 보장합니다. 실시간 ML 파이프라인부터 분석 또는 데이터 수집에 이르기까지 Python 데이터 소스 API는 Spark를 확장 가��능한 데이터 플랫폼으로 전환합니다.
향후 로드맵
Python 데이터 소스 API가 계속 발전함에 따라, 저희는 다음과 같은 몇 가지 향후 개선 사항을 기대하고 있습니다.
- Column Pruning 및 Filter Pushdown: 필터링 및 열 선택을 소스에 더 가깝게 이동하여 데이터 전송을 최적화하는 더 정교한 기능
- 사용자 지정 통계 지원: 커넥터가 소스별 통계를 제공하여 쿼리 계획 및 최적화를 개선할 수 있도록 합니다.
- 향상된 관찰 가능성 및 디버깅 가능성: 커넥터 개발 및 문제 해결을 간소화하는 향상된 로깅 도구
- 확장된 예제 라이브러리: 익숙한 데이터 소스 및 사용 패턴을 위한 더 많은 참조 구현
- 성능 최적화: 직렬화 오버헤드를 줄이고 처리량을 높이기 위한 지속적인 개선
오늘 사용해 보세요
Python 데이터 소스 API는 이제 Databricks Runtime 15.4 LTS 이상 및 Serverless 환경 을 포함한 Databricks Intelligence Platform 전반에서 정식으로 사용할 수 있습니다.
맞춤형 커넥터를 구축하여 모든 데이터 소스를 데이터 Lakehouse와 통합해 보세요! 또한 Data + AI Summit 2025에서 발표된 다음 강연을 통해 다른 사람들이 Python DataSource를 구현한 방법을 알아보세요.
- 장벽 허물기: Python으로 사용자 지정 Apache Spark™ 4.0 데이터 원본 커넥터 구축
- PySpark 4.0으로 사용자 지정 PySpark 스트림 리더 만들기
- 새로운 Python Source API로 데이터 수집 및 내보내기 단순화
자세한 정보가 필요하신가요? 맞춤형 Python 데이터 소스 API 데모가 필요하시면 문의 하시거나 설명서 를 참조하여 시작해 보세요.
설명서 및 리소스
- Python 데이터 소스 설명서
- 선언적 파이프라인
- 선언적 파이프라인이 포함된 싱크
- 예제 커넥터 리포지토리
- HuggingFace 커넥터
- 사이버 보안 사용 사례를 위한 최신 Declarative Pipelines 기능의 효율적인 사용
- Delta Live Tables 레시피: Unity Catalog 서비스 자격 증명을 사용하여 Azure Event Hubs에서 사용
- PySpark를 위한 새로운 데이터 소스 API
- HuggingFace AI Datasets용 Apache Spark™ 데이터 소스
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.