Lakebase 변경 데이터 피드(CDF) 발표
OLTP 데이터베이스를 다른 엔진에 개방
작성자: Pranav Aurora, Cheng Chen , Hristo Stoyanov
- Lakebase 변경 데이터 피드(공개 미리 보기)는 운영 데이터베이스의 파이프라인 확산을 제거합니다. Lakebase 프로젝트당 CDF를 한 번만 켜면 Unity Catalog 관리 테이블을 통해 모든 테이블의 변경 사항을 노출하여 모든 엔진, 모델 또는 에이전트가 직접 액세스할 수 있습니다.
- 네이티브 CDC는 사이드카 인프라 없이 엔드투엔드로 거버넌스됩니다. 데이터베이�스 커넥터, 복제 상태 모니터링 또는 별도의 추출 작업이 필요 없습니다. SDP 스트리밍 파이프라인, DBSQL 구체화된 뷰 및 에이전트 브릭 임베딩과 같은 다운스트림 소비자는 기본 워크로드에 영향을 주지 않고 동일한 격리된 피드를 구독합니다.
- 운영 데이터는 이제 메달리온 아키텍처의 기본 브론즈 계층 역할을 합니다. Lakebase 동기화된 테이블은 이미 골드 데이터를 애플리케이션에 제공하고 있으며, Lakebase CDF는 데이터 수명 주기 전반에 걸쳐 완전한 Unity Catalog 거버넌스와 계보를 통해 루프를 닫습니다.
운영 데이터베이스에서 데이터를 이동하는 것은 전통적으로 각 소스에서 각 대상까지 파이프라인을 설정하고 모니터링하는 것을 의미했습니다. 대부분의 팀에게 이는 취약하고, 거버넌스가 없으며, O(n)의 인적 노력이 필요한 작업입니다.
오늘, 저희는 이 접근 방식을 바꾸고 있습니다. 현재 공개 미리 보기로 제공되는 Lakebase는 Unity Catalog 관리 테이블에 저장되고 거버넌스되는 변경 데이터 피드(CDF)를 특징으로 합니다. 피드를 한 번만 활성화하면 모든 엔진, 모델 및 에이전트가 직접 읽을 수 있습니다.
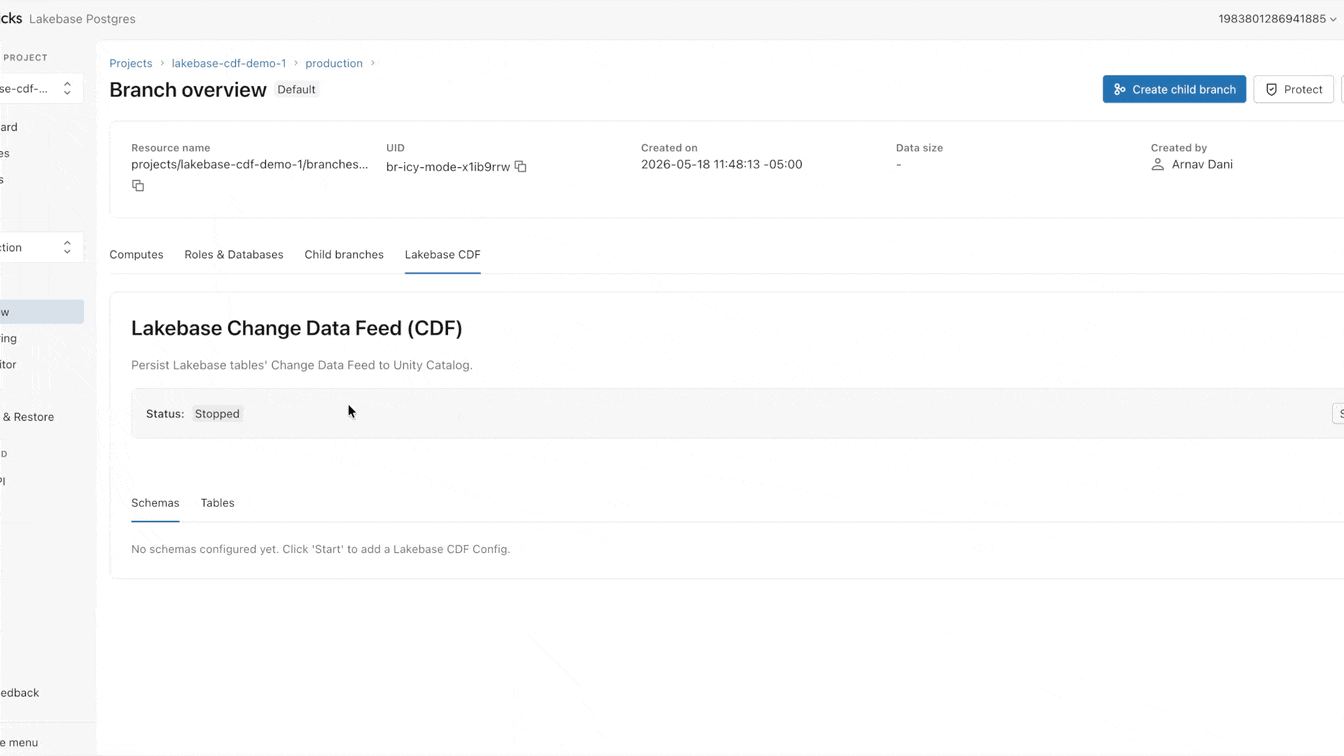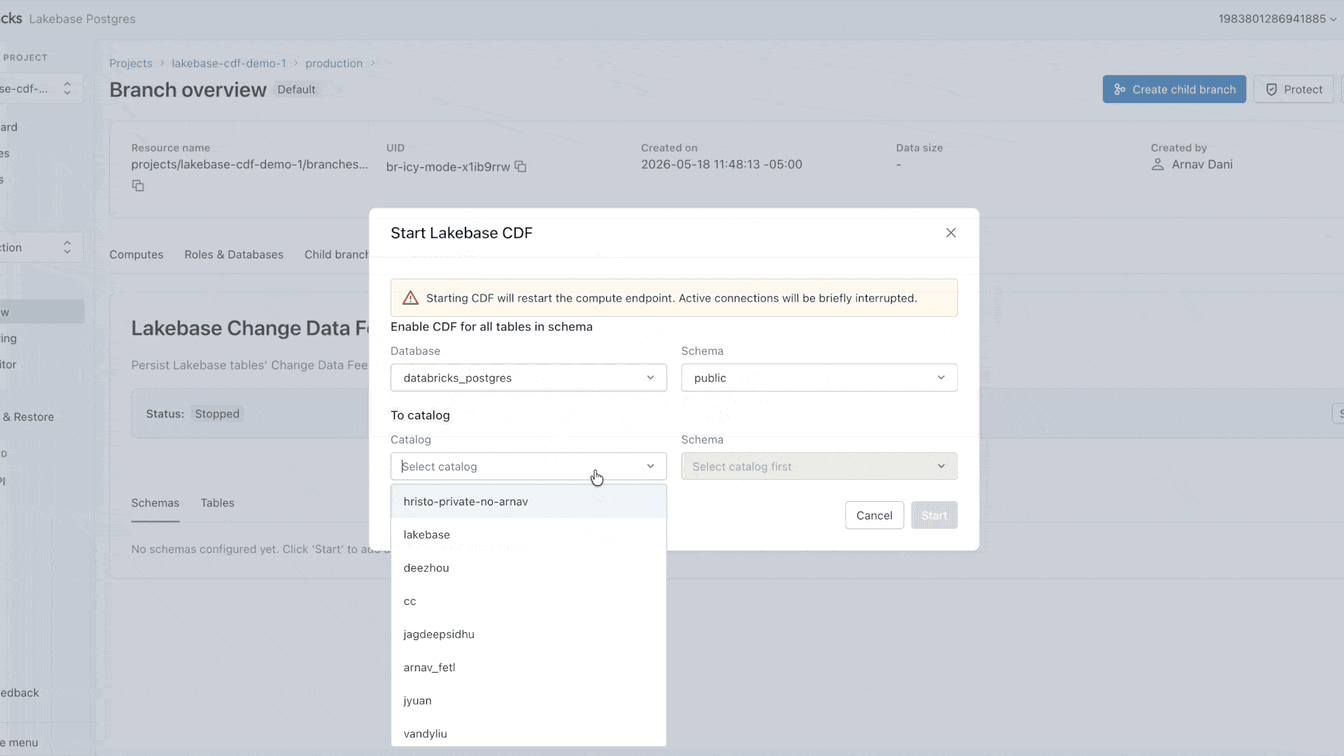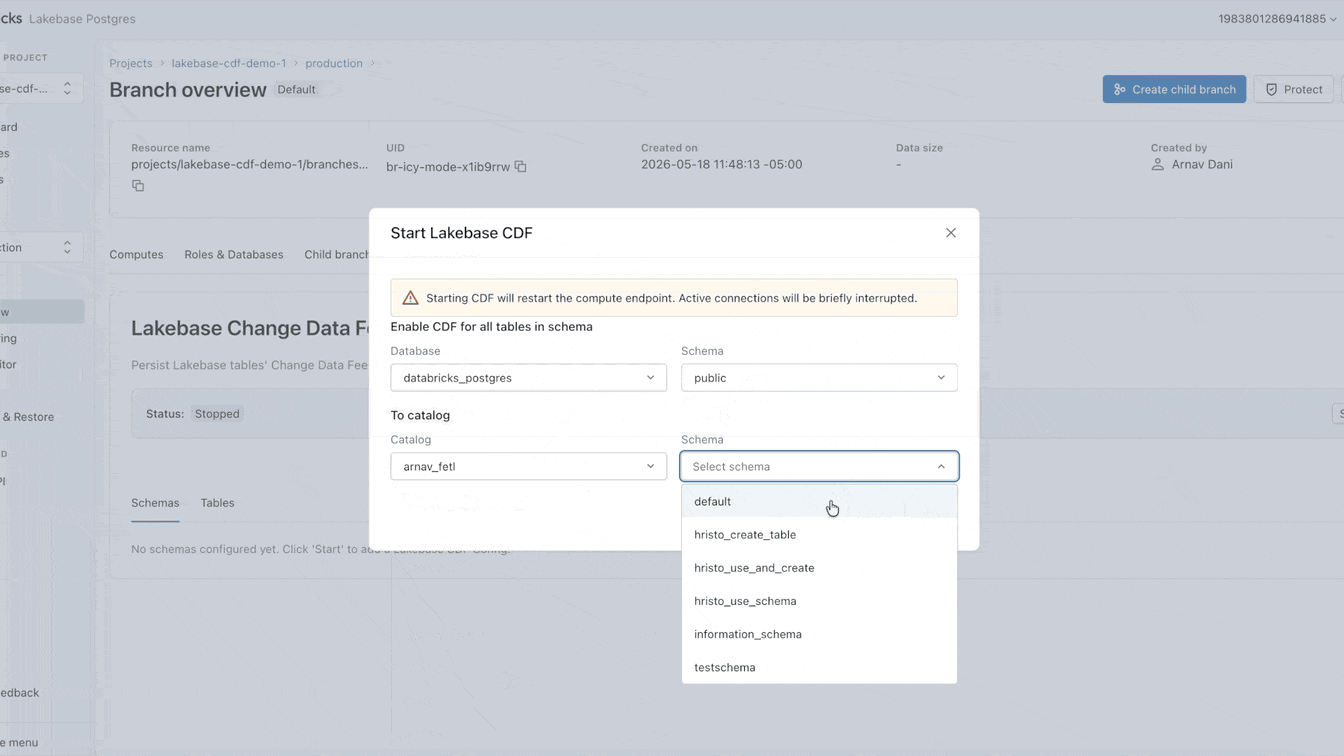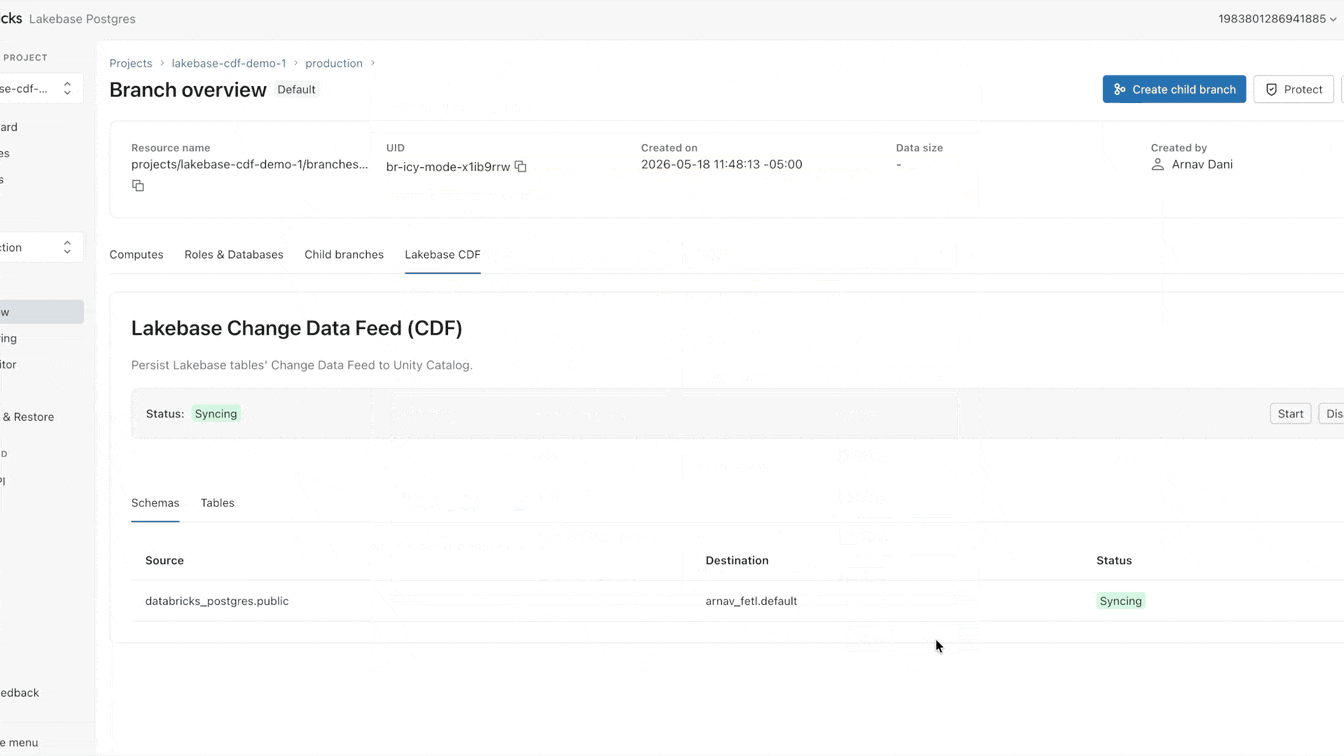
운영 데이터를 레이크에 랜딩하는 것이 여전히 어려운 이유는 무엇인가요?
Lakeflow Connect는 Lakehouse로의 데이터 수집을 매우 간편하게 만들었지만, OLTP 데이터베이스에서 데이터를 가져오는 것은 여전히 수동적이고 마찰이 많은 프로세스입니다. 변경 데이터 캡처(CDC)를 추출하면 팀은 데이터베이스 커넥터를 구성하고, 복제 상태를 감시하고, 성능 영향을 완화하고, 분리된 도구를 통해 오류를 추적해야 합니다. 이 모델은 빠른 데이터 분기에 의존하는 에이전트 우선 개발에서 무너집니다. 모든 새 분기에서 모든 대상으로 복잡하고 거버넌스가 없는 추출 파이프라인을 유지하는 것은 지속 가능하지 않습니다.
저희는 Lakehouse에서 이 문제를 해결했습니다. 이제 Lakebase로 가져옵니다.
Lakehouse는 데이터를 개방형 형식(Apache Iceberg™, Delta Lake)으로 한 번 저장하여 분석을 위한 추출 파이프라인을 제거했습니다. 다운스트림 복제를 위한 표준으로 변경 데이터 피드(CDF)를 설정하여 ETL, 스트리밍 워크플로 및 감사 로그를 지원했습니다.
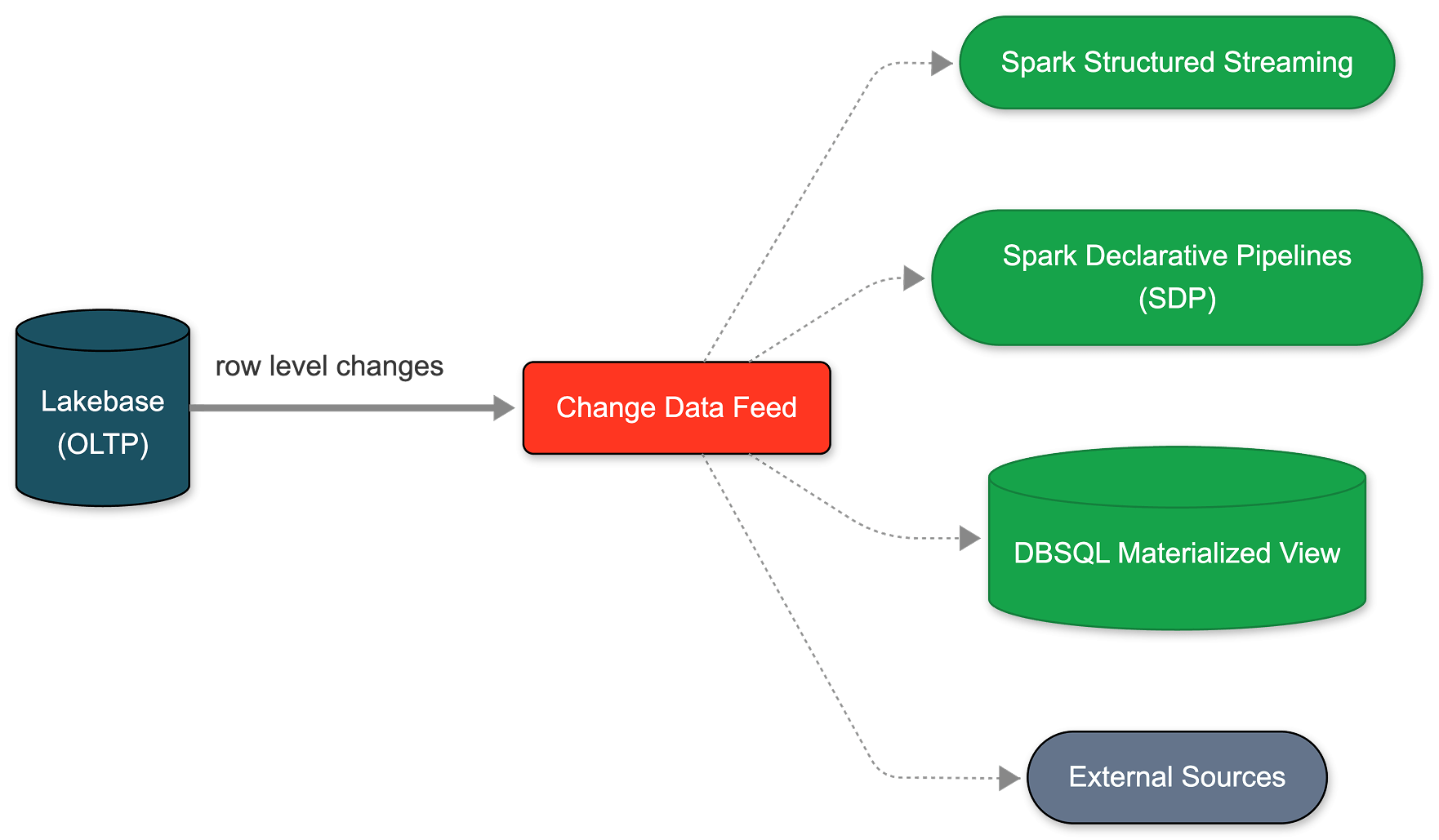
이제 Lakebase에서 이 CDF를 네이티브로 설정할 수 있습니다. 활성화하는 데 1분도 채 걸리지 않으며 프로젝트 내의 모든 테이블에 적용됩니다. 이 단일 피드에서 SDP를 사용하여 스트리밍 파이프라인을 구축하거나, DBSQL을 사용하여 구체화된 뷰를 생성하거나, 에이전트 브릭을 사용하여 임베딩을 계산하고 저장할 수 있습니다. 모든 다운스트림 소비자는 기본 운영 워크로드와 완전히 격리된 정확히 동일한 피드를 구독합니다.
운영 데이터베이스는 메달리온 아키텍처에 속합니다
Lakebase를 사용하면 운영 데이터가 더 이상 Lakehouse와 분리되지 않습니다. Lakebase는 이미 동기화된 테이블을 제공하여 골드 데이터셋을 애플리케이션에 직접 제공하는 패턴을 설정했습니다. Lakebase CDF는 아키텍처를 완성합니다. 운영 데이터베이스는 이제 기본 브론즈 계층이 되어 데이터를 Lakehouse에 랜딩하기 위한 별도의 파이프라인이나 추출 작업이 필요 없습니다. 대신 Unity Catalog를 통해 데이터 수명 주기 전반에 걸쳐 완전한 거버넌스와 계보를 얻을 수 있습니다.
이것은 시작에 불과합니다. 저희는 여러분이 Lakehouse에서 사랑하는 개방성을 Lakebase로 직접 가져오고 있습니다. Data and AI Summit를 기대해 주시고, 이 아키텍처에 대한 저희 주제 세션에 참여해 주세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구��독하고 최신 게시물을 이메일로 받아보세요.