MLflow 2.4 출시 : 강력한 모델 평가를 위한 LLMOps 도구
작성자: Corey Zumar, 휴버트 주브, Kasey Uhlenhuth, 프리트비 칸난, 리디마 굽타, Sunish Sheth, Harutaka Kawamura , Ann Zhang
(원문 보기)
LLM은 모든 규모의 조직이 강력한 애플리케이션을 신속하게 구축하고 비즈니스 가치를 제공할 수 있는 엄청난 기회를 제공합니다. 과거에는 데이터 과학자가 제한된 작업을 위해 모델을 훈련하고 재훈련하는 데 수천 시간을 쏟아야 했지만, 이제는 다양한 SaaS 및 오픈 소스 모델을 활용해 훨씬 더 지능적이고 폭넓은 애플리케이션을 빠르게 구축할 수 있습니다. 데이터 과학자는 프롬프트 엔지니어링과 같은 few-shot 및 zero-shot 학습 기법을 사용하여 다양한 데이터 세트에 대한 정확도 높은 classifier, 최첨단 감성 분석 모델, 지연 시간이 짧은 문서 요약기 등을 신속하게 구축할 수 있습니다.
그러나 프로덕션에 가장 적합한 모델을 식별하고 안전하게 배포하기 위해서는 조직에 적합한 도구와 프로세스가 필요합니다. 가장 중요한 요소 중 하나는 강력한 모델 평가입니다. 할루시네이션, 욕설 답변, 프롬프트 인젝션 취약점 등과 같은 모델 품질 문제 뿐만 아니라, 많은 작업에 대한 기준 데이터 레이블이 부족하기 때문에, 데이터 과학자는 다양한 데이터에 대한 모델의 성능을 평가하는 데 매우 부지런해야 합니다. 또한 데이터 과학자는 프로덕션에 가장 적합한 모델을 선택하기 위해 여러 모델 후보 간의 미묘한 차이점을 식별할 수 있어야 합니다. 이제 그 어느 때보다 모든 모델에 대한 상세한 성능 보고서를 제공하고, 프로덕션 이전에 약점과 취약점을 식별하고, 모델 비교를 간소화하는 데 도움이 되는 LLMOps 플랫폼이 필요합니다.
이러한 요구 사항을 충족하기 위해 모델 평가를 위한 종합적인 LLMOps 도구 세트를 제공하는 MLflow 2.4를 출시하게 되어 기쁘게 생각합니다. 언어 작업을 위한 새로운 mlflow.evaluate() 통합, 여러 모델 버전에서 텍스트 출력을 비교할 수 있는 새로운 아티팩트 보기 UI, 오랫동안 기다려온 데이터 세트 추적 기능 등을 통해 MLflow 2.4는 LLM을 사용한 개발을 가속화합니다.
언어 모델에 대한 mlflow.evaluate()로 성능 인사이트 캡처
언어 모델의 성능을 평가하려면 다양한 입력 데이터 세트를 제공하고, 해당 출력을 기록하고, 도메인별 메트릭을 계산해야 합니다. MLflow 2.4에서는 이 프로세스를 획기적으로 간소화하기 ��위해 MLflow의 강력한 평가 API인 mlflow.evaluate()를 확장했습니다. 코드 한 줄로 텍스트 요약, 텍스트 분류, 질문 답변, 텍스트 생성 등 LLM을 사용하는 다양한 작업에 대한 모델 예측 및 성능 메트릭을 추적할 수 있습니다. 이 모든 정보는 MLflow 추적에 기록되어 여러 모델에서 성능 평가를 검사하고 비교하여 프로덕션에 가장 적합한 후보를 선택할 수 있습니다.
다음 예제 코드는 mlflow.evaluate()를 사용하여 요약 모델에 대한 성능 정보를 빠르게 캡처합니다:
사용 예제를 포함하여 mlflow.evaluate()에 대한 자세한 내용은 MLflow 설명서 및 예제 리포지토리를 참조하세요.
새로운 아티팩트 뷰로 LLM 결과물을 검사하고 비교하세요.
기준 데이터 레이블이 없으면 많은 LLM 개발자가 모델 산출물을 수동으로 검사하여 품질을 평가해야 합니다. 이는 종종 문서 요약, 복잡한 질문에 대한 답변, 생성된 산문 등 모델이 생성한 텍스트를 읽는 것을 의미합니다. 생산에 가장 적합한 모델을 선택할 때는 이러한 텍스트 출력을 그룹화하고 �모델 간에 비교해야 합니다.
예를 들어 LLM을 사용하여 문서 요약 모델을 개발할 때는 각 모델이 주어진 문서를 어떻게 요약하는지 확인하고 차이점을 파악하는 것이 중요합니다.
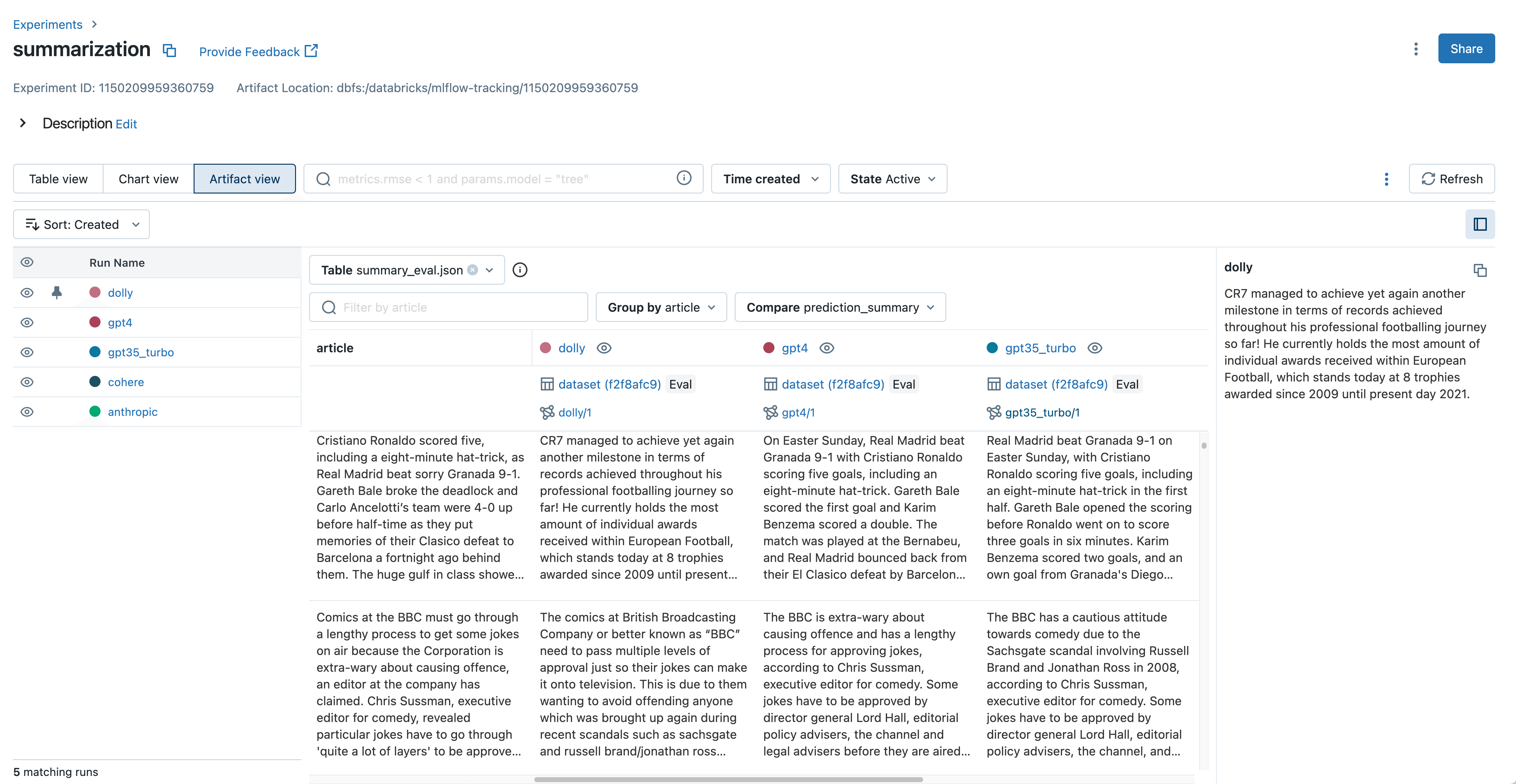
MLflow 아티팩트 뷰는 여러 모델에 걸쳐 입력, 출력 및 중간 결과를 나란히 비교할 수 있습니다.
MLflow 2.4에서는 MLflow 추적의 새로운 아티팩트 뷰가 이러한 출력 검사 및 비교를 간소화합니다. 몇 번의 클릭만으로 모든 모델에서 mlflow.evaluate()의 텍스트 입력, 출력 및 중간 결과를 보고 비교할 수 있습니다. 이를 통해 잘못된 출력을 식별하고 추론 중에 어떤 프롬프트가 사용되었는지 매우 쉽게 이해할 수 있습니다. MLflow 2.4의 새로운 mlflow.load_table() API를 사용하면 아티팩트 보기에 표시된 모든 평가 결과를 다운로드하여 데이터브릭스 SQL, 데이터 라벨링 등에 사용할 수도 있습니다. 다음 코드 예제에서 이를 확인할 수 있습니다:
평가 데이터 세트를 추적하여 정확한 비교 보장
프로덕션에 가장 적합한 모델을 선택하려면 여러 모델 후보 간의 성능을 철저히 비교해야 합니다. 이 비교에서 중요한 점은 모든 모델이 동일한 데이터 세트를 사용하여 평가되는지 확인하는 것입니다. 정확도가 높은 모델을 고르려면 모든 후보 모델이 동일한 데이터 세트에서 평가되어야만 의미가 있습니다.
MLflow 2.4에서는 오랫동안 기다려온 기능인 데이터 세트 추적을 도입하게 되어 매우 기쁩니다. 이 새로운 기능은 모델 개발 과정에서 데이터 세트를 관리하고 분석하는 방식을 표준화합니다. 데이터 세트 추적을 사용하면 각 모델을 개발하고 평가하는 데 사용된 데이터 세트를 빠르게 식별하여 공정한 비교를 보장하고 프로덕션 배포를 위한 모델 선택을 간소화할 수 있습니다.
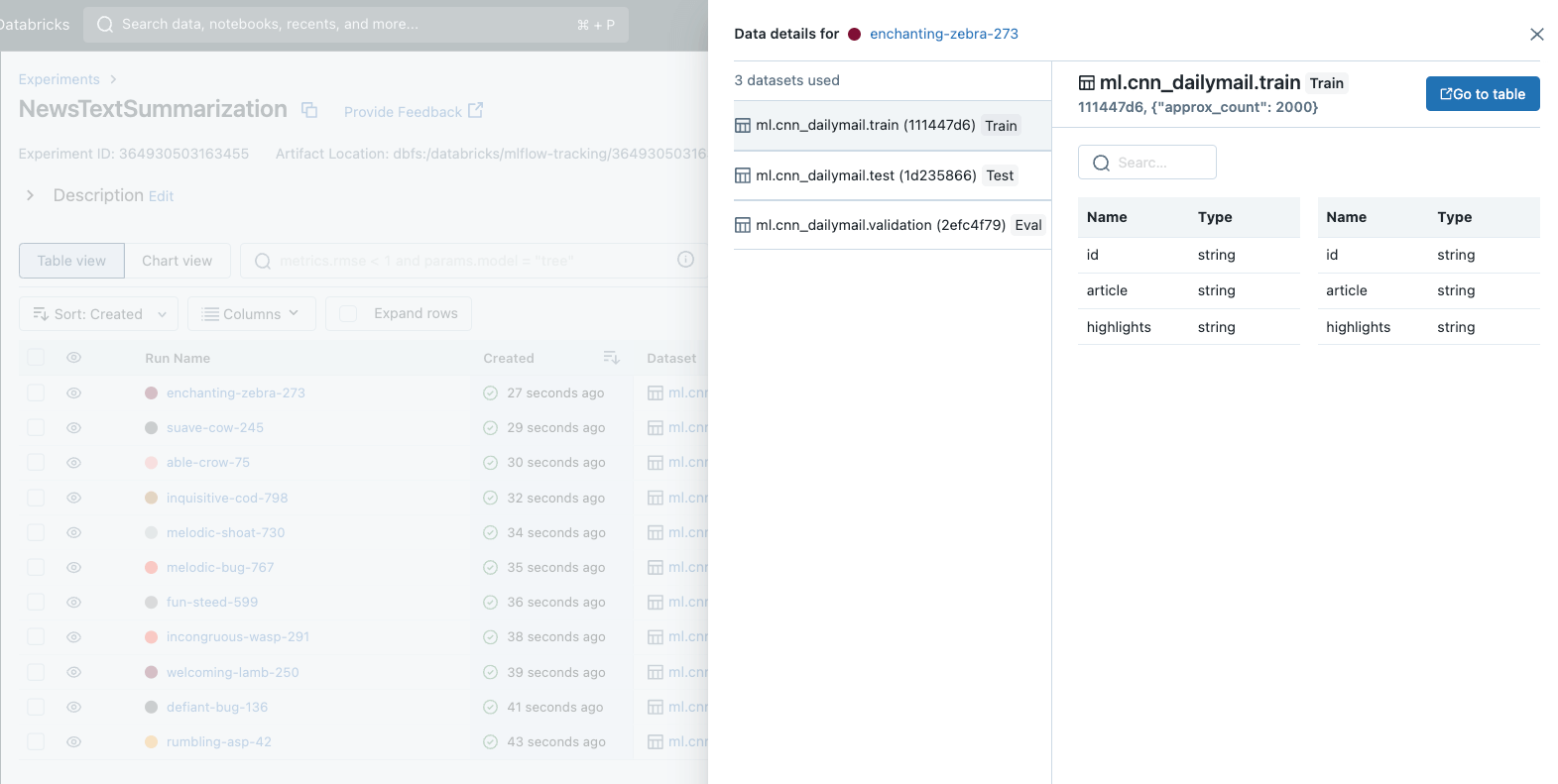
이제 MLflow 추적은 각 실행에 대한 데이터 세트 메타데이터에 대한 향상된 가시성과 함께 UI에 포괄적인 데이터 세트 정보를 표시합니다. 새로운 패널이 도입되어 데이터 세트의 세부 정보를 쉽게 시각화하고 탐색할 수 있으며, 실행 비교 보기와 실행 세부 정보 페이지 모두에서 편리하게 액세스할 수 있습니다.
MLflow에서 데이터 세트 추적을 시작하는 것은 매우 쉽습니다. 데이터 세트 정보를 MLflow 런에 기록하려면 mlflow.log_input() API를 호출하기만 하면 됩니다. 또한 데이터 세트 추적은 MLflow의 Autologging과 통합되어 추가 코드 없이도 데이터 인사이트를 제공합니다. 이 모든 데이터 세트 정보는 분석 및 비교를 위해 MLflow 추적 UI에 눈에 잘 띄게 표시됩니다. 다음 예는 mlflow.log_input()을 사용하여 훈련 데이터 세트를 실행에 기록하고, 실행에서 데이터 �세트에 대한 정보를 검색하고, 데이터 세트의 소스를 로드하는 방법을 보여줍니다:
더 많은 데이터 세트 추적 정보 및 사용 가이드는 MLflow 설명서를 참조하세요.
MLflow 2.4에서 LLMOps 도구 시작하기
MLflow 2.4는 언어 모델용 mlflow.evaluate(), 언어 모델 비교를 위한 새로운 아티팩트 보기, 포괄적인 데이터 세트 추적 기능을 도입하여 사용자가 더욱 강력하고 정확하며 신뢰할 수 있는 모델을 구축할 수 있도록 지속적으로 지원합니다. 특히 이러한 개선 사항은 LLM을 사용한 애플리케이션 개발 경험을 획기적으로 개선합니다.
LLM용 MLflow 2.4의 새로운 기능을 경험해 보시기 바랍니다. 기존 데이터브릭스 사용자라면 지금 바로 노트북이나 클러스터에 라이브러리를 설치하여 MLflow 2.4를 사용할 수 있습니다. MLflow 2.4는 또한 Databricks 머신 러닝 런타임 버전 13.2에 사전 설치됩니다. 시작하려면 Databricks MLflow 가이드 [AWS][Azure][GCP]를 참조하세요. 아직 Databricks 사용자가 아닌 경우, databricks.com/product/managed-mlflow를 방문하여 자세히 알아보고 Databricks 및 Managed MLflow 2.4의 무료 평가판을 시작하세요. MLflow 2.4의 새로운 기능 및 개선 사항의 전체 목록은 릴리스 변경 로그를 참조하세요.
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.