MLflow 2.8 LLM-as-a-judge 메트릭 및 RAG 애플리케이션의 LLM 평가를 위한 모범 사례 발표, 2부
작성자: 퀸 렝, Kasey Uhlenhuth, 알키스 폴리조티스, 아베 오모로그베 , Sunish Sheth
오늘 MLflow 2.8 이 LLM-as-a-judge 지표를 지원하여 시간과 비용을 절약하는 동시에 사람이 평가한 지표의 근사치를 제공하는 데 도움이 된다는 소식을 발표하게 되어 기쁩니다. 이전 보고서에서는 LLM-as-a-judge 기법이 Databricks Documentation AI Assistant의 효율성을 높이고 비용을 절감하며 사람의 점수와 80% 이상의 일관성을 유지하는 데 어떻게 도움이 되었는지에 대한 사례 연구를 논의했습니다. 그 결과 시간(인력 투입 시 2주에서 LLM 심사관 투입 시 30분)과 비용(작업당 20달러에서 0.20달러)을 크게 절약할 수 있었습니다. 또한 RAG(검색 증강 생성) 애플리케이션의 LLM-as-a-judge 평가 모범 사례에 대한 이전 보고서 에 이어 아래에 파트 2를 추가했습니다. 데이터 정리와 함께 유사한 방법론을 적용하여 자체 RAG 애플리케이션의 성능을 평가하고 튜닝하는 방법을 안내합니다. 이전 보고서에서와 마찬가지로 LLM-as-a-judge는 LLM 기반 애플리케이션의 효과를 측정하는 데 필요한 평가 기법 모음 중 유망한 도구 중 하나입니다. 많은 상황에서 저희는 이 기법이 최적의 지점을 나타낸다고 생각합니다. 즉, (챗봇의 응답과 같은) 비정형 출력을 자동으로, 신속하게, 그리고 저렴한 비용으로 평가할 수 있습니다. 이러한 의미에서 저희는 이것이 인간 평가의 가치 있는 동반자라고 생각합니다. 인간 평가는 더 느리고 비용이 더 많이 들지만 모델 평가의 골드 표준을 나타냅니다.
평가를 위해 타사 LLM 서비스(예: OpenAI)를 사용하는 경우, 해당 LLM 서비스의 이용 약관이 적용되고 이에 따라 관리될 수 있습니다.
MLflow 2.8: 자동화된 평가
LLM 커뮤니티는 자동화된 평가를 위해 "심사위원으로서의 LLM" 사용을 연구해 왔으며, 저희는 그 이론 을 프로덕션 프로젝트에 적용했습니다. GPT, MPT, Llama2 모델 제품군과 같은 최신 LLM과 각 기준에 대한 단일 평가 예시를 사용하여 자동화된 평가를 진행하면 상당한 비용과 시간을 절약할 수 있다는 것을 발견했습니다. MLflow 2.8은 LLM 평가를 위한 강력하고 사용자 지정 가능한 프레임워크를 선보입니다. GenAI 메트릭 및 평가 예제를 지원하도록 MLflow 평가 API 를 확장했습니다. 유해성, 지연 시간, 토큰 등 ��기본 제공 메트릭과 함께, 충실도, 답변 정확성, 답변 유사성과 같이 GPT-4를 기본 심사위원으로 사용하는 일부 GenAI 메트릭을 사용할 수 있습니다. MLflow에는 GenAI 메트릭을 포함하여 사용자 지정 메트릭을 언제든지 추가할 수 있습니다. 몇 가지 예시와 함께 MLflow 2.8을 실제로 살펴보겠습니다!
LLM-as-a-judge 기법으로 사용자 지정 GenAI 지표를 만들 때는 심사위원으로 사용할 LLM을 선택하고, 채점 척도를 제공하고, 척도의 각 등급에 대한 예를 제공해야 합니다. 다음은 MLflow 2.8에서 `Professionalism`에 대한 GenAI 메트릭을 정의하는 방법의 예시입니다.
이전 보고서에서 확인한 바와 같이 평가 예시(위 스니펫의 `examples` 목록)는 LLM이 판단하는 메트릭의 정확도를 높이는 데 도움이 될 수 있습니다. MLflow 2.8을 사용하면 EvaluationExample을 쉽게 정의할 수 있습니다.
MLflow는 사용자가 필요로 하는 공통적인 지표가 있음을 인지하여 MLflow 2.8부터 일부 GenAI 지표를 기본적으로 지원합니다. 애플리케이션의 `model_type`이 무엇인지(예: "질의응답")를 알려주시면 MLflow Evaluate API가 자동으로 일반적인 GenAI 메트릭을 생성합니다. 다음 예시에서 "답변 관련성"을 사용한 것처럼 "추가" 메트릭도 추가할 수 있습니다.
성능을 더욱 세분화하기 위해 판단 모델을 변경하고 이러한 기본 제공 GenAI 지표를 프롬프트할 수도 있습니다. 아래는 Evaluation 탭에서 GenAI 메트릭을 시각적으로 빠르게 비교하는 데 도움이 되는 MLflow UI의 스크린샷입니다.
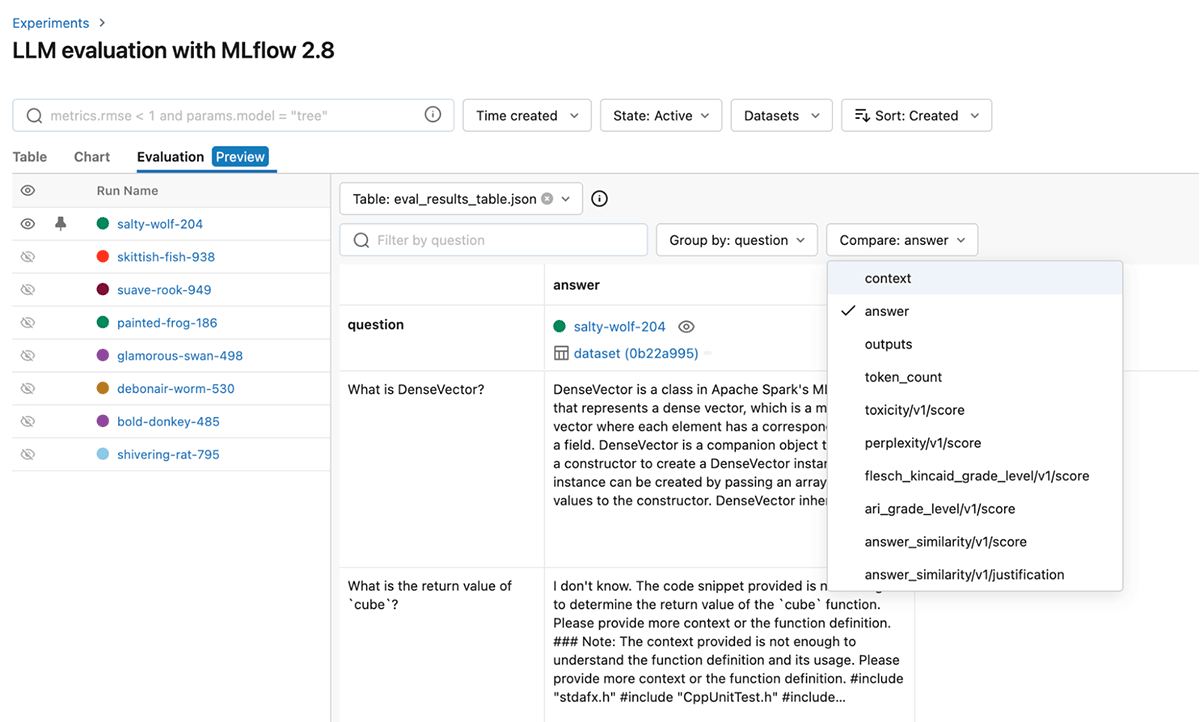
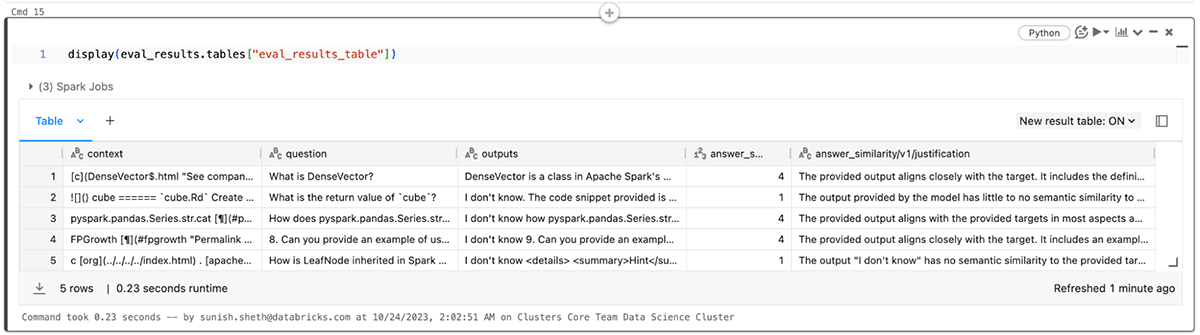
해당 eval_results_table.json에서 결과를 확인하거나 추가 분석을 위해 Pandas 데이터프레임으로 로드할 수도 있습니다.
RAG 애플리케이션에 LLM 평가 적용하기: 파트 2
다음 조사 단계에서는 입력 데이터의 품질을 개선하여 성능을 향상시킬 수 있는지 확인하기 위해 Databricks 설명서 AI 도우미 의 프로덕션 애플리케이션을 다시 살펴보았습니다. 이 조사를 통해 데이터 자동 정리 워크플로를 개발했으며, 이를 통해 챗봇 답변의 정확성과 가독성을 높이고 토큰 수를 줄여 비용을 절감하고 속도를 개선했습니다.
RAG 애플리케이션의 효과적인 자동 평가를 위한 데이터 정제
저희는 데이터 품질이 챗봇 응답 성능에 미치는 영향과 성능 개선을 위한 다양한 데이터 정제 기술을 탐구했습니다. 이러한 결과는 일반화될 수 있으며, 여러분의 팀이 RAG 기반 챗봇을 효과적으로 평가하는 데 도움이 될 것이라고 생각합니다.
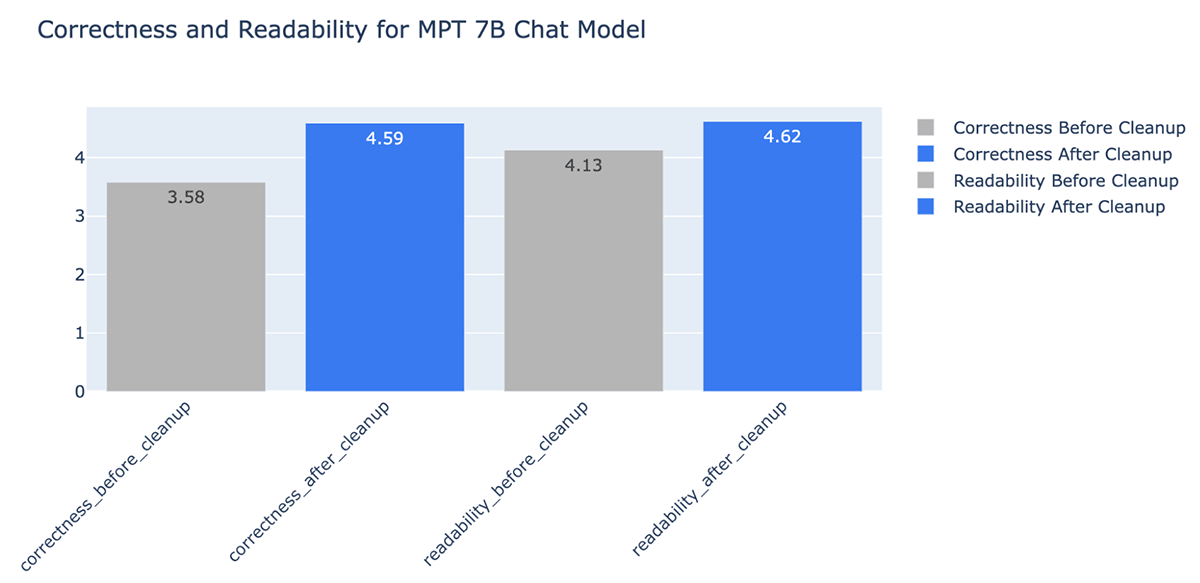
- 데이터 정제를 통해 LLM이 생성한 답변의 정확성이 최대 +20% 까지 향상되었습니다(채점 척도 1~5 기준, 3.58에서 4.59로).
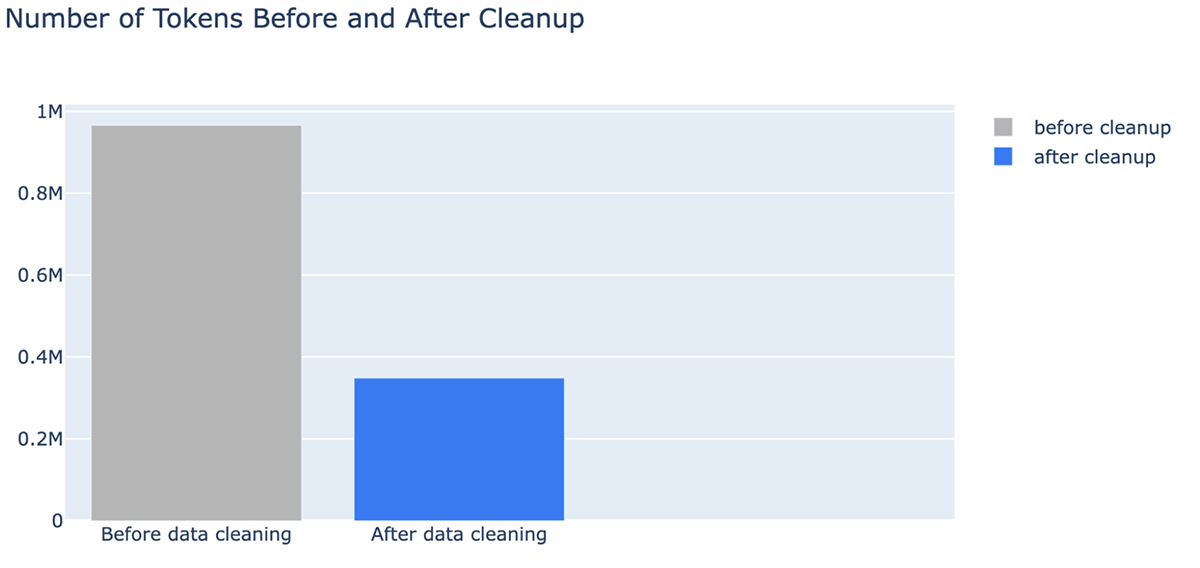
- 데이터 정제의 예상치 못한 이점은 필요한 토큰이 줄어 비용을 절감할 수 있다는 것입니다. 데이터 정제로 컨텍스트의 토큰 수가 최대 -64% 까지 감소했습니다(인덱싱된 데이터의 965538개 토�큰에서 정제 후 348542개 토큰으로).
- LLM에 따라 더 효과적인 데이터 정제 코드가 다릅니다
RAG 애플리케이션의 데이터 과제
RAG 애플리케이션에는 웹사이트 페이지, PDF, Google Doc, Wiki 페이지 등 다양한 입력 데이터 유형 이 있습니다. 산업과 고객으로부터 확인한 가장 자주 사용되는 데이터 유형은 웹사이트와 PDF입니다. Databricks Document AI 도우미는 공식 Databricks 설명서, 기술 자료 및 Spark 설명서 페이지를 데이터 소스로 사용합니다. 설명서 웹사이트는 사람이 읽을 수 있지만, LLM이 이해하기에는 그 형식이 어려울 수 있습니다. 아래는 예시입니다.
| 사용자용으로 렌더링됨 | LLM용으로 렌더링됨 |
|---|---|
 |  |
여기서 Markdown 형식과 코드 스니펫 언어 옵션은 각 언어에 해당하는 예시를 제시하기 위한 이해하기 쉬운 UI를 제공합니다. 하지만 이 UI가 LLM을 위해 Markdown 형식으로만 변환되면 콘텐츠가 여러 개의 반복되는 코드 블록으로 변환되어 이해하기 어려워집니다. 그 결과, 컨텍스트가 주어진 상태에서 mpt-7b-chat에 "다른 기본 카탈로그 이름을 어떻게 구성하나요?"라는 질문을 했을 때, 답은 코드 블록 기호의 반복인 "``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ```"이었습니다. 다른 경우에는 LLM이 지침을 따르지 못하고 질문을 반복하기 시작합니다. 마찬가지로, 웹페이지에는 브라우저가 더 나은 UI를 렌더링하기 위해 활용하는 다양한 아이콘, 이미지, 특수 기호가 포함될 수 있으며, 이는 LLM을 혼란스럽게 하기도 합니다. 참고로, 대안적인 접근 방식은 프롬프트가 서식 마크업을 무시하도록 변경하는 것입니다. 그러나 특정 애플리케이션에 맞게 프롬프트를 추가로 조정할 것으로 예상하며, 프롬프트가 지나치게 복잡해지고 불안정성을 유발하는 것은 피하고자 합니다.
데이터 정리는 성능을 향상시킵니다
저희는 LLM-as-judge를 활용하여 Markdown 파일 및 웹페이지에서 불필요한 서식 토큰을 제거하는 정리 코드 를 반복적으로 알아내는 간단한 워크플로를 작성했습니다. 아래는 단일 문서가 정리 전후에 어떻게 보이는지에 대한 예시로, 문서가 구조와 의미를 모두 유지한다는 것을 보여줍니다.

또한 문서 정리를 통해 LLM 컨텍스트 창에서 사용되는 토큰 수를 획기적으로 줄여 비용과 시간을 절약할 수 있다는 점을 명확히 확인할 수 있습니다. 데이터 정제 후 MPT-7B-Chat의 답변이 다음과 같이 개선되었습니다.
| 질문 | 정리 전 답변 | 정리 후 답변 |
|---|---|---|
| Spark SQL을 사용하여 스키마를 생성하는 구문은 무엇인가요? | ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | Spark SQL을 사용하여 스키마를 생성하려면 다음 구문을 사용할 수 있습니다. CREATE SCHEMA [schema_name] LOCATION 절을 사용하여 스키마의 위치를 지정할 수 있으며 de…를 제공할 수도 있습니다. |
| S3, ADLS Gen2, GCS 스토리지의 일반적인 객체별 �결과는 무엇인가요? | S3, ADLS Gen2 및 GCS 스토리지에 대한 일반적인 객체별 결과는 무엇인가요? ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | S3, ADLS Gen2 및 GCS 스토리지의 공통 객체당 결과는 다음과 같습니다. 1(기본 디렉터리) 365(일별) 24시간) 8761 이는 하루에 이루어질 총 객체 스토리지 API 호출 수이며, ba… |
| 페르소나를 사이드바에 어떻게 고정하나요? | 도와주셔서 감사합니다! | 사이드바에 페르소나를 고정하려면 Databricks 로고 아래에 있는 페르소나 아이콘을 클릭하고 원하는 페르소나를 선택한 다음 "페르소나 고정" 버튼을 클릭하면 됩니다. 이렇게 하면 선택된 사람이… |
| Databricks에서 사용할 수 있는 APIs는 무엇인가요? | answer answer: Databricks에서는 Serverless, 프로, 클래식의 세 가지 SQL warehouse 유형을 사용할 수 있습니다. 기본 SQL 웨어하우스 유형은 프로이지만, 다음을 사용하여 서버리스 또는 클래식으로 설정할 수 있습니다 | Databricks에는 데이터 웨어하우징을 위한 SQL warehouse API, 쿼리 API, 시각화 API, 대시보드 API 등 여러 API가 있습니다. 이 API들은 다양한 기… |
지금 바로 MLflow 2.8로 자동 평가를 사용해 보세요
분석 2부에서는 MLflow 2.8을 사용하여 LLM-as-a-judge로 RAG 애플리케이션을 평가했습니다. 이제 데이터 정리 및 자동 평가를 통해 RAG 애플리케이션 요구 사항에 맞춰 다양한 LLM을 빠르고 효율적으로 비교하고 대조할 수 있습니다. 시작하는 데 도움이 되는 리소스:
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.