대규모 언어 모델을 위한 최적의 매개변수 선택 가이드: LoRA를 이용한 효율적인 미세 조정
신경망 기반 기술과 대규모 언어 모델(LLM) 연구의 급속한 발전으로 기업들은 가치 창출을 위한 AI 애플리케이션��에 점점 더 많은 관심을 기울이고 있습니다. 텍스트 분류, 요약, 시퀀스-투-시퀀스 작업 및 제어된 텍스트 생성과 같은 텍스트 관련 문제를 해결하기 위해 생성 및 비생성 방식을 포함한 다양한 머신러닝 접근 방식을 사용합니다. 조직은 타사 API를 선택할 수 있지만, 독점 데이터로 모델을 미세 조정하면 도메인별이고 관련성 높은 결과를 얻을 수 있어 다양한 환경에서 안전하게 배포할 수 있는 비용 효율적이고 독립적인 솔루션을 구현할 수 있습니다.
미세 조정을 위한 전략을 선택할 때 효율적인 리소스 활용과 비용 효율성을 보장하는 것이 중요합니다. 이 블로그에서는 이러한 파라미터 효율적인 방법 중 가장 인기 있고 효과적인 변형이라고 할 수 있는 LoRA(Low Rank Adaptation)에 대해 알아보고, 특히 QLoRA(LoRA의 더욱 효율적인 변형)에 중점을 둡니다. 여기서의 접근 방식은 오픈 대규모 언어 모델을 가져와 제품 이름과 카테고리가 제공될 때 가상의 제품 설명을 생성하도록 미세 조정하는 것입니다. 이 연습에 선택된 모델은 허용적인 라이선스(Apache 2.0)를 가진 오픈 대규모 언어 모델인 OpenLLaMA-3b-v2이며, 선택된 데이터셋은 HuggingFace Hub에서 제공된 링크를 통해 다운로드할 수 있는 오픈 대규모 언어 모델인 Red Dot Design Award Product Descriptions입니다.
미세 조정, LoRA 및 QLoRA
언어 모델 분야에서는 기존 언어 모델을 특정 데이터에 대한 특정 작업을 수행하도록 미세 조정하는 것이 일반적인 관행입니다. 여기에는 필요한 경우 작업별 헤드를 추가하고 훈련 과정에서 역전파를 통해 신경망의 가중치를 업데이트하는 것이 포함됩니다. 이 미세 조정 과정과 처음부터 훈련하는 것의 차이점을 인지하는 것이 중요합니다. 후자의 시나리오에서는 모델 가중치가 무작위로 초기화되는 반면, 미세 조정에서는 가중치가 사전 훈련 단계에서 이미 어느 정도 최적화되어 있습니다. 어떤 가중치를 최적화하거나 업데이트하고 어떤 가중치를 고정할지 결정하는 것은 선택한 기술에 따라 달라집니다.
전체 미세 조정은 신경망의 모든 계층을 최적화하거나 훈련하는 것을 포함합니다. 이 접근 방식은 일반적으로 최상의 결과를 제공하지만 가장 많은 리소스와 시간이 소요됩니다.
다행히 효과적인 것으로 입증된 파라미터 효율적인 미세 조정 접근 방식이 존재합니다. 대부분의 이러한 접근 방식은 성능이 떨어졌지만, LoRA(Low Rank Adaptation)는 일부 사례에서 전체 미세 조정을 능가하는 성능을 보여 이러한 추세를 거슬렀습니다. 이는 사전 훈련된 모델의 지식이 미세 조정 과정에서 손실되는 현상인 치명적인 망각을 피하는 결과입니다.
LoRA는 사전 훈련된 대규모 언어 모델의 가중치 행렬을 구성하는 모든 가중치를 미세 조정하는 대신, 이 더 큰 행렬을 근사하는 두 개의 더 작은 행렬을 미�세 조정하는 개선된 미세 조정 방법입니다. 이 행렬들은 LoRA 어댑터를 구성합니다. 이 미세 조정된 어댑터는 사전 훈련된 모델에 로드되어 추론에 사용됩니다.
QLoRA는 LoRA의 메모리 효율적인 버전으로, LoRA의 8비트와 비교하여 사전 훈련된 모델을 양자화된 4비트 가중치로 GPU 메모리에 로드하면서 LoRA와 유사한 효과를 유지합니다. 이 방법을 탐구하고, 필요한 경우 두 가지 방법을 비교하고, 최적의 성능을 가장 빠른 훈련 시간으로 달성하기 위한 QLoRA 하이퍼파라미터의 최상의 조합을 찾는 것이 여기서의 초점이 될 것입니다.
LoRA는 Hugging Face PEFT(Parameter Efficient Fine-Tuning) 라이브러리에 구현되어 사용이 간편하며, QLoRA는 bitsandbytes와 PEFT를 함께 사용하여 활용할 수 있습니다. HuggingFace TRL(Transformer Reinforcement Learning) 라이브러리는 LoRA와의 원활한 통합을 통해 지도 미세 조정을 위한 편리한 트레이너를 제공합니다. 이 세 가지 라이브러리는 원하는 속성을 나타내는 지시가 제공될 때 일관되고 설득력 있는 제품 설명을 생성하도록 선택한 사전 훈련된 모델을 미세 조정하는 데 필요한 도구를 제공할 것입니다.
지도 미세 조정을 위한 데이터 준비
명령어 생성을 위해 모델을 미세 조정하는 데 QLoRA의 효과를 탐구하려면, 데이터를 지도 미세 조정에 적합한 형식으로 변환하는 것이 필수적입니다. 본질적으로 지도 미세 조정은 제공된 프롬프트를 조건으로 텍스트를 생성하도록 사전 훈련된 모델을 추가로 훈련하는 것입니다. 프롬프트-응답 쌍이 일관된 형식으로 구성된 데이터셋에 대해 미세 조정되므로 지도 방식입니다.
Hugging Face 허브에서 선택한 데이터셋의 예시 관찰은 다음과 같습니다.
|
제품 |
카테고리 |
설명 |
텍스트 |
|
"Biamp 랙 제품" |
"디지털 오디오 프로세서" |
"높은 인지도, 통일된 미학 및 실용적인 확장성 – Biamp 브랜드 언어를 통해 인상적으로 달성되었습니다…" |
"제품명: Biamp 랙 제품; 제품 카테고리: 디지털 오디오 프로세서; 제품 설명: “높은 인지도, 통일된 미학 및 실용적인 확장성 – Biamp 브랜드 언어를 통해 인상적으로 달성되었습니다…
|
이 데이터셋은 유용하지만, 위에서 설명한 ��방식으로 명령어 생성을 위해 언어 모델을 미세 조정하는 데 적합한 형식이 아닙니다.
다음 코드 스니펫은 Hugging Face 허브에서 데이터셋을 메모리로 로드하고, 필요한 필드를 프롬프트를 나타내는 일관된 형식의 문자열로 변환하고, 그 직후에 응답(즉, 설명)을 삽입합니다. 이 형식은 Meta의 LLaMA 모델을 원래 Alpaca 모델로 미세 조정하는 데 사용되었던 형식이기 때문에 대규모 언어 모델 연구 커뮤니티에서 'Alpaca 형식'으로 알려져 있습니다. Alpaca 모델은 최초로 널리 배포된 명령어 생성 대규모 언어 모델 중 하나입니다(상업적 사용 라이선스는 없음).
결과 프롬프트는 지도 미세 조정을 위해 Hugging Face 데이터셋으로 로드됩니다. 각 프롬프트는 다음 형식을 갖습니다.
빠른 실험을 위해 각 미세 조정은 이 데이터의 5000개 관측치 하위 집합에서 수행됩니다.
미세 조정 전 모델 성능 테스트
미세 조정을 하기 전에 사전 훈련된 모델 성능의 기준선을 얻기 위해 미세 조정 없이 모델이 어떻게 작동하는지 확인하는 것이 좋습니다.
모델은 다음과 같이 8비트로 로드하고 Hugging Face의 모델 카드에 지정된 형식으로 프롬프트를 지정할 수 있습니다.
결과가 우리가 원하는 것이 아닙니다.
결과의 첫 부분은 만족스럽지만 나머지는 장황한 혼란입니다.
마찬가지로, 이전에 논의한 'Alpaca 형식'으로 모델에 입력 텍스트를 프롬프트하면 출력은 다음과 같이 최적이 아닐 것으로 예상됩니다.
그리고 예상대로 그렇습니다.
모델은 훈련된 대로 다음으로 가장 확률이 높은 토큰을 예측합니다. 이 맥락에서 지도 미세 조정의 요점은 제어 가능한 방식으로 원하는 텍스트를 생성하는 것입니다. 후속 실험에서 QLoRA는 4비트로 로드되고 가중치가 고정된 모델을 활용하지만, 일관성을 위해 위에서 설명한 대로 8비트로 로드된 후 출력 품질을 검사하기 위한 추론 프로세스가 수행된다는 점에 유의하십시오.
조정 가능한 손잡이
PEFT를 사용하여 LoRA 또는 QLoRA로 모델을 훈련할 때(둘의 주요 차이점은 후자의 경우 사전 훈련된 모델이 미세 조정 프로세스 중에 4비트로 고정된다는 점이라는 점에 유의하십시오), 저랭크 적응 프로세스의 하이퍼파라미터는 다음과 같이 LoRA 구성에서 정의할 수 있습니다.
이러한 하이퍼파라미터 중 r과 target_modules는 경험적으로 적응 품질에 상당한 영향을 미치는 것으로 나타났으며 다음 테스트의 초점이 될 것입니다. 다른 하이퍼파라미터는 단순성을 위해 위에 표시된 값으로 일정하게 유지됩니다.
r은 미세 조정 프로세스 중에 학습된 저랭크 행렬의 랭크를 나타냅니다. 이 값이 증가함에 따라 저랭크 적응 중에 업데이트해야 하는 파라미터 수가 증가합니다. 직관적으로, 더 낮은 r은 더 빠르고 계산 집약적이지 않은 훈련 프로세스로 이어질 수 있지만, 생성된 모델의 품질에 영향을 미칠 수 있습니다. 그러나 특정 값을 초과하여 r을 늘려도 모델 출력 품질에 눈에 띄는 증가가 없을 수 있습니다. r 값이 적응(미세 조정) 품질에 어떻게 영향을 미치는지 곧 테스트될 것입니다.
LoRA로 미세 조정할 때 모델 아키텍처의 특정 모듈을 대상으로 지정할 수 있습니다. 적응 프로세스는 이러한 모듈을 대상으로 하고 업데이트 행렬을 적용합니다. "r"의 경우와 유사하게 LoRA 적응 중에 더 많은 모듈을 대상으로 지정하면 훈련 시간이 늘어나고 컴퓨팅 리소스에 대한 요구가 증가합니다. 따라서 트랜스포머의 어텐션 블록만 대상으로 지정하는 것이 일반적입니다. 그러나 Dettmers 등이 발표한 QLoRA 논문에서 볼 수 있듯이 최근 연구에서는 모든 선형 계층을 대상으로 지정하면 더 나은 적응 품질을 얻을 수 있다고 제안합니다. 이것도 여기서 탐구될 것입니다.
모델의 선형 계층 이름은 다음 코드 조각으로 목록에 편리하게 추가할 수 있습니다.
LoRA로 미세 조정 튜닝
일반적으로 대규모 언어 모델을 미세 조정하는 개발자 경험은 지난 몇 년 동안 극적으로 향상되었습니다. TRL 라이브러리의 Hugging Face 최신 고수준 추상화는 SFTTrainer 클래스입니다. QLoRA를 수행하려면 다음만 있으면 됩니다.
1. 4비트로 모델을 GPU 메모리에 로드합니다(bitsandbytes가 이 프로세스를 지원합니다).
2. 위에서 설명한 대로 LoRA 구성을 정의합니다.
3. 준비된 지시 따르기 데이터를 Hugging Face Dataset 객체로 분할하여 훈련 및 테스트합니다.
4. 훈련 인수를 정의합니다. 여기에는 이 연습 중에 일정하게 유지될 에포크 수, 배치 크기 및 기타 훈련 하이퍼파라미터가 포함됩니다.
5. 이러한 인수를 SFTTrainer 인스턴스에 전달합니다.
이러한 단계는 이 블로그와 관련된 리포지토리에서 소스 파일에 명확하게 표시됩니다.
실제 훈련 로직은 다음과 같이 �멋지게 추상화됩니다.
Databricks 작업 공간에서 MLFlow 자동 로깅이 활성화되어 있으면(강력히 권장됨) 모든 훈련 매개변수와 메트릭이 MLFlow 추적 서버에 자동으로 추적 및 로깅됩니다. 이 기능은 오래 실행되는 훈련 작업을 모니터링하는 데 매우 중요합니다. 말할 필요도 없이 미세 조정 프로세스는 GPU 지원을 갖춘 최신 Databricks Machine 런타임을 사용하여 생성된 컴퓨팅 클러스터(이 경우 단일 A100 GPU가 있는 단일 노드)를 사용하여 수행됩니다.
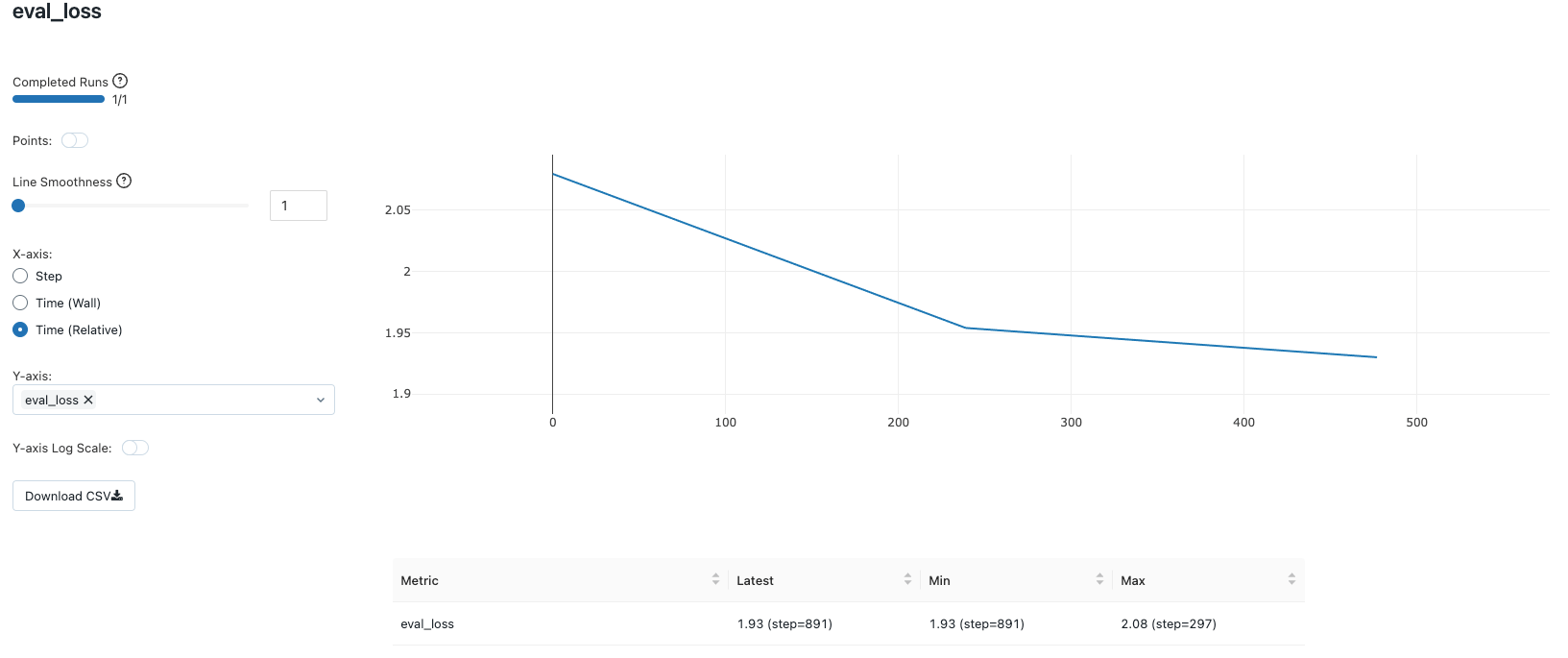
하이퍼파라미터 조합 #1: r=8 및 “q_proj”, “v_proj” 대상 지정 QLoRA
The first combination of QLoRA hyperparameters attempted is r=8 and targets only the attention blocks, namely “q_proj” and “v_proj” for adaptation.
The following code snippets gives the number of trainable parameters:
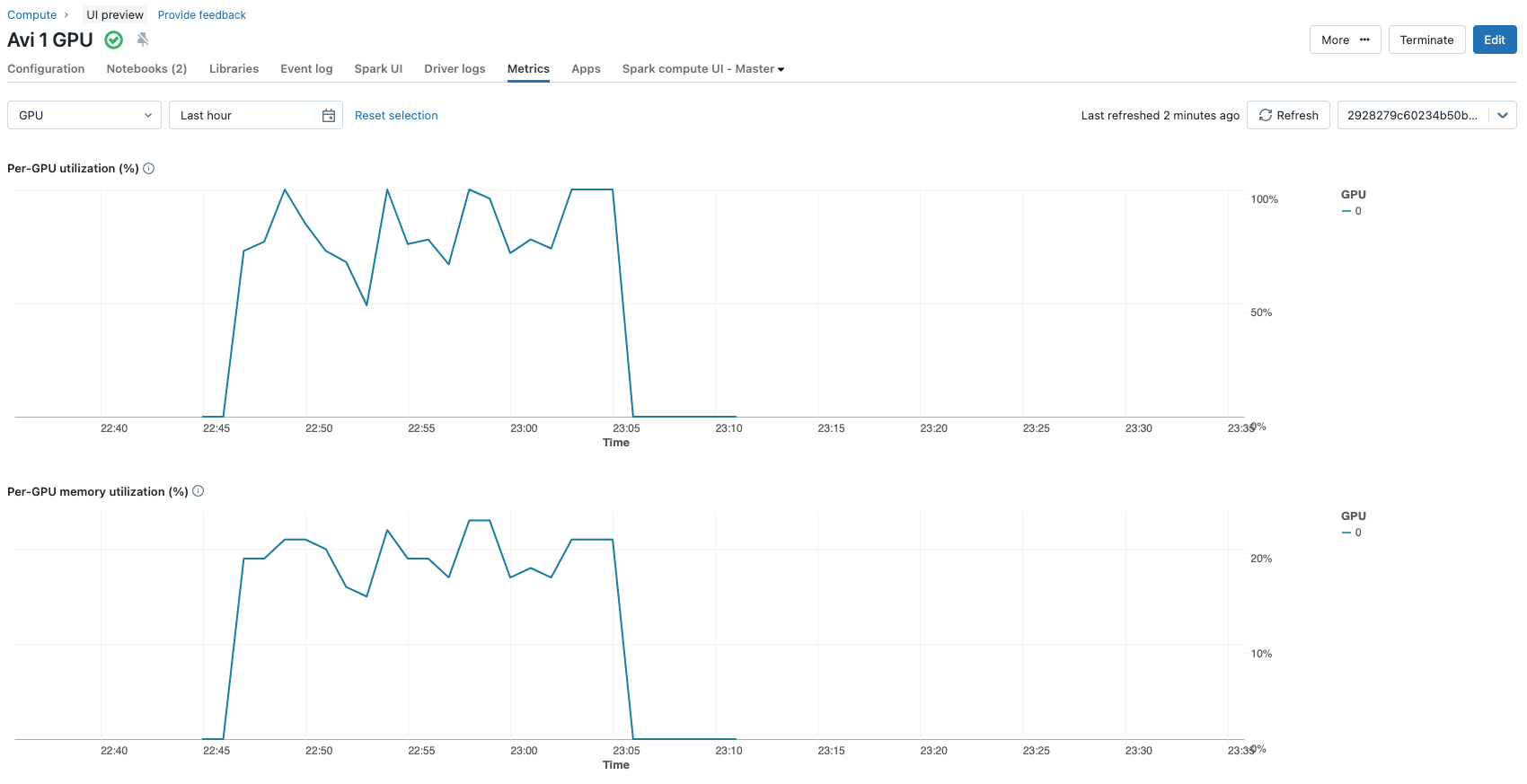
These choices result in 2,662,400 parameters being updated during the fine-tuning process (~2.6 million) from a total of ~3.2 billion parameters the model consists of. This is less than 0.1% of the model parameters. The entire finetuning process on a single Nvidia A100 with 80 GBs of GPU for 3 epochs only takes roughly 12 minutes. The GPU utilization metrics can be conveniently viewed at the metrics tab of the cluster configurations.
At the end of the training process, the fine-tuned model is obtained by loading the adapter weights to the pre-trained model as follows:
This model can now be used for inference as any other model.
Qualitative Evaluation
A couple of example prompt-response pairs are listed below
Prompt (passed to the model in the Alpaca format, not shown for conciseness here):
Create a detailed description for the following product: Corelogic Smooth Mouse, belonging to category: Optical Mouse
Response:
Prompt:
Create a detailed description for the following product: Hoover Lightspeed, belonging to category: Cordless Vacuum Cleaner
Response:
The model has clearly been adapted for generating more consistent descriptions. However the response to the first prompt about the optical mouse is quite short and the following phrase “The vacuum cleaner is equipped with a dust container that can be emptied via a dust container” is logically flawed.
Hyperparameter Combination #2: QLoRA with r=16 and targeting all linear layers
Surely, things can be improved here. It is worth exploring increasing the rank of low rank matrices learned during adaptation to 16, i.e. double the value of r to 16 and keep all else the same. This doubles the number of trainable parameters to 5,324,800 (~5.3 million).
Qualitative Evaluation
The quality of output, however, remains unchanged for the same exact prompts.
Prompt:
Create a detailed description for the following product: Corelogic Smooth Mouse, belonging to category: Optical Mouse
Response:
Prompt:
Create a detailed description for the following product: Hoover Lightspeed, belonging to category: Cordless Vacuum Cleaner
Response:
The same lack of detail and logical flaws in detail where details are available persists. If this fine tuned model is used for product description generation in a real-world scenario, this is not acceptable output.
Hyperparameter Combination #3: QLoRA with r=8 and targeting all linear layers
Given that doubling r does not seemingly result in any perceivable increase in output quality, it is worth changing the other important knob. i.e. targeting all linear layers instead of just the attention blocks. Here, the LoRA hyperparameters are r=8 and target_layers are 'q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj' and 'lm_head'. This increases the number of parameters updated to 12,994,560 and increases the training time to roughly 15.5 minutes.
Qualitative Evaluation
Prompting the model with the same prompts yield the following:
Prompt:
Create a detailed description for the following product: Corelogic Smooth Mouse, belonging to category: Optical Mouse
Response:
Prompt:
Create a detailed description for the following product: Hoover Lightspeed, belonging to category: Cordless Vacuum Cleaner
Response:
Now it is possible to see a somewhat longer coherent description of the fictitious optical mouse and there are no logical flaws in the description of the vacuum cleaner. The product descriptions are not only logical, but relevant. Just as a reminder, these relatively high-quality results are obtained by fine-tuning less than a 1% of the model’s weights with a total dataset of 5000 such prompt-description pairs formatted in a consistent manner.
Hyperparameter Combination #4: LoRA with r=8 and targeting all linear transformer layers
It is also worth exploring whether the quality of output from the model improves if the pretrained model is frozen in 8-bit instead of 4-bit. In other words, replicating the exact finetuning process using LoRA instead of QLoRA. Here, the LoRA hyperparameters are kept the same as before, in the new-found optimal configuration, i.e. r=8 and targeting all linear transformer layers during the adaptation process.
Qualitative Evaluation
The results for the two prompts used throughout the article are as given below:
Prompt:
Create a detailed description for the following product: Corelogic Smooth Mouse, belonging to category: Optical Mouse
Response:
Prompt:
Create a detailed description for the following product: Hoover Lightspeed, belonging to category: Cordless Vacuum Cleaner
Response:
Again, there isn’t much of an improvement in the quality of the output text.
Key Observations
Based on the above set of trials, and further evidence detailed in the excellent publication presenting QLoRA, it can be deduced that the value of r (the rank of matrices updated during adaptation) does not improve adaptation quality beyond a certain point. The biggest improvement is observed in targeting all linear layers in the adaptation process, as opposed to just the attention blocks, as commonly documented in technical literature detailing LoRA and QLoRA. The trials executed above and other empirical evidence suggest that QLoRA does not indeed suffer from any discernible reduction in quality of text generated, compared to LoRA.
Further Considerations for using LoRA adapters in deployment
어댑터 사용을 최적화하고 기법의 한계를 이해하는 것이 중요합니다. 파인튜닝을 통해 얻은 LoRA 어댑터의 크기는 일반적으로 몇 메가바이트에 불과하지만, 사전 훈련된 기본 모델은 메모리와 디스크에서 수 기가바이트에 달할 수 있습니다. 추론 중에는 어댑터와 사전 훈련된 LLM 모두 로드해야 하므로 메모리 요구 사항은 비슷하게 유지됩니다.
또한, 사전 훈련된 LLM과 어댑터의 가중치가 병합되지 않으면 추론 지연 시간이 약간 증가합니다. 다행히 PEFT 라이브러리를 사용하면 여기 표시된 대로 한 줄의 코드로 어댑터와 가중치를 병합하는 프로세스를 수행할 수 있습니다.
아래 그림은 어댑터 파인튜닝부터 모델 배포까지의 과정을 보여줍니다.

어댑터 패턴은 상당한 이점을 제공하지만, 어댑터 병합이 보편적인 해결책은 아닙니다. 어댑터 패턴의 한 가지 장점은 작업별 어댑터로 단일 대형 사전 훈련 모델을 배포할 수 있다는 것입니다. 이를 통해 사전 훈련된 모델을 다양한 작업의 백본으로 활용하여 효율적인 추론이 가능합니다. 그러나 가중치를 병합하면 이 접근 방식이 불가능해집니다. 가중치 병합 여부는 특정 사용 사례와 허용 가능한 추론 지연 시간에 따라 달라집니다. 그럼에도 불구하고 LoRA/QLoRA는 파라미터 효율적인 파인튜닝에 매우 효과적인 방법으로 계속 사용되고 있습니다.
결론
Low Rank Adaptation은 올바른 구성으로 사용하면 훌륭한 결과를 얻을 수 있는 강력한 파인튜닝 기법입니다. 적절한 랭크 값과 적응 중에 대상이 될 신경망 아키텍처의 계층을 선택하는 것이 파인튜닝된 모델의 출력 품질을 결정할 수 있습니다. QLoRA는 적응 품질을 유지하면서 추가적인 메모리 절약을 제공합니다. 파인튜닝이 수행되더라도, 적응된 모델이 올바르게 배포되도록 보장하기 위한 몇 가지 중요한 엔지니어링 고려 사항이 있습니다.
요약하자면, OpenLLaMA-3b-v2를 3 에포크 동안 5000개의 관측치에 대해 단일 A100에서 파인튜닝할 때 시도된 LoRA 파라미터의 다양한 조합, 텍스트 품질 출력 및 업데이트된 파라미터 수를 나타내는 간결한 표가 아래에 나와 있습니다.
|
r |
target_modules |
Base model weights |
Quality of output |
Number of parameters updated (in millions) |
|
8 |
Attention blocks |
4 |
low |
2.662 |
|
16 |
Attention blocks |
4 |
low |
5.324 |
|
8 |
All linear layers |
4 |
high |
12.995 |
|
8 |
All linear layers |
8 |
high |
12.995 |
Databricks에서 시도해 보세요! 시작하려면 블로그와 관련된 GitHub 저장소를 Databricks Repo로 복제하세요. Databricks에서 모델을 파인튜닝하기 위한 더 철저하게 문서화된 예제는 여기에서 확인할 수 있습니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게�시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.