Spark에서 임의의 상태 유지 스트림 처리의 진화
transformWithStateInPandas의 독특한 장점 탐색
작성자: Sol Ackerman, 아니쉬 슈리곤데카르, 에릭 마르나디, 징 잔, 보 가오, 정택 임 , 카르틱 라마사미
- 상태 유지 처리 진화: Spark™ 4.0에서 applyInPandasWithState와 transformWithStateInPandas 비교하여 향상된 유연성과 기능성.
- 새로운 기능: transformWithStateInPandas는 다양한 상태 유형, 타이머, TTL, 복잡한 스트리밍 파이프라인에 대한 스키마 진화를 제공합니다.
- 개발 단순화: transformWithStateInPandas는 상태 처리를 단��순화하고, 더 세밀한 제어와 상태 데이터 소스 리더와의 더 쉬운 통합으로 디버깅 과정을 개선합니다.
소개
Apache Spark™ 구조화된 스트리밍에서의 상태 유지 처리는 복잡한 스트리밍 애플리케이션의 성장하는 요구를 충족시키기 위해 크게 발전했습니다. 처음에는 applyInPandasWithState API가 개발자들이 스트리밍 데이터에 임의의 상태 유지 작업을 수행하도록 허용했습니다. 그러나 스트리밍 애플리케이션의 복잡성과 세련됨이 증가함에 따라, 더 유연하고 기능이 풍부한 API가 필요하게 되었습니다. 이러한 요구사항을 충족시키기 위해, Spark 커뮤니티는 크게 개선된 transformWithStateInPandas API를 소개했습니다. 이 API는 Apache Spark™ 4.0에서 사용할 수 있으며, 기존의 applyInPandasWithState 연산자를 완전히 대체할 수 있습니다. transformWithStateInPandas 는 유연한 데이터 모델링과 상태, 타이머, 상태에 대한 TTL, 연산자 체이닝, 스키마 진화 등을 정의하기 위한 복합 유형과 같은 훨씬 더 큰 기능을 제공합니다.
이 블로그에서는 Python에 초점을 맞추어 transformWithStateInPandas 와 이전의 applyInPandasWithState API를 비교하고 코딩 예제를 사용하여 transformWithStateInPandas 가 applyInPandasWithState 가 할 수 있는 모든 것을 표현할 수 있음을 보여줄 것입니다.
이 블로그의 끝에서는 transformWithStateInPandas 를 사용하는 장점과 applyInPandasWithState 대비, 어떻게 applyInPandasWithState 파이프라인을 transformWithStateInPandas 파이프라인으로 재작성할 수 있는지, 그리고 transformWithStateInPandas 가 Apache Spark™에서 상태 유지 스트리밍 애플리케이션 개발을 어떻게 단순화하는지 이해하게 될 것입니다.
applyInPandasWithState 개요
applyInPandasWithState 는 스트리밍 데이터에 임의의 상태 유지 작업을 허용하는 Apache Spark™ 구조화된 스트리밍의 강력한 API입니다. 이 API는 특히 사용자 정의 상태 관리 로직이 필요한 애플리케이션에 유용합니다. applyInPandasWithState 는 사용자가 키로 그룹화된 스트리밍 데이터를 조작하고 각 그룹에 상태 유지 연산을 적용할 수 있게 합니다.
대부분의 비즈니스 로직은 다음과 같은 유형 서명을 가진 func에서 발생합니다.
예를 들어, 다음 함수는 각 키에 대한 값의 수를 계속 세는 작업을 합니다. 이 함수는 단일 책임 원칙을 위반한다는 점을 주목할 가치가 있습니다: 새로운 데이터가 도착할 때 처리하고, 상태가 시간 초과될 때도 처리합니다.
다음은 전체 예제 구현입니다:
transformWithStateInPandas 개요
transformWithStateInPandas 는 Apache Spark™ 4.0에서 새롭게 도입된 사용자 정의 상태 유지 처리 연산자입니다. applyInPandasWithState와 비교하면, 그 API가 더 객체 지향적이고, 유연하며, 기능이 풍부하다는 것을 알 수 있습니다. 그 연산은 타입 서명을 가진 함수 대신 StatefulProcessor를 확장하는 객체를 사용하여 정의됩니다. transformWithStateInPandas 는 무엇을 구현해야 �하는지에 대해 더 구체적인 정의를 제공함으로써 코드를 훨씬 쉽게 이해할 수 있게 도와줍니다.
이 클래스에는 다섯 가지 주요 메소드가 있습니다:
init: 이것은 변환을 위한 변수 등을 초기화하는 설정 메소드입니다.handleInitialState: 이 선택적인 단계는 초기 상태 데이터로 파이프라인을 미리 채울 수 있게 해줍니다.handleInputRows: 이것은 핵심 처리 단계로, 들어오는 데이터 행을 처리합니다.handleExpiredTimers: 이 단계는 만료된 타이머를 관리할 수 있게 해줍니다. 이것은 시간 기반 이벤트를 추적해야 하는 상태 유지 작업에 있어 중요합니다.close: 이 단계에서는 변환이 끝나기 전에 필요한 정리 작업을 수행할 수 있습니다.
이 클래스를 사용하면 아래에 동등한 과일 카운팅 연산자가 표시됩니다.
그리고 이것은 다음과 같이 스트리밍 파이프라인에서 구현될 수 있습니다:
상태와 함께 작업하기
상태의 수와 종류
applyInPandasWithState 와 transformWithStateInPandas 는 상태 처리 능력과 유연성 면에서 차이가 있습니다. applyInPandasWithState 는 단일 상태 변수만 지원하며, 이는 GroupState로 관리됩니다. 이는 간단한 상태 관리를 가능하게 하지만, 상태를 단일 값 데이터 구조와 유형으로 제한합니다. 반면에, transformWithStateInPandas 는 더 다양하게 사용할 수 있으며, 다른 유형의 여러 상태 변수를 허용합니다. transformWithStateInPandas의 ValueState 유형(applyInPandasWithState의 GroupState와 유사) 외에도, ListState 와 MapState를 지원하여 더 큰 유연성을 제공하고 더 복잡한 상태 유지 작업을 가능하게 합니다. transformWithStateInPandas 에서 추가로 제공하는 이러한 상태 유형은 성능 향상을 가져옵니다: ListState 와 MapState 는 모든 읽기 및 쓰기 작업에서 전체 상태 구조를 직렬화하고 역직렬화할 필요 없이 부분 업데이트를 허용합니다. 이는 특히 크거나 복잡한 상태에서 효율성을 크게 향상시킬 수 있습니다.
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| 상태 객체의 수 | 1개 | 많은 |
| 상태 객체의 유형 | GroupState (ValueState와 유사) | ValueStateListStateMapState |
CRUD 작업들
비교를 위해, 우리는 오직 applyInPandasWithState의 GroupState 와 transformWithStateInPandas의 ValueState만을 비교할 것입니다, 왜냐하면 ListState 와 MapState 는 동등한 것이 없기 때문입니다. 상태를 다루는 데 있어 가장 큰 차이점은 applyInPandasWithState에서는 상태가 함수에 전달되는 반면, transformWithStateInPandas에서는 각 상태 변수가 클래스에 선언되어야 하고 init 함수에서 인스턴스화해야 한다는 것입니다. 이것은 상태를 생성/설정하는 것을 더욱 상세하게 만들지만, 더욱 설정 가능하게도 합니다. 상태를 다루는 다른 CRUD 작업들은 대체로 변하지 않습니다.
GroupState (applyInPandasWithState) | ValueState (transformWithStateInPandas) | |
|---|---|---|
| 만들기 | 상태 생성은 내포되어 있습니다. 상태는 state variable을 통해 함수로 전달됩니다. | self._state 는 클래스의 인스턴스 변수입니다. 선언하고 인스턴스화해야 합니다. |
def func(
key: _,
pdf_iter: _,
state: GroupState
) -> Iterator[pandas.DataFrame]
| class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state = handle.getValueState("state", schema)
| |
| 읽기 | state.get # 또는 PySparkValueError 발생 state.getOption # 또는 None 반환 | self._state.get() # 또는 None을 반환 |
| 업데이트 | state.update(v) | self._state.update(v) |
| 삭제 | state.remove() | self._state.clear() |
| 존재 | state.exists | self._state.exists() |
이 새로운 API가 가능하게 하는 몇 가지 기능에 대해 조금 더 자세히 알아봅시다. 이제 가능해졌습니다
- 단일 상태 객체 이상으로 작업하고,
- 생존 시간(TTL)이 있는 상태 객체를 생성합니다. 이는 규제 요구 사항이 있는 사용 사례에 특히 유용합니다.
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| 여러 상태 객체로 작업하기 | 불가능 | class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state1 = handle.getValueState("state1", schema1)
self._state2 = handle.getValueState("state2", schema2)
|
| TTL이 있는 상태 객체 생성 | 불가능 | class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state = handle.getValueState(
state_name="state",
schema="c LONG",
ttl_duration_ms=30 * 60 * 1000 # 30 min
)
|
내부 상태 읽기
상태를 가진 연산을 디버깅하는 것은 쿼리의 내부 상태를 검사하는 것이 어려워서 도전적이었습니다. applyInPandasWithState 와 transformWithStateInPandas 는 상태 데이터 소스 리더와 원활하게 통합하여 이를 쉽게 만듭니다. 이 강력한 기능은 사용자가 특정 상태 변수를 쿼리하고 다른 지원 옵션 범위와 함께 허용함으로써 문제 해결을 훨씬 간단하게 만듭니다.
아래는 각 상태 유형이 조회될 때 어떻게 표시되는지에 대한 예입니다. partition_id를 제외한 모든 열은 STRUCT 타입입니다. applyInPandasWithState 에서는 전체 상태가 단일 행으로 묶입니다. 따라서 사용자가 변수를 분리하고 분해하여 좋은 분석을 얻는 것은 사용자에게 달려 있습니다. transformWithStateInPandas 는 각 상태 변수의 세부 사항을 더 잘 나타내며, 각 요소는 이미 쉽게 데이터를 탐색할 수 있도록 자체 행으로 분해되어 있습니다.
| 운영자 | 상태 클래스 | statestore 읽기 |
|---|---|---|
applyInPandasWithState | 그룹스테이트 | display(
spark.read.format("statestore")
.load("/Volumes/foo/bar/baz")
)
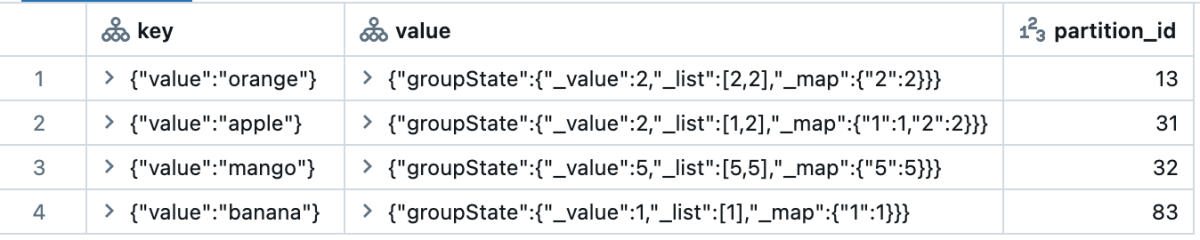 |
transformWithStateInPandas | ValueState | display(
spark.read.format("statestore")
.option("stateVarName", "valueState")
.load("/Volumes/foo/bar/baz")
)
 |
ListState | display(
spark.read.format("statestore")
.option("stateVarName", "listState")
.load("/Volumes/foo/bar/baz")
)
 | |
MapState | display(
spark.read.format("statestore")
.option("stateVarName", "mapState")
.load("/Volumes/foo/bar/baz")
)
 |
초기 상태 설정
applyInPandasWithState 는 초기 상태로 파이프라인을 시작하는 방법을 제공하지 않습니다. 이로 인해 새 파이프라인을 백필할 수 없어 파이프라인 마이그레이션이 매우 어려웠습니다. 반면에, transformWithStateInPandas 는 이를 쉽게 만드는 방법이 있습니다. handleInitialState 클래스 함수를 사용하면 사용자가 초기 상태 설정 등을 사용자 정의할 수 있습니다. 예를 들어, 사용자는 handleInitialState 를 사용하여 타이머를 설정할 수도 있습니다.
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| 초기 상태를 전달 | 불가능 | .transformWithStateInPandas(
MySP(),
"fruit STRING, count LONG",
"append",
"processingtime",
grouped_df
)
|
| 초기 상태 사용자 정의 | 불가능 | class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state = handle.getValueState("countState", "count LONG")
self.handle = handle
def handleInitialState(
self,
key: Tuple[str],
initialState: pd.DataFrame,
timerValues: TimerValues
) -> None:
self._state.update((initialState.at[0, "count"],))
self.handle.registerTimer(
timerValues.getCurrentProcessingTimeInMs() + 10000
)
|
따라서 applyInPandasWithState 파이프라인을 transformWithStateInPandas로 마이그레이션하려는 경우, 상태 리더를 사용하여 이전 파이프�라인의 내부 상태를 새 파이프라인으로 마이그레이션할 수 있습니다.
스키마 진화
스키마 진화는 데이터 구조를 수정하면서도 데이터 처리를 중단하지 않게 해주므로, 스트리밍 데이터 파이프라인을 관리하는 데 있어 중요한 측면입니다.
applyInPandasWithState를 사용하면, 쿼리가 시작되면 상태 스키마에 대한 변경이 허용되지 않습니다. applyInPandasWithState 는 저장된 스키마와 활성 스키마 사이의 동등성 을 확인함으로써 스키마 호환성을 검증합니다. 사용자가 스키마를 변경하려고 하면 예외가 발생하여 쿼리가 실패합니다. 따라서, 모든 변경사항은 사용자가 수동으로 관리해야 합니다.
고객들은 보통 두 가지 해결책 중 하나를 선택합니다: 쿼리를 새 체크포인트 디렉토리에서 시작하여 상태를 다시 처리하거나, JSON이나 Avro와 같은 형식을 사용하여 상태 스키마를 래핑하고 스키마를 명시적으로 관리합니다. 이 두 가지 접근 방식 중 어느 것도 실제로는 특별히 선호되지 않습니다.
반면에, transformWithStateInPandas 는 스키마 진화에 대해 더욱 강력한 지원을 제공합니다. 사용자는 단순히 파이프라인을 업데이트하면 되며, 스키마 변경이 호환되는 한 Apache Spark™는 자동으로 데이터를 새로운 스키마로 이동시킵니다. 쿼리는 동일한 체크포인트 디렉토리에서 계속 실행될 수 있으므로, 상태를 다시 구축하고 처음부터 모든 데이터를 다시 처리할 필요가 없습니다. 이 API는 새로운 상태 변수를 정의하고, 기존의 것을 제거하며, 코드 변경만으로 기존의 것을 업데이트할 수 있게 해줍니다.
요약하면, transformWithStateInPandas 의 스키마 진화 지원은 장기 실행 스트리밍 파이프라인의 유지 관리를 크게 단순화합니다.
| 스키마 변경 | applyInPandasWithState | transformWithStateInPandas |
|---|---|---|
| 열 추가 (중첩 열 포함) | 지원되지 않음 | 지원됩니다 |
| 열 제거 (중첩된 열 포함) | 지원되지 않음 | 지원됩니다 |
| 열 재정렬 | 지원되지 않음 | 지원됩니다 |
| 타입 확장 (예. Int → Long) | 지원되지 않음 | 지원됩니다 |
스트리밍 데이터 다루기
applyInPandasWithState 는 새로운 데이터가 도착하거나 타이머가 작동할 때 트리거되는 단일 함수를 가지고 있습니다. 함수 호출의 이유를 결정하는 것은 사용자의 책임입니다. 새로운 스트리밍 데이터가 도착했는지 확인하는 방법은 상태가 시간 초과되지 않았는지 확인하는 것입니다. 따라서, 시간 초과를 처리하기 위한 별도의 코드 분기를 포함하는 것이 모범 사례이며, 그렇지 않으면 코드가 시간 초과와 함께 제대로 작동하지 않을 위험이 있습니다.
반면에, transformWithStateInPandas 는 다른 이벤트에 대해 다른 함수를 사용합니다:
handleInputRows는 새로운 스트리밍 데이터가 도착할 때 호출되며,handleExpiredTimer는 타이머가 울릴 때 호출됩니다.
결과적으로, 추가적인 확인은 필요하지 않습니다; API가 이를 관리해줍니다.
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| 새로운 데이터와 작업하기 | def func(key, rows, state):
if not state.hasTimedOut:
...
| 클래스 MySP(StatefulProcessor):
def handleInputRows(self, key, rows, timerValues):
...
|
타이머 작업
타이머 대 시간 초과
transformWithStateInPandas 는 타이머라는 개념을 도입하며, 이는 applyInPandasWithState 의 타임아웃보다 설정하고 이해하기가 훨씬 쉽습니다.
타임아웃은 특정 시간까지 새로운 데이터가 도착하지 않으면 트리거됩니다. 추가로, 각 applyInPandasWithState 키는 하나의 타임아웃만 가질 수 있으며, 함수가 실행될 때마다 타임아웃이 자동으로 삭제됩니다.
반면에, 타이머는 예외 없이 특정 시간에 트리거됩니다. 각 transformWithStateInPandas 키에 대해 여러 타이머를 가질 수 있으며, 이들은 지정된 시간이 도달할 때 자동으로 삭제됩니다.
타임아웃 (applyInPandasWithState) | 타이머 (transformWithStateInPandas) | |
|---|---|---|
| 키 당 숫자 | 1개 | 많은 |
| 트리거 이벤트 | 시간 x까지 새로운 데이터가 도착하지 않는 경우 | 시간 x에서 |
| 이벤트 삭제 | 모든 함수 호출 시 | 시간 x에서 |
이러한 차이점은 미묘해 보일 수 있지만, 시간을 다루는 것을 훨씬 간단하게 만듭니다. 예를 들어, 오전 9시와 오후 5시에 액션을 트리거하려고 한다고 가정해 봅시다. applyInPandasWithState를 사용하면, 먼저 오전 9시 타임아웃을 생성하고, 나중에 상태로 오후 5시를 저장하고, 새로운 데이터가 도착할 때마다 타임아웃을 재설정해야 합니다. transformWithState를 사용하면 이것이 쉽습니다: 두 개의 타이머를 등록하면 됩니다.
타이머가 작동했음을 감지하기
applyInPandasWithState에서, 상태와 시간 초과는 GroupState 클래스에서 통합되어, 두 가지가 별도로 처리되지 않습니다. 함수 호출이 타임아웃 만료 또는 새로운 입력 때문인지 판단하려면 사용자가 명시적으로 state.hasTimedOut 메소드를 호출하고, 그에 따라 if/else 로직을 구현해야 합니다.
transformWithState를 사용하면 이러한 복잡한 과정이 더 이상 필요하지 않습니다. 타이머는 상태와 분리되어 각각 다르게 취급됩니다. 타이머가 만료되면 시스템은 타이머 이벤트를 전담하는 별도의 메서드인 handleExpiredTimer를 트리거합니다. 이로 인해 state.hasTimedOut 인지 아닌지 확인할 필요가 없어집니다 - 시스템이 대신 해줍니다.
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| 타이머가 울렸나요? | def func(key, rows, state):
if state.hasTimedOut:
# 네
...
else:
# 아니요
...
| 클래스 MySP(StatefulProcessor):
def handleExpiredTimer(self, key, expiredTimerInfo, timerValues):
when = expiredTimerInfo.getExpiryTimeInMs()
...
|
이벤트 시간 vs 처리 시간으로 CRUD 수행
applyInPandasWithState API의 특이점은 처리 시간과 이벤트 시간에 기반한 타임아웃 설정을 위한 별도의 ��메소드가 존재한다는 것입니다. GroupStateTimeout.ProcessingTimeTimeout를 사용할 때, 사용자는 setTimeoutDuration으로 시간 초과를 설정합니다. 반면에, EventTimeTimeout의 경우 사용자는 대신 setTimeoutTimestamp 를 호출합니다. 한 방법이 작동하면 다른 방법은 오류를 발생시키고, 그 반대의 경우도 마찬가지입니다. 또한, 이벤트 시간과 처리 시간 모두에 대해, 시간 초과를 삭제하는 유일한 방법은 그 상태도 삭제하는 것입니다.
반면에, transformWithStateInPandas 는 타이머 작업에 대해 더 직관적인 접근 방식을 제공합니다. 그 API는 이벤트 시간과 처리 시간 모두에 대해 일관되며, 타이머를 생성(registerTimer), 읽기(listTimers), 삭제(deleteTimer)하는 메소드를 제공합니다. transformWithStateInPandas를 사용하면 동일한 키에 대해 여러 타이머를 생성할 수 있어, 시간의 다양한 지점에서 데이터를 방출하는 데 필요한 코드를 크게 단순화할 수 있습니다.
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| 하나 생성하기 | state.setTimeoutTimestamp(tsMilli) | self.handle.registerTimer(tsMilli) |
| 많은 것을 생성하십시오 | 불가능 | self.handle.registerTimer(tsMilli_1) self.handle.registerTimer(tsMilli_2) |
| 읽기 | state.oldTimeoutTimestamp | self.handle.listTimers() |
| 업데이트 | state.setTimeoutTimestamp(tsMilli) # for EventTime state.setTimeoutDuration(durationMilli) # for ProcessingTime | self.handle.deleteTimer(oldTsMilli) self.handle.registerTimer(newTsMilli) |
| 삭제 | state.remove() # 하지만 이것은 타임아웃과 상태를 삭제합니다 | self.handle.deleteTimer(oldTsMilli) |
여러 상태 유지 연산자와 함께 작업하기
한 개의 파이프라인에서 상태 유지 연산자를 연결하는 것은 전통적으로 도전적이었습니다. applyInPandasWithState 연산자는 사용자가 워터마크와 연관된 출력 열을 지정할 수 없습니다. 결과적으로, 상태 유지 연산자는 applyInPandasWithState 연산자 뒤에 배치될 수 없습니다. 따라서, 사용자들은 상태를 유지하는 계산을 여러 파이프라인에 분할해야 했으며, 이를 중개하는 데는 Kafka나 다른 저장 계층이 필요했습니다. 이로 인해 비용과 대기 시간이 모두 증가하게 됩니다.
반대로, transformWithStateInPandas 는 다른 상태 유지 연산자와 안전하게 연결될 수 있습니다. 사용자는 아래 예시와 같이 파이프라인에 추가할 때 이벤트 시간 열을 지정하기만 하면 됩니다:
이 접근 방식은 watermark 정보를 하류 연산자에게 전달하여, 새로운 파이프라인과 중간 저장소를 설정하지 않고도 늦은 레코드 필터링과 상태 추방을 가능하게 합니다.
결론
Apache Spark™ 구조화된 스트리밍의 새로운 transformWithStateInPandas 연산자는 이전의 applyInPandasWithState 연산자보다 많은 이점을 제공합니다. 더 큰 유연성, 향상된 상태 관리 기능, 그리고 더 사용자 친화적인 API를 제공합니다. 여러 상태 객체, 상태 검사, 그리고 사용자 정의 타이머와 같은 기능들로, transformWithStateInPandas 는 복잡한 상태 유지 스트리밍 애��플리케이션의 개발을 단순화합니다.
경험 많은 사용자에게는 여전히 applyInPandasWithState 가 익숙할 수 있지만, transformWithState's 향상된 기능과 다양성은 현대의 스트리밍 작업에 더 나은 선택이 됩니다. transformWithStateInPandas를 채택함으로써, 개발자들은 더 효율적이고 유지보수가 쉬운 스트리밍 파이프라인을 만들 수 있습니다. Apache Spark™ 4.0에서 직접 시도해 보고, Databricks Runtime 16.2 이상에서도 사용해 보세요.
| 기능 | applyInPandasWithState (State v1) | transformWithStateInPandas (State v2) |
|---|---|---|
| 지원되는 언어들 | Scala, Java, 그리고 Python | Scala, Java, 그리고 Python |
| 처리 모델 | 함수 기반 | 객체 지향 |
| 입력 처리 | 그룹화 키 당 입력 행 처리 | 그룹화 키 당 입력 행 처리 |
| 출력 처리 | 선택적으로 출력 생성 가능 | 선택적으로 출력 생성 가능 |
| 지원되는 시간 모드 | 처리 시간 & 이벤트 시간 | 처리 시간 & 이벤트 시간 |
| 세분화된 상태 모델링 | 지원되지 않음 (단일 상태 객체만 전달됨) | 지원됨 (사용자는 필요에 따라 어떤 상태 변수든 생성할 수 있습니다) |
| 복합 유형 | 지원되지 않음 | 지원됨 (현재 Value, List 및 Map 유형을 지원) |
| 타이머들 | 지원되지 않음 | 지원됩니다 |
| 상태 정리 | 수동 | 상태 TTL에 대한 지원으로 ��자동화 |
| 상태 초기화 | 부분 지원 (Scala에서만 사용 가능) | 모든 언어에서 지원 |
| 이벤트 타임 모드에서 연산자 연결하기 | 지원되지 않음 | 지원됩니다 |
| 상태 데이터 소스 리더 지원 | 지원됩니다 | 지원됩니다 |
| 상태 모델 진화 | 지원되지 않음 | 지원됩니다 |
| 상태 스키마 진화 | 지원되지 않음 | 지원됩니다 |
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.