버전 없는 Apache Spark™ 살펴보기: AI 기반 업그레이드 및 20억 개 워크로드에 대한 원활한 안정성
플랫폼에서 수동 Spark 업그레이드를 제거한 방법
작성자: Justin Breese, 비자얀 프라바카란, 아미트 슈클라, Martin Grund, Stefania Leone, Chris Munson, Tatiana Romanova , Lennart Kats
- Apache Spark™ 업그레이드는 이제 Serverless Notebooks 및 Jobs용 versionless를 통해 자동화되어 마이그레이션이나 코드 변경이 필요 없습니다.\n
- 안정적인 클라이언트 API와 AI 기반 릴리스 관리를 통해 최신 기능과 수정 사항을 제공하면서도 워크로드의 안정성을 유지합니다.
- 20억 개 이상의 워크로드가 99.99%의 성공률로 업그레이드되어 이 시스템이 대규모로 작동함을 입증했습니다.
Apache Spark™ 업그레이드는 결코 쉽지 않았습니다. 모든 주요 버전은 성능 개선, 버그 수정, 새로운 기능을 제공하지만 그 과정은 고통스럽습니다. 대부분의 Spark 사용자에게는 익숙한 일입니다. 워크로드가 중단되고 API가 변경되며, 개발자는 따라잡기 위해 몇 주 동안 작업을 수정해야 할 수 있습니다. 이로 인해 새로운 기능, 성능 개선, 버그 및 보안 수정 사항을 채택하는 데 훨씬 더 오랜 시간이 걸립니다.
Databricks는 이러한 마찰을 완전히 제거하고 싶었습니다. 그 결과 지속적인 업그레이드, 코드 변경 불필요, 독보적인 안정성을 제공하는 새로운 Spark 실행 방식인 Versionless Spark가 탄생했습니다. 지난 18개월 동안 Serverless Notebooks 및 Jobs를 출시한 이후, Versionless Spark는 사용자의 개입 없이 주요 Spark 버전을 포함하여 25개의 Databricks Runtime 릴리스에 걸��쳐 20억 개 이상의 Spark 워크로드를 자동으로 업그레이드했습니다.
이 블로그에서는 저희가 Versionless Spark를 구축한 방법과 그 결과를 공유하고, 최근 발표된 SIGMOD 2025 논문에서 더 자세한 내용을 확인하는 방법을 알려드립니다.
새로운 방향: 버전 관리 클라이언트를 통한 안정적인 공개 API
원활한 업그레이드를 지원하고 Databricks 사용자의 시간을 절약하려면, 서버를 원활하게 업데이트할 수 있도록 안정적인 공개 Spark API가 필요했습니다. 이는 Spark Connect를 기반으로 하는 안정적인 버전 관리형 클라이언트 API를 통해 달성되었습니다. 이 API는 클라이언트를 Spark 서버와 분리하여 Databricks가 서버를 자동으로 업그레이드할 수 있도록 지원합니다.
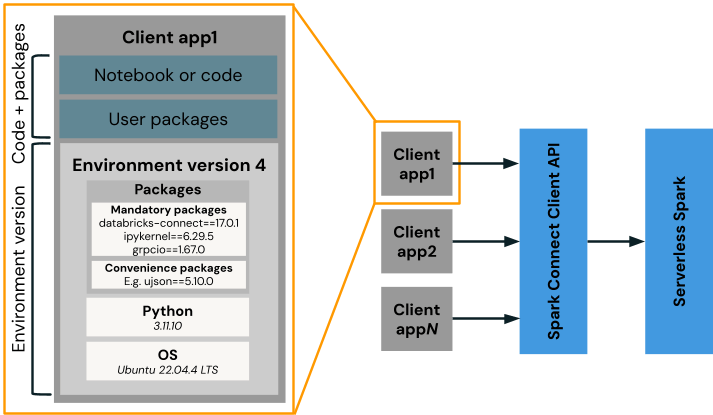
Databricks 환경 버전은 Spark Connect, Python 및 pip 종속성과 같은 클라이언트 패키지를 포함하는 기본 이미지 역할을 합니다. 사용자 코드와 추가 패키지는 이 환경 위에서 실행되며(예: 클라이언트 앱1) 서버리스 Spark 서비스와 통신합니다. Databricks는 주기적으로 새로운 환경 버전을 출시하며, 각 버전은 DBR LTS와 유사하게 3년간 지원됩니�다. 기본적으로 새 워크로드는 최신 버전을 사용하지만, 사용자는 원하는 경우 지원되는 이전 버전에서 계속 실행할 수 있습니다.
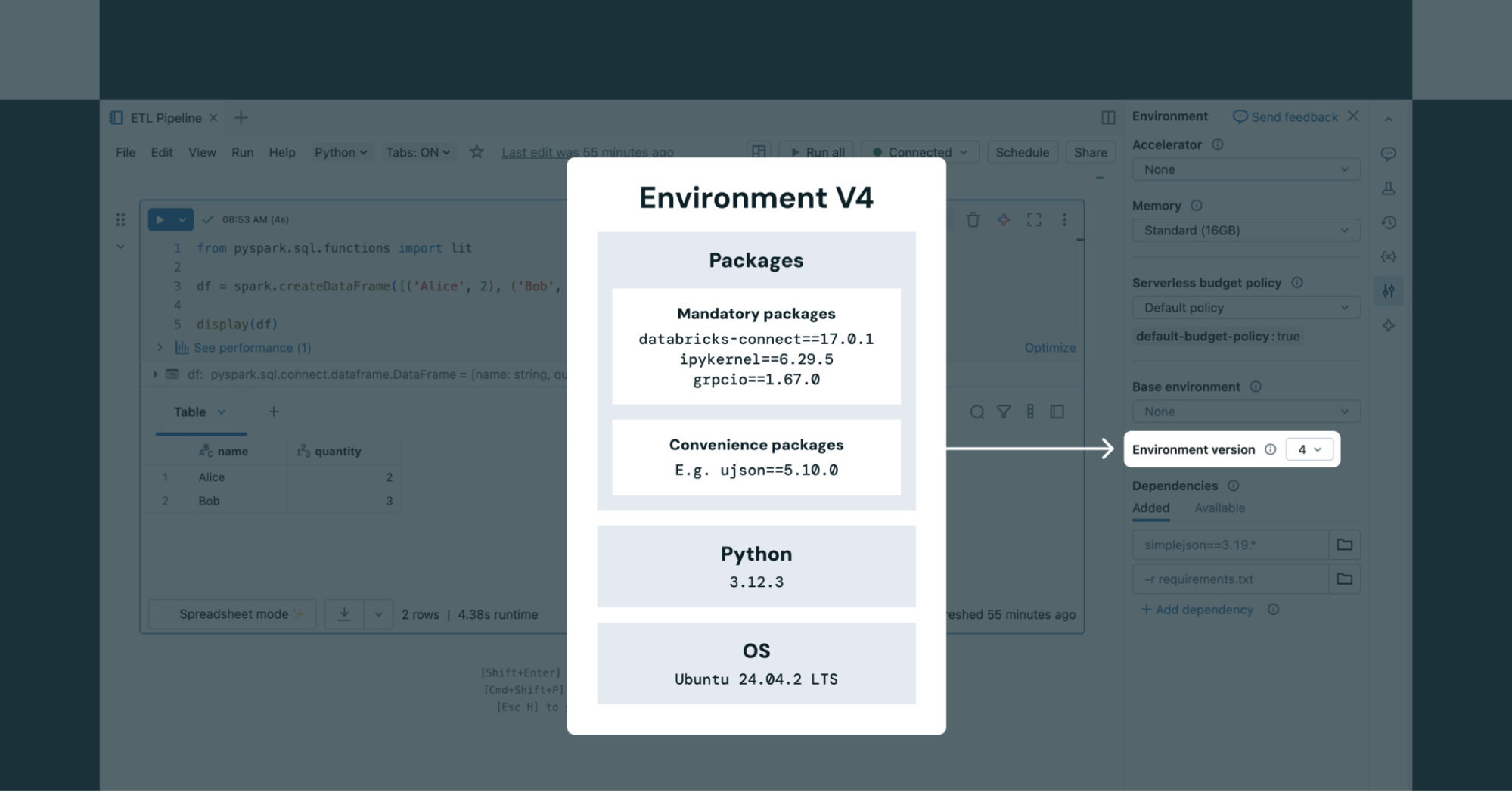
서버리스 Notebooks를 사용할 때 사용자는 (그림 2와 같이) 노트북의 환경(Environment) 패널에서 지원되는 환경 버전 중에서 선택할 수 있습니다. 서버리스 작업의 경우, 환경 버전은 Job API를 통해 정의됩니다.
자동 업그레이드 및 AI 기반 롤백
Databricks에서 자동화된 워크로드를 실행할 때 사용자에게 빈번한 보안, 안정성, 성능 업데이트를 제공하는 것은 매우 중요합니다. 이는 특히 프로덕션 파이프라인의 경우 안정성을 저해하지 않으면서 자동으로 수행되어야 합니다. AI 기반 RSS(릴리스 안정성 시스템)는 자동화된 워크로드의 고유한 핑거프린트와 실행 메타데이터를 결합하여 새 서버 버전에서 성능이 저하된 워크로드를 감지하고 후속 실행을 자동으로 이전 서버 버전으로 되돌립니다. RSS는 여러 구성 요소를 포함합니다.
- 각 워크로드에는 일련의 속성을 기반으로 동일한 워크로드의 반복 실행을 식별하는 워크로드 핑거프린트 가 있습니다.
- 실행 기록 은 이전 실행에 대한 메타데이터를 보관합니다.
- 피닝 서비스 는 두 개의 다른 서버 버전에서 다르게 작동하는 워크로드를 추적합니다.
- ML 모델 이 오류를 분류하고 티켓의 우선순위를 정하며 플릿 내에서 이상을 감지합니다.
- 이상 감지 파이프라인이 전체 플릿에서 실행됩니다.
- 릴리스 상태 보고서 및 알림은 Databricks 엔지니어링팀에 실시간 릴리스 상태 정보를 제공합니다.

자동 롤백은 회귀가 발생한 후에도 워크로드가 계속해서 성공적으로 실행되도록 보장합니다.
RSS가 자동화된 작업에 대해 롤백을 수행하면 워크로드는 이전에 성공했던 마지막으로 알려진 버전에서 자동으로 다시 실행됩니다. 실제 사례를 통해 RSS를 설명해 보겠습니다. 특정 자동화된 작업이 4월 9일에 DBR 버전 16.1.2를 사용하여 실행되었으나 오류가 발생했습니다. 이전 실행 기록에 따르면 해당 워크로드는 16.1.1 버전에서 며칠 연속으로 성공했습니다. ML 모델은 오류의 원인이 버그일 가능성이 높다고 판단했습니다. 그 결과, pinning 서비스에 pinning 항목이 자동으로 생성되었습니다. 워크로드가 자동으로 재시도(이 경우)를 시작했을 때 pinning 서비스 항목을 발견했고 워크로드는 16.1.1에서 다시 실행되어 성공했습니다. 이로 인해 자동 분류 프로세스가 시작되었고, Databricks 엔지니어링팀은 알림을 받고 버그를 식별하여 수정 사항을 발표했습니다. 그동안 후속 워크로드 실행은 16.1.1에 고정(pin)되어 있었습니다 버그 수정이 16.1.3에 출시될 때까지. 그리고 워크로드는 결국 16.1.3으로 릴리스되었습니다 (파란색 상자) 그리고 계속해서 성공적으로 실행되었습니다.
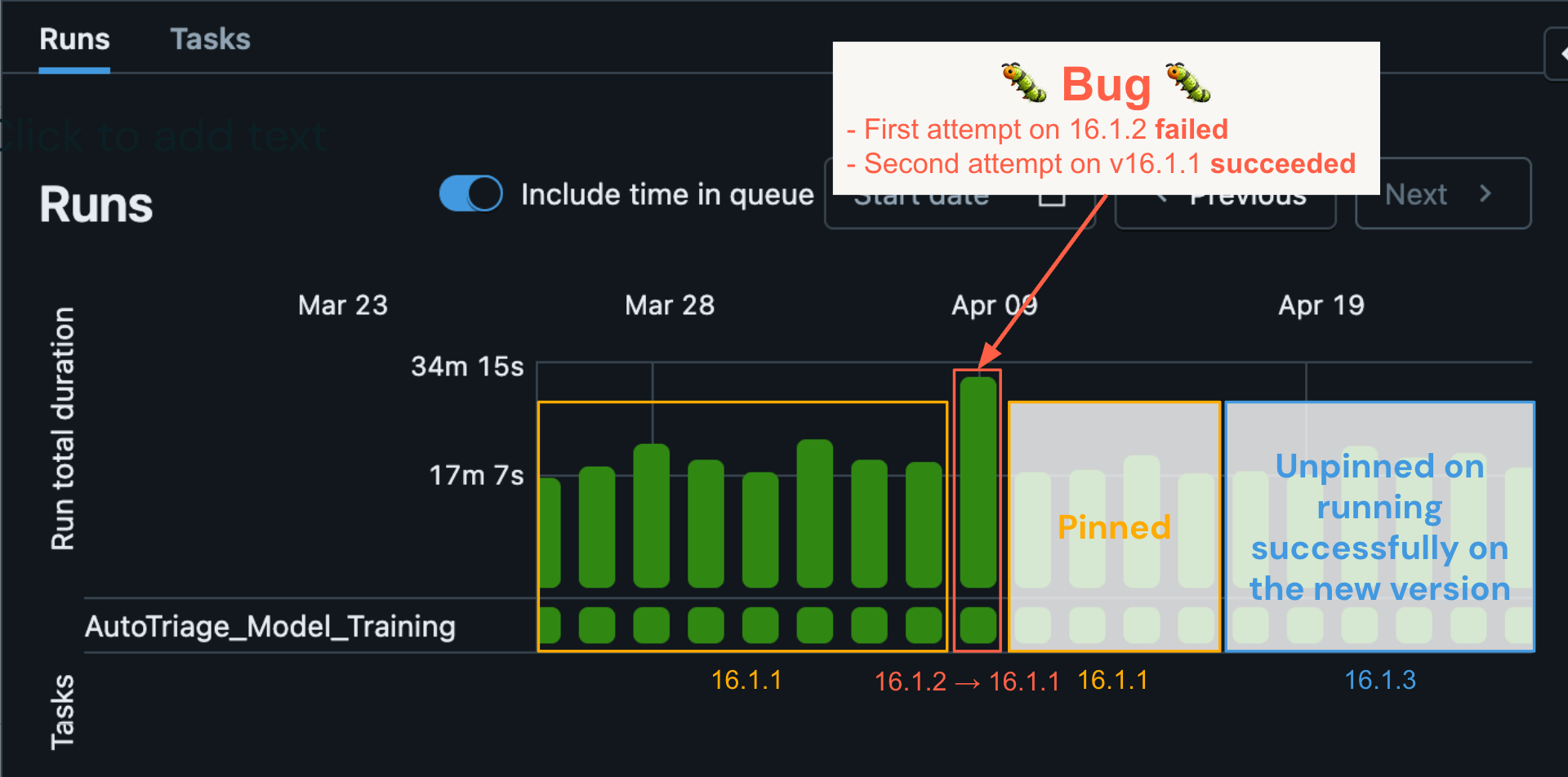
이 경우, 고객의 안정성에 아무런 영향을 미치지 않으면서 소수의 고객 워크로드에만 영향을 미치는 매우 미묘한 버그를 신속하게 감지하고 수정할 수 있었습니다. 이를 사용자가 수동으로 업그레이드해야 하고 일반적으로 상당한 지연이 발생하는 기존 Spark 업그레이드 모델과 비교해 보세요. 사용자가 업그레이드를 수행하면 작업에 오류가 발생하기 시작하여 문제를 해결하기 위해 지원 티켓을 제출해야 하는 경우가 있었습니다. 이 문제를 해결하는 데는 훨씬 더 오랜 시간이 걸릴 것이며, 결국 더 많은 고객의 참여가 필요하고 신뢰도도 떨어질 것입니다.
결론
저희는 릴리스 안정성 시스템을 사용하여 Spark 4로의 전환을 포함, DBR 14에서 DBR 17까지 20억 개 이상의 작업을 업그레이드하면서 collation, 블룸 필터 조인 최적화, JDBC 드라이버와 같은 새로운 기능을 원활하게 제공했습니다. 그중 작업의 0.000006%만이 자동 롤백이 필요했으며, 모든 롤백은 수정 사항으로 해결되어 평균 12일 이내에 최신 버전으로 성공적으로 업그레이드되었습니다. 이 성과는 사용자의 코드 변경 없이 수십억 개의 프로덕션 Spark 워크로드를 자동으로 업그레이드한 업계 최초의 기록입니다.
저희는 환경 버전 관리, 자동 업그레이드되는 버전 없는 서버, 릴리스 안정성 시스템을 결합한 새로운 아키텍처를 구축하여 Spark 업그레이드를 완전히 원활하게 만들었습니다. 이러한 업계 최초의 접근 방식을 통해 Databricks는 기능과 수정 사항을 훨씬 더 빠르고 안정적으로 사용자에게 제공할 수 있게 되었으며, 데이터 팀은 인프라 유지보수보다 가치가 높은 비즈니스 성과에 더 집중할 수 있습니다.
이 여정은 이제 막 시작되었으며, 앞으로 UX를 더욱 개선해 나갈 것입니다.
다음 단계
- SIGMOD 2025 에서 발표한 이 주제에 대한 심층적인 논문을 확인해 보세요.
- Notebook 및 작업을 위한 서버리스 컴퓨팅의 최초 GA 발표
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.