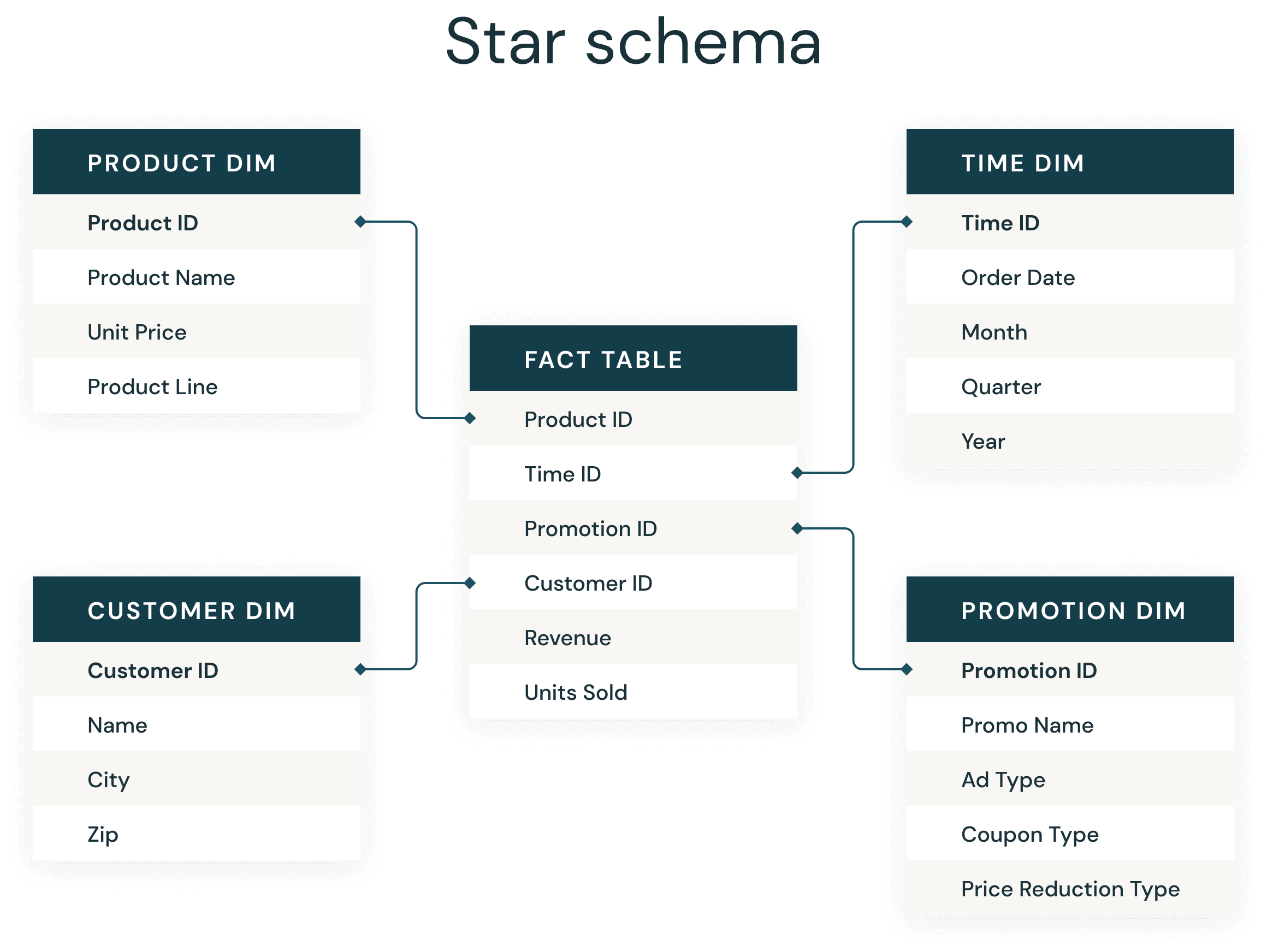
Delta Lake로 Databricks에서 스타 스키마를 구현하기 위한 간단한 5단계
Delta Lake를 사용하여 데이터 웨어하우스 및 데이터 마트에서 사용되는 스타 스키마 데이터베이스에서 일관되게 최고의 성능을 얻는 업데이트된 방법
- Delta 테이블을 사용하여 팩트 테이블과 차원 테이블을 만드세요.
- Liquid Clustering을 사용하여 최적의 파일 크기를 제공하세요.
- 팩트 테이블에 Liquid Clustering을 사용하세요.
Databricks의 최신 기능과 Spark의 발전된 기술을 개발자가 활용하는 방법을 보여드리기 위해 이 블로그를 업데이트하고 있습니다.
대부분의 데이터 웨어하우스 개발자에게 스타 스키마는 매우 친숙한 개념입니다. 1990년대에 Ralph Kimball이 도입한 스타 스키마는 비즈니스 데이터를 차원(시간 및 제품 등)과 팩트(금액 및 수량의 트랜잭션 등)로 비정규화하는 데 사용됩니다. 스타 스키마는 반복적인 비즈니스 정의의 중복을 줄여 데이터를 효율적으로 저장하고, 기록을 유지하며 데이터를 업데이트함으로써 집계와 필터링을 빠르게 수행할 수 있도록 합니다.
비즈니스 인텔리��전스 애플리케이션을 지원하기 위한 스타 스키마의 일반적인 구현은 매우 일상적이고 성공적이어서 많은 데이터 모델러들이 거의 눈 감고도 할 수 있을 정도가 되었습니다. Databricks에서는 수많은 데이터 애플리케이션을 제작해 왔으며, 훌륭한 결과를 보장하는 기본 구현이자 경험 법칙으로 삼을 수 있는 모범 사례 접근법을 끊임없이 찾고 있습니다.
기존 데이터 웨어하우스에서와 마찬가지로, Delta Lake에도 Delta 스타 스키마 조인을 크게 향상시킬 수 있는 몇 가지 간단한 경험 법칙이 있습니다.
성공을 위한 기본 단계는 다음과 같습니다.
- Delta 테이블을 사용하여 팩트 및 차원 테이블을 생성하세요.
- Liquid Clustering을 사용하여 최적의 파일 크기를 확보하세요.
- 팩트 테이��블에 Liquid Clustering을 사용하세요.
- 더 큰 차원 테이블의 키와 자주 사용되는 조건자에 Liquid Clustering을 사용하세요
- Predictive Optimization을 활용하여 테이블을 유지 관리하고 통계를 수집하세요.
1. Delta Tables를 사용하여 팩트 및 차원 테이블을 생성하세요.
Delta Lake 는 데이터 레이크 테이블에서 삽입, 업데이트, 삭제를 용이하게 하고 ACID 트랜잭션을 추가하여 유지 관리 및 수정을 단순화하는 개방형 스토리지 형식 레이어입니다. Delta Lake는 또한 동적 파일 프루닝 을 수행하여 더 빠른 SQL 쿼리를 위해 최적화하는 기능도 제공합니다.
Delta Lake가 default 테이블 형식인 Databricks Runtime 8.x 이상(현재 장기 지원 런타임은 15.4)에서는 구문이 간단합니다. 다음과 같이 SQL을 사용하여 Delta 테이블을 생성할 수 있습니다.
CREATE TABLE MY_TABLE (COLUMN_NAME STRING) CLUSTER BY (COLUMN_NAME);
8.x 런타임 이전에는 Databricks에서 USING DELTA 구문을 사용하여 테이블을 생성해야 했습니다.
8.x 런타임 이전에는 Databricks에서 USING DELTA 구문을 사용하여 테이블을 생성해야 했습니다.
2. Liquid Clustering을 사용하여 최적의 파일 크기 제공
Apache Spark™ 쿼리에서 가장 시간이 많이 소요되는 두 가지 작업은 클라우드 스토리지에서 데이터를 읽는 시간과 모든 기본 파일을 읽어야 한다는 점입니다. 데이터 스키핑 을 Delta Lake에서 사용하면 쿼리는 관련 데이터가 포함된 Delta 파일만 선택적으로 읽어 상당한 시간을 절약할 수 있습니다. 데이터 스키핑은 정적 파일 정리, 동적 파일 정리, 정적 파티션 정리, 동적 파티션 정리에 도움이 될 수 있습니다.
Liquid Clustering이 도입되기 전에는 수동으로 설정해야 했습니다. 쿼리에 효율적이도록 파일이 적절한 크기인지 확인하는 경험적 규칙이 있었습니다. 이제 Liquid Clustering을 사용하면 최적화 루틴으로 파일 크기가 자동으로 결정되고 유지 관리됩니다.
이 기사를 읽고 계시거나 (이전 버전을 읽으신 경우) 이미 ZORDER로 테이블을 생성하셨다면 Liquid Clustering으로 테이블을 다시 생성해야 합니다.
또한 Liquid 클러스터링은 파일이 너무 작거나 너무 커지는 것(데이터 쏠림 및 균형)을 방지하도록 최적화하고 새 데이터가 추가될 때 파일 크기를 업데이트하여 테이블을 최적화된 상태로 유지합니다.
3. 팩트 테이블에 Liquid Clustering을 사용하세요.
쿼리 속도를 개선하기 위해 Delta Lake는 Liquid 클러스터링을 사용하여 클라우드 스토리지에 저장된 데이터의 레이아웃을 �최적화하는 기능을 지원합니다. 실제로는 보조 구조가 아니지만 데이터베이스 세계의 클러스터형 인덱스와 유사한 상황에서 사용할 열을 기준으로 클러스터링하세요.리퀴드 클러스터링된 테이블은 CLUSTER BY 정의에 따라 데이터를 클러스터링하여 CLUSTER BY 정의의 열 값과 같은 행이 최적의 파일 집합에 함께 배치되도록 합니다.
대부분의 데이터베이스 시스템은 쿼리 성능을 향상시키기 위한 방법으로 인덱싱을 도입했습니다. 인덱스는 파일이므로 데이터 크기가 커짐에 따라 해결해야 할 또 다른 빅데이터 문제가 될 수 있습니다. 대신 Delta Lake는 Parquet 파일의 데이터를 정렬하여 객체 스토리지에서 범위 선택을 더 효율적으로 만듭니다. 통계 수집 프로세스 및 데이터 스키핑과 결합된 리퀴드 클러스터형 테이블은 쿼리가 찾는 데이터를 찾기 위해 또 다른 compute 병목 현상을 일으키지 않으면서, 인덱스가 해결한 데이터베이스의 seek 대 scan 작업과 유사합니다.
Liquid Clustered 테이블의 경우, CLUSTER BY 절의 열 수를 가장 적합�한 1~4개로 제한하는 것이 좋습니다. 저희는 외래 키를 선택했습니다 (실제로 강제되는 외래 키가 아닌 사용에 따른 외래 키) 이는 작업자에게 브로드캐스트하기에는 너무 큰 3개의 가장 큰 차원에서 온 것입니다.
마지막으로, Liquid 클러스터링은 ZORDER와 파티셔닝의 필요성을 모두 대체하므로 Liquid 클러스터링을 사용하면 더 이상 테이블을 명시적으로 하이브 파티션할 필요가 없거나 할 수 없습니다.
4. 더 큰 차원의 키와 자주 사용될 조건자에 Liquid Clustering을 사용하세요.
이 블로그를 읽고 계신다면 차원 테이블에 차원과 대리 키 또는 기본 키가 있을 가능성이 높습니다. 이 키는 큰 정수이며 고유성이 검증되고 예상됩니다. databricks runtime 10.4 이후, ID 열이 정식 출시되었으며 CREATE TABLE 구문의 일부입니다.
Databricks는 또한 Runtime 11.3에서 적용되지 않는 기본 키 및 외래 키 를 도입했으며 Unity Catalog가 활성화된 클러스터 및 작업 공간에 표시됩니다.
저희가 작업하던 차원 중 하나는 10억 개가 넘는 행을 가지고 있었으며, 조건자를 클러스터링된 테이블에 추가한 후 파일 건너뛰기 및 동적 파일 프루닝의 이점을 얻었습니다. 더 작은 차원은 차원 키 필드를 기준으로 클러스터링되었으�며 팩트와의 조인에서 브로드캐스트되었습니다. 팩트 테이블에 대한 조언과 마찬가지로, Cluster By의 열 수를 키 외에 필터에 포함될 가능성이 가장 높은 1~4개의 차원 필드로 제한하세요.
파일 건너뛰기 및 유지 관리 용이성 외에도, liquid clustering은 ZORDER보다 더 많은 열을 추가할 수 있게 해주며 hive 스타일 파티셔닝보다 더 유연합니다.
5. 테이블을 분석하여 Adaptive Query Execution Optimizer를 위한 통계를 수집하고 Predictive Optimization을 활성화하세요.
Apache Spark™ 3.0의 주요 발전 사항 중 하나는 적응형 쿼리 실행(Adaptive Query Execution), 줄여서 AQE였습니다. Spark 3.0부터 AQE에는 셔플 후 파티션 병합, 정렬-병합 조인을 브로드캐스트 조인으로 변환, 스큐 조인 최적화 등 세 가지 주요 기능이 있습니다. 이러한 기능들은 함께 Spark에서 차원 모델의 성능을 가속화합니다.
AQE가 사용자를 위해 어떤 계획을 선택할지 알 수 있도록 테이블에 대한 통계를 수집해야 합니다. 이 작업은 ANALYZE TABLE 명령을 실행하여 수행합니다. 고객들은 테이블 통계 수집이 복잡한 조인을 포함한 차원 모델의 query 실행 시간을 크게 단축시켰다고 보고했습니다.
ANALYZE TABLE MY_BIG_DIM COMPUTE STATISTICS FOR ALL COLUMNS
로드 루틴의 일부로 Analyze table을 계속 활용할 수 있지만, 이제는 계정, 카탈로그 및 스키마에서 예측 최적화를 간단히 활성화하는 것이 더 좋습니다.
ALTER CATALOG [catalog_name] {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
ALTER {SCHEMA | DATABASE} schema_name {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
예측 최적화 는 Databricks에서 Unity Catalog가 관리하는 테이블에 대한 유지 관리 운영을 수동으로 관리할 필요성을 없애줍니다.
Predictive Optimization이 활성화되면 Databricks는 유지 관리 운영으로 이점을 얻을 수 있는 테이블을 자동으로 식별하고 사용자를 위해 해당 운영을 실행합니다. 유지 관리 운영은 필요할 때만 실행되므로 불필요한 유지 관리 운영 실행과 성능 추적 및 문제 해결에 따르는 부담을 없애줍니다.
현재 예측 최적화는 테이블에서 Vacuum 및 Optimize를 수행합니다. Predictive Optimization에 대한 업데이트를 확인하고, 이 기능에 Liquid 클러스터형 키 자동 적용뿐만 아니라 테이블 분석 및 통계 수집 기능이 통합되는 시점을 기대해 주세요.
결론
위의 가이드라인을 따르면 조직은 쿼리 시간을 줄일 수 있습니다. 이 예시에서는 동일한 클러스터에서 쿼리 성능을 9배 향상시켰습니다. 최적화를 통해 I/O가 크게 줄었으며 필요한 데이터만 처리되도록 보장했습니다. 또한 Delta Lake의 유연한 구조 덕분에 비즈니스 인텔리전스 도구��에서 애드혹으로 전송되는 쿼리 유형을 확장하고 처리할 수 있다는 이점을 얻었습니다.
이 블로그의 첫 번째 버전부터 Photon은 이제 Databricks SQL Warehouse에서 기본적으로 켜져 있으며 All Purpose 및 Jobs 클러스터에서 사용할 수 있습니다. Photon 과 Databricks를 사용한 모든 Spark SQL 쿼리에 제공될 성능 향상에 대해 자세히 알아보세요.
고객은 Databricks Runtime에서 Photon을 활성화하여 ETL/ELT 및 SQL 쿼리 성능 향상을 기대할 수 있습니다. 여기에 설명된 모범 사례를 Photon이 활성화된 Databricks 런타임과 결합하면 최고의 클라우드 데이터 웨어하우스를 능가할 수 있는 짧은 대기 시간의 쿼리 성능을 기대할 수 있습니다.
지금 바로 Databricks SQL로 스타 스키마 데이터베이스를 구축하세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.