유연한 노드 유�형 정식 출시
자동 인스턴스 대체 기능으로 클러스터 시작 안정성을 개선하고 컴퓨팅 비용을 절감하세요
- 용량 오류로부터 워크로드 보호: 선호하는 VM 유형을 사용할 수 없는 경우 Databricks는 호환 가능한 대안으로 자동 대체하여 클러스터를 계속 시작할 수 있도록 합니다.
- 모든 클라우드에서 Fleet 스타일의 유연성을 확보하세요: 유연한 노드 유형은 Azure, GCP, AWS에 자동 인스턴스 유형 fallback을 제공합니다. 간단한 "원클릭"으로 워크스페이스 전체에 활성화하고, 확보한 리소스에 대한 명확한 가시성을 제공하며, fallback 순서를 선택적으로 구성할 수 있습니다.
- 안정성을 저해하지 않으면서 비용 절감: 사용 가능한 경우 할인된 스팟(Spot) 인스턴스를 우선적으로 사용하고, 시작 성공을 유지하기 위해 필요할 때만 대체합니다.
특히 트래픽이 많고 부담이 큰 기간에는 특정 compute 용량을 확보하기 어려울 수 있습니다. 데이터 엔지니어와 플랫폼 관리자는 클라우드 공급자가 특정 인스턴스 유형에 대한 요청을 이행할 수 없어 클러스터 시작이 실패할 때 발생하는 용량 부족 또는 "재고 부족(stockout)" 오류에 대한 좌절감을 너무나 잘 알고 있습니다.
다음과 같은 경우:
AWS_INSUFFICIENT_INSTANCE_CAPACITY_FAILURE- Azure의
CLOUD_PROVIDER_RESOURCE_STOCKOUT또는 GCP_INSUFFICIENT_CAPACITY,
이러한 오류는 특히 가동 시간이 가장 중요한 비즈니스 핵심 기간 동안 중요한 워크로드를 중단시킵니다.
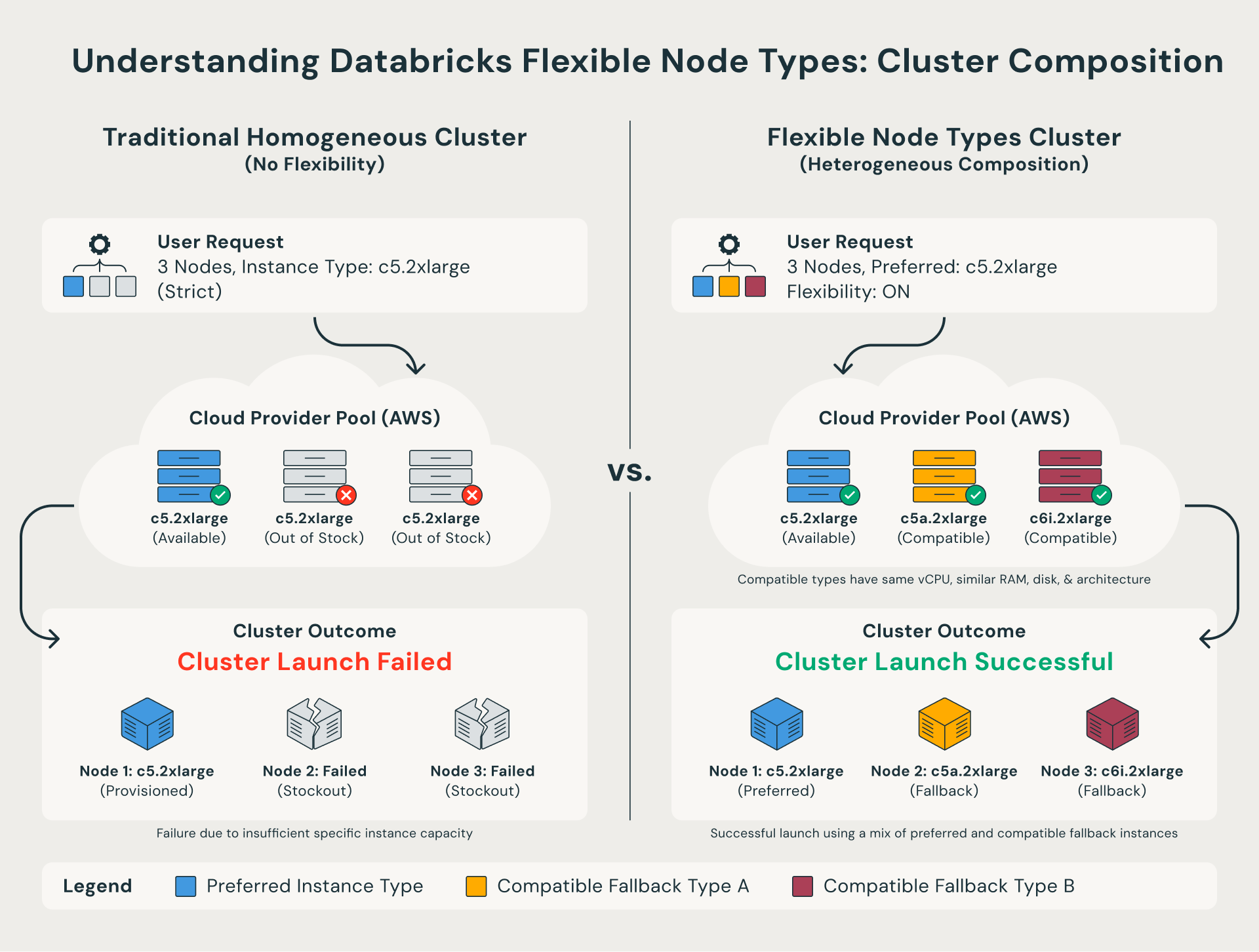
유연한 노드 유형이란 무엇인가요?
기존에는 Databricks 클러스터의 모든 노드가 구성에 지정된 정확한 인스턴스 유형이어야 했습니다. 해당 특정 유형을 사용할 수 없는 경우 클러스터 시작이 실패했습니다.
유연한 노드 유형은 이 제약 조건을 제거합니다. 선호하는 인스턴스 유형을 사용할 수 없는 경우 Databricks는 동일한 컴퓨팅 형태를 공유하는 호환 가능한 대안으로 자동으로 대체됩니다. 다시 말해, 완전히 실패하는 대신 유사한 인스턴스 유형을 혼합하여 사용하여 클러스터가 성공적으로 시작됩니다.
더 엄격한 제어가 필요한 팀은 API를 통해 시도할 인스턴스 유형과 순서를 포함한 사용자 지정 대체 목록을 정의할 수도 있습니다.
주요 장점
피크 수요 시 클러스터 시작 실패 감소
유연한 노드 유형은 용량 관련 장애의 빈도와 심각성을 모두 줄여줍니다. 클라우드 공급자가 선호하는 인스턴스 유형을 제공할 수 없을 때 Databricks는 호환 가능한 대안으로 자동 대체하여 오류 발생 없이 클러스터를 시작할 수 있도록 합니다.
최적화된 스팟 인스턴스 사용
Spot-with-fallback으로 구성된 클러스터의 경우, 유연한 노드 유형은 On-Demand 인스턴스로 되돌아가기 전에 전체 폴백 목록에서 Spot 용량을 확보하려고 시도합니다. 이를 통해 스팟(Spot)에서 실행되는 클러스터의 비율을 높여 성공적인 시작을 우선순위로 유지하면서 컴퓨팅 비용을 절감할 수 있습니다.
명확한 가시성과 정밀한 제어
팀은 `node_timeline` 시스템 테이블을 사용하여 어떤 노드 유형이 정확히 확보되었는지 검사할 수 있습니다. 또한 API를 통해 사용자 지정 폴백 순서를 정의하여 비용 및 성능 동작을 정밀하게 제어할 수 있습니다.
빠른 시작
워크스페이스 관리자는 관리자 설정에서 이 기능을 쉽게 활성화할 수 있습니다(문서: AWS, Azure, GCP). 그 후 이 기능은 모든 새 클러스터 시작에 즉시 적용됩니다. 장기 실행 클러스터는 다음 재시작 시 이 기능을 적용하게 되며, 기존 작업을 위해 생성되는 향후 작업 클러스터도 이 기능을 자동으로 활용합니다.
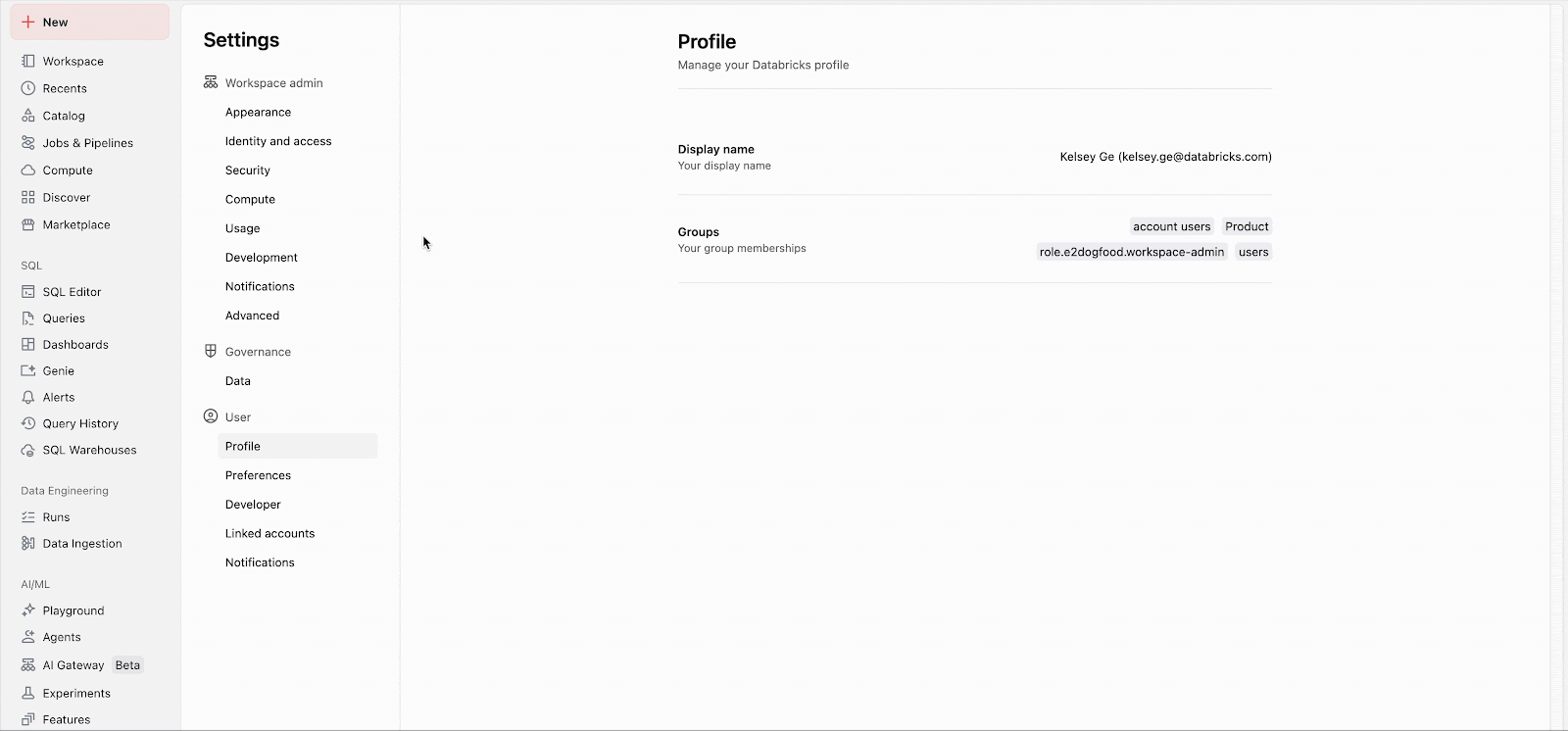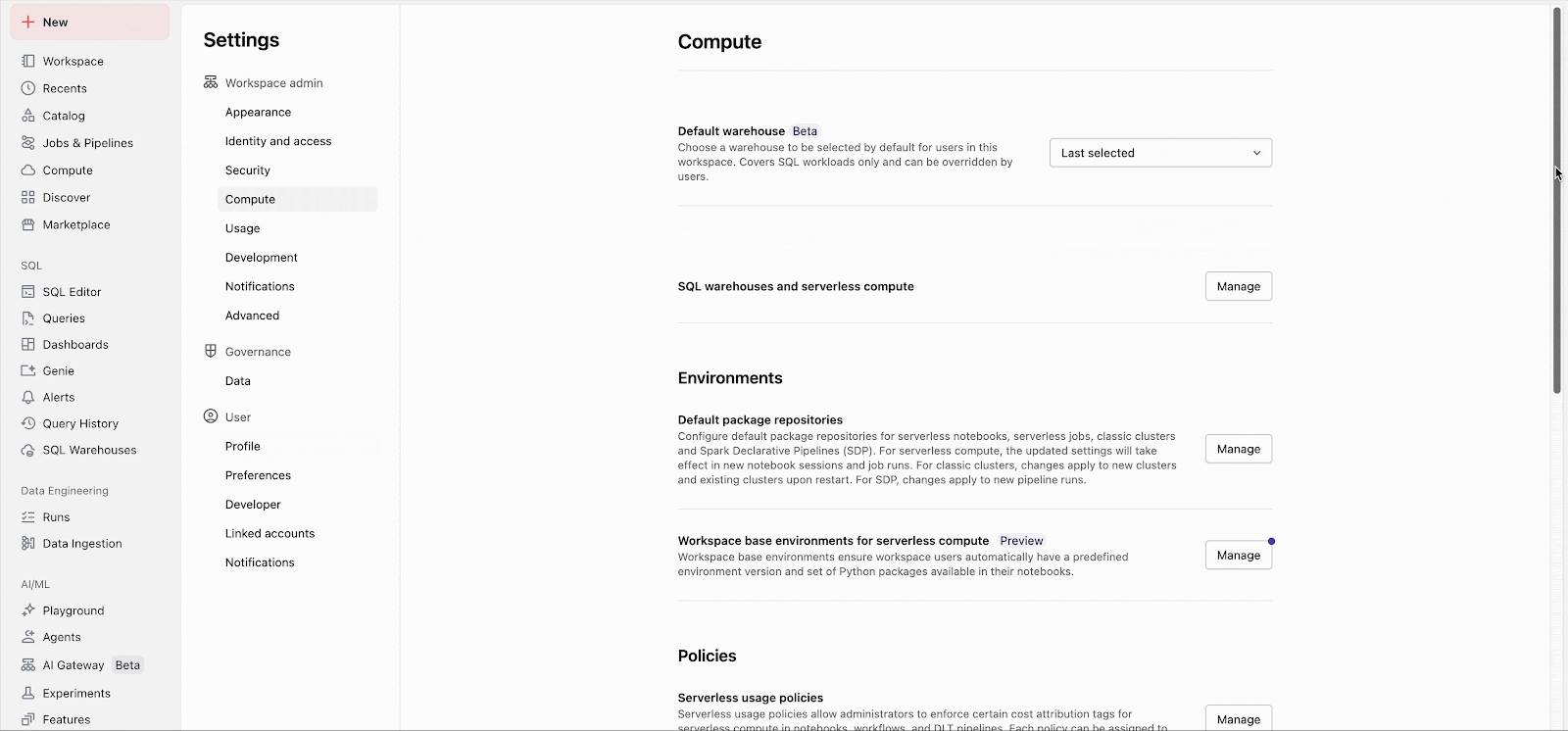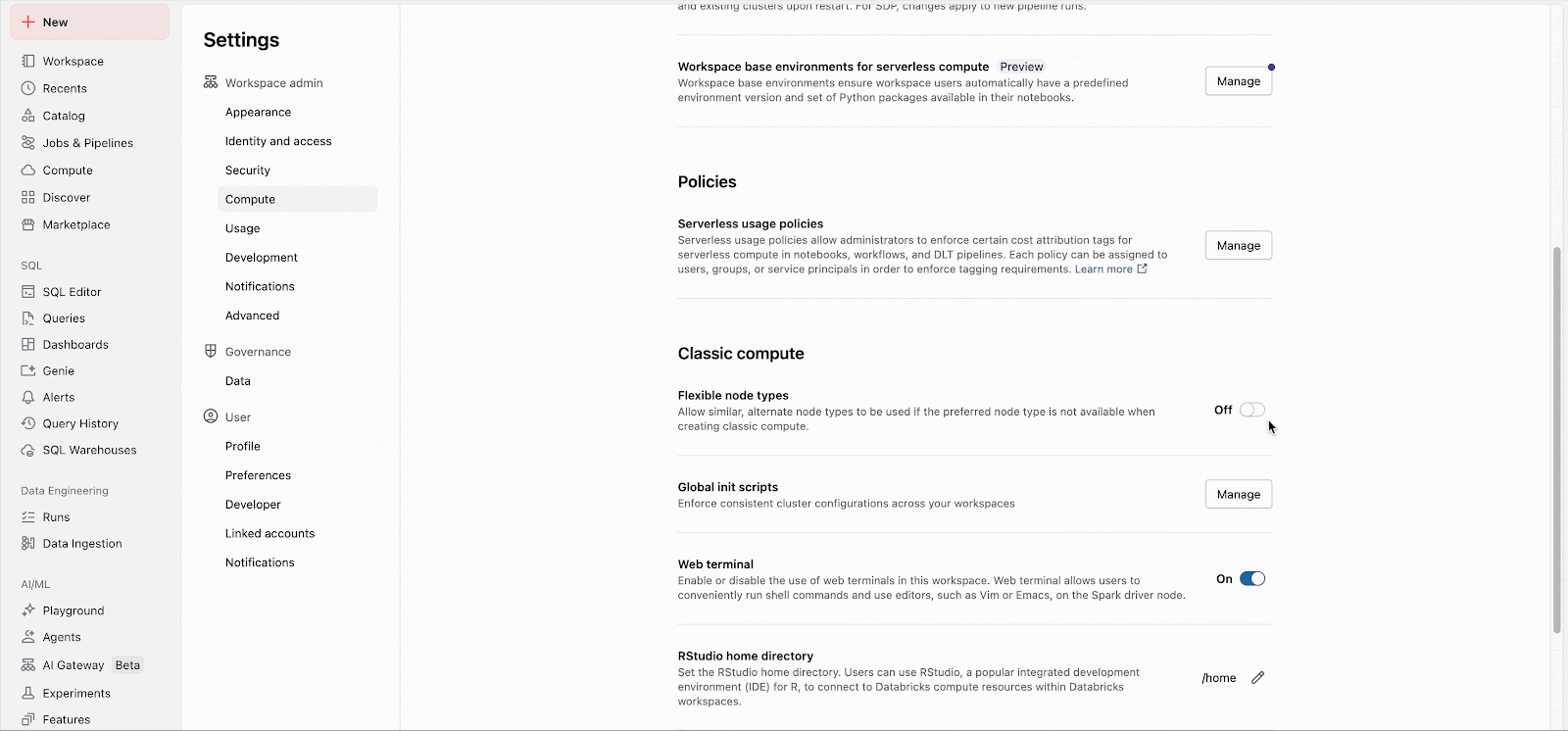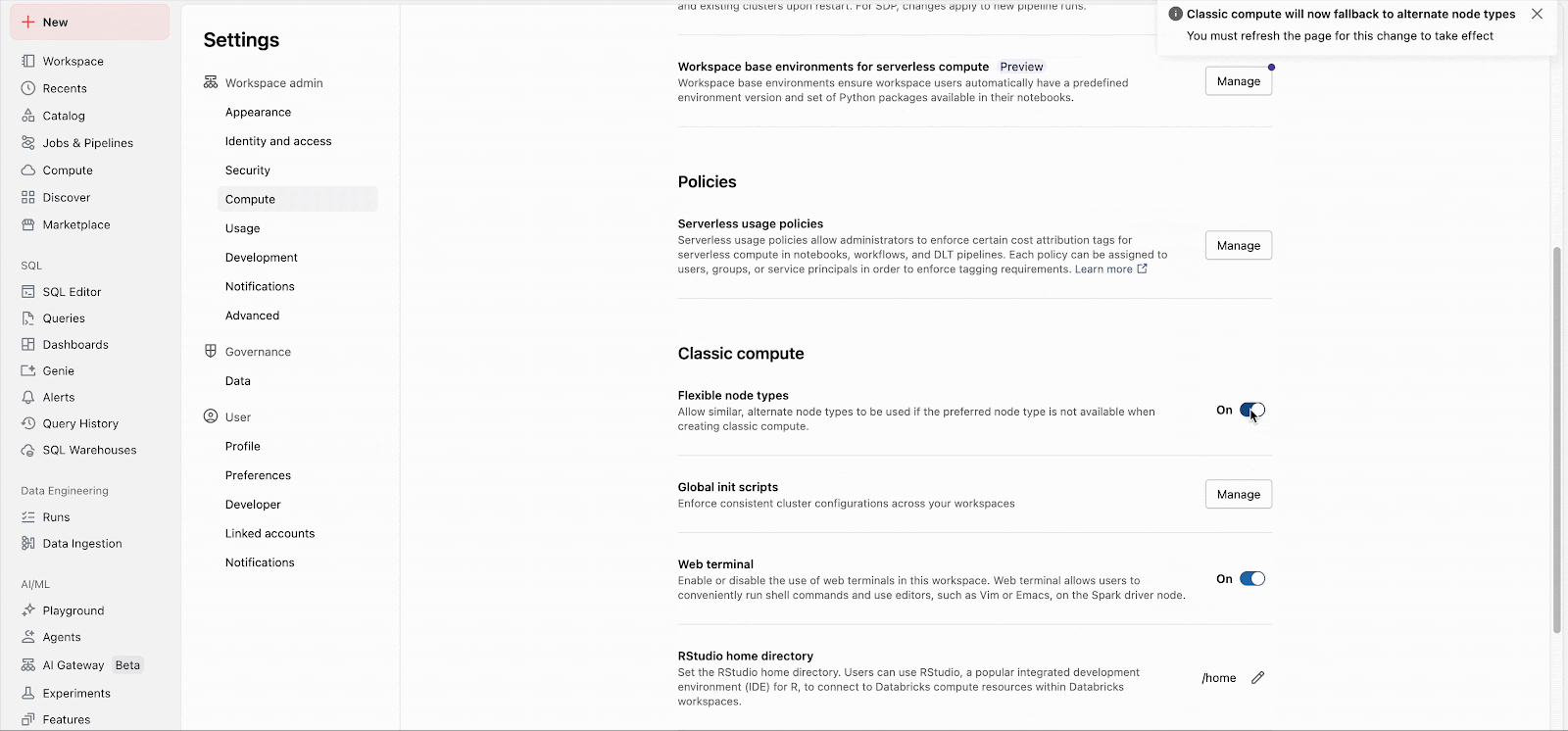
사용자 지정 fallback 목록은 워크스페이스 설정과 관계없이 API를 통해 구성할 수 있습니다.
추가 세부 정보
인스턴스 풀, 청구, 노드 유형 할당량 및 선택적 활성화/비활성화를 사용한 유연한 노드 유형 구성에 대한 자세한 내용은 설명서를 참조하세요(문서: AWS, Azure, GCP).
'유연한 노드 유형'은 데이터 플랫폼을 더욱 탄력적이고 비용 효율적으로 만들도록 설계되었습니다. 관리자는 설명서의 지침에 따라 워크스페이스 관리자 설정에서 클릭 한 번으로 이 기능을 활성화할 수 있습니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.