쿼리 태그를 통한 dbt 파이프라인의 세분화된 사용량 귀속
단 한 줄의 설정이나 Genie를 통해 비용 귀속 및 성능 디버깅부터 환경 모니터링까지, 모든 dbt 모델을 태그하고 추적하며 최적화해 보세요.
작성자: Heeren Sharma, Lennart Reschke , JooHo Yeo
- SQL 모델의 코드를 전혀 변경하지 않고 모든 dbt 쿼리에 팀, 비용 센터, 프로젝트, 환경 태그를 지정하세요.
- system.query.history를 쿼리하여 어떤 dbt 모델의 비용이 가장 많이 발생하고 컴퓨팅 시간이 어디에 소요되는지 정확히 확인하세요.
- 단일 GitHub 리포지토리에서 Declarative Automation Bundles를 사용하여 dbt 파이프라인, Query Tag 분석 대시보드, 예약된 작업 등 완전한 참조 프로젝트를 배포하세요.
여러분의 dbt 프로젝트는 매일 밤 80개의 모델을 실행합니다. 지난 분기 웨어하우스 비용이 두 배로 늘었습니다. 모델 성능은 천차만별이며, 가장 최근에 진행한 최적화의 효과도 불분명합니다. 재무팀에서 어느 팀의 책임인지 묻습니다. 쿼리 기록을 열어보니... 'Databricks Dbt'라고 표시된 동일한 행 80개가 보입니다. 행운을 빕니다.
현재 퍼블릭 프리뷰로 제공되는 Query Tags ()를 사용하면, 데이터 팀은 이제 모든 실행을 풍부하게 만들어 주는 dbt_model_name과 같이 기본으로 자동 삽입되는 태그의 이점을 누릴 수 있습니다. 또한 파이프라인이 생성하는 모든 쿼리에 팀, 비용 센터, 환경 등 원하는 맞춤형 태그를 직접 추가할 수도 있습니다.
태그는 system.query.history에 기록되므로 간단한 SQL 쿼리만으로 비용 귀속, 성능 디버깅, 워크로드 모니터링을 쉽게 수행할 수 있습니다(자세한 ��내용은 문서를 참조하세요).
이 블로그에서는 구성부터 비용 귀속 대시보드에 이르기까지 Query Tags를 엔드투엔드로 보여주는 완전한 오픈 소스 dbt 프로젝트를 살펴봅니다. 여기에 설명된 모든 내용은 복제하여 자체 워크스페이스에 배포할 수 있는 GitHub 리포지토리로 제공되거나, Genie에게 간단히 물어볼 수도 있습니다.
dbt-databricks와 Query Tags의 통합 방법
dbt-databricks 어댑터(버전 1.11 이상)는 Query Tags를 기본적으로 지원합니다. 태그를 적용할 수 있는 수준은 세 가지가 있으며, 각 수준은 이전 수준을 기반으로 합니다.
자동 삽입 태그
맞춤형 태그 외에도 dbt-databricks는 각 모델 실행에 대한 메타데이터를 자동으로 삽입합니다.
태그 | 예시 값 | 설명 |
@@dbt_model_name | fct_daily_usage_by_sku | 실행 중인 dbt 모델 |
@@dbt_materialized | table | 구체화 전략(table, view, incremental, metric_view) |
@@dbt_core_version | 1.11.6 | dbt-core 버전 |
@@dbt_databricks_version | 1.12.0a1 | dbt-databricks 어댑터 버전 |
이러한 자동 태그 덕분에 별도의 구성 없이도 모델별 가시성을 확보할 수 있습니다. 어댑터가 알아서 처리해 주기 때문입니다.
프로필 수준 태그
가장 간단한 방법은 dbt 프로필의 특정 대상에 query_tags 필드를 추가하는 것입니다. 프로젝트의 모든 쿼리가 이 태그를 자동으로 상속합니다.
예를 들어, 이 한 줄은 소유자(team), 비용 발생처(cost_center), 속한 파이프라인(project_name), 실행 환경(env)의 네 가지 차원으로 모든 쿼리에 태그를 지정합니다.
모델 수준 태그
더 세분화된 귀속을 위해 dbt_project.yml의 특정 모델이나 sql 정의의 모델 구성에 태그를 제공할 수 있습니다.
모델 수준 태그는 프로필 수준 태그와 병합됩니다. 양쪽 모두에 동일한 키가 정의되어 있으면 모델 수준 값이 우선합니다.
태그가 표시되는 위치 – system.query.history
dbt run을 실행한 후, 모든 SQL 문은 query_tags 열이 MAP으로 채워진 채 system.query.history에 나타납니다. 다음과 같이 표준 맵 액세스 구문을 사용하여 쿼리할 수 있습니다.
이렇게 하면 지난 7일 동안 태그가 지정된 모든 쿼리가 반환되며, 맞춤형 및 자동 삽입 태그가 개별 열로 추출되어 집계할 준비가 완료됩니다.
실행한 쿼리의 Query Tags는 Query History UI 또는 SQL Warehouse Monitoring UI에서도 확인할 수 있습니다.

Query Profile의 오른쪽 하단에서 정의한 Query Tags를 볼 수 있어 필요한 모든 정보를 한눈에 파악할 수 있습니다.

Query Tags를 사용한 비용 귀속
Query Tags를 사용하면 SQL 쿼리를 통해 직접 세부적인 사용량 귀속을 결정할 수 있으므로, 수동으로 로그를 분석하거나 웨어하우스 리소스를 분할할 필요가 없습니다.
어떤 dbt 모델이 웨어하우스 리소스를 가장 많이 사용하나요?
두 가지 방법으로 답을 얻을 수 있습니다. 애드혹 탐색을 위해 Genie에게 일상적인 언어로 물어보거나, 대시보드에 바로 사용할 수 있는 반복 가능한 결과를 위해 직접 SQL을 작성하는 것입니다. 두 방법 모두 동일한 system.query.history 데이터를 읽습니다.
옵션 1: Genie

Genie가 이에 해당하는 쿼리를 작성하고 실행하므로, SQL을 전혀 건드리지 않고도 후속 질문을 통해 계속해서 상세히 분석할 수 있습니다.
옵션 2: SQL
어떤 경로를 선택하든 동일한 결과를 얻을 수 있습니다. 참조 프로젝트에서는 4개의 마트 테이블(table로 구체화됨)이 컴퓨팅 시간의 대부분을 차지하는 반면, 스테이징 뷰와 메트릭 뷰는 거의 즉각적으로 처리됩니다. 이를 통해 최적화 작업에 집중해야 할 부분을 즉시 파악할 수 있습니다.

자체 모니터링 대시보드 구축
참조 프로젝트에는 프로젝트 자체의 쿼리 태그로 필터링된 system.query.history를 쿼리하는 AI/BI 대시보드가 포함되어 있습니다. 그 결과, 청구 데이터를 분석하는 파이프라인이 자체 비용도 추적하게 되며, Query Tags를 자체적으로 직접 테스트(dogfooding)하게 됩니다.
대시보드에는 다음이 포함됩니다:
- KPIs: 총 태그 지정된 쿼리 수, 총 컴퓨팅 시간(초), 고유 dbt 모델 수
- 일별 활동: 환경별로 구분된 일별 쿼리 수 및 컴퓨팅 시간
- 모델별 분석: 구체화 유형별로 색상이 지정된 모델당 컴퓨팅 시간
- 구체화 분포: table, view, metric_view 간에 컴퓨팅이 어떻게 분배되는지 보여주는 원형 차트
- 쿼리 세부 정보 테이블: 모델, 소요 시간, 환경, 실행기(executor)가 포함된 태그된 모든 쿼리
참조 프로젝트에서는 4개의 마트 모델이 컴퓨팅 시간의 92%를 차지했습니다. Query Tags가 없었다면 이러한 인사이트를 파악할 수 없었을 것입니다.
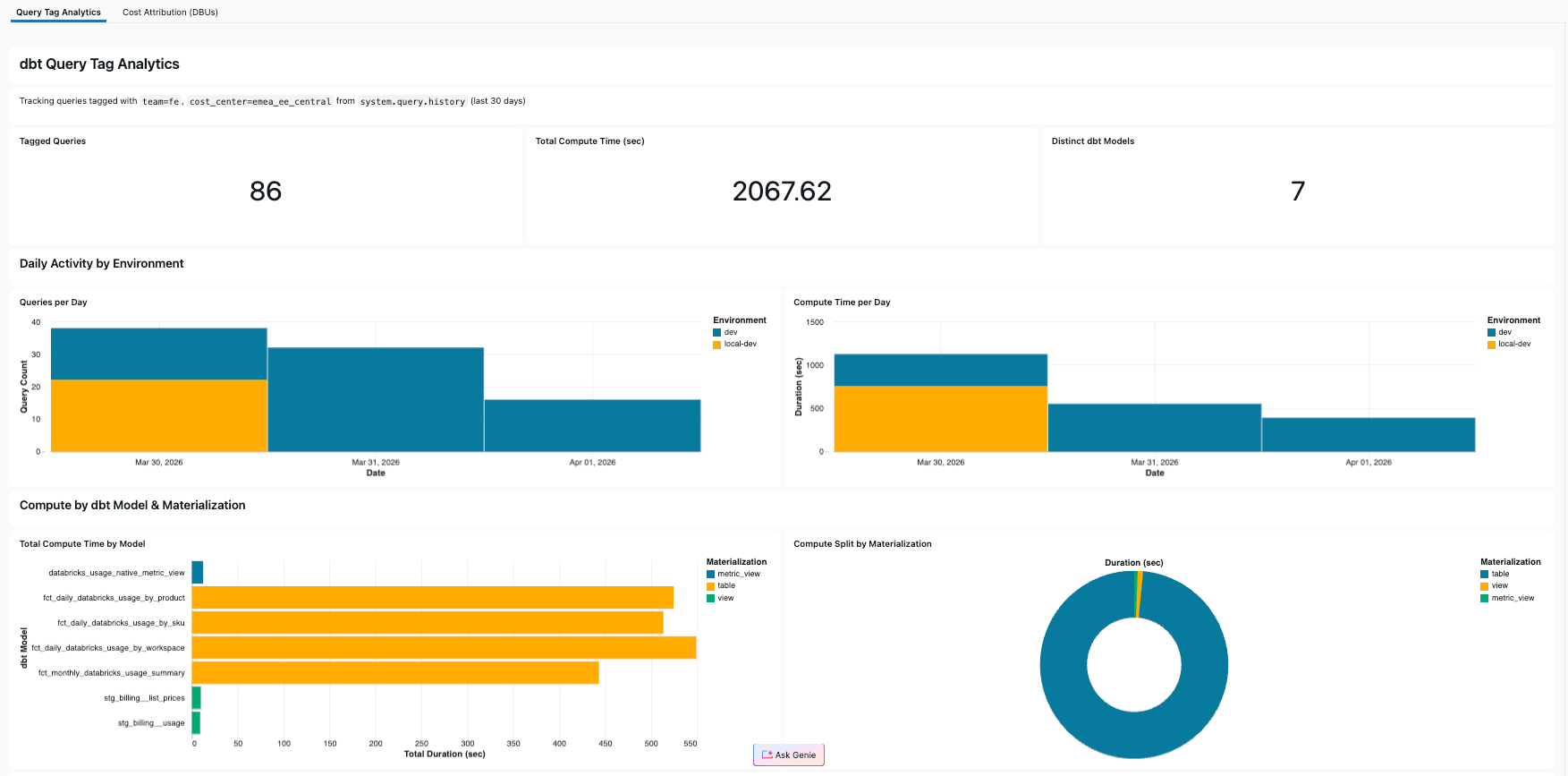
Genie Code를 사용하면 이 대시보드를 직접 구축하는 데 몇 분밖에 걸리지 않습니다. Genie Code에 쿼리 태그로 필터링된 system.query.history의 dbt 모델당 컴퓨팅 시간을 요청하면, SQL을 작성하고 시각화 자료를 구성해 줍니다. 완성된 결과로 바로 넘어가고 싶다면, 이 대시보드는 참조 프로젝트에도 포함되어 있으며 dbt 작업과 함께 단 한 번의 databricks bundle deploy 명령으로 배포할 수 있습니다(자세한 가이드는 GitHub 리포지토리를 참조하세요).
메트릭 뷰 태깅
Databricks 메트릭 뷰(dbt-databricks 1.12+에서 사용 가능)는 Unity Catalog에서 직접 차원 및 측정값 형태로 재사용 가능한 비즈니스 의미 체계를 정의하는 새로운 구체화 유형입니다(전체 문서 참조). query_tags 구성 매개변수를 사용하여 다른 모델과 마찬가지로 Query Tags를 가질 수 있습니다:
차이점에 유의하세요. query_tags는 메트릭 뷰를 생성하거나 새로 고치는 SQL 쿼리(system.query.history에서 추적됨)에 첨부되는 반면, databricks_tags는 Unity Catalog 태그로 객체 자체에 지정됩니다(거버넌스 및 검색용). 전자는 쿼리 수준의 추적을 위한 것이고, 후자는 전반적인 데이터 검색 가능성을 위한 Unity Catalog 객체 수준의 태그입니다.
dbt 프로젝트 태깅을 위한 모범 사례
이 문서에서는 비용 할당의 기초가 되는 Query Tags를 사용하여 탄탄한 FinOps 관행을 구축하기 위한 전체적인 프로세스를 다루었습니다. 참조 프로젝트를 구축하고 dbt 파워 유저들과 대화하면서 배운 점은 다음과 같습니다:
- 일관된 태그 계층 구조를 사용하세요. 프로필 수준(team, cost_center, project_name, env)에서 조직 전체 태그를 정의하고, 모델 수준 태그는 예외적인 경우를 위해 예약해 두세요. 이렇게 하면 태그를 예측 가능하게 유지하고 모델별 구성이 무분별하게 늘어나는 것을 방지할 수 있습니다.
- 항상 환경을 태깅하세요. 로컬 개발(local-dev)과 배포된 작업(dev, staging, prod)에 서로 다른 env 값을 ��사용하세요. 이를 통해 분석 시 임시 개발 쿼리와 예약된 프로덕션 실행을 분리할 수 있습니다. 참조 프로젝트에서 로컬 프로필은 "env": "local-dev"로 설정하고, 배포된 프로필은 "env": "dev"로 설정합니다.
- `project_name`을 사용하여 파이프라인을 구분하세요. 여러 dbt 프로젝트가 웨어하우스를 공유할 때, project_name을 사용하면 웨어하우스를 분할하지 않고도 파이프라인별로 비용을 할당할 수 있습니다. 자동으로 삽입되는 @@dbt_model_name과 결합하면 프로젝트 → 모델 → 구체화로 이어지는 완전한 추적성을 확보할 수 있습니다.
- 과도하게 태깅하지 마세요. 자동으로 삽입되는 태그에는 이미 모델 이름, 구체화 유형, 어댑터 버전이 포함되어 있습니다. 사용자 지정 태그에서 이 정보를 중복으로 지정할 필요는 거의 없습니다. 사용자 지정 태그는 dbt가 유추할 수 없는 비즈니스 컨텍스트(팀 소유권, 비용 센터, 프로젝트 식별 등)에 집중하세요.
- 메트릭 뷰를 명시적으로 태깅하세요. 메트릭 뷰는 비교적 새로운 구체화 유형이므로, 비용 분석 시 메트릭 뷰 생성 쿼리를 쉽게 필터링할 수 있도록 기능 키(예: "feature": "metric_view")를 태깅하는 것이 유용합니다.
직접 시도해 보세요
전체 참조 프로젝트는 GitHub에서 확인할 수 있습니다: github.com/databricks-solutions/dbt-query-tags
시작 방법:
- 리포지토리 복제
- Python 3.12 가상 환경을 생성하고 종속성을 설치합니다: pip install dbt-databricks>=1.12.0a1
- 워크스페이스 호스트, SQL 웨어하우스 HTTP 경로, 카탈로그 및 사용자 지정 쿼리 태그로 profiles.yml을 업데이트합니다.
- 파이프라인을 실행하려면 dbt deps && dbt run --profiles-dir .을 실행합니다.
- 태그가 작동하는지 확인하려면 system.query.history를 쿼리합니다.
- 올바른 구성을 가리키도록 dbt_profiles/profiles.yml 및 databricks.yml을 업데이트합니다.
- 예약된 실행 및 분석 대시보드를 위해 databricks bundle deploy로 배포합니다.
자신의 팀 및 비용 센터 값으로 바꾸어 사용하세요. 이 패턴은 Databricks의 모든 dbt 프로젝트에 적용됩니다.
지금 리포지토리를 복제해 보세요! 프로필에 단 한 줄만 추가하면 전체 웨어하우스에서 모델 수준의 사용량 할당 가시성을 확보할 수 있습니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.