Superhuman과 Databricks가 함께 200K QPS 추론 플랫폼을 구축한 방법
Superhuman과 Databricks 엔지니어들이 맞춤법 및 문법 교정 워크로드를 Databricks Model Serving Platform으로 공동 마이그레이션하여 20만 QPS 이상을 제공하고 60% 처리량 향상 및 1초 미만의 P99 지연 시간을 달성한 방법을 공유합니다.
작성자: Christoph Stüber, Wai Wu, 아르준 디쿠냐, Amine El Helou, Tian Ouyang , Alex Coleman
- Superhuman은 자체 구축한 vLLM 스택에서 Databricks FMAPI Provisioned Throughput으로 마이그레이션하여, 현재 20만 QPS 이상으로 맞춤형 LLM을 1초 미만의 P99 지연 시간으로 제공하고 있습니다. 이를 통해 Superhuman 엔지니어링 팀은 제품 구축 및 개선에 집중할 수 있었고, 확장성 및 인프라 처리는 Databricks Platform에 위임했습니다.
- 공동 엔지니어링 최적화를 통해 GPU당 60%의 처리량 향상(H100 pod당 750 → 1,200 QPS)을 달성했으며, FP8 양자화를 통한 서비스 비용 절감, CPU 측 오버헤드 제거, Hopper 아키텍처에서 어텐션 커널 최적화를 통해 품질 저하 없이 이 모든 것을 이루었습니다.
- Databricks FMAPI는 프로덕션급 로드 밸런싱, 자동 스케일링 및 빠른 컨테이너 시작을 통해 250개 이상의 GPU로 안정적으로 확장됩니다. 사전 프로덕션 램프 스트레스 테스트를 통해 트래픽이 프로덕션에 도달하기 전에 p99 가용성 및 지연 시간 목표가 충족되도록 보장합니다.
분석 파트너에서 실시간 추론 파트너로
Superhuman, Coda, Superhuman Mail, Superhuman Go를 포함하는 생산성 플랫폼인 Superhuman은 수십 개 언어로 매일 4천만 명 이상의 사용자에게 서비스를 제공합니다. Superhuman의 AI 커뮤니케이션 지원은 사람들이 글을 쓰는 모든 곳에서 정확성, 명확성, 어조 및 스타일에 대한 실시간 제안을 제공합니다.
Databricks와 Superhuman은 수년간 파트너 관계를 유지해 왔습니다. Superhuman 팀은 역사적으로 Databricks Data Intelligence Platform을 분석의 기반으로 사용했습니다. 하지만 분석은 전체 그림의 절반에 불과했습니다.
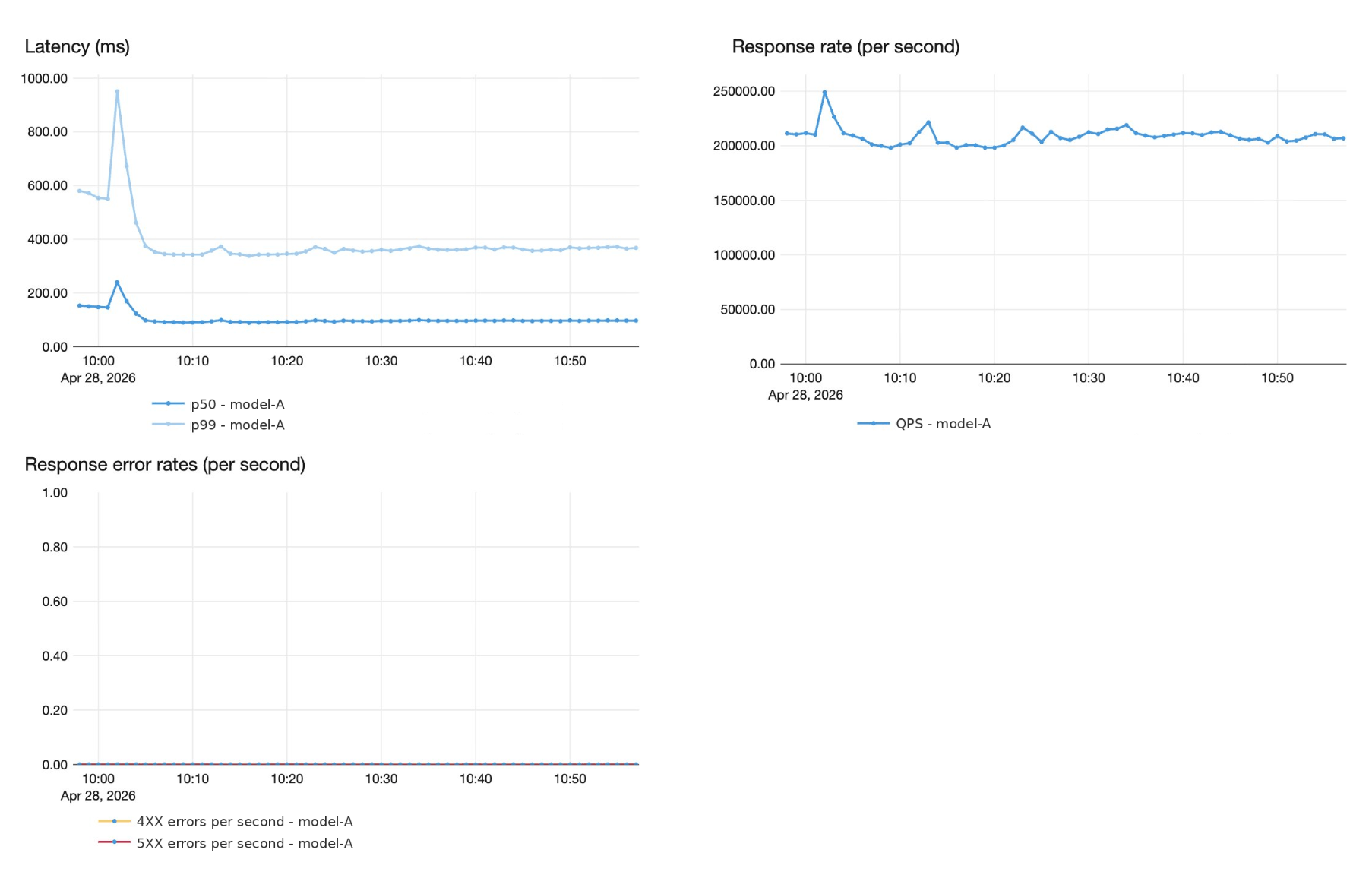
Superhuman의 많은 실시간 제안 뒤에는 대규모로 서비스되는 고도로 정교한 맞춤형 AI 모델이 있습니다. Superhuman은 이 모델을 초당 20만 건 이상의 피크 트래픽으로 실행하며, P99에서 1초 미만의 종단 간 지연 시간과 엄격한 4 9의 안정성 보장을 제공합니다. Superhuman은 Databricks 모델 서빙을 활용하여 대규모 언어 모델을 위한 서빙 스택을 현대화했으며, 이는 공동 제품 및 엔지니어링 작업을 기반으로 하는 새로운 종류의 파트너십을 필요로 했습니다.
Superhuman이 서빙 스택을 현대화한 방법
이 마이그레이션 이전에 Superhuman은 vLLM을 기반으로 구축된 DIY 서빙 스택을 내부 훈련 및 모델 관리 도구와 함께 운영했습니다. 내부 ML 인프라 팀이 이 스택을 유지 관리했으며, 이는 대규모 확장을 지원했지만, 대규모 언어 모델을 서빙할 때 여러 문제점이 복합적으로 발생했습니다.
맞춤형 대규모 언어 모델은 요청당 약 50개의 입력 토큰과 50개의 출력 토큰으로 20만 QPS 이상의 피크를 기록하며 엄청난 볼륨으로 문법 오류 교정을 지원합니다. 이는 L40S-gpus 기반 스택이 제공할 수 있는 한계를 뛰어넘는 것이었습니다. 모델의 각 새로운 반복은 온보딩을 위해 수개월의 수동 성능 튜닝을 필요로 했습니다. 한편, 용량 계획, 성능 튜닝, 자동 스케일링으로 인해 모델 품질 및 제품 혁신에 집중해야 하는 소규모 팀의 시간이 소모되면서 운영 부담이 가중되고 있었습니다.
Superhuman은 서빙 스택의 성능 및 지연 시간 SLA를 약속하고, 이를 충족하는 데 필요한 엔지니어링에 공동 투자할 수 있는 플랫폼 파트너가 필요했습니다. 양 팀은 사전에 목표 실시간 지연 시간 SLO를 정의했습니다: 1초 미만의 P99 지연 시간과 Superhuman의 내부 평가 하네스에서 품질 저하 없음.
플랫폼 인프라에서 실시간 SLA 충족
단일 파드에서 지연 시간 목표를 달성하는 것은 필요하지만 충분하지 않습니다. 20만 QPS 이상을 안정적으로 서빙하려면 로드를 균형 있게 분산하고, 동적으로 확장하며, 급증하는 트래픽을 흡수할 수 있는 인프라가 필요합니다. 이를 제대로 구현하려면 양 팀 간의 긴밀한 협력이 필요했습니다.
로드 밸런싱 최적화: 2의 선택(power-of-two choices)
Superhuman의 문법 교정 엔드포인트 트래픽은 특정 기간에 급격히 증가하는 강력한 일일 패턴을 보이며, 종종 20만 QPS를 초과합니다. 기본 Kubernetes 라운드 로빈 로드 밸런서는 낮은 QPS에서는 충분하지만, 테스트 결과 높은 QPS에서는 성능이 저하되고, 고르지 못한 요청 분산으로 인해 꼬리 지연 시간을 급증시키는 핫스팟이 생성되는 것으로 나타났습니다.
저희 접근 방식의 핵심은 Endpoint Discovery Service(EDS)입니다. EDS는 서비스 및 EndpointSlices 변경 사항을 지속적으로 모니터링하는 경량 제어 플레인입니다. EDS는 2의 선택(power of two choices)(인용)을 기반으로 하는 맞춤형 로드 밸런싱 알고리즘을 구동합니다. 각 요청에 대해 두 개의 후보 파드를 샘플링하고, 활성 요청이 더 적은 파드로 트래픽을 라우팅하여 높은 QPS에서 라운드 로빈이 생성하는 핫스팟을 방지합니다(블로그 참조).
가변적인 트래픽 패턴에 대해 플랫폼 비용을 최적화하기 위해 시스템은 고객 수요에 따라 동적으로 자동 스케일링됩니다. 자동 스케일러는 파드 전체에서 평균 request_concurrency를 추적하며, 복제본당 최대 지속 가능한 RPS 벤치마킹에서 파드당 동시성 목표를 도출합니다. 스케일링 전략은 의도적으로 비대칭적입니다. 스케일업은 공격적이고 반응적이며, 스케일다운은 지연 시간 급증을 유발하는 플래핑을 방지하기 위해 보수적입니다. Superhuman과 Databricks 간의 공동 섀도우 테스트를 통해, 공격적으로 스케일링할 시점, 안정적으로 유지할 시점, 스케일다운 시 얼마나 보수적이어야 하는지 등 자동 스케일러의 매개변수를 튜닝할 때 엣지 케이스를 발견하고 문제를 해결했습니다.
이미지 가속을 통한 컨테이너 시작 최적화
Superhuman 엔드포인트 트래픽이 비피크 시간에서 피크 시간으로 증가할 때, 자동 스케일러는 수십 개의 파드를 추가해야 합니다. 각 파드가 컨테이너 이미지를 가져오고 시작하는 데 몇 분 이상 걸리면, 사용자는 트래픽 증가 중에 지연 시간 급증을 경험합니다. 파드 시작 시간을 단축하는 것은 트래픽 급증 시 더 빠른 스케일업과 더 부드러��운 지연 시간으로 직접 연결됩니다.
Databricks 모델 서빙 팀은 콜드 스타트를 방지하기 위해 서버리스 컴퓨팅을 위해 원래 구축된 이미지 가속 작업을 채택했습니다(블로그). 이 접근 방식은 Superhuman을 위해 서비스한 비교적 작은 모델에 잘 맞습니다.
컨테이너 이미지를 구축할 때, 표준 gzip 기반 이미지 형식을 지연 로딩에 적합한 블록 장치 기반 형식으로 변환하는 추가 단계를 추가합니다. 이를 통해 컨테이너 이미지는 프로덕션에서 4MB 섹터를 가진 탐색 가능한 블록 장치로 표현될 수 있습니다.
컨테이너 이미지를 가져올 때, 저희의 맞춤형 컨테이너 런타임은 디렉터리 구조, 파일 이름, 권한을 포함하여 컨테이너의 루트 디렉터리를 설정하는 데 필요한 메타데이터만 검색하고, 이에 따라 가상 블록 장치를 생성합니다. 그런 다음 가상 블록 장치를 컨테이너에 마운트하여 애플리케이션이 즉시 실행될 수 있도록 합니다.
애플리케이션이 파일을 처음 읽을 때, 가상 블록 장치에 대한 I/O 요청은 이미지 페처 프로세스에 콜백을 발행하고, 이 프로세스는 원격 컨테이너 레지스트리에서 실제 블록 콘텐츠를 검색합니다. 검색된 블록 콘텐츠는 컨테이너 레지스트리로의 반복적인 네트워크 왕복을 방지하기 위해 로컬에 캐시되어, 향후 읽기 시 가변적인 네트워크 지연 시간의 영향을 줄입니다.
이 지연 로딩 컨테이너 파일 시스템은 애플리케이션을 시작하기 전에 전체 컨테이너 이미지를 다운로드할 필요를 없애, 컨테이너 시작 시간을 몇 분에서 단 몇 초로 단축합니다.
런타임 최적화: 파드당 처리량 60% 증가
플랫��폼 계층이 플릿 수준의 확장을 처리함에 따라, 다음 질문은 각 파드가 얼마나 많은 QPS를 지원할 수 있으며 그 비용은 얼마인가였습니다.
이 섹션에서는 품질 저하 없이 H100 GPU에서 파드당 처리량을 750 QPS에서 1,200 QPS로 60% 향상시킨 최적화에 대해 설명합니다.
FP8 양자화
FP8 양자화는 파드당 QPS를 최대 30% 증가시켜 가장 큰 처리량 개선을 이루었습니다.
Superhuman의 ML 팀은 vLLM의 온라인 양자화 라이브러리를 사용하여 체크포인트를 FP8로 사전 양자화하여, Databricks가 서빙을 위해 로드하는 압축 텐서 형식 체크포인트를 생성했습니다. 최종 구성에서 어텐션 프로젝션(Q, K, V 및 출력)과 MLP 프로젝션은 모두 FP8 경로를 통해 실행되었으며, KV-캐시 양자화는 비활성화되었습니다. 이는 처리량 이득이 가중치 양자화에서 비롯되었고, KV-캐시 양자화는 이 워크로드에 대해 추구할 가치가 없는 자체적인 품질 절충을 가져왔기 때문입니다.
최종 구성을 결정하기 전에 양 팀은 어떤 계층을 양자화할지 반복적으로 논의했습니다. Databricks 모델 서빙은 처음부터 하이브리드 정밀도 추론을 지원하도록 서빙 엔진을 설계했으므로, 어떤 계층 그룹이 양자화 시 품질에 너무 민감한 것으로 판명되면 전체 서빙 아키텍처를 변경하지 않고 더 높은 정밀도를 유지할 수 있었습니다. 우리는 어텐션 양자화를 켜고 끌 수 있는 플래그를 제공하여 양 팀이 그 영향을 직접 측정할 수 있도록 했습니다. 실험은 깔끔하게 진행되었으며, Q/K/V 및 출력 프로젝션을 양자화해도 Superhuman의 평가에서 측정 가능한 품질 저하는 발생하지 않았습니다.
다른 고려 사항은 양자화 세분성이었습니다. 상용 커널은 텐서당 스케일링(전체 가중치 텐서에 대한 단일 FP8 스케일 팩터)을 사용했습니다. Databricks의 커널은 채널당 스케일링을 사용하여 각 선형 계층의 출력 채널당 별도의 스케일 팩터를 계산합니다. 이는 중요한 동적 범위를 보존하고, MLP 계층 양자화 오류를 평가에 나타나는 임계값보다 훨씬 낮게 유지합니다. 커널 수준 개선과 결합하여, 채널당 양자화는 동일한 처리량에서 다른 오픈 소스 기준선과 일치하거나 이를 능가했습니다.
CPU 측 병목 현상 제거
작고 빠른 모델의 경우 성능은 종종 GPU가 아닌 CPU에 의해 병목 현상이 발생합니다. Databricks 팀은 이미 빠른 PEFT 서빙 작업에서 CPU 병목 현상 제거를 조사했으며, 여기서는 유사한 CPU 최적화를 Superhuman의 워크로드에 직접 적용했습니다.
구체적으로 팀은 다중 처리 런타임 서버를 도입했습니다. 대부분의 모델 서빙 워크로드에서 GPU가 병목 현상이지 CPU가 아니므로 단일 프로세스는 GPU를 포화 상태로 유지하기에 충분히 빠릅니다. 그러나 작고 빠른 모델의 경우 GPU는 단일 프로세스가 다음 배치를 준비하는 것보다 더 빠르게 순방향 패스를 완료하여 병목 현상을 CPU로 전환합니다.
팀은 여러 RPC 서버 프로세스를 실행하여 이 문제를 해결했습니다. 여러 CPU 프로세스가 GPU에 작업을 병렬로 준비하고 전달함으로써, 단일 프로세스 직렬화 병목 현상을 제거했습니다. 이를 통해 처리량이 20% 추가로 향상되었습니다.
다른 CPU 측 최적화는 성능을 몇 퍼센트 포인트 향상시켰습니다.
- Python 오버헤드 감소. 각 CUDA 그래프 디코딩 단계 시작 시 Python 수준의 텐서 슬라이싱, 복사 및 채우기를 단일 C++ 호�출로 대체했습니다. 병렬 전략(ThreadPool, OpenMP)도 탐색했지만, CUDA 동기화 오버헤드로 인해 단일 스레드 C++가 최적이었습니다. 이는 각 순방향 패스당 GPU 유휴 시간을 약간 줄였습니다.
- CPU-GPU 작업 오버랩 개선을 위한 비동기 스케줄링. CPU 측 후처리 작업을 중요 경로에서 벗어나 다음 GPU 순방향 패스와 동시에 실행되도록 했습니다. 배치 N에 대한 모든 후처리를 완료한 후 배치 N+1을 시작하는 대신, 스케줄러는 N+1을 즉시 디스패치하고 N의 후처리를 병렬로 처리합니다. 후처리 또한 전체 배치가 아닌 관련 요청의 하위 집합에 대해서만 반복됩니다. 그 결과 다음 순방향 패스가 더 빨리 시작되었습니다.
다음 단계
이 작업은 더 광범위한 파트너십의 기반이 됩니다. Superhuman은 이제 다양한 모델 크기, 작업 유형 및 지연 시간 요구 사항을 포괄하는 추가 모델을 Databricks로 마이그레이션하고 있으며, 훈련 워크플로, 실험 추적, 평가(고전 ML, 딥러닝 및 생성형 AI/에이전트), 모델 및 (LLM) 심사위원 레지스트리, 대규모 에이전트 추적 수집을 위해 AI 플랫폼을 더 광범위하게 채택하고 있습니다.
이 대규모 플랫폼을 구축하는 것은 양측의 전사적인 노력과 특별한 학습 경험이었습니다. Superhuman ML 및 인프라 팀의 깊은 협력, 어려운 절충안에 대한 공개적인 반복 의지, 그리고 모든 품질 기준 및 부하 테스트에 대한 엄격함에 깊이 감사드립니다. 우리가 함께 구축한 엔지니어링 플레이북은 우리만큼 그들의 것이며, 앞으로 이어질 모든 워크로드에 동일한 수준의 파트너십을 제공하게 되어 기쁩니다.
주요 내용
관리형 추론 서비스를 사용한다고 해서 제어권을 포기해야 ��하는 것은 아닙니다. Superhuman은 모델 훈련, 양자화 및 품질 표준에 대한 완전한 소유권을 유지하며, Databricks는 런타임 성능 및 플랫폼 안정성을 유지합니다. 이러한 책임 분담은 Databricks 플랫폼 온보딩 시 공유 SLO, 공동 품질 검증 및 점진적 부하 테스트와 잘 작동합니다.
맞춤형 모델을 대규모로 서비스할 준비가 되셨습니까? Databricks Foundation Model API가 가장 까다로운 추론 SLA를 어떻게 충족하고, 단순한 관리형 서비스가 아닌 진정한 엔지니어링 파트너를 팀에 제공할 수 있는지 알아보십시오. 높은 QPS 모델 서빙 사용 사례를 온보딩하려면 https://www.databricks.com/company/contact로 문의하십시오.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.