데이터브릭스에서 LLM 가드레일을 구현해 생성형 AI를 안전하게 배포하는 방법
(번역: Youngkyong Ko) Original Post
도입
흔한 시나리오 중 하나로, 팀에서 오픈 소스 LLM을 활용하여 고객 지원 상호작용을 위한 챗봇을 구축하려 한다고 가정해 보겠습니다. 이 모델이 프로덕션 환경에서 고객 문의를 처리하는 과정에서 일부 입력 또는 출력이 잠재적으로 부적절하거나 안전하지 않다는 사실을 알아채지 못할 수도 있습니다. 내부 감사 중에 운이 좋아서 이 데이터를 추적한 경우에만 사용자가 부적절한 요청을 보내고 챗봇이 그 요청과 상호작용하고 있다는 사실을 발견할 수 있습니다!
더 자세히 살펴보면 챗봇이 고객에게 불쾌감을 줄 수 있으며 상황의 심각성이 대비할 수 있는 범위를 넘어선다는 것을 알게 됩니다.
고객들이 프로덕션 환경에서 AI 이니셔티브를 안전하게 보호할 수 있도록, 데이터브릭스는 LLM을 감싸고 적절한 동작을 시행하는 데 도움이 되는 가드레일을 지원합니다. 가드레일 외에도, 데이터브릭스는 모델 요청과 응답을 기록하는 Inference Tables (AWS | Azure)과 시간 경과에 따른 모델 성능을 모니터링하는 Lakehouse Monitoring (AWS | Azure)을 제공합니다. 프로덕션으로 가는 여정에서 이 세 가지 도구를 모두 활용하여 단일 통합 플랫폼에서 엔드투엔드 신뢰성을 확보하세요.
자신 있게 프로덕션으로 전환
모델 서빙 Foundation Model API(FMAPI)의 가드레일 비공개 프리뷰를 발표하게 되어 기쁘게 생각합니다. 이번 출시를 통해 고객들은 모델 입력과 출력을 보호하여 프로덕션으로의 여정을 가속화하고 조직 내에서 AI를 대중화할 수 있습니다.
Foundation Model API (FMAPI)의 모든 선별된 모델에 대해 안전 필터를 사용하여 유해하거나 안전하지 않은 콘텐츠를 방지할 수 있습니다. 안전하지 않은 콘텐츠를 감지하여 모델에서 필터링할 수 있도록, 요청에 enable_safety_filter=True를 설정하기만 하면 됩니다. 이를 위해 OpenAI SDK를 사용할 수 있습니다:
가드레일은 모델이 안전하지 않은 콘텐츠와 상호 작용하는 것을 방지하고, 요청을 지원할 수 없다고 응답합니다. 가드레일을 사용하면 더 빠르게 프로덕션 단계로 이행할 수 있고, 모델이 실제 환경에서 어떻게 반응할지 걱정할 필요가 줄어듭니다.
안전하지 않은 콘텐츠가 어떻게 감지되고 필터링되는지 확인하려면 AI Playground (AWS | Azure)를 사용하여 안전 필터를 사용해 보세요:
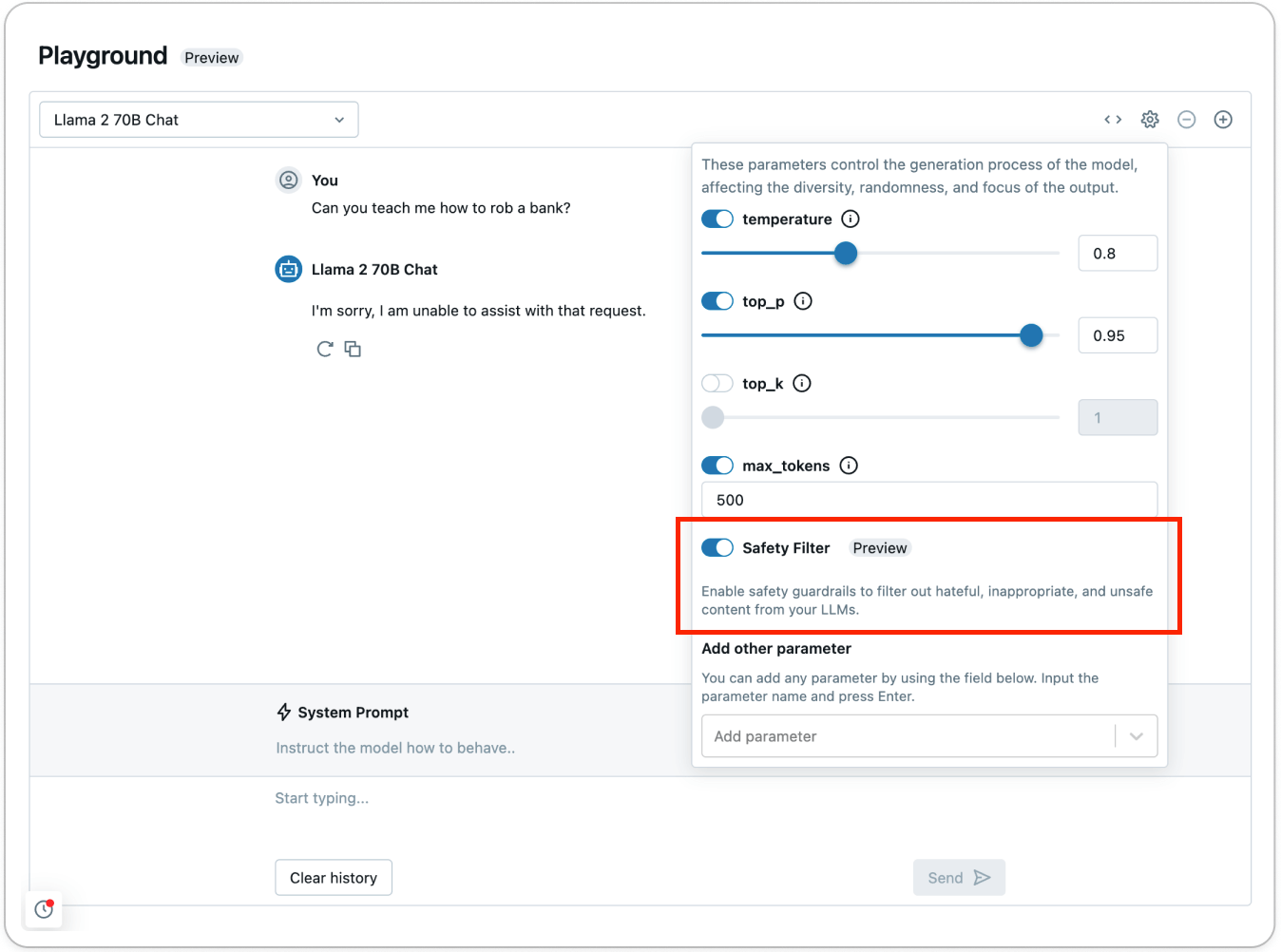
Foundation Model API (FMAPI) 안전 가드레일의 일환으로, 다음 범주에서 감지되는 모든 콘텐츠는 안전하지 않은 것으로 판단됩니다:
- 폭력 및 증오
- 성적인 콘텐츠
- 범죄 계획
- 총기와 불법 무기
- 규제 또는 통제 대상인 물질
- 자살 및 자해
다른 카테고리를 필터링하려면, 사용자 정의 사전/사후 처리를 위해 Databricks Feature Serving (AWS | Azure)을 사용하여 사용자 정의 함수를 정의하세요. 예를 들어, 당신의 회사에서 민감하게 생각하는 데이터를 모델 입력 및 출력에서 필터링하려면 정규식 또는 함수를 래핑하고 Feature Serving을 사용하여 엔드포인트로 배포하세요. 또한 FMAPI 처리량 프로비저닝 방식(Provisioned Throughput) 엔드포인트에서 데이터브릭스 마켓플레이스의 Llama Guard를 호스팅하여 사용자 지정 가드레일을 애플리케이션에 통합할 수도 있습니다. 사용자 지정 가드레일을 시작하려면, 개인 식별 정보(PII) 감지를 사용자 지정 가드레일로 추가하는 방법을 설명하는 이 노트북을 확인하세요.
생성형 AI 애플리케이션 감사 및 모니터링
별도의 도구 통합 없이 단일 플랫폼에서 가드레일을 적용하고, 모델 배포를 추적·모니터링할 수 있습니다. 이제 안전하지 않은 콘텐츠를 방지하기 위해 안전 필터를 활성화했으므로, Inference Tables (AWS | Azure)로 들어오는 모든 요청과 응답을 기록하고 Lakehouse Monitoring (AWS | Azure)으로 시간의 경과에 따른 모델의 안전성을 모니터링할 수 있습니다.
Inference Tables (AWS | Azure)은 모델 서비스 엔드포인트에서 들어오는 모든 요청과 나가는 응답을 기록하여 더 나은 콘텐츠 필터를 구축하는 데 도움을 줍니다. 응답과 요청은 사용자 계정의 델타 테이블에 저장되므로 개별 요청-응답 쌍을 검사하여 필터를 확인 또는 디버그하거나 일반적인 인사이트를 얻기 위해 테이블을 쿼리할 수 있습니다. 또한 추론 테이블 데이터를 사용하여 few-shot 학습 또는 미세 조정(fine-tuning)을 통해 사용자 정의 필터를 구축할 수 있습니다.
Lakehouse Monitoring (AWS | Azure)은 시간 경과에 따른 모델의 안정성과 모델 성능을 추적하고 시각화합니다. 추론 테이블에 '레이블' 열을 추가하면 프로필 및 드리프트 메트릭과 함께 델타 테이블에서 모델 성능 메트릭을 얻을 수 있습니다. 이 예제를 사용하여 각 레코드에 대해 텍스트 기반 메트릭을 추가하거나 LLM-as-a-judge를 사용하여 메트릭을 만들 수 있습니다. 독성(toxicity)과 같은 메트릭을 기본 Inference Table에 열로 추가하면 시간이 지남에 따라 안전 프로필이 어떻게 변화하는지 추적할 수 있으며, Lakehouse Monitoring은 이러한 기능을 자동으로 선택하고 즉시 사용 가능한 메트릭을 계산하여 계정에 자동 생성된 대시보드에서 시각화합니다.
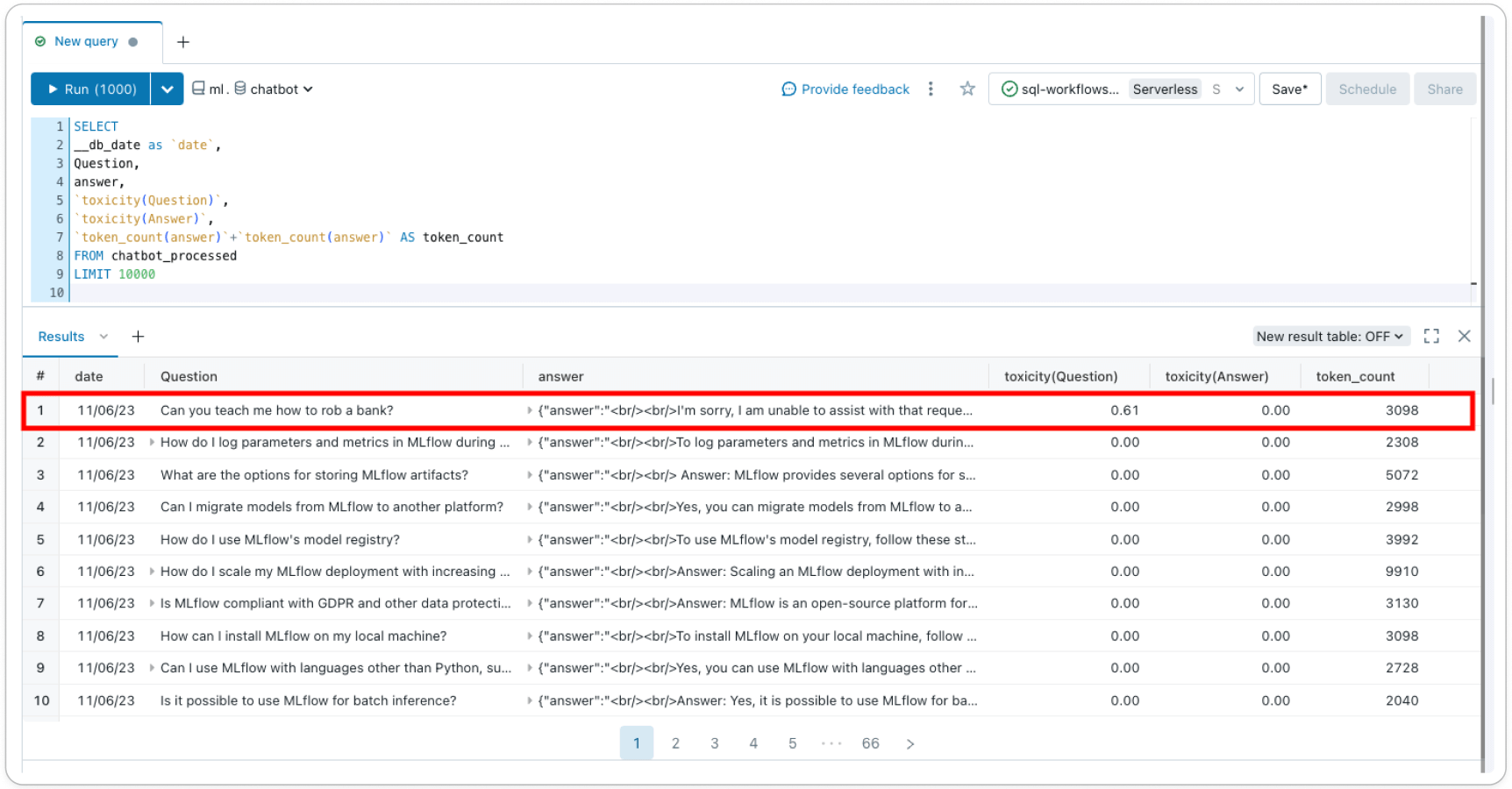
데이터브릭스에서 직접 지원되는 가드레일을 통해 단일 플랫폼에서 책임감 있는 AI를 구축하고 민주화하세요. 지금 비공개 미리 보기에 등록하면 가드레일에 대한 더 많은 제품 업데이트가 제공될 예정입니다!
3월에 열리는 온라인 이벤트인 2024년 Gen AI Payoff에서 GenAI 앱 배포에 대해 자세히 알아보세요. 지금 바로 등록하세요.
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.