OfficeQA 소개: 종단간 근거 기반 추론을 위한 벤치마크
작성자: Databricks AI 연구팀
에이전트 기능의 한계를 시험하는 여러 벤치마크(GDPval, Humanity's Last Exam (HLE), ARC-AGI-2)가 있지만, 저희는 이러한 벤치마크가 고객에게 중요한 종류의 작업을 대표한다고 생각하지 않습니다. 이러한 격차를 해소하기 위해 저희는 Databricks의 기업 고객이 수행하는 경제적으로 가치 있는 작업을 반영하는 벤치마크인 OfficeQA를 만들고 오픈 소스로 공개합니다. 저희는 비정형 문서와 표 형식 데이터를 포함하는 복잡한 독점 데이터세트를 기반으로 질문에 답하는, 매우 일반적이면서도 까다로운 기업 작업인 Grounded Reasoning에 중점을 둡니다.
최첨단 모델이 올림피아드 스타일 문제에서는 좋은 성능을 보이지만, 경제적으로 중요한 이러한 작업에서는 여전히 어려움을 겪는다는 것을 발견했습니다. 코퍼스에 액세스하지 않으면 질문의 약 2%만 정확하게 답변합니다. PDF 문서 코퍼스가 제공되었을 때 에이전트는 모든 질문에서 45% 미만의 정확도를 보이며, 가장 어려운 질문의 일부에서는 25% 미만의 정확도를 보입니다.
이 포스트에서는 먼저 OfficeQA와 저희의 설계 원칙에 대해 설명합니다. 그다음, OpenAI의 File Search & Retrieval API를 사용하는 GPT-5.1 Agent와 Claude의 Agent SDK를 사용하는 Claude Opus 4.5 Agent를 포함한 기존 AI 에이전트 솔루션을 벤치마크에서 평가합니다. Databricks의 ai_parse_document 를 사용하여 OfficeQA의 PDF 코퍼스를 파싱하는 Experiment를 진행했으며, 이를 통해 상당한 이점을 얻을 수 있음을 확인했습니다. 이러한 개선에도 불구하고 모든 시스템은 여전히 전체 벤치마크에서 70%의 정확도에 미치지 못하고, 가장 어려운 구간에서는 약 40%의 정확도에 그쳐 이 작업에 대한 개선의 여지가 많다는 것을 확인했습니다. 마지막으로, 이 분야의 혁신을 주도하기 위해 AI 에이전트가 인간 팀과 경쟁하는 2026년 봄 Databricks Grounded Reasoning Cup 개최를 발표합니다.
데이터세트 요구사항
OfficeQA를 구축하는 데에는 몇 가지 핵심 목표가 있었습니다. 첫째, 질문은 박사 수준의 전문 지식을 요구해서가 아니라 정밀성, 성실함, 시간과 같은 세심한 작업이 필요하기 때문에 어려워야 합니다. 둘째, 각 질문에는 그라운드 트루스(ground truth)와 비교하여 자동으로 확인할 수 있는 명확한 정답이 하나만 있어야 합니다. 그래야 인간이나 LLM의 판단 없이 시스템을 훈련하고 평가할 수 있습니다. 마지막으로 가장 중요한 것은, 벤치마크가 기업 고객이 직면하는 일반적인 문제를 정확하게 반영해야 한다는 점입니다.
일반적인 기업 문제를 세 가지 주요 구성 요소로 정리했습니다.
- 문서 복잡성: 기업은 스캔, PDF, 사진과 같은 방대한 소스 자료를 보유하고 있으며, 이러한 자료에는 상당한 양의 수치 또는 표 형식 데이터가 포함된 경우가 많습니다.
- 정보 검색 및 집계: 이러한 많은 문서 전반에 걸쳐 정보를 효율적으로 검색, 추출, 결합해야 합니다.
- 분석적 추론 및 질의응답: 기업은 이러한 문서에 기반하여 질문에 답하고 분석을 수행할 수 있는 시스템을 필요로 하며, 여기에는 때로 계산이나 외부 지식이 필요합니다.
또한 저희는 많은 기업이 이러한 작업을 수행할 때 매우 높은 정확도를 요구한다는 점에 주목합니다. 비슷한 것만으로는 충분하지 않습니다. 제품 번호나 송장 번호가 하나라도 틀리면 후속 작업에 치명적인 결과를 초래할 수 있습니다. 수익 예측에서 5%의 오차가 발생하면 심각하게 잘못된 비즈니스 결정으로 이어질 수 있습니다.
기존 벤치마크는 우리의 요구 사항을 충족하지 못합니다: | ||
|
| 예제 |
GDPVal | 과제는 경제적으로 가치 있는 작업의 명확한 예시이지만, 대부분은 고객이 중요하게 생각하는 부분을 구체적으로 테스트하지 않습니다. �전문가의 인간 심사가 권장됩니다. 또한 이 벤치마크는 각 질문에 직접 답하는 데 필요한 문서 집합만 제공하므로, 대규모 코퍼스에 대한 에이전트 검색 기능을 평가할 수 없습니다. | “당신은 2024년 로스앤젤레스의 음악 프로듀서입니다. 클라이언트의 의뢰를 받아 'Deja Vu'라는 노래의 뮤직비디오에 사용할 연주곡을 제작합니다” |
ARC-AGI-2 | 작업이 너무 추상적이어서 실제 세계의 경제적으로 가치 있는 작업과의 연결고리가 단절되어 있습니다. 즉, 색상이 있는 그리드의 추상적인 시각적 조작을 포함합니다. 매우 작고 전문화된 모델이 훨씬 더 큰(1000배) 범용 LLM의 성능에 필적할 수 있습니다. | 
|
인류의 마지막 시험(HLE) | 대부분의 경제적으로 가치 있는 작업을 명확하게 대표하지 않으며, Databricks 고객의 워크로드는 확실히 대표하지 않습니다. 질문에는 PhD 수준의 전문 지식이 필요하며, 한 사람이 모든 질문에 답할 수 있을 것 같지 않습니다. | “리 군 G2의 분류 공간에 대한 축소된 12차원 스핀 보디즘을 계산하시오. "축소되었다"는 것은 자명한 주 G2 번들을 갖는 다양체로 표현될 수 있는 모든 보디즘 클래스를 무시할 수 있다는 의미입니다.” |
OfficeQA 벤치마크를 소개합니다
저희는 기업용 내부 코퍼스와 유사하게 구성되었지만 무료로 사용할 수 있고 다양하고 흥미로운 질문을 지원하는 데이터 세트인 OfficeQA를 소개합니다. 이 벤치마크는 U.S. Treasury Bulletins(미국 재무부 회보) 를 활용하여 제작되었습니다. 이 회보는 1939년부터 50년간 매월 발행되었고 그 이후로는 분기별로 발행된 역사적인 자료입니다. 각 회보는 100~200페이지 분량이며 미국 재무부의 운영, 즉 자금의 출처, 현재 위치, 사용처, 운영 자금 조달 방법 등을 설명하는 산문, 다수의 복잡한 표, 차트, 그림으로 구성되어 있습니다. 전체 데이터 세트는 약 89,000페이지에 달합니다. 1996년까지 회보는 실제 문서를 스캔한 것이었고 그 이후에는 디지털로 제작된 PDF였습니다.
저희는 또한 이 역사적인 재무부 데이터를 일반 대중, 연구원, 학계에서 더 쉽게 접근할 수 있도록 만드는 데 가치가 있다고 생각합니다. USAFacts 는 '정부 데이터에 더 쉽게 접근하고 이해할 수 있도록 만드는 것'을 핵심 사명으로 하므로 이러한 비전을 자연스럽게 공유하는 조직입니다. 그들은 저희의 파트너로서 이 벤치마크를 개발했으며, 재무부 회보를 이상적인 데이터세트로 선정하고 저희 질문이 이 문서들의 현실적인 사용 사례를 반영하도록 했습니다.
비전문가도 질문에 답할 수 있어야 한다는 목표에 따라, 어떤 질문�도 고등학교 수준을 넘는 수학 연산을 요구하지 않습니다. 대부분의 사람들은 일부 금융 또는 통계 용어를 웹에서 찾아봐야 할 것으로 예상합니다.
데이터 세트 개요
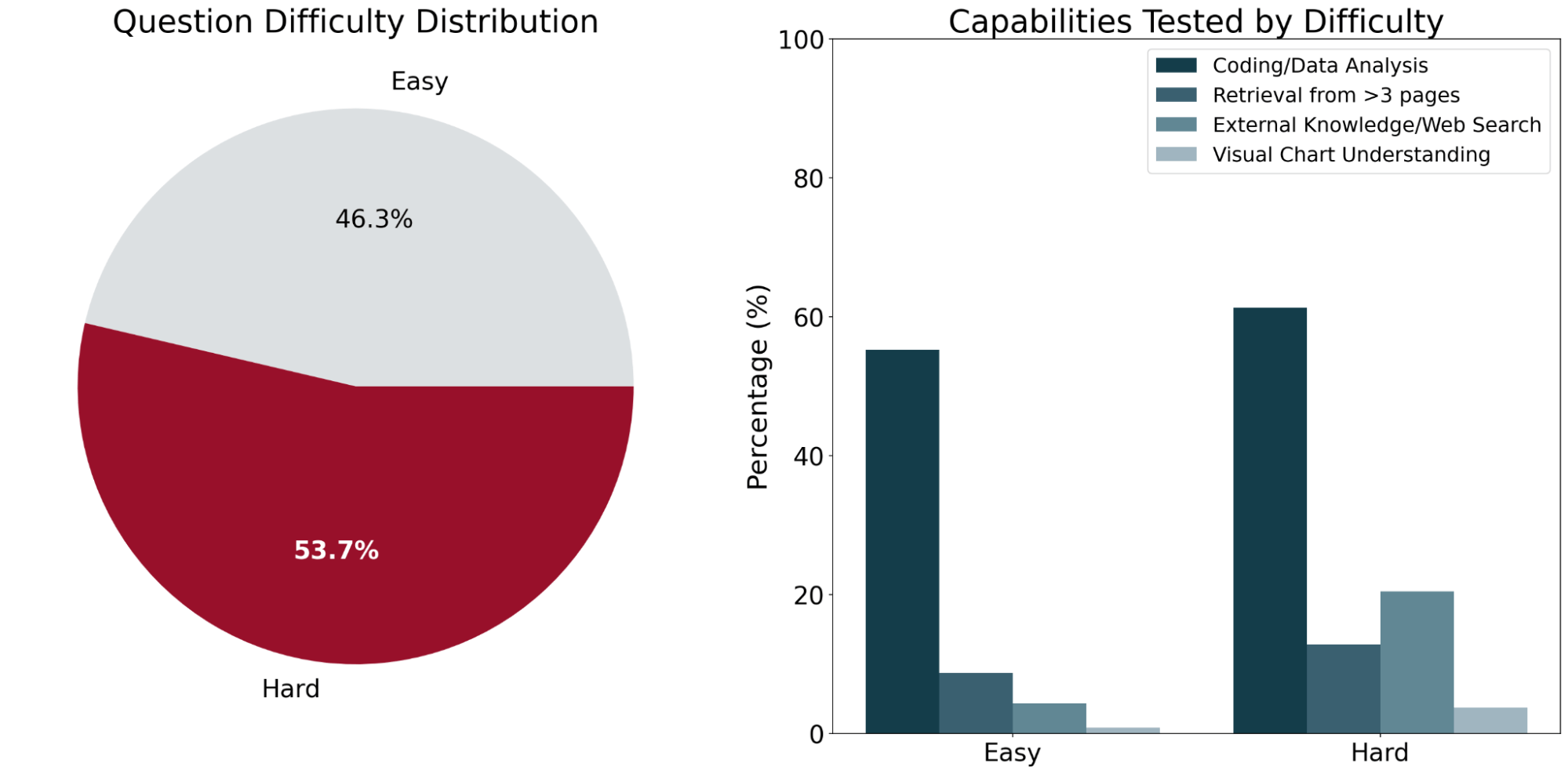
OfficeQA는 기존 AI 시스템의 성능에 따라 쉬움과 어려움, 두 가지 난이도로 분류된 246개의 질문으로 구성됩니다. “쉬움” 질문은 두 프론티어 에이전트 시스템(아래에 자세히 설명)이 모두 정답을 맞힌 질문으로 정의되며, “어려움” 질문은 에이전트 중 하나 이상이 오답을 낸 질문입니다.
질문에 답하려면 평균적으로 약 2개의 서로 다른 재무부 회보(Treasury Bulletin) 문서의 정보가 필요합니다. 벤치마크의 대표 샘플에 걸쳐, 인간 해결사들은 질문당 평균 50분의 완료 시간을 기록했습니다. 이 시간의 대부분은 코퍼스 내의 수많은 표와 그림에서 질문에 답하는 데 필요한 정보를 찾는 데 사용되었습니다.
OfficeQA의 질문이 문서 기반 검색(document-grounded retrieval)을 필요로 하도록 하기 위해, 소스 문서에 접근하지 않고도 LLM이 정답을 맞힐 수 있는 질문(즉, 모델의 파라메트릭 지식이나 웹 검색을 통해 답할 수 있는 질문)을 걸러내기 위해 최선을 다했습니다. 이렇게 걸러진 질문들은 대부분 “조지 H.W. 부시가 처음 대통령이 된 회계연도에 투자 증가율이 가장 높았던 미국 연방 신탁 기금은 무엇이었나요?” 와 같이 더 단순하거나 일반적인 사실에 대해 묻는 경향이 있었습니다.
흥미롭게도, “1942-1945년(제2차 세계대전 종료 전)과 1946-1949년(제2차 세계대전 종료 후) 사이 미국 재무부 채권의 평균 금리에 변화가 있었는지 5% 유의수준에서 2표본 t-검정을 실시하세요. 계산된 t-통계량을 소수점 둘째 자리까지 반올림하여 구하면 얼마입니까?” 와 같이 모델이 파라미터 지식만으로 답변할 수 있는, 겉보기에 더 복잡한 질문들이 일부 있었습니다. 이 경우 모델은 사전 학습 중에 암기한 과거 금융 기록을 활용하여 최종 값을 정확하게 compute합니다. 이러한 예시는 최종 벤치마크에서 제외되었습니다.
OfficeQA 질문 예시
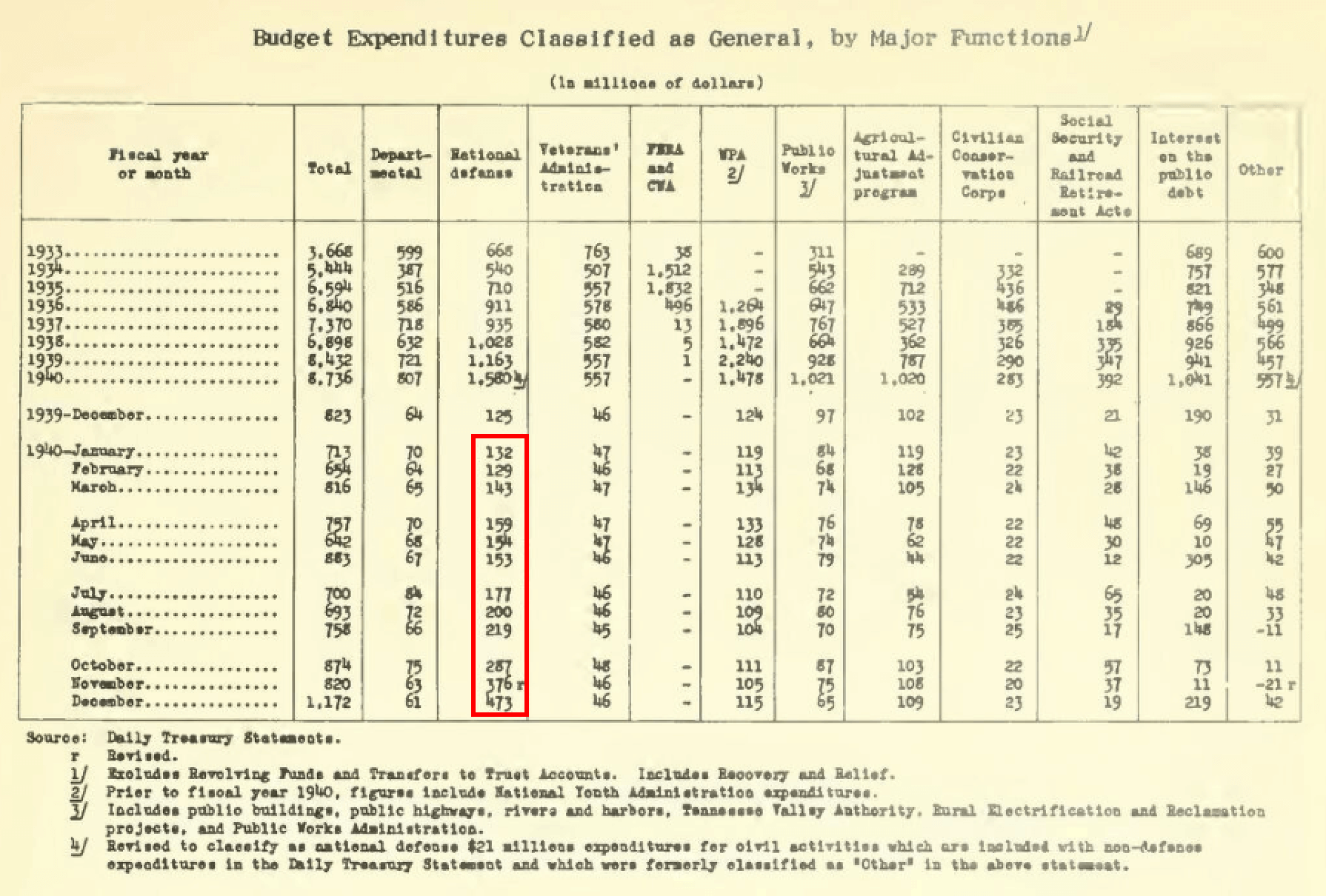
쉬움: “1940년 미국 국방비 총지출액(백만 명목 달러 기준)은 얼마였습니까?”
이 작업은 기본적인 값 조회와 단일 표(빨간색으로 강조 표시됨)에서 지정된 역년의 월별 값을 합산하는 것을 필요로 합니다. 이전 연도의 총계는 역년이 아닌 회계 연도 기준이라는 점에 유의하세요.
난이도: 상:"1990년부터 1998년까지(해당 연도 포함)의 연간 데이터를 사용하여 1999년 미국 농무부의 총지출을 예측하세요. 기본 선형 회귀 분석으로 기울기와 y절편을 구하세요. 시간 변수는 1990년을 '0'년으로 간주합니다. 모든 계산은 명목 달러 기준으로 수행하며, 연도 이후 조정은 고려하지 않아도 됩니다. 모든 값을 대괄호 안에 쉼표로 구분하여 보고하세요. 값의 순서는 �기울기(소수점 둘째 자리까지 반올림), y절편(가장 가까운 정수로 반올림), 예측값(가장 가까운 정수로 반올림)입니다."
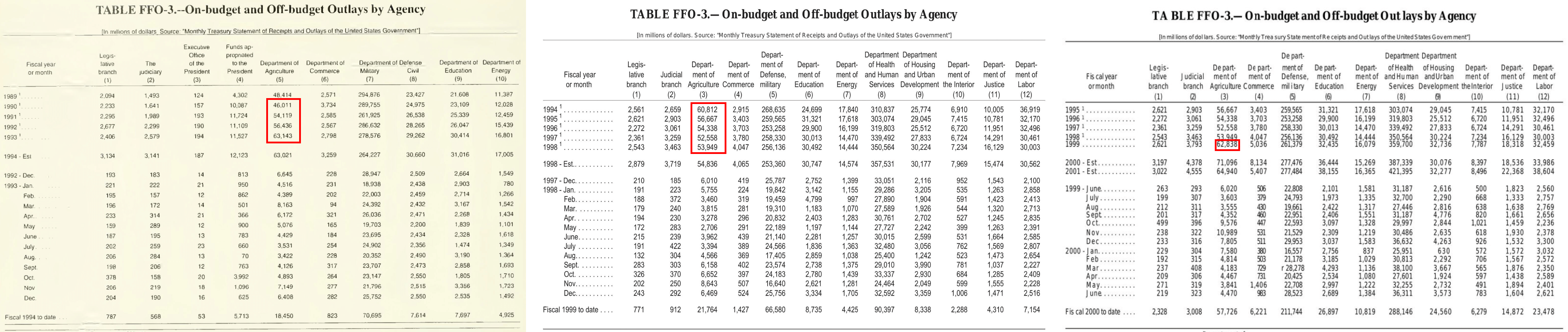
이 작업은 여러 문서(위에 그림으로 표시됨)를 탐색하며 정보를 찾아야 하고, 자세한 답변 가이드라인과 함께 더 발전된 추론과 통계 계산을 포함합니다.
기준 에이전트: 구현 및 성능
다음 베이스라인1을 평가합니다:
- 파일 검색 기능을 갖춘 GPT-5.1 에이전트: 저희는 OpenAI Responses API를 통해 reasoning_effort=high로 구성된 GPT-5.1을 사용하며, 이 에이전트에 파일 검색 및 웹 검색과 같은 도구에 대한 액세스 권한을 부여합니다. PDF는 OpenAI Vector Store에 upload되어 자동으로 파싱되고 인덱싱됩니다. 또한 ai_parse_document를 사용하여 사전 파싱된 문서를 Vector Store에 제공하는 Experiment도 진행합니다.
- Claude Opus 4.5 에이전트: 우리는 Claude의 에이전트 Python SDK를 Claude Opus 4.5를 백엔드(default thinking=high)로 사용하여 이 에이전트를 컨텍스트 관리와 같은 SDK 제공 자율 기능 및 파일 검색(읽기, grep, glob 등), 웹 검색, 프로그래밍 실행 및 기타 도구 기능이 포함된 기본 내장 도구 생태계로 구성합니다. Claude 에이전트 SDK는 자체 기본 내장 파싱 솔루션을 제공하지 않았기 때문에, (1) 에이전트에게 로컬 폴더 샌드박��스에 저장된 PDF를 제공하고
pdftotext및pdfplumber와 같은 PDF 리더 패키지를 설치할 수 있는 기능을 제공하고, (2) ai_parse_document를 사용하여 사전에 파싱된 문서를 에이전트에게 제공하는 Experiment를 했습니다. - Oracle PDF 페이지가 제공된 LLM: 질문에 답하는 데 필요한 정확한 Oracle PDF 페이지를 모델에 직접 제공하여 Claude Opus 4.5와 GPT 5.1을 평가합니다. 이는 에이전트 방식이 아닌 베이스라인으로, 추론 및 정답 도출에 필요한 소스 자료가 주어졌을 때 LLM의 성능을 측정하며 오라클 검색 시스템을 가정할 때의 성능 상한선을 나타냅니다.
- Oracle로 파싱한 PDF 페이지를 LLM에 제공: 저희는 또한 질문에 답하는 데 필요한 Oracle PDF 페이지를 ai_parse_document를 사용하여 미리 파싱한 후, Claude Opus 4.5와 GPT-5.1에 직접 제공하여 테스트합니다.
모든 실험에서, 우리는 미국 재무부 회보 PDF의 정확도가 낮기 때문에 기존 OCR 레이어를 제거합니다. 이를 통해 스캔된 문서에서 직접 정보를 추출하고 해석하는 각 에이전트의 능력을 공정하게 평가할 수 있습니다.
아래 그래프의 y축은 모든 에이전트의 정답률을 나타내고, x축은 정답으로 간주되기 위해 허용되는 절대 상대 오차를 나타냅니다. 예를 들어, 질문의 정답이 '520만'이고 에이전트가 '510만'(정답�에서 1.9% 차이)이라고 답한 경우, 에이전트는 1.9% 이상의 허용 절대 상대 오차에서는 정답으로, 1.9% 미만에서는 오답으로 채점됩니다.
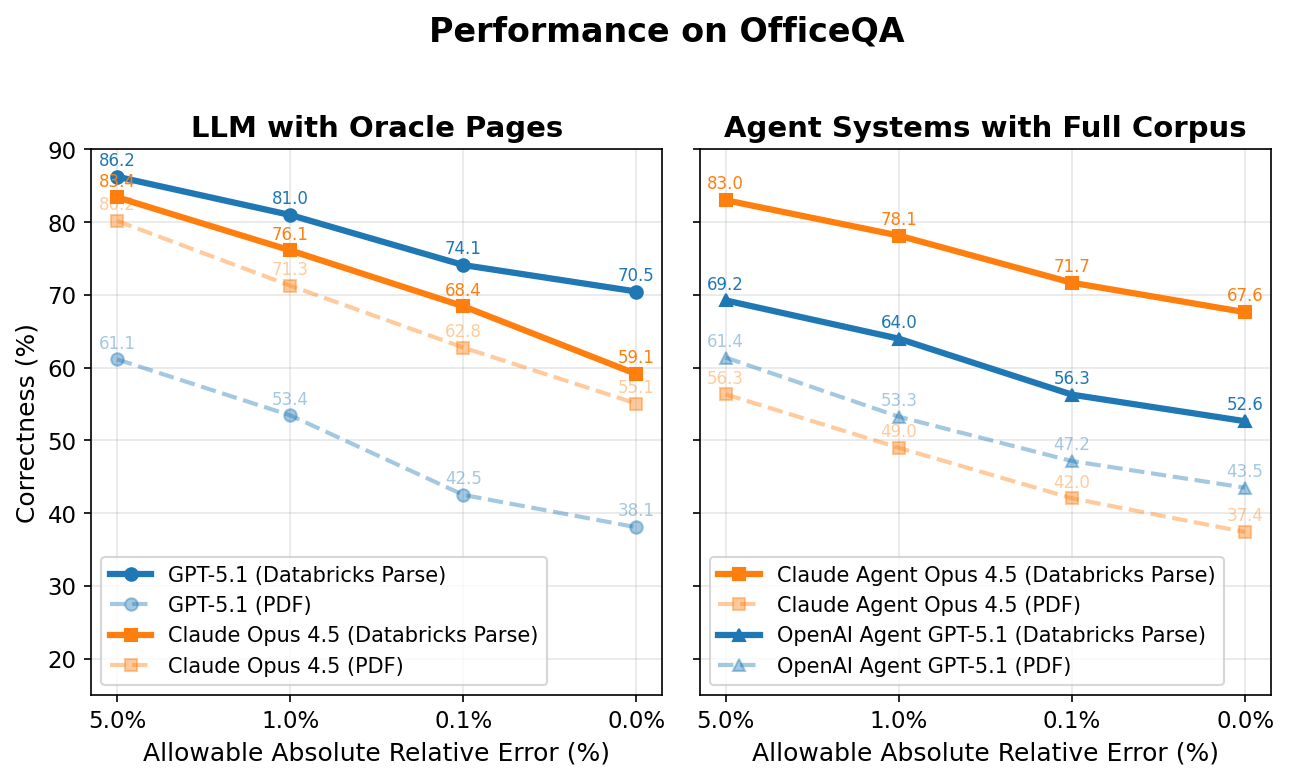
Oracle 페이지가 제공된 LLM
흥미롭게도 Claude Opus 4.5와 GPT 5.1은 각 질문에 필요한 오라클 PDF 페이지를 직접 제공받았을 때조차도 저조한 성능을 보였습니다. 하지만 이 동일한 페이지를 Databricks ai_parse_document를 사용하여 사전 처리하면 Claude Opus 4.5와 GPT 5.1의 성능이 각각 +4.0 및 +32.4 퍼센트 포인트(+7.5% 및 +85.0%에 해당)만큼 크게 향상됩니다 상대적 증가).
파싱 적용 시 최고 성능 모델(GPT-5.1)은 약 70%의 정확도에 도달합니다. 나머지 약 30%의 격차는 여러 요인에서 비롯됩니다. (1) 에이전트 방식이 아닌 이 베이스라인은 웹 검색과 같은 도구에 접근할 수 없는데, 약 13%의 질문이 이를 필요로 합니다. (2) 표와 차트에서 파싱 및 추출 오류가 발생합니다. (3) 계산 추론 오류가 남아 있습니다.
전체 코퍼스를 사용하는 에이전트 시스템
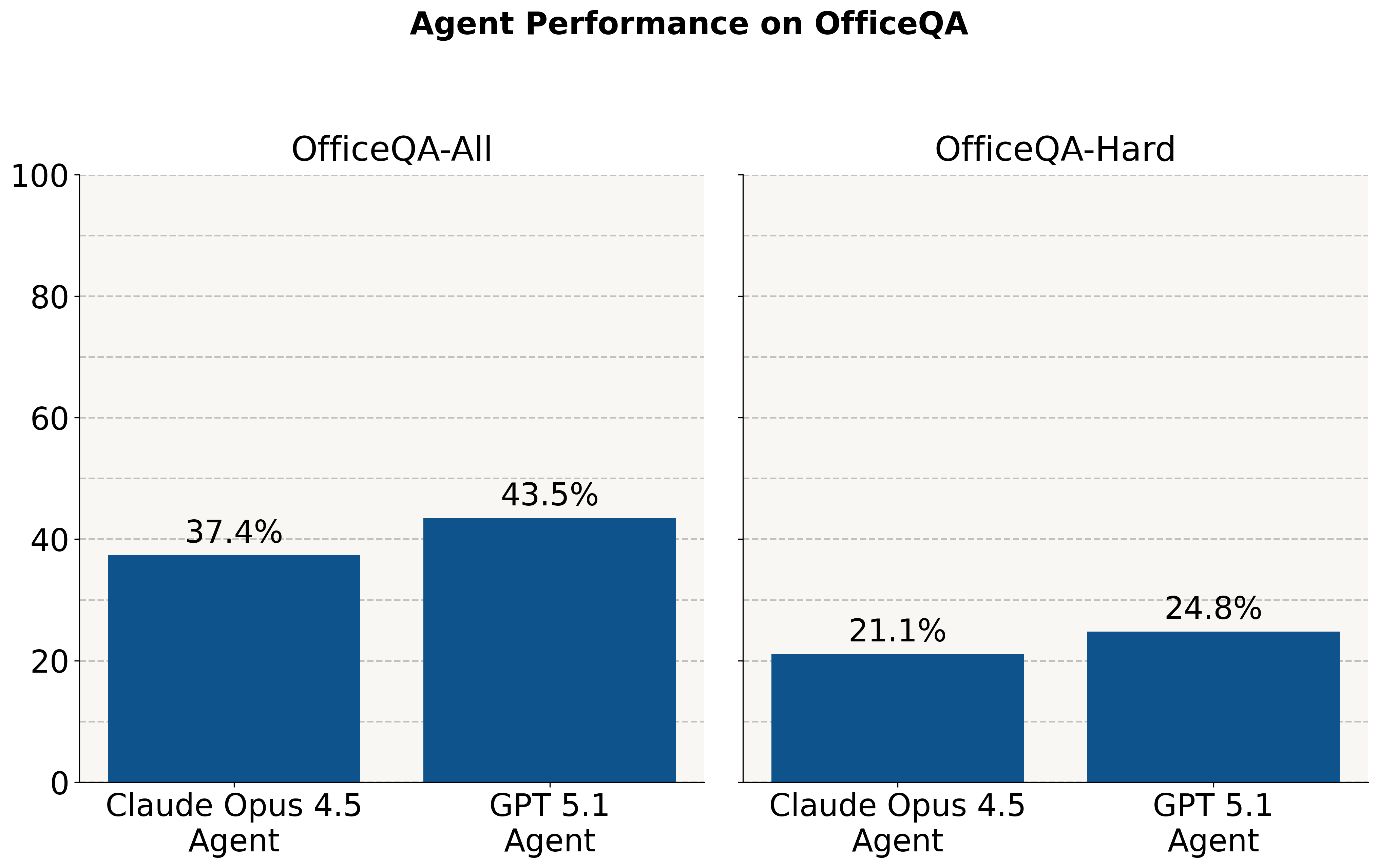
OfficeQA 코퍼스가 직접 제공되었을 때, 두 에이전트 모두 OfficeQA 질문의 절반 이상에 잘못 답변하여 허용 오차 0%에서 최�대 43.5%의 성능을 기록했습니다. Databricks ai_parse_document로 파싱된 문서를 에이전트에 제공하자 성능이 다시 한번 향상되었습니다. Claude 4.5 Opus Agent는 +30.2%p, GPT 5.1 Agent는 +9.1%p 향상되었습니다(각각 81.7%, 20.9% 상대적 증가율).
하지만 최고의 에이전트인 Claude Opus 4.5를 사용하는 Claude Agent조차도 파싱된 문서를 사용했을 때 허용 오차 0%에서 70% 미만의 정확도를 달성하는 데 그쳤으며, 이는 최신 AI 시스템에게 이러한 작업이 얼마나 어려운지를 잘 보여줍니다. 이러한 더 높은 성능을 달성하려면 더 높은 지연 시간과 관련 비용이 수반됩니다. 평균적으로 Claude Agent는 각 질문에 답하는 데 약 5분이 걸리는 반면, 더 낮은 점수를 받은 OpenAI 에이전트는 약 3분이 걸립니다.
예상대로, 더 높은 절대 상대 오차를 허용하면 정답률 점수가 점차 증가합니다. 이러한 불일치는 정밀도 drift(precision divergence)로 인해 발생하는데, 이는 에이전트가 사용하는 소스 값의 미세한 차이가 운영 과정을 거치면서 누적되어 최종 답변에서 작은 편차를 만들어내는 현상입니다. 오류에는 잘못된 파싱(예: '508'을 '608'로 읽는 경우), 통계 값의 오해석, 코퍼스에서 관련성 있고 정확한 정보를 검색하지 못하는 에이전트의 능력 부족 등이 포함됩니다. 예를 들어, 한 에이전트는 '2005년부터 2009년까지 각 회계연도 말에 기록된, 미국 정부 계정이 보유한 미결제 공채 총액의 합계(명목상 백만 달러)를 단일 값으로 반환하면 얼마인가요?'라는 질문에 대해 정답에 가깝지만 틀린 답을 내놓았습니다. 에이전트는 결국 2010년 6월 회보에서 정보를 가져왔지만, 관련성 있고 정확한 값은 (보고된 수정 사항에 따라) 2010년 9월 발행물에 있었습니다. 그 결과 2,100만 달러의 차이가 발생했습니다(정답에서 0.01% 벗어남).
더 큰 차이를 보이는 또 다른 예는 "1989-2013 역년의 보고된 총 흑자/적자 값에 대해 시계열 분석을 수행하고, 모든 값을 백만 달러 단위의 명목 가치로 취급한 다음, 3차 다항 회귀 모델을 피팅하여 2025 역년의 예상 흑자 또는 적자를 추정하고, 미국 재무부의 보고된 추정치와의 절대 차이를 백만 달러 단위에서 가장 가까운 정수로 반올림하여 보고하세요."라는 질문에서 찾아볼 수 있습니다. 한 에이전트가 8년 동안 역년(calendar year) 값 대신 회계연도(fiscal year) 값을 잘못 검색했습니다. 이로 인해 3차 회귀 분석에 사용된 입력 시계열이 변경되었고, 결과적으로 2025년 예측값과 절대 차이 결과가 실측값(ground truth)에서 31.6% 벗어난 $286,831백만 오차를 보였습니다.
실패 모드
OfficeQA를 개발하는 동안 우리는 기존 AI 시스템의 몇 가지 일반적인 실패 모드를 관찰했습니다:
- 파싱 오류 는 여전히 근본적인 문제입니다. 중첩된 열 계층, Merge된 셀, 특이한 서식을 가진 복잡한 표는 종종 값이 잘못 정렬되거나 잘못 추출되는 결과를 낳습니다. 예를 들어, 자동 추출 중에 열이 이동하여 숫자 값이 완전히 다른 헤더에 귀속되는 사례를 관찰했습니다.
- 답변의 모호성 또한 어려움을 야기합니다. U.S. Treasury Bulletin과 같은 금융 문서는 자주 개정되고 재발행되므로, 에이전트가 참조하는 발행일에 따라 동일한 데이터 포인트에 대해 여러 개의 유효한 값이 존재할 수 있습니다. 에이전트는 최신 값을 찾으라는 프롬프트가 있음에도 불구하고, 그럴듯한 답변을 찾으면 검색을 중단하여 가장 신뢰할 수 있거나 최신인 출처를 놓치는 경우가 많�습니다.
- 시각적 이해 능력 은 또 다른 중요한 격차를 보여줍니다. OfficeQA 질문의 약 3%는 시각적 추론이 필요한 차트, 그래프 또는 그림을 참조합니다. 아래 예시에서 볼 수 있듯이, 현재 에이전트들은 이러한 작업에서 자주 실패합니다.
이러한 남아있는 실패 모드는 AI 에이전트가 기업의 모든 도메인 내 추론 작업을 처리할 수 있기까지 아직 더 많은 연구 발전이 필요함을 보여줍니다.
Databricks Grounded Reasoning Cup
2026년 봄, 저희는 OfficeQA 벤치마크에서 누가 최고의 결과를 달성하는지 보기 위해 AI 에이전트와 인간 팀의 대결을 주최할 것입니다.
- 시기: 메인 이벤트 장소로 샌프란시스코를 고려하고 있으며, 시기는 3월 말에서 4월 말 사이가 될 가능성이 높습니다. 업데이트를 신청하신 분들께는 정확한 날짜가 곧 공지될 예정입니다.
- 오프라인 결선: 상위 팀들은 최종 대회를 위해 샌프란시스코로 초대됩니다.
현재 참가 관심 목록을 받고 있습니다. 공식 규칙, 날짜, Pool이 발표되는 즉시 알림을 받으려면 link 를 방문하세요. (곧 공개됩니다!)
결론
OfficeQA 벤치마크는 경제적으로 가치 있는 실제 세계의 근거 기반 추론 과제에 대해 AI 에이전트를 평가하는 데 있어 중요한 진전을 나타냅니다. 80년 이상에 걸쳐 거의 89,000페이지에 달하는 코퍼스인 미국 재무부 회보에 벤치마크의 기반을 둠으로써, 우리는 에이전트가 복잡한 표를 파싱하고, 여러 문서에 걸쳐 정보를 검색하며, 높은 정밀도로 분석적 추론을 수행해야 하는 도전적인 테스트베드를 만들었습니다.
OfficeQA 벤치마크는 연구 커뮤니티에 무료로 제공되며 여기에서 찾을 수 있습니다. Databricks Grounded Reasoning Cup의 일환으로 팀들이 OfficeQA를 탐색하고 벤치마크에 대한 솔루션을 제시하도록 권장합니다.
저자: Arnav Singhvi, Krista Opsahl-Ong, Jasmine Collins, Ivan Zhou, Cindy Wang, Ashutosh Baheti, Jacob Portes, Sam Havens, Erich Elsen, Michael Bendersky, Matei Zaharia, Xing Chen.
OfficeQA의 질문을 만드는 데 도움을 주신 Dipendra Kumar Misra, Owen Oertell, Andrew Drozdov, Jonathan Chang, Simon Favreau-Lessard, Erik Lindgren, Pallavi Koppol, Veronica Lyu, 그리고 SuperAnnotate와 Turing에 감사를 표합니다.
마지막으로, 미국 재무부 회보를 선정하고 질문이 시의적절하며 관련성이 있도록 피드백을 제공해주신 USAFacts에도 감사를 표합니다.
1 저희는 최근 출시된 Gemini File Search Tool API를 Gemini 3를 사용한 대표적인 Gemini 에이전트 베이스라인의 일부로 평가하려고 시도했습니다. 하지만 OfficeQA 코퍼스에 있는 PDF 및 파싱된 PDF의 약 30%가 수집(ingest)에 실패했으며, File Search Tool은 Google Search Tool��과 호환되지 않았습니다. 이는 에이전트가 외부 지식이 필요한 OfficeQA 질문에 답변하는 것을 제한하므로, 저희는 이 설정을 베이스라인 평가에서 제외했습니다. 수집(ingestion) 기능이 안정적으로 작동하면 성능을 정확하게 측정하기 위해 다시 검토할 것입니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.