LLM 추론 성능 엔지니어링: 모범 사례
작성자: Megha Agarwal, Asfandyar Qureshi, Nikhil Sardana, Linden Li, Julian Quevedo , Daya Khudia
In this blog post, the MosaicML engineering team shares best practices for how to capitalize on popular open source large language models (LLMs) for production usage. We also provide guidelines for deploying inference services built around these models to help users in their selection of models and deployment hardware. We have worked with multiple PyTorch-based backends in production; these guidelines are drawn from our experience with FasterTransformers, vLLM, NVIDIA's soon-to-be-released TensorRT-LLM, and others.
LLM 텍스트 생성 이해하기
Large Language Models (LLMs)는 두 단계 프로세스를 통해 텍스트를 생성합니다. 첫 번째 단계는 입력 프롬프트의 토큰을 병렬로 처리하는 "prefill"이고, 두 번째 단계는 텍스트를 '토큰' 단위로 순환적으로 생성하는 "decoding"입니다. 생성된 각 토큰은 입력에 추가되어 다음 토큰을 생성하기 위해 모델에 다시 입력됩니다. LLM이 특수 중지 토큰을 출력하거나 사용자가 정의한 조건(예: 최대 토큰 수 생성)이 충족되면 생성이 중지됩니다. LLM이 디코더 블록을 사용하는 방법에 대한 자세한 내용은 이 블로그 게시물을 참조하세요.
토큰은 단어 또는 하위 단어일 수 있습��니다. 텍스트를 토큰으로 분할하는 정확한 규칙은 모델마다 다릅니다. 예를 들어, Llama 모델이 텍스트를 토큰화하는 방식과 OpenAI 모델이 텍스트를 토큰화하는 방식을 비교할 수 있습니다. LLM 추론 제공업체는 종종 토큰 기반 지표(예: 초당 토큰 수)로 성능을 이야기하지만, 이러한 변형으로 인해 이 수치가 모델 유형 간에 항상 비교 가능한 것은 아닙니다. 구체적인 예로, Anyscale 팀은 Llama 2 토큰화가 ChatGPT 토큰화보다 19% 더 길다는 것을 발견했습니다(하지만 전체 비용은 훨씬 낮습니다). HuggingFace의 연구원들은 또한 Llama 2가 GPT-4와 동일한 양의 텍스트를 학습하는 데 약 20% 더 많은 토큰이 필요하다는 것을 발견했습니다.
LLM 서빙을 위한 중요 지표
그렇다면 추론 속도에 대해 정확히 어떻게 생각해야 할까요?
저희 팀은 LLM 서빙에 네 가지 주요 지표를 사용합니다.
- 최초 토큰까지의 시간(TTFT): 사용자가 쿼리를 입력한 후 모델의 출력을 보기 시작하는 데 걸리는 시간입니다. 실시간 상호 작용에서는 짧은 대기 시간이 필수적이지만, 오프라인 작업에서는 덜 중요합니다. 이 지표는 프롬프트 처리 및 첫 번째 출력 토큰 생성에 필요한 시간으로 결정됩니다.
- 출력 토큰당 시간(TPOT): 저희 시스템에 쿼리하는 모든 사용자에 대해 출력 토큰을 생성하는 데 걸리는 시간입니다. 이 지표는 각 사용자가 모델의 "속도"를 어떻게 인식하는지에 해당합니다. 예를 들어, TPOT가 100밀리초/토큰이면 사용자당 초당 10토큰, 즉 분당 약 450단어이며, 이는 일반적인 사람이 읽는 속도보다 빠릅니다.
- 지연 시간: 모델이 사용자에게 전체 응답을 생성하는 데 걸리는 총 시간입니다. 전체 응답 지연 시간은 이전 두 지표를 사용하여 계산할 수 있습니다: 지연 시간 = (TTFT) + (TPOT) * (생성될 토큰 수).
- 처리량: 추론 서버가 모든 사용자 및 요청에 대해 초당 생성할 수 있는 출력 토큰 수입니다.
저희의 목표는 무엇일까요? 최초 토큰까지의 가장 빠른 시간, 가장 높은 처리량, 그리고 가장 빠른 출력 토큰당 시간입니다. 즉, 가능한 한 많은 사용자를 지원하기 위해 가능한 한 빨리 텍스트를 생성하는 모델을 원합니다.
특히, 처리량과 출력 토큰당 시간 사이에는 절충점이 있습니다. 16개의 사용자 쿼리를 동시에 처리하면 순차적으로 쿼리를 실행하는 것보다 더 높은 처리량을 얻을 수 있지만, 각 사용자에 대한 출력 토큰 생성에는 더 오래 걸립니다.
전체 추론 지연 시간 목표가 있다면, 모델을 평가하는 데 유용한 몇 가지 휴리스틱이 있습니다.
- 출력 길이가 전체 응답 지연 시간을 지배합니다: 평균 지연 시간의 경우, 예상/최대 출력 토큰 길이에 모델의 전반적인 평균 출력 토큰당 시간을 곱하면 됩니다.
- 입력 길이는 성능에 중요하지 않지만 하드웨어 요구 사항에는 중요합니다: 512개의 입력 토큰을 추가해도 MPT 모델에서 8개의 추가 출력 토큰을 생성하는 것보다 지연 시간이 덜 증가합니다. 그러나 긴 입력을 지원해야 하는 필요성은 모델을 서빙하기 어렵게 만들 수 있습니다. 예를 들어, MPT-7B를 최대 컨텍스트 길이 2048 토큰으로 서빙하려면 A100-80GB(또는 최신 모델)를 사용하는 것이 좋습니다.
- 전체 지연 시간은 모델 크기에 따라 비선형적으로 확장됩니다: 동일한 하드웨어에서 더 큰 모델은 느리지만, 속도 비율이 반드시 파라미터 수 비율과 일치하지는 않습니다. MPT-30B 지연 시간은 MPT-7B 지연 시간의 약 2.5배입니다. Llama2-70B 지연 시간은 Llama2-13B 지연 시간의 약 2배입니다.
잠재 고객으로부터 평균 추론 지연 시간을 제공해 달라는 요청을 자주 받습니다. 특정 지연 시간 목표("토큰당 20ms 미만이 필요합니다")에 자신을 고정하기 전에 예상 입력 길이와 원하는 출력 길이를 파악하는 데 시간을 할애하는 것이 좋습니다.
LLM 추론의 과제
LLM 추론 최적화는 다음과 같은 일반적인 기술의 이점을 얻습니다.
- 연산자 융합: 서로 인접한 다른 연산자를 결합하면 종종 지연 시간이 개선됩니다.
- 양자화: 활성화 및 가중치가 더 적은 비트를 사용하도록 압축됩니다.
- 압축: 희소성 또는 증류.
- 병렬화: 여러 장치에 걸친 텐서 병렬화 또는 더 큰 모델을 위한 파이프라인 병렬화.
이러한 방법 외에도 Transformer별로 중요한 최적화가 많이 있습니다. 그중 대표적인 예가 KV(키-값) 캐싱입니다. 디코더 전용 Transformer 기반 모델의 어텐션(Attention) 메커니즘은 계산적으로 비효율적입니다. 각 토큰은 이전에 본 모든 토큰에 주의를 기울이므로, 새 토큰이 생성될 때마다 동일한 값을 많이 다시 계산합니다. 예를 들어, N번째 토큰을 생성하는 동안 (N-1)번째 토큰은 (N-2)번째, (N-3)번째… 1번째 토큰에 주의를 기울입니다. 마찬가지로, (N+1)번째 토큰을 생성하는 동안 N번째 토큰에 대한 어텐션은 다시 (N-1)번째, (N-2)번째, (N-3)번째… 1번째 토큰을 살펴봐야 합니다. KV 캐싱, 즉 어텐션 레이어의 중간 키/값을 저장하는 것은 나중에 재사용하기 위해 해당 결과를 보존하여 반복적인 계산을 피하는 데 사용됩니다.
메모리 대역폭이 핵심입니다
LLM의 계산은 주로 행렬-행렬 곱셈 연산에 의해 지배됩니다. 작은 차원을 가진 이러한 연산은 대부분의 하드웨어에서 일반적으로 메모리 대역폭에 의해 제한됩니다. 순환 방식으로 토큰을 생성할 때, 활성화 행렬 차원 중 하나(배치 크기와 시퀀스의 토큰 수로 정의됨)는 작은 배치 크기에서 작습니다. 따라서 속도는 로드된 데이터에 대해 얼마나 빨리 계산할 수 있는지보다 GPU 메모리에서 로컬 캐시/레지스터로 모델 파라미터를 얼마나 빨리 로드할 수 있는지에 따라 달라집니다. 추론 하드웨어의 사용 가능한 메모리 대역폭과 달성된 메모리 대역폭은 피크 컴퓨팅 성능보다 토큰 생성 속도를 더 잘 예측합니다.
추론 하드웨어 활용도는 서빙 비용 측면에서 매우 중요합니다. GPU는 비싸며 최대한 많은 작업을 수행하도록 해야 합니다. 공유 추론 서비스는 여러 사용자의 워크로드를 결합하고 개별 간격을 채우고 중복 요청을 일괄 처리하여 비용��을 낮게 유지할 것을 약속합니다. Llama2-70B와 같은 대형 모델의 경우 대규모 배치 크기에서만 좋은 비용/성능을 달성할 수 있습니다. 대규모 배치 크기에서 작동할 수 있는 추론 서빙 시스템을 갖추는 것이 비용 효율성에 중요합니다. 그러나 큰 배치는 더 큰 KV 캐시 크기를 의미하며, 이는 모델을 서빙하는 데 필요한 GPU 수를 증가시킵니다. 여기서 밀고 당기는 힘이 있으며 공유 서비스 운영자는 비용 절충을 하고 시스템 최적화를 구현해야 합니다.
모델 대역폭 활용도(MBU)
LLM 추론 서버는 얼마나 최적화되었을까요?
앞서 간략하게 설명했듯이, 작은 배치 크기에서의 LLM 추론, 특히 디코드 시에는 장치 메모리에서 컴퓨팅 유닛으로 모델 파라미터를 얼마나 빨리 로드할 수 있는지에 따라 병목 현상이 발생합니다. 메모리 대역폭은 데이터 이동이 얼마나 빨리 발생하는지를 결정합니다. 기본 하드웨어의 활용도를 측정하기 위해 모델 대역폭 활용도(MBU)라는 새로운 지표를 도입합니다. MBU는 (달성된 메모리 대역폭) / (최대 메모리 대역폭)으로 정의되며, 여기서 달성된 메모리 대역폭은 ((총 모델 파라미터 크기 + KV 캐시 크기) / TPOT)입니다.
예를 들어, 16비트 정밀도로 실행되는 7B 매개변수 모델의 TPOT가 14ms라면, 이는 14GB의 매개변수를 14ms 동안 이동시키는 것으로 초당 1TB의 대역폭 사용량을 의미합니다. 머신의 최대 대역폭이 2TB/sec라면, 우리는 50%의 MBU로 실행 중인 것입니다. 단순화를 위해, 이 예제에서는 배치 크기가 작고 시퀀스 길이가 짧을 때 작은 KV 캐시 크기는 무시합니다. 100%에 가까운 MBU 값은 추론 시스템이 사용 가능한 메모리 대역폭을 효과적으로 활용하고 있음을 의미합니다. MBU는 또한 서로 다른 추론 시��스템(하드웨어 + 소프트웨어)을 정규화된 방식으로 비교하는 데 유용합니다. MBU는 계산 집약적인 환경에서 중요한 지표인 모델 연산 활용률(MFU; PaLM 논문에서 소개됨) 지표를 보완합니다.
그림 1은 루프라인 플롯과 유사한 플롯에서 MBU를 시각적으로 표현한 것입니다. 주황색 음영 영역의 기울어진 실선은 메모리 대역폭이 100% 포화되었을 때 가능한 최대 처리량을 보여줍니다. 그러나 실제로는 낮은 배치 크기(흰색 점)의 경우 관찰된 성능이 최대치보다 낮으며, 얼마나 낮은지가 MBU의 척도입니다. 큰 배치 크기(노란색 영역)의 경우 시스템은 계산 집약적이며, 가능한 최대 처리량 대비 달성된 처리량 비율은 모델 연산 활용률(MFU)로 측정됩니다.
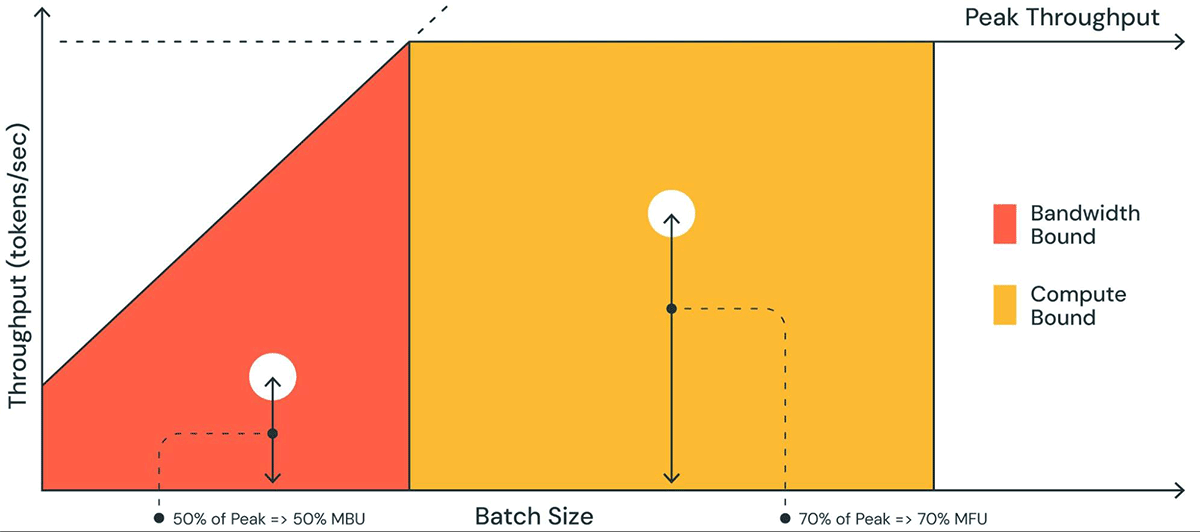
MBU와 MFU는 주어진 하드웨어 설정에서 추론 속도를 얼마나 더 높일 수 있는지를 결정합니다. 그림 2는 TensorRT-LLM 기반 추론 서버에서 다양한 수준의 텐서 병렬 처리에 대한 측정된 MBU를 보여줍니다. 최대 메모리 대역폭 활용률은 크고 연속적인 메모리 청크를 전송할 때 달성됩니다. MPT-7B와 같이 더 작은 모델이 여러 GPU에 분산될 때, 각 GPU에서 더 작은 메모리 청크를 이동시키므로 MBU가 낮아지는 것을 관찰할 수 있습니다.
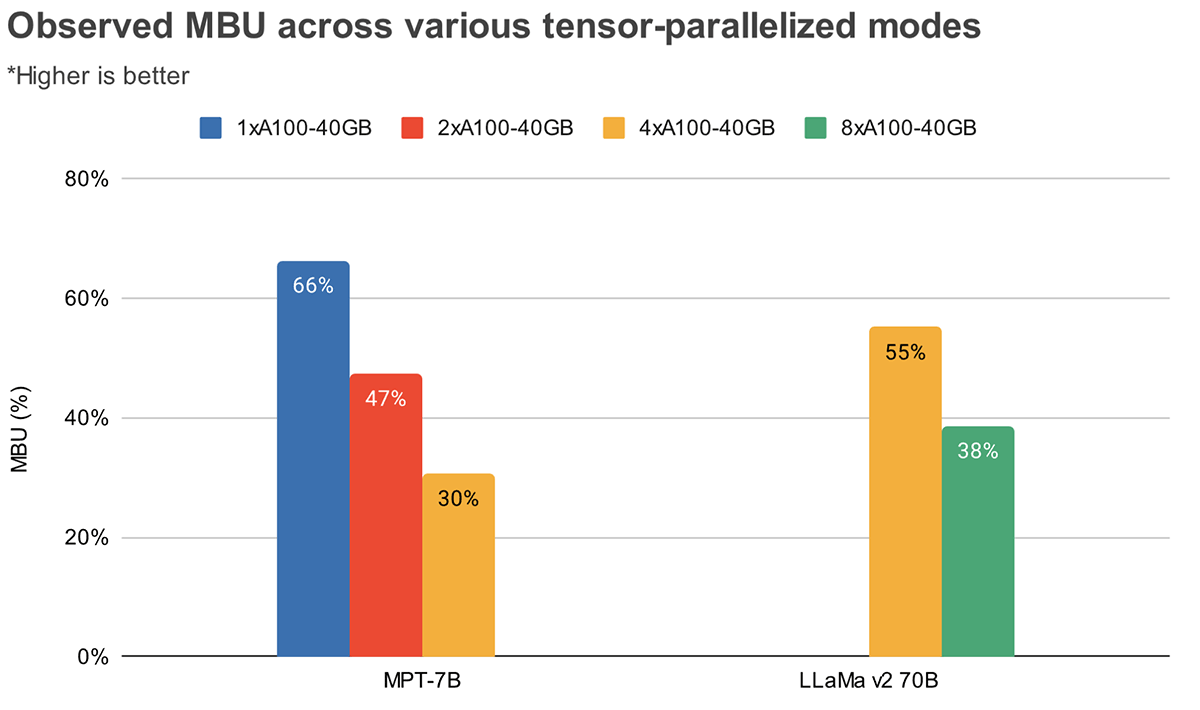
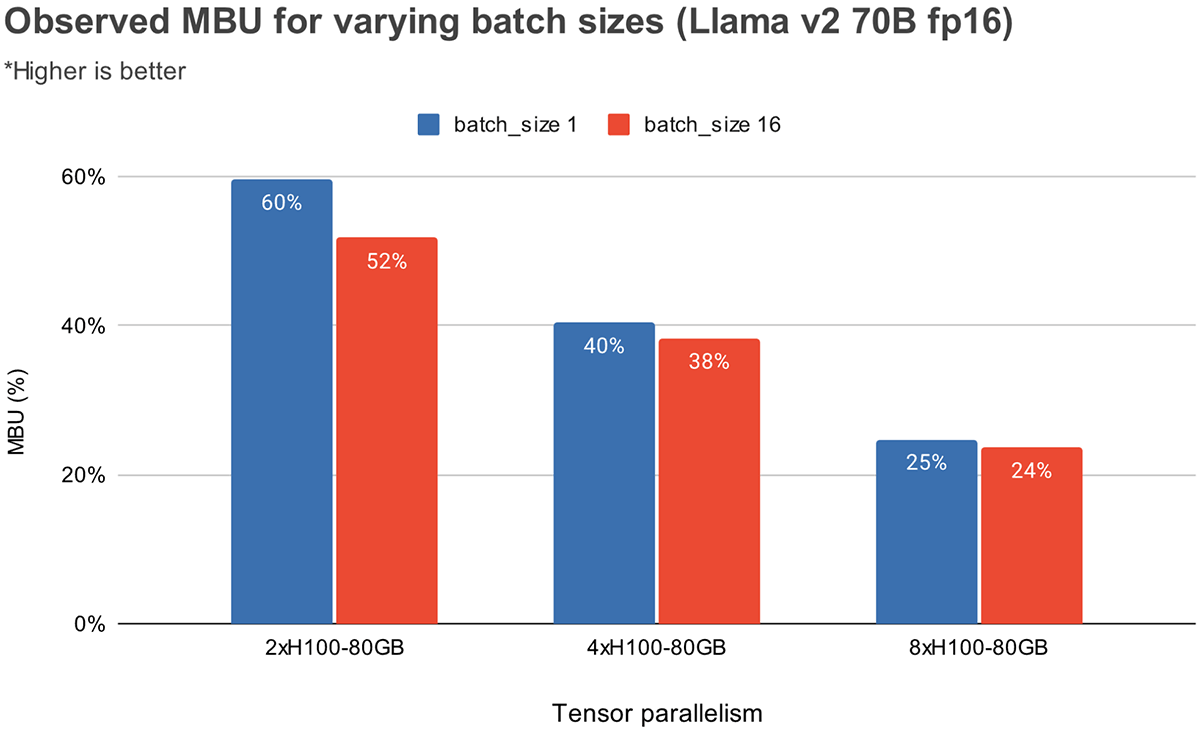
그림 3은 NVIDIA H100 GPU에서 다양한 텐서 병렬 처리 수준 및 배치 크기에 대한 경험적으로 관찰된 MBU를 보여줍니다. MBU는 배치 크기가 증가함에 따라 감소합니다. 그러나 GPU를 확장함에 따라 MBU의 상대적 감소는 덜 중요해집니다. 또한 더 큰 메모리 대역폭을 가진 하드웨어를 선택하면 더 적은 GPU로 성능을 향상시킬 수 있다는 점도 주목할 가치가 있습니다. 배치 크기 1에서, 그림 2의 4xA100-40GB GPU에서 55%보다 2xH100-80GB에서 60%의 더 높은 MBU를 달성할 수 있습니다.
벤치마킹 결과
지연 시간
MPT-7B 및 Llama2-70B 모델에 대해 다양한 수준의 텐서 병렬 처리에 걸쳐 첫 번째 토큰까지의 시간(TTFT)과 출력 토큰당 시간(TPOT)을 측정했습니다. 입력 프롬프트가 길어질수록 첫 번째 토큰 생성 시간이 전체 지연 시간의 상당 부분을 차지하기 시작합니다. 여러 GPU에 걸쳐 텐서를 병렬 처리하면 이 지연 시간을 줄이는 데 도움이 됩니다.
모델 학습과 달리, 추론 지연 시간에 더 많은 GPU를 사용해도 성능 향상의 효과가 크게 줄어듭니다. 예를 들어, Llama2-70B의 경우 4x에서 8x GPU로 확장해도 작은 배치 크기에서는 지연 시간이 0.7배만 감소합니다. 한 가지 이유는 더 높은 병렬 처리 수준이 더 낮은 MBU를 갖기 때문이며(앞서 논의됨), 또 다른 이유는 텐서 병렬 처리가 GPU 노드 간 통신 오버헤드를 발생시키기 때문입니다.
| 첫 번째 토큰까지의 시간 (ms) | ||||
|---|---|---|---|---|
| 모델 | 1xA100-40GB | 2xA100-40GB | 4xA100-40GB | 8xA100-40GB |
| MPT-7B | 46 (1x) | 34 (0.73x) | 26 (0.56x) | - |
| Llama2-70B | 수용 불가 | 154 (1x) | 114 (0.74x) | |
표 1: 입력 요청이 배치 크기 1의 512 토큰 길이일 때 첫 번째 토큰까지의 시간. Llama2 70B와 같은 더 큰 모델은 메모리에 수용하려면 최소 4개의 A100-40B GPU가 필요합니다.
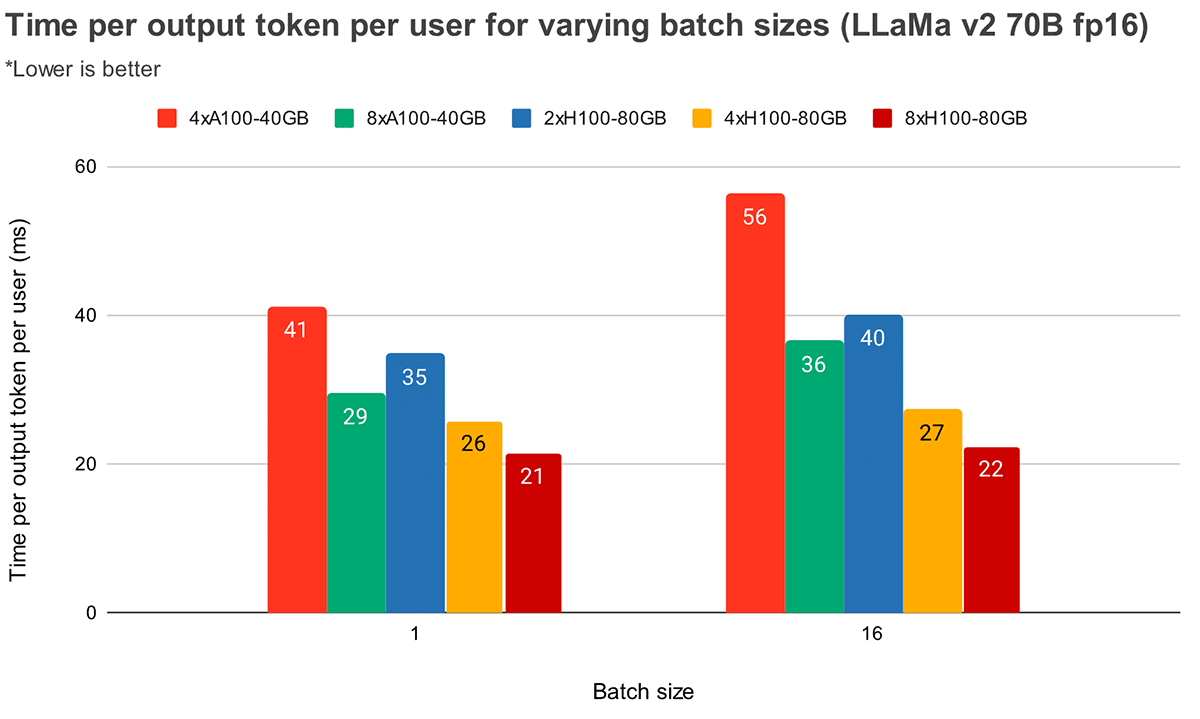
더 큰 배치 크기에서는 높은 텐서 병렬 처리가 토큰 지연 시간의 상대적 감소를 더 크게 만듭니다. 그림 4는 MPT-7B의 출력 토큰당 시간이 어떻게 변하는지 보여줍니다. 배치 크기 1에서는 2x에서 4x로 늘릴 때 토큰 지연 시간이 약 12%만 감소합니다. 배치 크기 16에서는 4x일 때의 지연 시간이 2x일 때보다 33% 낮습니다. 이는 배치 크기 16의 경우 배치 크기 1에 비해 텐서 병렬 처리 수준이 높을수록 MBU의 상대적 감소가 작다는 이전 관찰과 일치합니다.
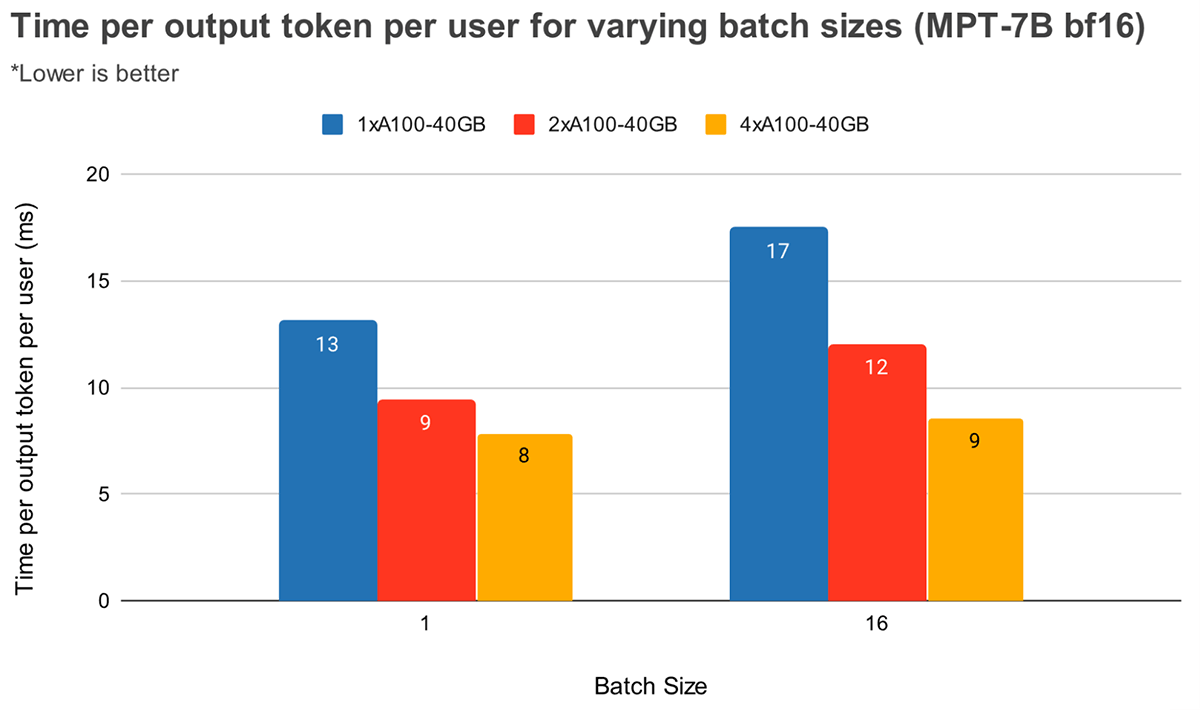
그림 5는 Llama2-70B에 대한 유사한 결과를 보여주지만, 4x와 8x 간의 상대적 개선은 덜 두드러집니다. 또한 두 가지 다른 하드웨어 간의 GPU 확장을 비교합니다. H100-80GB는 A100-40GB에 비해 GPU 메모리 대역폭이 2.15배 더 크기 때문에, 4x 시스템의 경우 배치 크기 1에서 지연 시간이 36% 낮고 배치 크기 16에서 52% 낮다는 것을 알 수 있습니다.
처리량
요청을 함께 배치하여 처리량과 토큰당 시간을 절충할 수 있습니다. GPU 평가 중에 쿼리를 그룹화하면 쿼리를 순차적으로 처리하는 것보다 처리량이 증가하지만, 각 쿼리가 완료되는 데 더 오래 걸립니다(큐잉 효과는 무시).
추론 요청을 배치하는 데는 몇 가지 일반적인 기법이 있습니다:
- 정적 배치: 클라이언트가 여러 프롬프트를 요청으로 묶고 배치 내의 모든 시퀀스가 완료된 후 응답이 반환됩니다. 당사의 추론 서버는 이를 지원하지만 필수는 아닙니다.
- 동적 배치: 프롬프트는 서버 내부에서 즉석에서 함께 배치됩니다. 일반적으로 이 방법은 정적 배치보다 성능이 떨어지지만, 응답이 짧거나 길이가 균일한 경우 최적에 가까워질 수 있습니다. 요청에 다른 매개변수가 있을 때는 잘 작동하지 않습니다.
- 연속 배치: 요청을 도착하는 대로 함께 배치하는 아이디어는 이 훌륭한 논문에서 소개되었으며 현재 SOTA(State-of-the-Art) 방법입니다. 배치 내의 모든 시퀀스가 완료될 때까지 기다리는 대신, 반복 수준에서 시퀀스를 함께 그룹화합니다. 동적 배치보다 10배-20배 더 나은 처리량을 달성할 수 있습니다.
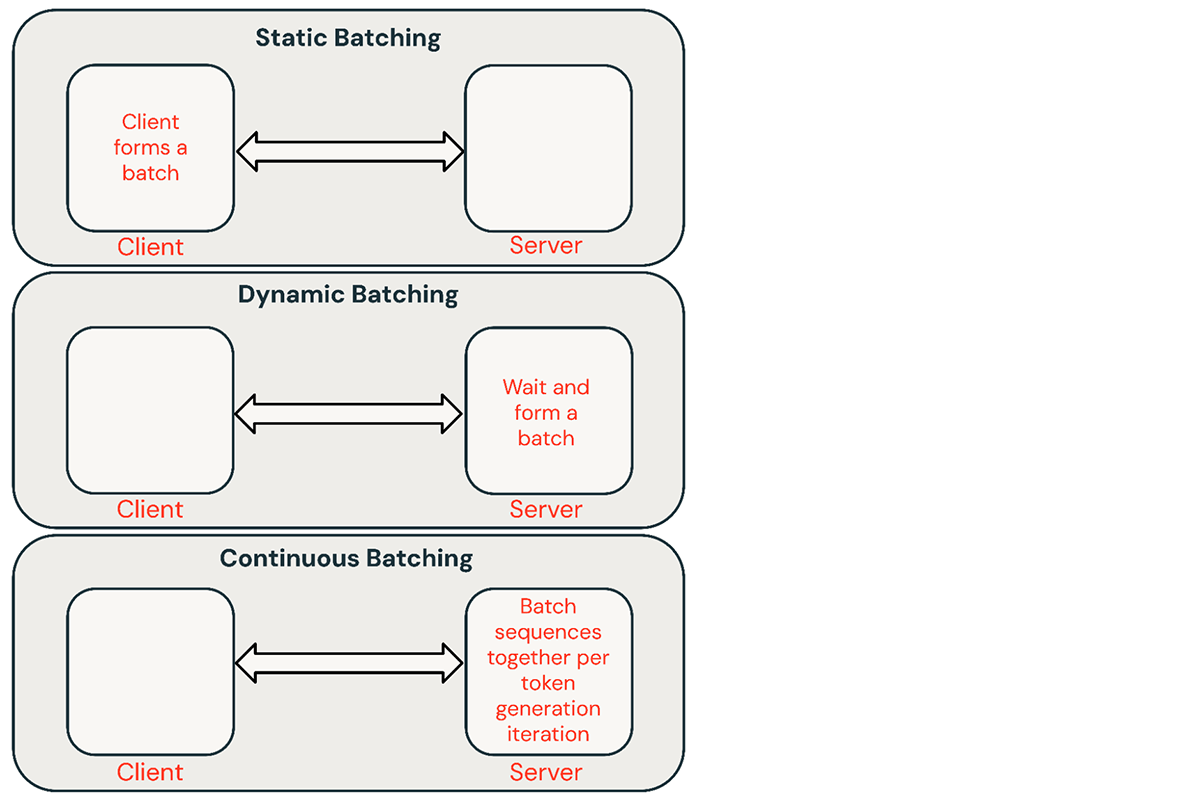
연속 배치는 일반적으로 공유 서비스에 가장 좋은 접근 방식이지만, 다른 두 가지가 더 나은 상황도 있습니다. 낮은 QPS 환경에서는 동적 배치가 연속 배치보다 성능이 좋을 수 있습니다. 더 간단한 배치 프레임워크에서 저수준 GPU 최적화를 구현하는 것이 때때로 더 쉽습니다. 오프라인 배치 추론 워크로드의 경우, 정적 배치는 상당한 오버헤드를 피하고 더 나은 처리량을 달성할 수 있습니다.
배치 크기
배칭이 얼마나 잘 작동하는지는 요청 스트림에 따라 크게 달라집니다. 하지만 균일한 요청으로 정적 배칭을 벤치마킹하여 성능의 상한선을 파악할 수 있습니다.
| 배치 크기 | |||||||
|---|---|---|---|---|---|---|---|
| 하드웨어 | 1 | 4 | 8 | 16 | 32 | 64 | 128 |
| 1 x A10 | 0.4 (1x) | 1.4 (3.5x) | 2.3 (6x) | 3.5 (9x) | OOM (메모리 부족) 오류 | ||
| 2 x A10 | 0.8 | 2.5 | 4.0 | 7.0 | 8.0 | ||
| 1 x A100 | 0.9 (1x) | 3.2 (3.5x) | 5.3 (6x) | 8.0 (9x) | 10.5 (12x) | 12.5 (14x) | |
| 2 x A100 | 1.3 | 3.0 | 5.5 | 9.5 | 14.5 | 17.0 | 22.0 |
| 4 x A100 | 1.7 | 6.2 | 11.5 | 18.0 | 25.0 | 33.0 | 36.5 |
표 2: FasterTransformers 기반 백엔드를 사용한 정적 배칭 시 MPT-7B의 최대 처리량(초당 요청 수). 요청: 입력 512개, 출력 64개 토큰. 더 큰 입력의 경우, OOM 경계는 더 작은 배치 크기에서 발생합니다.
지연 시간 절충
요청 지연 시간은 배치 크기가 증가함에 따라 늘어납니다. 예를 들어, NVIDIA A100 GPU 하나로 배치 크기를 64로 설정하여 처리량을 최대로 하면, 지연 시간은 4배 증가하는 반면 처리량은 14배 증가합니다. 공유 추론 서비스는 일반적으로 균형 잡힌 배치 크기를 선택합니다. 자체 모델을 호스팅하는 사용자는 애플리케이션에 적합한 지연 시간/처리량 절충을 결정해야 합니다. 챗봇과 같은 일부 애플리케이션에서는 빠른 응답을 위한 낮은 지연 시간이 최우선입니다. 구조화되지 않은 PDF를 일괄 처리하는 것과 같은 다른 애플리케이션에서는 개별 문서를 처리하는 지연 시간을 희생하여 모든 문서를 빠르게 병렬로 처리할 수 있습니다.
그림 7은 7B 모델의 처리량 대 지연 시간 곡선을 보여줍니다. 이 곡선의 각 선은 배치 크기를 1에서 256으로 늘려 얻은 것입니다. 이는 다양한 지연 시간 제약 조건 하에서 배치 크기를 얼마나 크게 만들 수 있는지 결정하는 데 유용합니다. 위에서 설명한 루프라인 플롯을 다시 살펴보면, 이러한 측정값이 예상과 일치함을 알 수 있습니다. 특정 배치 크기를 넘어서, 즉 컴퓨팅 바운드 영역으로 넘어가면, 배치 크기를 두 배로 늘릴 때마다 처리량은 증가하지 않고 지연 시간만 증가합니다.
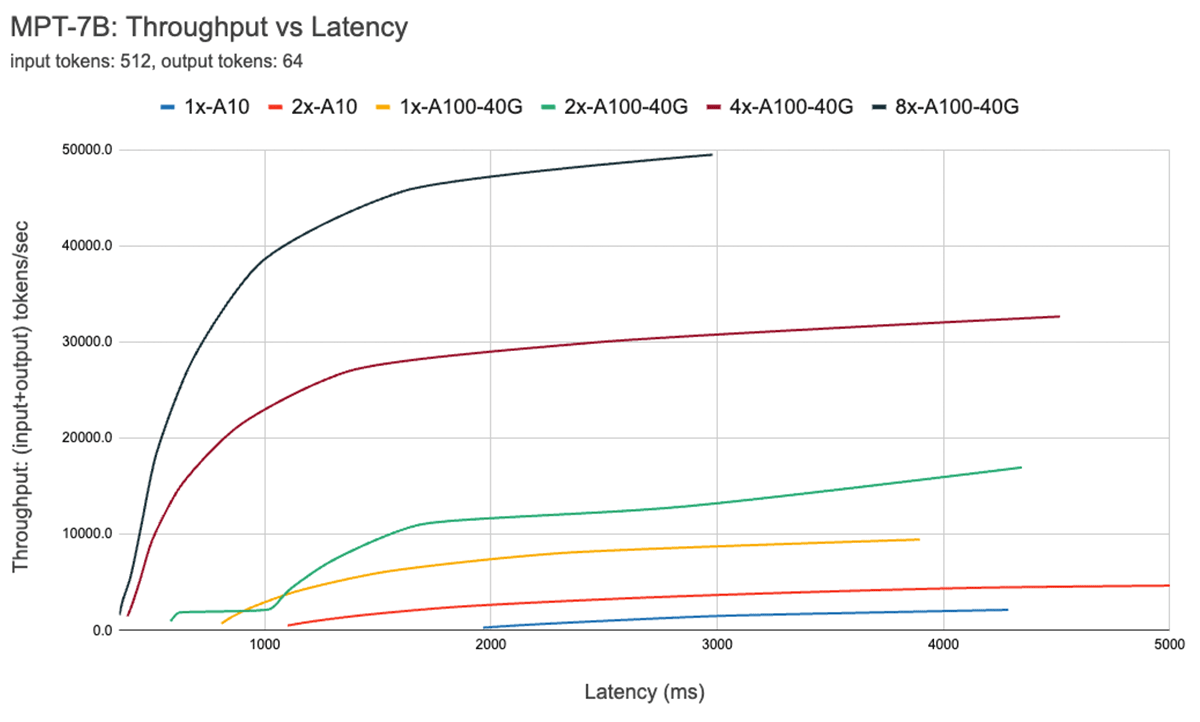
병렬 처리를 사용할 때는 저수준 하드웨어 세부 정보를 이해하는 것이 중요합니다. 예를 들어, 클라우드마다 8xA100 인스턴스가 모두 동일하지는 않습니다. 일부 서버는 모든 GPU 간에 고대역폭 연결을 가지고 있고, 다른 서버는 GPU를 쌍으로 묶어 쌍 간의 연결 대역폭이 낮습니다. 이는 병목 현상을 일으켜 실제 성능이 위 곡선과 크게 다를 수 있습니다.
최적화 사례 연구: 양자화
양자화는 LLM 추론에 필요한 하드웨어 요구 사항을 줄이는 데 사용되는 일반적인 기술입니다. 추론 중에 모델 가중치와 활성화의 정밀도를 낮추면 하드웨어 요구 사항을 ��크게 줄일 수 있습니다. 예를 들어, 16비트 가중치에서 8비트 가중치로 전환하면 메모리 제약 환경(예: A100의 Llama2-70B)에서 필요한 GPU 수를 절반으로 줄일 수 있습니다. 4비트 가중치로 낮추면 소비자 하드웨어(예: MacBooks의 Llama2-70B)에서 추론을 실행할 수 있습니다.
경험상 양자화는 신중하게 구현해야 합니다. 단순한 양자화 기법은 모델 품질을 상당히 저하시킬 수 있습니다. 양자화의 영향은 모델 아키텍처(예: MPT 대 Llama) 및 크기에 따라 다릅니다. 이에 대해서는 향후 블로그 게시물에서 더 자세히 다룰 것입니다.
양자화와 같은 기술을 실험할 때는 모델 자체의 품질뿐만 아니라 추론 시스템의 품질을 평가하기 위해 Mosaic Eval Gauntlet과 같은 LLM 품질 벤치마크를 사용하는 것이 좋습니다. 또한, 더 깊은 시스템 최적화를 탐색하는 것이 중요합니다. 특히 양자화는 KV 캐시를 훨씬 더 효율적으로 만들 수 있습니다.
앞서 언급했듯이, 자기회귀 토큰 생성 시, 어텐션 레이어의 이전 키/값(KV)은 매 단계마다 다시 계산하는 대신 캐시됩니다. KV 캐시의 크기는 한 번에 처리되는 시퀀스 수와 이 시퀀스의 길이에 따라 달라집니다. 또한, 다음 토큰 생성의 각 반복 중에 새로운 KV 항목이 기존 캐시에 추가되어 새 토큰이 생성됨에 따라 더 커집니다. 따라서 이러한 새 값을 추가할 때 효과적인 KV 캐시 메모리 관리는 좋은 추론 성능에 중요합니다. Llama2 모델은 그룹화된 쿼리 어텐션(GQA)이라는 어텐션 변형을 사용합니다. KV 헤드 수가 1�일 때 GQA는 다중 쿼리 어텐션(MQA)과 동일합니다. GQA는 키/값을 공유하여 KV 캐시 크기를 줄이는 데 도움이 됩니다. KV 캐시 크기를 계산하는 공식은 다음과 같습니다.
batch_size * seqlen * (d_model/n_heads) * n_layers * 2 (K 및 V) * 2 (Float16당 바이트) * n_kv_heads
표 3은 시퀀스 길이 1024 토큰에서 다양한 배치 크기로 계산된 GQA KV 캐시 크기를 보여줍니다. 이에 비해 Llama2 모델의 매개변수 크기는 70B 모델의 경우 140GB(Float16)입니다. KV 캐시의 양자화는 (GQA/MQA 외에) KV 캐시 크기를 줄이는 또 다른 기술이며, 생성 품질에 미치는 영향을 적극적으로 평가하고 있습니다.
| 배치 크기 | GQA KV 캐시 메모리 (FP16) | GQA KV 캐시 메모리 (Int8) |
|---|---|---|
| 1 | .312 GiB | .156 GiB |
| 16 | 5 GiB | 2.5 GiB |
| 32 | 10 GiB | 5 GiB |
| 64 | 20 GiB | 10 GiB |
표 3: 시퀀스 길이 1024에서 Llama-2-70B의 KV 캐시 크기
앞서 언급했듯이, 낮은 배치 크기에서 LLM을 사용한 토큰 생성은 GPU 메모리 대역폭 제한 문제, 즉 생성 속도가 모델 매개변수를 GPU 메모리에서 온칩 캐시로 얼마나 빨리 이동할 수 있는지에 따라 달라집니다. 모델 가중치를 FP16(2바이트)에서 INT8(1바이트) 또는 INT4(0.5바이트)로 변환하면 더 적은 데이터를 이동하므로 토큰 생성이 빨라��집니다. 그러나 양자화는 모델 생성 품질에 부정적인 영향을 미칠 수 있습니다. 현재 Model Gauntlet을 사용하여 모델 품질에 미치는 영향을 평가 중이며 곧 후속 블로그 게시물에서 이를 게시할 예정입니다.
결론 및 주요 결과
앞서 설명한 각 요인은 모델을 구축하고 배포하는 방식에 영향을 미칩니다. 이러한 결과를 사용하여 하드웨어 유형, 소프트웨어 스택, 모델 아키텍처 및 일반적인 사용 패턴을 고려한 데이터 기반 결정을 내립니다. 다음은 저희 경험에서 얻은 몇 가지 권장 사항입니다.
최적화 대상 식별: 대화형 성능이 중요하신가요? 처리량 극대화? 비용 최소화? 여기에는 예측 가능한 절충이 있습니다.
지연 시간 구성 요소에 주의: 대화형 애플리케이션의 경우 첫 번째 토큰까지의 시간(time-to-first-token)이 서비스의 응답성을 결정하고 출력 토큰당 시간(time-per-output-token)이 응답 속도를 결정합니다.
메모리 대역폭이 핵심: 첫 번째 토큰 생성은 일반적으로 컴퓨팅 바운드인 반면, 후속 디코딩은 메모리 바운드 작업입니다. LLM 추론은 종종 메모리 바운드 설정에서 작동하므로 MBU는 최적화하기 유용한 지표이며 추론 시스템의 효율성을 비교하는 데 사용할 수 있습니다.
배치가 중요합니다: 높은 처리량과 비싼 GPU를 효과적으로 활용하려면 여러 요청을 동시에 처리하는 것이 중요합니다. 공유 온라인 서비스의 경우 연속 배치가 필수적이지만, 오프라인 일괄 추론 워크로드는 더 간단한 배치 기술로 높은 처리량을 달성할 수 있습니다.
심층 최적화: 연산자 융합, 가중치 양자화와 같은 표준 추론 최적화 기술은 LLM에 중요하지만, 특��히 메모리 활용도를 개선하는 심층 시스템 최적화를 탐색하는 것이 중요합니다. 한 가지 예로 KV 캐시 양자화를 들 수 있습니다.
하드웨어 구성: 모델 유형과 예상 워크로드를 사용하여 배포 하드웨어를 결정해야 합니다. 예를 들어, 여러 GPU로 확장할 때 MPT-7B와 같은 더 작은 모델의 경우 Llama2-70B와 같은 더 큰 모델보다 MBU가 훨씬 빠르게 감소합니다. 성능은 또한 텐서 병렬화 정도가 높아질수록 부분적으로만 선형적으로 확장되는 경향이 있습니다. 그렇긴 하지만, 트래픽이 많거나 사용자가 추가적인 낮은 지연 시간에 대해 프리미엄을 지불하려는 경우 더 작은 모델에 대해 높은 수준의 텐서 병렬화가 여전히 유용할 수 있습니다.
데이터 기반 의사 결정: 이론을 이해하는 것이 중요하지만, 항상 종단 간 서버 성능을 측정하는 것이 좋습니다. 추론 배포가 예상보다 성능이 떨어지는 데에는 여러 가지 이유가 있습니다. 소프트웨어 비효율성으로 인해 MBU가 예상보다 낮을 수 있습니다. 또는 클라우드 제공업체 간의 하드웨어 차이로 인해 예상치 못한 결과가 발생할 수 있습니다(두 클라우드 제공업체의 8xA100 서버 간에 2배의 지연 시간 차이를 관찰했습니다).
LLM 추론을 시작하려면 Databricks Model Serving을 사용해 보세요. 자세한 내용은 설명서를 확인하세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금��하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.