오픈 레이크하우스의 차세대: Databricks의 Apache Iceberg™ v3 공개 미리 보기
완벽한 성능. 완벽한 상호 운용성. 절충 없음.
작성자: Ryan Blue, Daniel Weeks, 제이슨 리드, 벤자민 매튜 , Hao Jiang
• Unity Catalog는 Iceberg 생태계의 중앙 허브입니다. 팀에서 어떤 엔진이나 카탈로그를 사용하든 모든 도구가 일관되고 세분화된 거버넌스로 동일한 데이터에 액세스합니다.
• Iceberg v3는 Row Lineage, Deletion Vectors, VARIANT를 도입하여 고성�능 증분 처리 및 반정형 데이터 워크로드를 지원합니다.
• Iceberg v3는 성능과 상호 운용성의 절충점을 없앱니다. Deletion Vectors, Row Lineage, VARIANT는 개방형 사양의 일부이므로 데이터 팀은 엔진 호환성을 희생하지 않고 이러한 성능 향상을 얻을 수 있습니다.
오늘, Databricks의 Iceberg v3 지원이 Public Preview로 제공되어, 개방형 레이크하우스에서 최신 Iceberg 커뮤니티 혁신을 네이티브로 활용할 수 있게 됩니다.
Iceberg v3는 개방형 테이블 형식의 중요한 발전을 의미하며, 이전에는 불안정한 해결 방법이 필요했던 증분 데이터 처리 및 반정형 데이터 분석 전반에 걸쳐 사용 사례를 지원합니다. 또한 Iceberg v3는 Iceberg와 Delta Lake의 데이터 계층을 더욱 통합하여 상호 운용 가능한 파이프라인을 구축할 때 데이터를 다시 작성할 필요성을 제거하는 중요한 기술 혁신을 나타냅니다.
Iceberg v3의 새로운 기능, 그 중요성, 그리고 Databricks가 레이크하우스를 실행하기에 가장 좋은 장소인 이유를 소개합니다.
Iceberg v3의 새로운 기능은 무엇인가요?
Unity Catalog 관리형 Iceberg v3 테이블은 Row Lineage, Deletion Vectors, VARIANT를 지원하여 새로운 사용 사례와 상당한 성능 이점을 제공합니다. Databricks는 외부 Iceberg 테이블(다른 카탈로그에 등록된 Iceberg 테이블)에서도 이러한 기능을 상호 운용할 수 있어, 고객은 데이터의 위치에 관계없이 에��이전트 및 AI 애플리케이션을 데이터에 대해 구축할 수 있습니다.
대규모 증분 처리: Row Lineage 및 Deletion Vectors
대부분의 데이터는 배치보다는 변경 스트림(INSERT, UPDATE, MERGE, DELETE)으로 도착하며, 일반적으로 운영 데이터베이스, 이벤트 스트림 및 타사 API에서 소싱됩니다. 과거에는 이러한 변경 사항을 처리하기 위해 두 가지 어려운 문제를 해결해야 했습니다.
- Bronze 데이터 세트에서 변경된 행 식별
- Silver/Gold 데이터 세트에 이러한 변경 사항을 효율적으로 적용
팀은 일반적으로 변경 사항을 감지하기 위해 전체 테이블 스캔 또는 외부 CDC 시스템에 의존했으며, 이를 적용하기 위해 비용이 많이 드는 파일 다시 쓰기를 수행했습니다. 이로 인해 파이프라인이 느리고 유지 관리 비용이 많이 들며, 데이터 드리프트 및 사일로가 발생하기 쉬웠습니다.
이제 Row Lineage를 통해 팀은 변경된 행을 빠르게 식별할 수 있습니다. Iceberg v3 테이블의 모든 행에는 영구적인 row ID와 마지막으로 수정된 시점을 반영하는 시퀀스 번호가 포함됩니다.
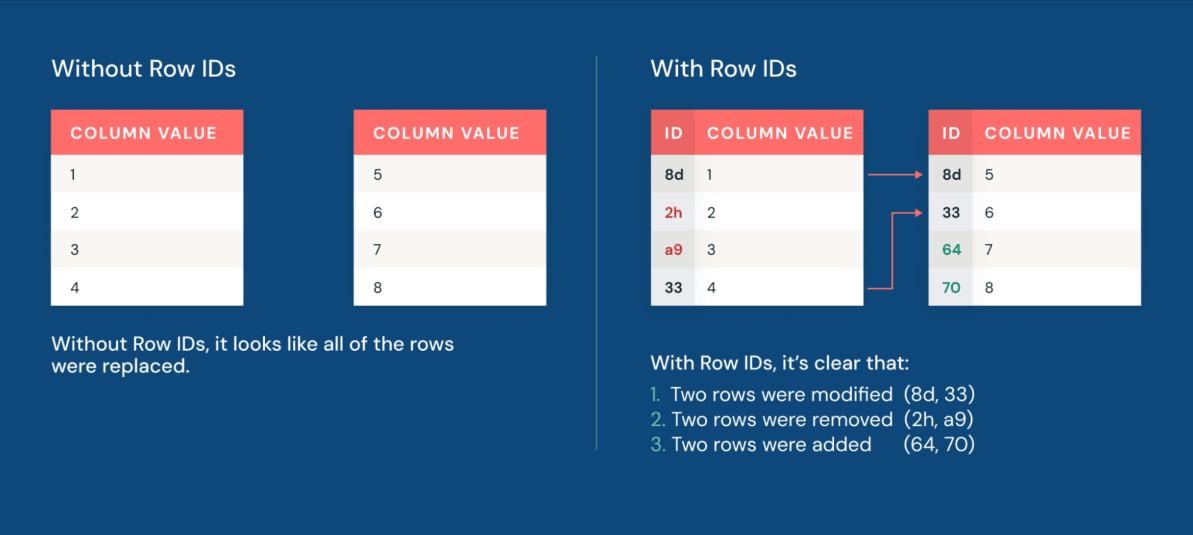
또한 Deletion Vectors는 데이터 세트에 변경 사항을 적용하는 것을 그 어느 때보다 효율적으로 만듭니다. Deletion Vectors를 사용하면 Iceberg는 기본 데이터 파일을 즉시 다시 작성하지 않고도 논리적으로 삭제된 행을 추적할 수 있습니다. 대규모 Parquet 파일을 다시 작성하여 행을 물리적으로 삭제하는 대신, 엔진은 데이터 옆에 경량 삭제 파일을 작성합니다. 결과적으로 데이터 조작 성능은 기존 복사 후 쓰기 방식보다 최대 10배 더 빠릅니다.

Deletion Vectors가 이제 Iceberg의 네이티브 기능이 되었으므로, Geodis는 성능이나 엔진 선택에 타협하지 않고 Databricks에서 Iceberg 레이크하우스를 구축할 수 있습니다.
“Deletion Vectors가 Iceberg에 도입됨에 따라 Unity Catalog에서 Iceberg 데이터 에스테이트를 중앙 집중화하면서도 원하는 엔진을 활용하고 최고 수준의 성능을 유지할 수 있습니다.” —Delio Amato, Chief Architect & Data Officer, Geodis
Row Lineage와 Deletion Vectors를 함께 사용하면 CDC가 테이블 자체의 네이티브 속성이 됩니다. 팀은 실제로 변경된 내용만 점진적으로 처리하는 데 중점을 둔 파이프라인을 구축하여 비용을 절감하고 모든 다운스트림 분석가 및 데이터 과학자에 대한 인사이트 도출 시간을 단축할 수 있습니다.

VARIANT를 통한 반정형 데이터의 최우선 처리
��로그, API 응답, 클릭스트림 및 IoT 페이로드는 매우 가치 있는 반정형 데이터 소스입니다. 이러한 데이터가 발전함에 따라 AI 모델은 변화하는 실제 신호에서 직접 학습하면서 함께 적응할 수 있습니다.
하지만 과거에는 데이터 팀이 반정형 데이터를 다룰 때 어려운 절충안에 직면했습니다. 한 가지 일반적인 접근 방식은 엄격한 스키마를 적용하는 것이었지만, 이는 업스트림 데이터가 변경될 때마다 중단되는 불안정한 파이프라인으로 이어졌습니다. 또 다른 일반적인 해결책은 데이터를 원시 문자열 덤프로 저장하는 것이었지만, 이는 쿼리를 매우 복잡하고 느리게 만들었습니다. 어느 쪽도 확장 가능하지 않았습니다.
Iceberg v3 VARIANT 유형은 이러한 절충안을 해결합니다. VARIANT는 동일한 Iceberg 테이블에서 관계형 열과 함께 반정형 페이로드를 저장하는 네이티브 열 유형입니다. 이는 플랫화, 별도 시스템에 저장 또는 정규화를 위한 ETL 파이프라인이 필요하지 않습니다. 오히려 데이터 팀은 반정형 데이터를 그대로 수집하고 표준 SQL로 쿼리할 수 있습니다.

Panther는 VARIANT를 사용하여 반정형 보안 로그 전반에 걸쳐 대규모 수집 및 분석을 지원합니다.
“Unity Catalog와 Iceberg v3는 VARIANT를 통해 반정형 데이터의 강력한 기능을 활용할 수 있게 합니다. 이를 통해 상호 운용성과 비용 효율적인 페타바이트 규모의 로그 수집이 가능합니다.” —Russell Leighton, Chief Architect, Panther
VARIANT를 사용하면 AI 모델과 분석 파이프라인이 단일 거버넌스 테이블에서 실시간으로 변화하는 데이터에 직접 작동합니다. API 응답에 새 필드가 나타나거나 클릭스트림에 새 이벤트 유형이 들어오면 스키마 마이그레이션 없이 즉시 쿼리할 수 있습니다. Shredding과 같은 성능 최적화를 통해 고객은 반정형 데이터에 대한 컬럼과 유사한 성능을 활용하여 저지연 BI, 대시보드 및 경고 파이프라인을 활성화할 수 있습니다.
Unity Catalog는 다중 엔진, 다중 카탈로그 엔터프라이즈를 위한 상호 운용성 및 성능을 제공합니다.
현대 기업은 비즈니스 단위 및 레거시 시스템 전반에 걸쳐 다양한 사용 사례를 지원하기 위해 여러 엔진과 카탈로그에 의존합니다. Unity Catalog는 카탈로그 간의 상호 운용성 및 거버넌스를 지원하고 쿼리 패턴에 따라 데이터 레이아웃을 최적화하도록 설계되었습니다.
카탈로그 및 엔진 전반의 통합 거버넌스
Unity Catalog의 개방형 API를 통해 고객은 한 번 작성하고 어디서든 읽을 수 있습니다. 더 이상 데이터 중복이나 사일로화된 액세스 제어가 필요 없습니다. UC는 다른 Iceberg 카탈로그로 페더레이션할 수 있어 양방향 상호 운용성을 지원합니다. Snowflake, AWS Glue, Salesforce 및 기타 주요 카탈로그의 모든 Iceberg 데이터는 Unity Catalog�에서 읽을 수 있으며, UC의 모든 데이터는 개방형 API를 통해 해당 타사 플랫폼에서 액세스할 수 있습니다.
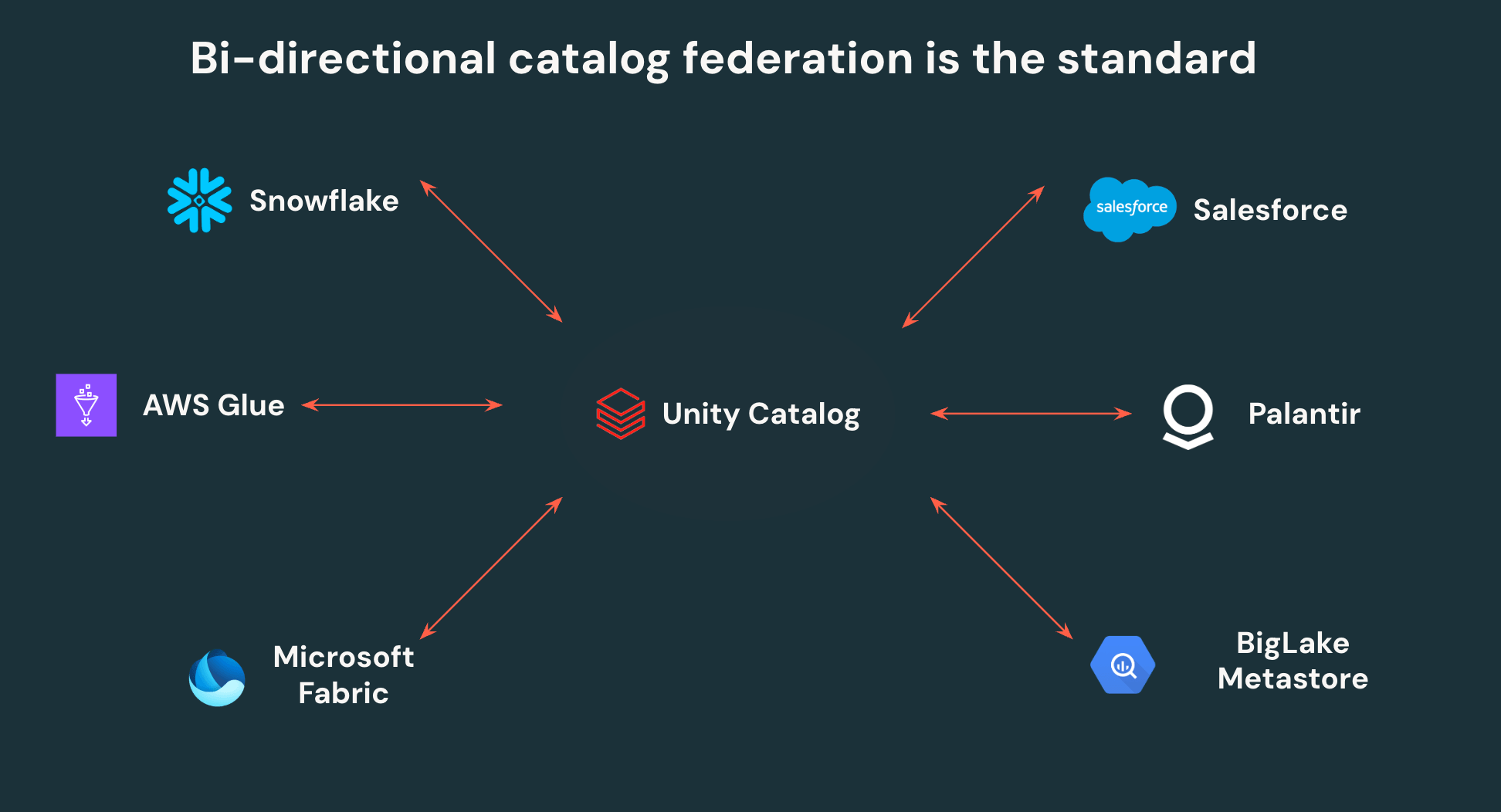
또한 Unity Catalog는 외부 엔진에 대한 세분화된 액세스 제어를 지원하는 최초의 카탈로그로, 팀이 행 필터 및 열 마스크를 한 번 정의하고 데이터 액세스 시 모든 곳에서 적용할 수 있도록 지원합니다. Unity Catalog에서 거버넌스를 중앙 집중화하면 보안 팀이 레이크하우스를 거버넌스하고 모니터링하기가 훨씬 쉬워지며, 데이터 팀은 모든 도구를 레이크하우스에 연결할 수 있는 자율성을 갖게 됩니다.

Delta 및 Iceberg 상호 운용성
UniForm을 사용한 Delta Lake는 고객의 Delta Lake 및 Iceberg 생태계 전반에 걸쳐 상호 운용성을 지원합니다. Delta Lake에 한 번 쓰면 Snowflake, BigQuery, Redshift, Athena, Trino 또는 기타 Iceberg 엔진에서 Iceberg로 읽을 수 있습니다. Iceberg v3가 Deletion Vectors, Row Lineage 및 VARIANT를 네이티브로 채택함에 따라 고객은 더 이상 Delta Lake 성능 기능과 Iceberg 호환성 간의 절충안에 직면하지 않습니다. 결과적으로 스택의 모든 엔진에 서비스를 제공하는 단일 데이터 복사본이 생성되며, 유지 관리할 복제 파이프라인이 없거나 드리프트 위험이 없습니다. ��선도적인 금융 서비스 제공업체는 비용이 많이 드는 전체 테이블 복제 서비스를 UniForm으로 교체하여 Snowflake가 Unity Catalog 관리 테이블에서 직접 읽을 수 있도록 했습니다.
자동화된 성능 및 최적화
Databricks는 상호 운용성을 넘어 성능, 레이아웃 최적화 및 거버넌스를 단일 시스템으로 통합하여 팀이 이러한 기능을 직접 통합할 필요가 없도록 합니다. Databricks는 지능형 유지 관리(Predictive Optimization), 쿼리 패턴 기반의 물리적 레이아웃 최적화(Automatic Liquid Clustering), 그리고 엔진 간 거버넌스(Unity Catalog)를 수동 구성 없이 한 계층에서 결합합니다.
다른 관리형 Iceberg 제품은 팀이 테이블 유지 관리, 파일 레이아웃 및 액세스 정책 적용을 독립적으로 관리해야 합니다. Databricks에서는 이러한 기능이 통합되고 자동화되어 운영 오버헤드를 제거하는 동시에 데이터 이식성을 완전히 보존합니다.
Databricks에서 Apache Iceberg v3 시작하기
Iceberg v3는 현재 Databricks에서 공개 미리 보기로 제공됩니다! 이제 팀은 성능이나 상호 운용성 저하 없이 Delta와 Iceberg의 최상의 기능을 활용할 수 있습니다.
Iceberg v3는 Unity Catalog가 활성화된 Databricks Runtime 18.0 이상에서 사용할 ��수 있습니다.
v3가 활성화된 Unity Catalog 관리 Iceberg 테이블을 만드는 것은 쉽습니다.
UniForm 및 v3가 활성화된 Unity Catalog 관리 Delta 테이블을 만드는 것도 마찬가지로 간단합니다.
향후 전망: Iceberg v4
Iceberg v3는 성능과 상호 운용성이 뛰어난 기반 위에서 Delta와 Iceberg 간의 데이터 계층을 통합합니다. 다음 개척지는 메타데이터 계층입니다. Databricks 엔지니어는 메타데이터를 더 간단하고 빠르며 확장 가능하게 만들기 위해 Apache 커뮤니티에서 여러 핵심 Iceberg v4 제안을 적극적으로 추진하고 있습니다. 여기에는 메타데이터 구조를 단순화하여 대부분의 작업에서 여러 파일 대신 단일 파일만 쓰면 되도록 하는 적응형 메타데이터 트리가 포함됩니다. 추가 제안에는 원활한 테이블 이전을 위한 상대 경로 지원 및 VARIANT 및 GEOMETRY와 같은 최신 데이터 형식으로 확장되는 현대화된 통계 모델이 포함됩니다. 이러한 발전은 함께 엔터프라이즈 규모에서 더 빠른 수집, 더 효율적인 쿼리 계획 및 더 간단한 테이블 관리를 의미할 것입니다. 커뮤니티와 함께 Iceberg 사양을 계속 발전시키기를 기대합니다.
Data and AI Summit에서 자세히 알아보기
Iceberg v3로 시작하고 2026년 6월 15-18일 샌프란시스코에서 열리는 다가오는 Data and AI Summit에 참여하여 Iceberg 로드맵 및 생태계 전반의 작업에 대해 자세히 알아보세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.