머티리얼라이즈드 뷰 최적화 재계산
작성자: 안드레아 타르디프 , Justin Edrington
- Lakeflow 선언적 파이프라인에서 머티리얼라이즈드 뷰 (MV) 새로 고침 행동을 감지하고 모니터링하는 방법
- MV에서 불필요한 전체 재계산의 일반적인 원인
- 성능 향상과 비용 통제를 위해 증분 새로 고침을 최적화하고 전체 재계산을 관리하는 모범 사례
머티리얼라이즈드 뷰의 증분 계산 최적화
디지털 기반의 회사들이 AI가 혁신을 주도하는 중요한 역할을 인식하고 있지만, 많은 회사들이 여전히 ETL 파이프라인을 운영적으로 효율적으로 만드는 데 어려움을 겪고 있습니다.
머티리얼라이즈드 뷰(MVs) 는 관리 테이블로 사전 계산된 쿼리 결과를 저장하여, 사용자가 동일한 쿼리를 반복적으로 계산하는 것을 피하면서 복잡하거나 자주 사용되는 데이터에 훨씬 빠르게 접근할 수 있게 해줍니다. MVs는 쿼리 성능을 향상시키고, 계산 비용을 줄이며, 변환 과정을 단순화합니다.
Lakeflow 선언적 파이프라인 (LDP)은 데이터 파이프라인을 구축하는데 있어 직관적이고 선언적인 접근법을 제공하며, MV에 대한 전체 및 증분 새로고침을 모두 지원합니다. Databricks 파이프라인은 Enzyme 엔진에 의해 구동되며, 이 엔진은 새로운 데이터가 쿼리 결과에 어떻게 영향을 미치는지 추적하고 필요한 부분만 업데이트하여 MV를 효율적으로 최신 상태�로 유지합니다. 다양한 기법 중에서 선택하기 위해 내부 비용 모델을 활용하며, 이에는 물리화 뷰와 수동 ETL 패턴이 일반적으로 사용됩니다.
이 블로그에서는 예상치 못한 전체 재계산을 감지하고 적절한 증분 MV 새로 고침을 위해 파이프라인을 최적화하는 방법에 대해 논의할 것입니다.
주요 아키텍처 고려사항
증분 및 전체 새로 고침에 대한 시나리오
전체 재계산은 소스로부터 모든 가능한 데이터를 재처리하여 MV의 결과를 덮어씁니다. 이는 전체 기본 데이터 세트를 재처리해야 하므로, 변경된 부분이 작더라도 비용이 많이 들고 시간이 많이 소요될 수 있습니다.
증분 새로 고침이 일반적으로 효율성을 위해 선호되지만, 전체 새로 고침이 더 적합한 상황이 있습니다. 우리의 비용 모델은 다음과 같은 고수준 가이드라인을 따릅니다:
- 전체 새로 고침을 사용하십시오 특히 기록이 삭제되거나 수정되었을 때, 비용 모델이 증분 변경을 효율적으로 계산하고 적용할 수 있는 경우, 기본 데이터에 큰 변화가 있을 때 사용합니다.
- 소스 테이블이 자주 업데이트되고 변경사항이 상대적으로 적을 때 증분 새로고침을 사용하세요—이 방법은 컴퓨팅 비용을 줄이는 데 도움이 됩니다.
Enzyme Compute Engine
새로운 데이터가 도착하거나 변경이 발생할 때마다 전체 테이블이나 뷰를 처음부터 다시 계산하는 대신, Enzyme은 새로운 데이터나 변경된 데이터만을 지능적으로 판단하고 처리합니다. 이 방법은 전통적인 배치 ETL 방법에 비해 리소스 소비와 지연 시간을 크게 줄입니다.
아래 다이어그램은 Enzyme 엔진이 머티리얼라이즈드 뷰를 업데이트하는 최적의 방법을 어떻게 지능적으로 결정하는지를 설명합니다.
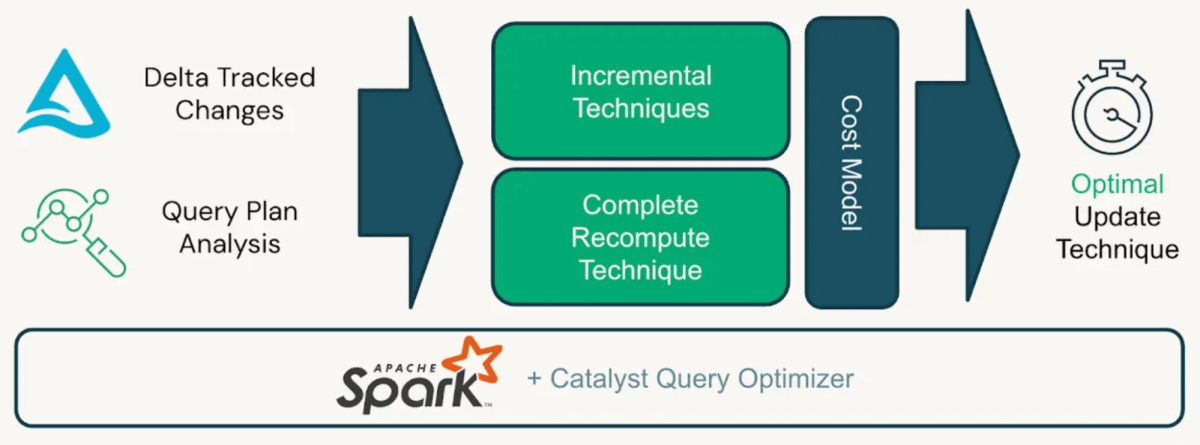
Enzyme 엔진은 내부 비용 모델에 기반하여 업데이트 전략을 선택하고, 성능과 계산 효율성을 최적화하기 위해 증분 또는 전체 새로 고침을 수행할지 결정합니다.
델타 테이블 기능 활성화
소스 테이블에서 행 추적 을 활성화하는 것은 MV 재계산을 증분화하는 데 필요합니다.
행 추적은 마지막 MV 새로 고침 이후 어떤 행이 변경되었는지 감지하는 데 도움이 됩니다. 이것은 Databricks가 Delta 테이블에서 행 수준의 계보를 추적하게 하며, 물리화 된 뷰에 대한 특정 증분 업데이트에 필요합니다.
삭제 벡터 활성화는 선택적 기능입니다. 삭제 벡터를 사용하면 Databricks가 원본 테이블에서 삭제된 행을 추적할 수 있습니다. 이를 통해 전체 파일을 다시 작성할 필요를 없애고, 몇 개의 행만 삭제될 때 전체 파일을 다시 작성하는 것을 피할 수 있습니다.
이러한 테이블 기능을 원본 테이블에서 활성화하려면 다음 SQL 코드를 활용하십시오:
기술 솔루션 분석
다음 섹션에서는 파이프라인이 전체 재계산을 트리거하는지 아니면 MV에서 증분 새로 고침을 트리거하는지 감지하는 방법과 증분 새로 고침을 장려하는 방법에 대한 예를 살펴볼 것입니다.
이 기술적인 안내서는 다음과 같은 고수준의 단계를 따릅니다:
- 무작위로 생성된 데이터로 델타 테이블 생성
- LDP 를 생성하고 사용하여 머티리얼라이즈드 뷰를 생성합니다
- 머티리얼라이즈드 뷰에 비결정적 함수 추가
- 파이프라인을 다시 실행하고 새로 고침 동작에 미치는 영향을 관찰합니다
- 파이프라인을 업데이트하여 증분 새로 고침 복원
- 새로 고침 기법을 검사하기 위해 파이프라인 이벤트 로그를 쿼리합니다
이 예제를 따라가려면 이 스크립트를 복제하십시오: MV_Incremental_Technical_Breakdown.ipynb
run_mv_refresh_demo() 함수 내에서 첫 번째 단계는 무작위로 생성된 데이터로 Delta 테이블을 생성합니다:
다음으로, 무작위로 생성된 데이터를 삽입하기 위해 다음 함수가 실행됩니다. 이는 새로운 레코드가 집계 가능하도록 보장하기 위해 각 새 파이프라인 실행 전에 실행됩니다.
그런 다음, Databricks SDK 가 LDP를 생성하고 배포하는 데 사용됩니다.
MVs는 서버리스 LDP 또는 Databricks SQL (DBSQL)을 통해 생성될 수 있으며, 동일하게 작동합�니다. DBSQL MVs 는 MV 아래에 결합된 관리 서버리스 LDP를 시작합니다. 이 예제는 이벤트 로그를 게시하는 등의 다양한 기능을 활용하기 위해 서버리스 LDP를 사용하지만, DBSQL MV를 사용해도 동일하게 작동할 것입니다.
파이프라인이 성공적으로 생성되면, 함수는 파이프라인에 업데이트를 실행할 것입니다:
파이프라인이 성공적으로 실행되고 초기 머티리얼라이즈드 뷰를 생성한 후, 다음 단계는 더 많은 데이터를 추가하고 뷰를 새로 고침하는 것입니다. 파이프라인을 실행한 후, 이벤트 로그를 확인하여 새로 고침 동작을 검토합니다.
결과는 GROUP_AGGREGATE 메시지에 의해 표시된 것처럼 머티리얼라이즈드 뷰가 증분 새로 고침되었음을 보여줍니다:
| 실행 # | 메시지 | 흐름 유형 |
|---|---|---|
| 2 | 흐름 '<catalog_name>.demo.random_data_mv' DLT에서 GROUP_AGGREGATE로 실행될 계획이 세워졌습니다. | 비결정적 함수 없음. 증분 새로 고침됨. |
| 1개 | 플로우 '<catalog_name>.demo.random_data_mv' COMPLETE_RECOMPUTE로 실행될 예정으로 DLT에 계획되었습니다. | 초기 실행. 전체 다시 compute |
다음으로, 비결정적 함수(RANDOM())를 추가하는 것이 물리화 뷰가 증분 새로 고침을 방해하는 방법을 보여주기 위해, MV는 다음과 같��이 업데이트됩니다:
MV의 변경사항을 고려하고 비결정적 함수를 보여주기 위해, 파이프라인은 두 번 실행되고, 데이터가 추가됩니다. 그런 다음 이벤트 로그가 다시 쿼리되고, 결과는 전체 재계산을 보여줍니다.
| 실행 # | 메시지 | 설명 |
|---|---|---|
| 4 | 플로우 'andrea_tardif.demo.random_data_mv' DLT에서 COMPLETE_RECOMPUTE로 실행될 계획이 세워졌습니다. | MV에는 비결정적인 요소가 포함되어 있습니다 — 전체 재계산이 트리거됩니다. |
| 3 | 플로우 '<catalog_name>.demo.random_data_mv' COMPLETE_RECOMPUTE로 실행될 예정으로 DLT에 계획되었습니다. | MV 정의 변경 — 전체 재계산이 트리거됩니다. |
| 2 | 흐름 '<catalog_name>.demo.random_data_mv' DLT에서 GROUP_AGGREGATE로 실행될 계획이 세워졌습니다. | 증분 새로 고침 — 비결정적 함수가 없습니다. |
| 1개 | 플로우 '<catalog_name>.demo.random_data_mv' COMPLETE_RECOMPUTE로 실행될 예정으로 DLT에 계획되었습니다. | 초기 실행 — 전체 재계산이 필요합니다. |
RANDOM() 또는 CURRENT_DATE()와 같은 비결정적 함수를 추가함으로써, MV는 소스 데이터의 변경에만 기반을 둔 결과를 예측할 수 없기 때문에 증분 새로 고침을 할 수 없습니다.
파이프라인 이벤트 로그 세부 정보 내에서, planning_information, 아래의 JSON 이벤트 세부 정보는 증분화를 방�지하는 다음과 같은 이유를 제공합니다:
비결정적 함수가 분석에 필요한 경우, 머티리얼라이즈드 뷰에서 동적으로 계산하는 것보다 원본 테이블 자체에 그 값을 넣는 것이 더 좋은 접근 방식입니다. 이를 위해 random_number 열을 MV 수준에서 추가하는 대신 원본 테이블에서 가져오도록 이동시킵니다.
아래는 MV 내의 정적 random_number 열을 참조하기 위한 업데이트된 머티리얼라이즈드 뷰 쿼리입니다:
새로운 데이터가 추가되고 파이프라인이 다시 실행되면, 이벤트 로그를 쿼리하세요. 출력 결과는 MV가 COMPLETE_RECOMPUTE 대신 GROUP_AGGREGATE를 수행했음을 보여줍니다!
| 실행 # | 메시지 | 설명 |
|---|---|---|
| 5 | 흐름 '<catalog_name>.demo.random_data_mv' DLT에서 GROUP_AGGREGATE로 실행될 계획이 세워졌습니다. | MV는 결정적 로직을 사용합니다 — 증분 새로 고침. |
| 4 | 플로우 '<catalog_name>.demo.random_data_mv' COMPLETE_RECOMPUTE로 실행될 예정으로 DLT에 계획되었습니다. | MV에는 비결정적인 요소가 포함되어 있습니다 — 전체 재계산이 트리거됩니다. |
| 3 | 플로우 '<catalog_name>.demo.random_data_mv' COMPLETE_RECOMPUTE로 실행될 예정으로 DLT에 계획되었습니다. | MV 정의 변경 — 전체 재계산이 트리거됩니다. |
| 2 | 흐름 '<catalog_name>.demo.random_data_mv' DLT에서 GROUP_AGGREGATE로 실행될 계�획이 세워졌습니다. | 증분 새로 고침 — 비결정적 함수가 없습니다. |
| 1개 | 플로우 '<catalog_name>.demo.random_data_mv' COMPLETE_RECOMPUTE로 실행될 예정으로 DLT에 계획되었습니다. | 초기 실행 — 전체 재계산이 필요합니다. |
다음 조건에서 파이프라인에 의해 전체 새로 고침이 자동으로 트리거 될 수 있습니다:
- UUID()와 RANDOM()과 같은 비결정적 함수 의 사용
- 크로스, 전체 외부, 반, 반대, 그리고 많은 수의 조인과 같은 복잡한 조인을 포함하는 머티리얼라이즈드 뷰를 생성합니다.
- Enzyme 은 전체 재계산을 수행하는 것이 계산 비용이 덜 든다고 판단합니다
증분 새로고침 호환 함수에 대해 더 알아보려면 여기를 클릭하세요.
실제 데이터 볼륨
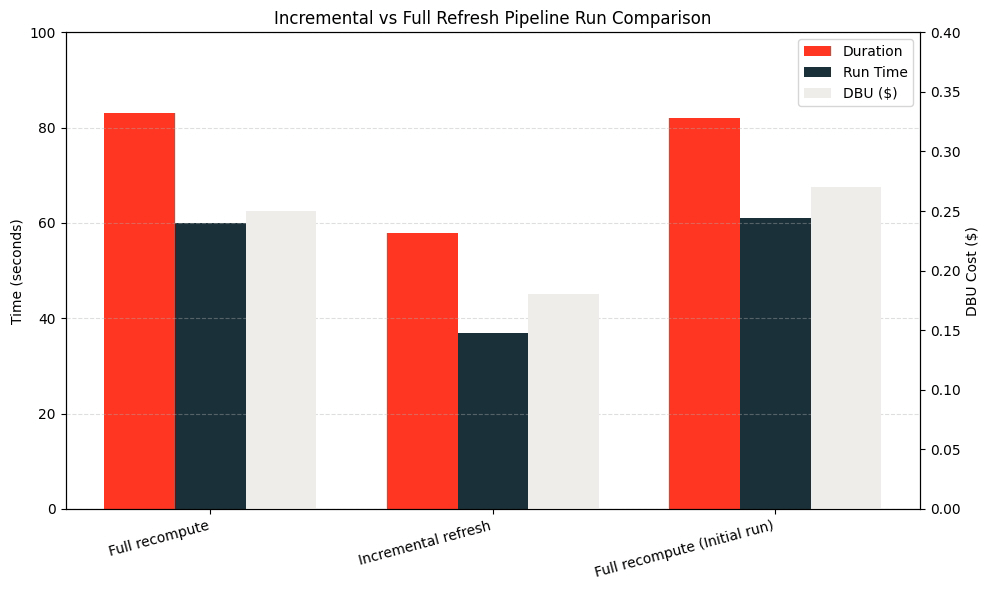
대부분의 경우, 데이터 수집은 5행을 삽입하는 것보다 훨씬 큽니다. 이를 설명하기 위해, 초기 로드에 10억 행을 삽입하고 각 파이프라인 실행에 1000만 행을 삽입해 봅시다.
dbldatagen 을 사용하여 데이터를 무작위로 생성하고 Databricks SDK 를 사용하여 LDP를 생성하고 실행하여, 소스 테이블에 10억 행이 삽입되었고, 파이프라인이 실행되어 MV가 생성되었습니다. 그런 다음, 원본 데이터에 1000만 행이 추가되었고, MV는 증분 새로 고침되었습니다. 그 후, 파이프라인은 강제 새로 고침되어 전체 재계산을 수행하였습니다.
파이프라인이 완료되면, list_pipeline_events 와 청구 시스템 테이블을 dlt_update_id에 병합하여 업데이트 별 비용을 결정합니다.
아래 그래프에서 볼 수 있듯이, 증분 새로 고침은 전체 새로 고침보다 두 배 빠르고 저렴했습니다!
운영 고려사항
강력한 모니터링, 관찰 가능성, 자동화 실천은 선언적 파이프라인에서 증분 새로 고침의 이점을 완전히 실현하는 데 중요합니다. 다음 섹션에서는 Databricks의 모니터링 기능을 활용하여 파이프라인 새로 고침과 비용을 추적하는 방법을 설명합니다.
파이프라인 새로고침 모니터링
이벤트 로그 와 LDP UI 인터페이스 와 같은 도구들은 파이프라인 실행 패턴을 볼 수 있게 해주어, 다양한 새로 고침이 언제 발생하는지 감지하는 데 도움을 줍니다.
우리는 팀이 머티리얼라이즈드 뷰 새로 고침 행동을 추적하고 분석하는 데 도움이 되는 가속 도구 를 포함했습니다. 이 솔루션은 AI/BI 대시보드를 활용하여 새로 고침 패턴에 대한 가시성을 제공합니다. 이것은 Databricks SDK 를 사용하여 설정된 작업 공간에서 모든 파이프라인을 검색하고, 파이프라인에 대한 이벤트 세부 정보를 수집한 다음, 아래와 유사한 대시보드를 생성합니다.
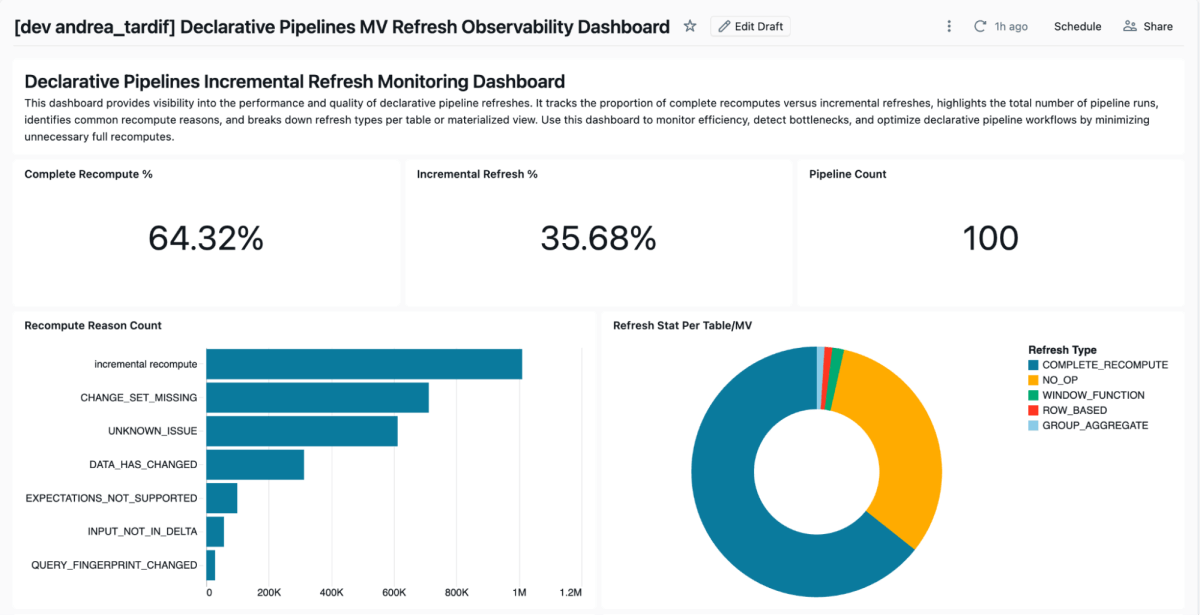
Github 링크: monitoring-declarative-pipeline-refresh-behavior
주요 학습 내용
머티리얼 뷰 새로 고침을 증분화하면 Databricks가 원본 테이블의 새로운 또는 변경된 데이터만 처리할 수 있어, 성능을 향상시키고 비용을 줄일 수 있습니다.
MVs에서는, 비결정적 함수 사용을 피하십시오 (즉, CURRENT_DATE() 및 RANDOM()) 및 쿼리 복잡성을 제한하십시오 (즉, 과도한 조인) 증분 새로 고침을 효율적으로 가능하게 하기 위해. 증분 재계산으로 리팩토링 될 수 있는 MV에서 예상치 못한 전체 재계산을 무시하면 다음과 같은 결과를 초래할 수 있습니다:
- 컴퓨팅 비용 증가
- 데이터 신선도가 느린 ��하류 애플리케이션
- 데이터 볼륨이 확장됨에 따른 파이프라인 병목 현상
서버리스 컴퓨트를 이용하여, LDP는 내장된 실행 모델을 활용하여 전체 파이프라인 계산 비용에 따라 증분 또는 전체 재계산을 수행할 수 있게 해주는 Enzyme을 사용합니다.
가속기 도구 를 활용하여 AI/BI 대시보드에서 모든 파이프라인의 동작을 모니터링하고 예상치 못한 전체 재계산을 감지합니다.
결론적으로, 효율적인 머티리얼라이즈드 뷰 새로 고침을 생성하기 위해 다음의 모범 사례를 따르세요:
- 가능한 경우 결정적 로직 을 사용하세요.
- 비결정적 함수를 피하기 위해쿼리를 리팩토링합니다
- 조인 로직을 단순화합니다
- 소스 테이블에서 행 추적 을 활성화하세요
다음 단계 및 추가 자원
오늘 당신의 MV 새로 고침 유형을 검토해보세요!
Databricks Delivery Solutions Architects (DSAs)는 조직 전반의 데이터 및 AI 이니셔티브를 가속화합니다. 그들은 건축적인 리더십을 제공하며, 비용과 성능에 대한 플랫폼을 최적화하고, 개발자 경험을 향상시키며, 프로젝트의 성공적인 실행을 주도합니다. DSAs는 초기 배포와 생산 수준 솔루션 사이의 간극을 메우며, 데이터 엔지니어링, 기술 리드, 임원, 그리고 다른 이해관계자를 포함한 다양한 팀과 긴밀하게 협력하여 맞춤형 솔루션과 빠른 가치 창출을 보장합니다. 맞춤형 실행 �계획, 전략적 지침, 그리고 데이터 및 AI 여정에서의 지원을 위해 DSA를 이용하려면 Databricks 계정 팀에게 문의하십시오.
기타 리소스
LDP를 생성하고 오늘 MV 증분 새로 고침 유형을 검토하세요!
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.