PySpark UDF 통합 프로파일링
통합 프로파일링을 통한 PySpark UDF 최적화: 향상된 성능 및 메모리 인사이트
작성자: Xinrong Meng , Takuya Ueshin
- PySpark UDF 통합 프로파일링 소개 - Databricks Runtime 17.0에서 UDFs의 성능 및 메모리 프로파일링이 실행 및 리소스 사용 최적화에 어떻게 도움이 되는지 알아보세요.
- 성능 향상 및 디버깅 강화 - 함수 호출, 실행 시간, 메모리 소비를 추적하여 병목 현상을 식별하고 효율성을 향상시키는 방법을 탐색합니다.
- 통합 접근법으로 레거시 프로파일링 교체 - 새로운 SparkSession 기반 프로파일링의 이점, Spark Connect와의 호환성, 그리고 프로파일링 결과를 활성화, 시각화, 관리하는 방법을 이해하세요.
Databricks Runtime 17.0의 일부로 PySpark 사용자 정의 함수 (UDFs)에 대한 통합 프로파일링을 출시하게 되어 기쁩니다 (릴리스 노트). PySpark UDFs에 대한 통합 프로파일링은 개발자가 PySpark UDFs의 성능과 메모리 사용량을 프로파일링 할 수 있게 해줍니다. 이에는 함수 호출, 실행 시간, 메모리 사용량, 그 외의 메트릭 추적이 포함됩니다. 이를 통해 PySpark 개발자들은 병목 현상을 쉽게 식별하고 해결할 수 있어, 더 빠르고 자원 효율적인 UDF를 구현할 수 있습니다.
통합 프로파일러는 Runtime SQL 구성 “spark.sql.pyspark.udf.profiler”을 “perf” 또는 “memory”로 설정하여 성능 또는 메모리 프로파일러를 활성화할 수 있습니다. 아래에 그 방법이 나와 있습니다.
레거시 프로파일링 대체
레거시 프로파일링 [1, 2]은 SparkContext 수준에서 구현되었으므로, Spark Connect와 함께 작동하지 않았습니다. 새로운 프로파일링은 SparkSession 기반으로, Spark Connect에 적용되며 런타임에 활성화 또는 비활성화할 수 있습니다. 프로파일 결과를 시각화하고 작업공간 폴더에 저장하기 위한 “show”와 “dump” 명령을 제공함으로써 레거시 프로파일링과의 API 일치성을 극대화합니다. 또한, 필요에 따라 프로파일 결과를 관리하고 재설정하는 데 도움이 되는 편리한 API를 제공합니다. 마지막으로, 레거시 프로파일링에서 지원하지 않았던 등록된 UDF를 지원합니다.
PySpark 성능 프로파일러
PySpark 성능 프로파일러는 Python의 내장 프로파일러를 활용하여 드라이버와 분산 방식으로 실행되는 UDFs에 프로파일링 기능을 확장합니다.
PySpark 성능 프로파일러의 작동을 보기 위해 예제를 살펴보겠습니다. 다음 코드를 Databricks Runtime 17.0 노트북에서 실행합니다.
added.show() 명령은 아래와 같이 성능 프로파일링 결과를 표시합니다.
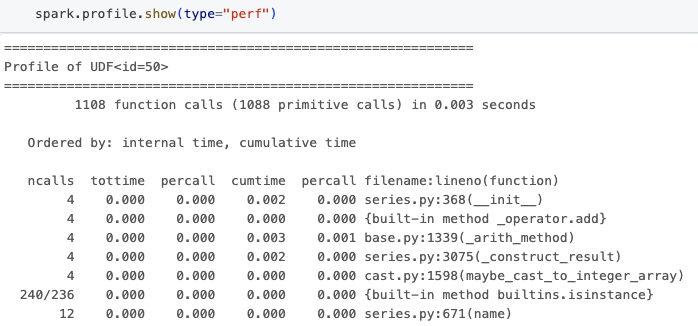
출력에는 함수 호출 횟수, 주어진 함수에서 소비��한 총 시간, 파일 이름 등의 정보가 포함되어 있어, 이를 통해 탐색을 돕습니다. 이 정보는 PySpark 프로그램에서 타이트 루프를 식별하고 성능을 향상시키기 위한 결정을 내리는 데 필수적입니다.
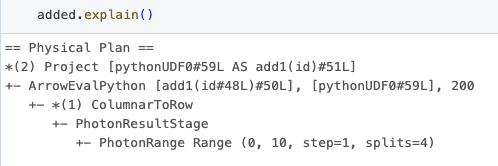
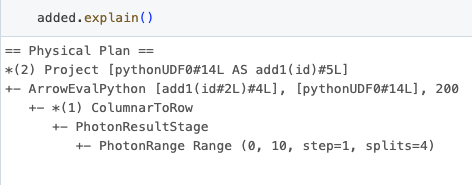
이 결과에서 UDF id는 Spark 계획에서 찾은 것과 직접 연관되어 있음을 주목해야 합니다. 이는 데이터프레임에 대해 explain 메소드를 호출할 때 드러나는 “ArrowEvalPython [add1(...)#50L]”을 관찰함으로써 확인할 수 있습니다.
마지막으로, 프로파일링 결과를 폴더에 덤프하고 결과 프로파일을 지울 수 있습니다. 아래에 그 방법이 나와 있습니다.
PySpark 메모리 프로파일러
이는 memory-profiler를 기반으로 하며, 드라이버를 프로파일링 할 수 있습니다. 여기에서 확인할 수 있습니다. PySpark는 분산 방식으로 실행되는 UDF를 프로파일링하는 데 사용되도록 확장되었습니다.
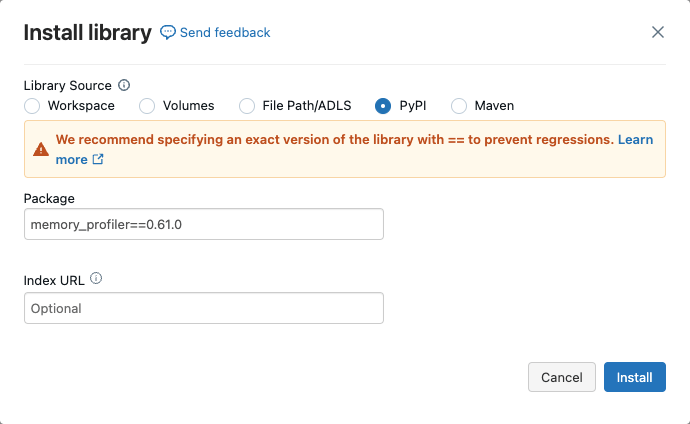
클러스터에서 메모리 프로파일링을 활성화하려면, 아래와 같이 클러스터에 memory-profiler 를 설치해야 합니다.
위의 예제는 마지막 두 줄을 다음과 같이 수정합니다:
그런 다음 아래와 같이 메모리 프로파일링 결과를 얻습니다.
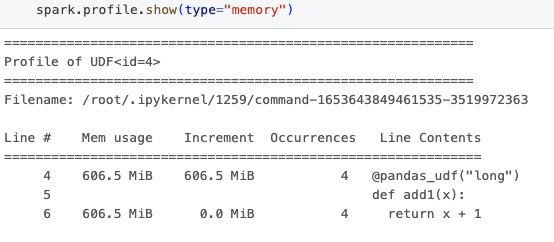
출력에는 코드의 메모리 사용량에 대한 종합적인 이해를 제공하는 여러 열이 포함되어 있습니다. "Mem usage"는 해당 줄을 실행한 후의 메모리 사용량을 나타냅니다. "Increment"는 이전 줄에서의 메모리 사용량 변화를 자세히 설명하여, 메모리 사용량이 급증하는 위치를 파악하는 데 도움이 됩니다. "Occurrences"는 각 줄이 실행된 횟수를 나타냅니다.
이 결과에서의 UDF id도 성능 프로파일링 결과와 마찬가지로 Spark 계획에서 찾은 것과 직접 연관되어 있습니다. 이는 데이터프레임에 대해 explain 메소드를 호출할 때 드러나는 “ArrowEvalPython [add1(...)#4L]”을 관찰함으로써 확인할 수 있습니다.
이 기능을 사용하려면, 클러스터에 memory-profiler 패키지가 설치되어 있어야 함을 유의해야 합니다.
결론
PySpark 통합 프로파일링은 Databricks Runtime 17.0에서 UDF의 성능 및 메모리 프로파일링을 포함하여 제공됩니다. 통합 프로파일링은 함수 호출 빈도, 실행 시간, 메모리 소비 등 중요한 측면을 관찰하는 간편한 방법을 제공합니다. 병목 현상을 식별하고 해결하는 과정을 단순화하여, 더 빠르고 자원 효율적인 UDF 개발을 가능하게 합니다.
더 탐색해 볼 준비가 되셨나요? PySpark API 문서를 확인하여 자세한 가이드와 예시를 참조하세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.