Databricks Intelligence Platform 기반 Mercedes-Benz의 페타바이트급 솔루션: 차량 측정 데이터 저장 및 분석의 혁신
작성자: Dr. Thomas Bonfert, 조나단 브로이어, Xuan Wang 박사 , 플로리안 돌
- Mercedes-Benz는 Databricks와 협력하여, 비용과 확장성을 최적화하면서 페타바이트 규모의 차량 시계열 데이터를 표현하고 분석하기 위해 Databricks Intelligence Platform 상에 새로운 데이터 모델을 구축했습니다.
- 실제 Mercedes-Benz 데이터를 기반으로 모델의 여러 데이터 레이아웃을 평가하고 벤치마킹했으며, Run-Length-Encoding과 Liquid Clustering을 사용하는 것이 가장 적합한 데이터 레이아웃임을 확인했습니다.
- 저희의 접근 방식은 스토리지 요구사항과 실행 속도의 균형을 맞추어, 미래 지향적인 혁신을 이끌어내기 위한 더 빠르고 효율적인 자동차 시계열 데이터 분석을 가능하게 합니다.
초록
커넥티드 차량의 부상으로 자동차 산업에서는 시계열 데이터가 폭발적으로 증가하고 있습니다. 수백 개의 전자 제어 장치(ECU)가 차량 내 네트워크를 통해 높은 주파수(1Hz~100Hz)로 데이터를 지속적으로 스트리밍합니다. 이 데�이터는 예측 분석과 혁신을 위한 엄청난 잠재력을 가지고 있지만, 페타바이트 규모에서 지식을 추출하는 데에는 주요한 기술적, 재정적, 지속 가능성 문제가 따릅니다.
이 블로그 게시물에서는 대규모 시계열 데이터에 맞춤화된 새로운 계층적 시맨틱 데이터 모델을 소개합니다. 최신 기능(예: liquid clustering)은 Databricks Intelligence Platform에서 도입한 기능으로, 확장 가능하고 비용 효율적인 분석을 지원하여 원시 자동차 측정 데이터를 차량 개발, 성능 튜닝, 예측 유지보수를 촉진하는 실행 가능한 인사이트로 전환합니다.
또한 Mercedes-Benz의 실제 데이터를 기반으로 한 벤치마크를 공유하고, 주요 산업 사용 사례 전반의 성능을 평가하기 위해 최신 데이터 최적화 전략을 비교합니다.
소개
자동차 산업의 시계열 분석은 단순한 숫자 계산이 아니라 도로 위 모든 차량의 맥박을 읽는 것과 같습니다. 엔진의 미세한 진동부터 자율 주행 시스템의 순간적인 결정, 운전자와 차량의 상호작용에 이르기까지 각 데이터 포인트는 고유한 스토리를 담고 있습니다. 이러한 데이터 포인트가 모여 추세와 패턴을 형성하면서, 차량 개발을 혁신하고 안전 기능을 향상하며, 대시보드에 경고등이 켜지기도 전에 유지보수 필요성을 예측할 수 있는 통찰력을 얻게 됩니다.
하지만 이 데이터의 방대한 양은 엄청난 과제를 제기합니다. 수백 개의 ECU를 장착한 최신 차량은 방대한 양의 시계열 데이터를 생성합니다. 이처럼 풍부한 정보를 수집하고 저장하는 것도 중요하지만, 진정한 과제이자 기회는 ML & AI를 활용하여 단순한 보고를 넘어 미래 예측 분석으로 나아가는 데 있습니다.
이 문제의 핵심은 잘 정의된 사용 사례와 새로운 사용 ��사례를 모두 지원하는, 보편적으로 적용 가능하고 효율적이며 확장 가능한 시계열 데이터 표현 모델이 필요하다는 것입니다. 이러한 요구 사항을 충족하기 위해 저희는 자동차 시계열 분석의 복잡성을 해결하고 원시 측정 데이터를 전략적 자산으로 전환하는 새로운 계층적 시맨틱 데이터 모델을 소개합니다.
이 데이터 모델을 개발하면서 다음 세 가지 중요한 측면에 중점을 두었습니다.
- 비용 효율적이고 확장 가능한 데이터 액세스: 데이터 모델은 시계열 데이터 분석의 일반적인 쿼리 패턴을 지원하여 방대한 데이터 세트를 빠르고 리소스 효율적으로 처리할 수 있도록 설계되어야 합니다.
- 사용 편의성: 데이터 실무자뿐만 아니라 도메인 전문가도 쉽게 사용하는 것이 중요합니다. 규모에 관계없이 데이터 작업을 간단하고 직관적으로 수행할 수 있어 쿼리 작성에 몇 시간을 소비하지 않고도 신속하게 통찰력을 얻을 수 있습니다.
- 데이터 검색 가능성 및 데이터 거버넌스: 수천에서 수백만 개에 이르는 다양한 신호와 컨텍스트 메타데이터를 포함하는 시계열 데이터의 데이터 모델을 최소화하는 것은 거버넌스와 유지 관리성에 매우 중요합니다. 몇 개의 Unity Catalog 테이블에 임의의 수의 차량 플릿 데이터를 쉽게 등록할 수 있으며, 사용자는 신뢰할 수 있는 데이터를 안전하게 검색, 액세스하고 협업할 수 있습니다.
독일 슈투트가르트에 본사를 둔 세계 최대 프리미엄 자동차 제조업체 중 하나인 Mercedes-Benz AG와의 협력을 통해, 저희는 ASAM 표준 기반의 데이터 모델을 개선하여 Mercedes-Benz가 Mercedes-Benz Operating System(MB.OS)의 성능을 활용해 가장 매력적인 자동차를 개발할 수 있도록 지원합니다. 전기 주행 거리와 효율성에서 새로운 기준을 제시한 Mercedes-Benz Vision EQXX 콘셉트카처럼, 우리도 최첨단 기술을 사용하여 분석 성능과 효율성을 완전히 새로운 차원으로 끌어올리고 있습니다.
이 블로그 게시물에서는 실제 데이터와 데이터 분석 활용 사례를 통해 다양한 설정에서 확장된 데이터 모델의 기능을 시연합니다. 또한 저희는 다양한 최적화 전략에 대한 과학적 연구와 Z-Ordering 및 Liquid Clustering 데이터 레이아웃에 대한 체계적인 벤치마크를 수행했습니다.
세 가지 중요한 측면을 해결하기 위한 계층적 시맨틱 데이터 모델
이 데이터 모델은 단일 테이블에서 수만 개의 신호로 구성된 시계열 데이터를 표현할 수 있으며 컨텍스트 메타데이터의 계층적 표현을 포함합니다. 따라서 저희 모델은 다음과 같은 이점을 제공합니다.
- 효율적인 필터링: 계층적 구조를 통해 여러 차원에서 신속하게 필터링할 수 있어 분석가가 검색 범위를 빠르게 좁힐 수 있습니다.
- 시맨틱 관계: 샘플과 컨텍스트 메타데이터 간의 시맨틱 관계를 통합함으로써 모델은 더 직관적이고 강력한 쿼리 기능을 지원합니다.
- 확장성: 모델의 계층적 특성은 데이터 볼륨이 페타바이트 규모로 커질 때 효율적인 데이터 구성을 지원합니다.
- 컨텍스트 통합: 시맨틱 레이어를 통해 컨텍스트 메타데이터를 원활하게 통합하여 가능한 분석의 깊이를 향상시킬 수 있습니다.
코어 데이터 모델
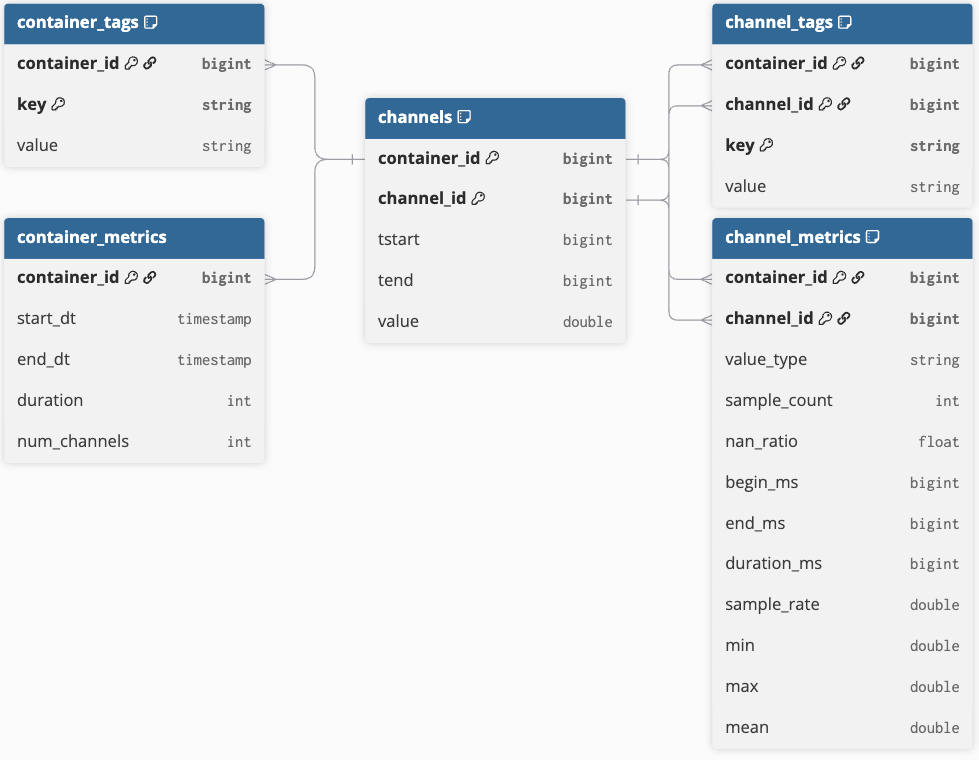
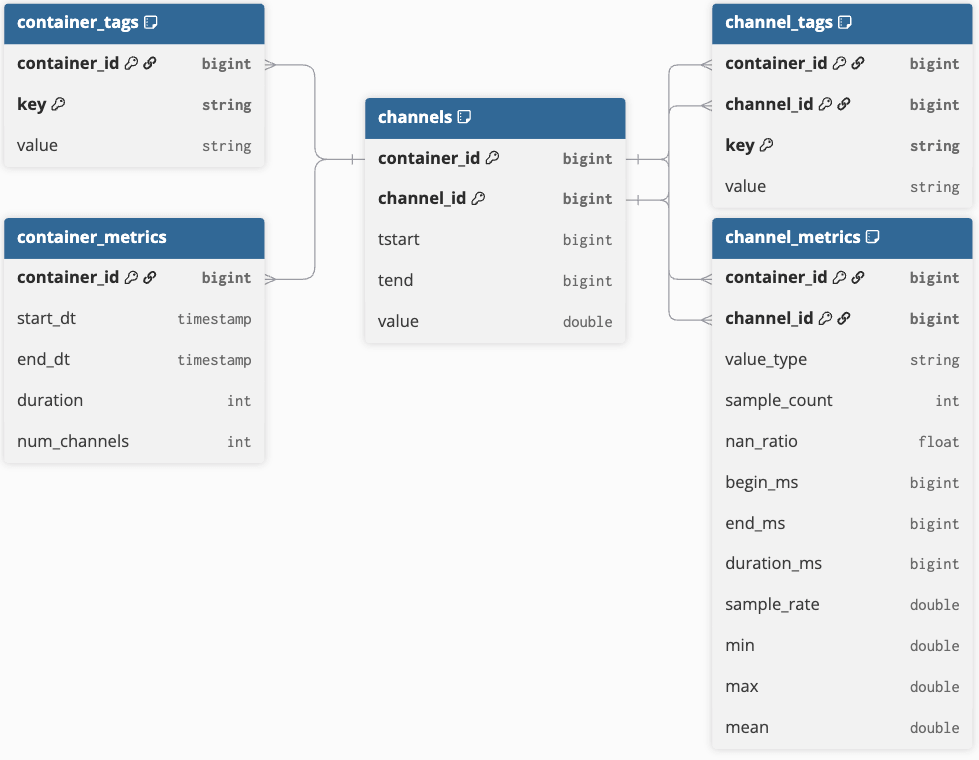
코어 모델은 시계열 데이터와 컨텍스트 메타데이터를 효율적으로 표현하는 5개의 테이블로 구성됩니다(엔터티 관계 다이어그램은 그림 1 참조). 모델의 중심에는 container_id 와 channel_id라는 두 ��개의 식별자 열이 있는 narrow 형식의 시계열 데이터를 포함하는 samples 테이블이 있습니다. container_id 는 시계열 객체 컬렉션의 고유 식별자 역할을 하며, channel_id 는 해당 컨테이너 내의 각 시계열(또는 채널)을 고유하게 식별합니다. 이 구조는 기본 시계열 데이터의 분산 분석을 가능하게 합니다.
자동차 분야에서 컨테이너는 테스트 주행 중 차량 데이터 로거가 기록하여 단일 파일에 저장한 사전 정의된 채널을 포함합니다. 그러나 크기 제약으로 인해 주행 측정값이 분할되는 경우 여러 측정 파일을 단일 컨테이너로 그룹화할 수 있습니다. 이 개념은 연속적인 시계열 데이터 스트림(예: IoT 장치)에도 적용되며, 이 경우 컨테이너 경계는 시간(예: 시간별 또는 일별) 또는 생산 단계나 배치를 기준으로 스트림을 분할하는 것과 같은 프로세스 지식으로 정의할 수 있습니다.
모든 샘플 데이터는 RLE(Run-Length Encoding)를 사용하여 저장되며, 동일한 값을 갖는 연속적인 샘플은 시작 시간('tstart'), 종료 시간('tend') 및 기록된 값으로 정의된 단일 행으로 병합됩니다. 종료 시간은 포함되지 않으며 다음 값으로의 전환을 표시합니다. RLE는 값을 버킷으로 나누고 기간(tend - tstart)을 합산하여 히스토그램을 계산하는 등 효율적인 분석을 용이하게 하는 간단한 압축 방법입니다. 각 행은 container_id, channel_id 및 활성 시간 프레임으로 인덱싱됩니다. 이 코어 샘플 테이블은 스토리지 크기를 최소화하고 쿼리 성능을 향상시키기 위해 단순하게 유지됩니다.
샘플 테이블 외에도 문맥 메타데이터를 나타내는 4개의 테이블이 있습니다:
- “container_metrics”와 “container_tags”는 주어진 “container_id”로 인덱싱됩니��다.
- “channel_metrics” 및 “channel_tags” 메타데이터는 해당하는 “channel_id”로 추가 식별이 가능합니다.
- 두 metrics 테이블 모두 쿼리 프루닝에 유용한 정보를 포함하는 정적 스키마를 가집니다.
- 두 tags 테이블은 모든 종류의 메타데이터를 저장할 수 있는 간단한 키-값 쌍 저장소로 사용됩니다.
일부 메타데이터는 측정 파일에서 직접 추출할 수 있으며, 태그는 외부 메타데이터 소스에서 보강하여 연결된 컨테이너와 신호에 컨텍스트를 부여할 수도 있습니다.
{kind=link}
Mercedes-Benz 구현
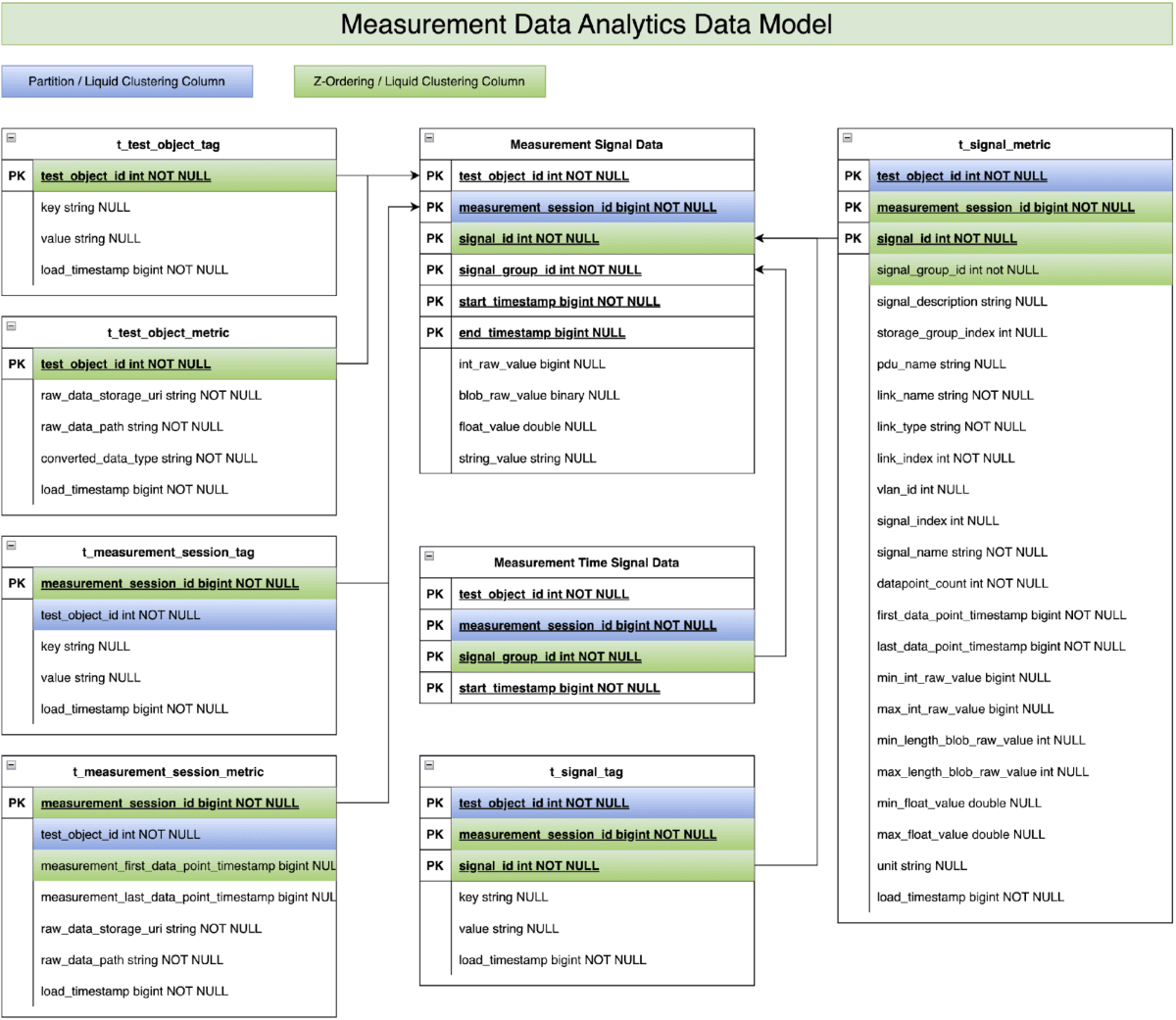
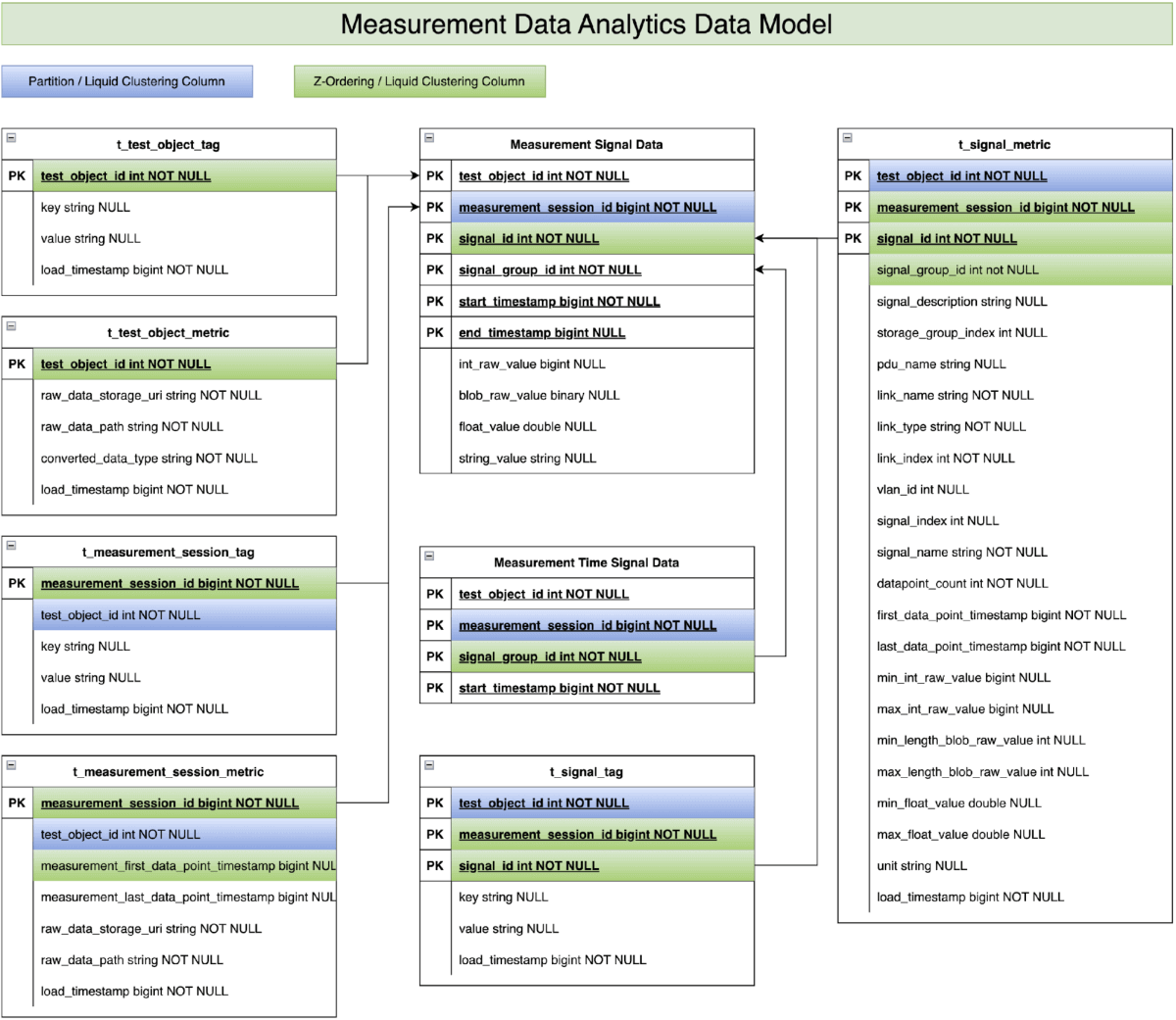
자동화 및 측정 시스템 표준화 협회(ASAM) 커뮤니티의 회원사(2025년 8월 기준)인 Mercedes-Benz는 오랫동안 수집된 측정 데이터를 분석하기 위해 다양한 기술을 활용해 왔습니다. Databricks와의 협력을 통해 저희는 앞서 언급한 시계열 데이터 모델이 Mercedes-Benz 차량 개발을 지원하는 데 엄청난 잠재력이 있음을 인식했습니다. 따라서 저희는 차량 개발 전문 지식을 활용하여 ASAM MDF 표준을 기반으로 데이터 모델을 개선했습니다(그림 2 참조). 저희는 개발 차량의 실제 측정 데이터를 제공하고 실제 데이터 분석 사용 사례를 조정했습니다. 이를 통해 데이터 모델 개념을 검증하고 차량 개발 프로세스와 품질을 향상시키는 데 있어 그 실현 가능성을 입증할 수 있었습니다.
이제 이 향상된 데이터 모델이 Mercedes-Benz 개발 차량 측정 데이터에서 어떤 성능을 보이는지 시연하는 데 집중하겠습니다.
- “t_test_object_metric” 및 “t_test_object_tag”을 통한 1단계 필터링 : 이 두 테이블은 테스트 객체 수준에서 비즈니스 정보와 통계를 저장합니다(예: 테스트 차량). 예를 들어 차량 유형, 차량 시리즈, 모델 연도, 차량 구성 등이 있습니다. 이 정보는 첫 번째 단계의 데이터 분석 사용 사례가 수백 개의 테스트 객체 중에서 특정 테스트 객체에 집중할 수 있도록 해줍니다.
- 레벨 2 필터링 ("t_measurement_session_metric" 및 "t_measurement_session_tag" 사용): 이 두 테이블은 측정 세션 수준의 비즈니스 정보와 통계를 저장합니다. 예시에는 테스트 이벤트, 시간대 정보, 측정 시작/종료 타임스탬프가 포함됩니다. 측정 시작/종료 타임스탬프는 데이터 분석 스크립트가 두 번째 단계에서 수백만 개의 측정 세션 중에서 관심 있는 수백 개의 세션을 추려내는 데 도움이 됩니다.
- t_signal_metric & t_signal_tag를 통한 레벨 3 필터링 : 이 두 테이블은 신호 키 수준에서 비즈니스 정보와 통계를 저장합니다. 예를 들어 차량 속도, 도로 유형, 기상 조건, 드라이브 파일럿 신호 등이 있습니다. 데이터 분석 스크립트는 마지막 단계의 정보를 활용하여 수천 개의 사용 가능한 신호 중에서 기본 쿼리에 대한 관련 신호를 식별합니다.
- 측정 신호 데이터 테이블에 대한 분석 스크립트: 실제 분석 로직은 테스트 차량에서 수집된 시계열 데이터를 저장하는 측정 신호 데이터 테이블에서 �실행됩니다. 하지만 위에 언급된 세 가지 수준의 데이터 필터링을 적용하면 일반적으로 원시 시계열 데이터 원본 중 극히 일부만 처리하고 분석하면 됩니다.
{kind=link}
메타데이터 테이블 작업을 위한 메르세데스-벤츠 사용 사례
다양한 수준의 메트릭 및 태그 테이블을 핵심 메타데이터로 도입함으로써 메르세데스-벤츠의 기존 솔루션에 비해 데이터 분석 성능이 크게 향상되었습니다. 핵심 메타데이터가 분석 성능을 향상시키는 방법을 설명하기 위해 자동 차선 변경(ALC) 시스템 준비 상태 감지를 예로 들어보겠습니다.
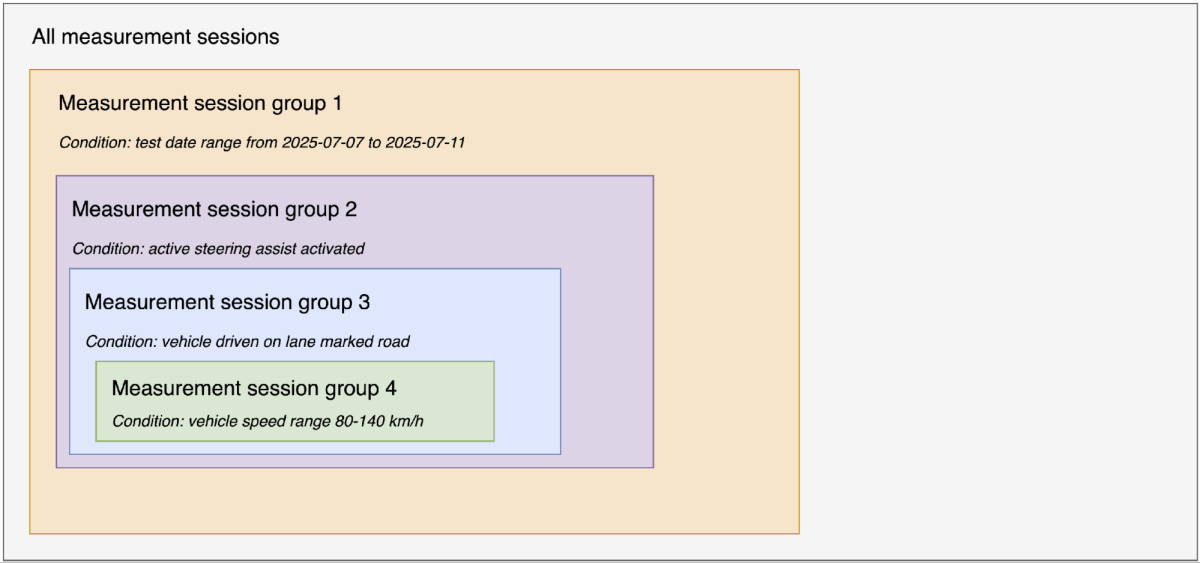
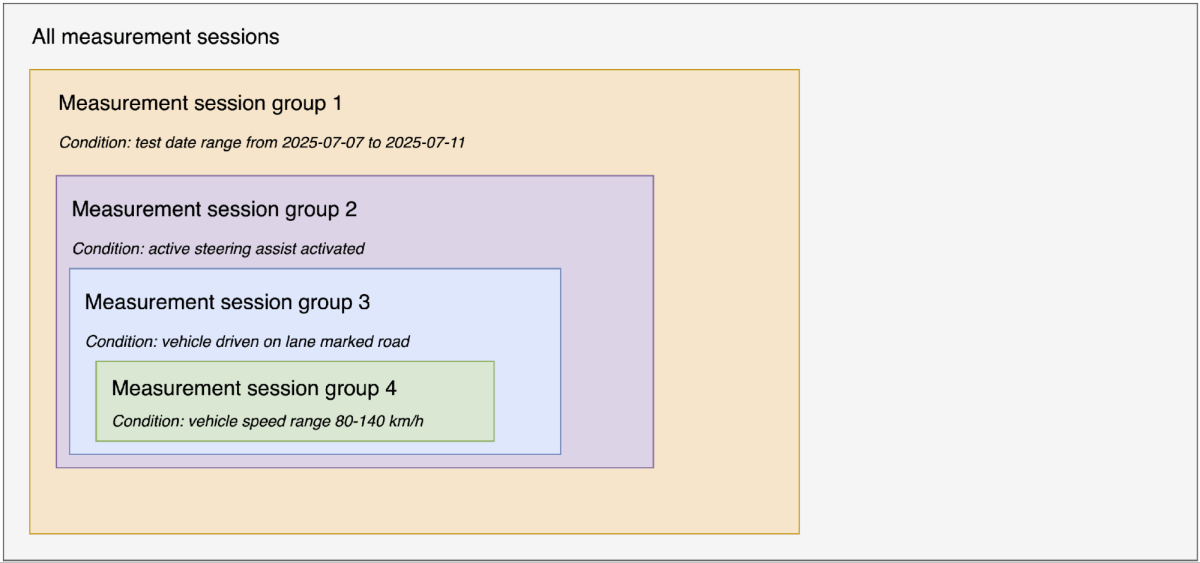
Mercedes-Benz 혁신에서 강조된 바와 같이, ALC 기능은 액티브 스티어링 어시스트가 포함된 액티브 디스턴스 어시스트 DISTRONIC의 핵심적인 부분입니다. 전방에 저속 차량이 있는 경우, 차선 표시 가 감지되고 충분한 공간이 확보되면 차량이 시속 80~140km 의 속도 범위에서 스스로 차선 변경을 시작하여 완전히 자동으로 추월할 수 있습니다. 전제 조건은 도로에 �속도 제한이 있고 차량에 MBUX 내비게이션이 장착되어 있어야 한다는 것입니다. 이 정교한 시스템은 운전자의 추가적인 개입 없이도 자동 차선 변경을 실행합니다. 이 세 가지 전제 조건은 분석 스크립트가 수천 개의 세션 중에서 관련 세션을 필터링하는 데 도움을 줍니다. 명확성을 위해 저희는 방법론을 논리적이고 순차적인 방식으로 제시하지만(그림 3 참조), 실제 구현은 병렬로 수행될 수 있다는 점에 유의해야 합니다.
- 생성된 모든 측정 세션에서 2025-07-07~2025-07-11의 테스트 주행 기간에 해당하는 세션을 필터링하여 세션 그룹 1을 만듭니다. 이 단계에서는 "t_measurement_session_metric" 테이블의 measurement_first_data_point_timestamp 및 measurement_end_data_point_timestamp 열을 사용하여 차량의 모든 기록된 세션 중에서 관련 세션을 식별합니다.
- 활성화된 액티브 스티어링 어시스트(Active Steering Assist)를 포함하는 세션 그룹 1 내 세션을 필터링하여 세션 그룹 2를 생성합니다. 이 단계에서는 't_signal_metric' 테이블에서 max_int_raw_value > 0 (활성화된 액티브 스티어링 어시스트의 신호 정수 원시값이 1이라고 가정)인 세션을 확인하여 세션 그룹 1에서 관련 세션을 식별합니다.
- 차량이 차선이 표시된 도로에서 주행하는 세션 그룹 2 내의 세션을 필터링하여 세션 그룹 3을 생성합니다. 이 단계에서는 't_signal_metric' 테이블에서 max_int_raw_value > 2(차선 표시 도로 유형의 신호 정수 원시 값이 3이라고 가정)인 세션을 확인하여 세션 그룹 2에서 관련 세션을 식별합니다.
- 세션 그룹 3 내에서 80~140km/h 범위의 차량 속도를 포함하는 세션을 필터링하여 세션 그룹 4를 생성합니다. 이 단계에서는 't_signal_metric' 테이블에서 max_float_value >= 80 또는 min_float_value <= 140 인 세션을 확인하여 세션 그룹 3에서 관련 세션을 식별합니다.
- 세션 그룹 4 내에서 필요한 신호 ID를 필터링합니다. 이 단계에서는 관련 신호의 신호 ID를 찾기 위해 pdu_name, link_name, vlan_id 및 signal_name 의 조합을 사용합니다.
- 세션 그룹 4 의 필터링된 신호 ID 및 측정 세션 ID를 사용하여 측정 신호 데이터 포인트 테이블을 조인하고 ALC 시스템 준비 상태를 식별합니다.
{kind=link}
실제 데이터 및 사용 사례 벤치마킹을 통한 최적의 데이터 레이아웃 선택
설명된 데이터 모델의 성능과 확장성을 입증하기 위해 실제 측정 데이터와 사용 사례를 체계적으로 벤치마킹했습니다. 벤치마크 연구에서는 다양한 데이터 레이아웃 및 최적화 기법 조합을 평가했습니다. 벤치마크는 다음에 최적화하도록 설계되었습니다.
- 데이터 레이아웃 & 최적화 전략: 쿼리 성능을 최적화하기 위해 파티셔닝 방식, RLE, non-RLE, Z-Ordering, Liquid Clustering과 같은 다양한 데이터 레이아웃 접근 방식을 ��테스트했습니다.
- 확장성: 효율성을 유지하면서 계속 증가하는 측정 데이터 양을 처리할 수 있는 솔루션에 중점을 두었습니다.
- 비용 효율성: 장기적인 데이터 보존 및 분석을 위해 가장 비용 효율적인 접근 방식을 찾고자 스토리지 비용과 쿼리 성능을 모두 고려했습니다.
벤치마크 결과는 메르세데스-벤츠의 향후 측정 데이터 스키마와 형식을 선택하는 데 매우 중요하므로, 실제 데이터와 분석 스크립트를 사용하여 다양한 옵션을 평가했습니다.
실제로 사소한 최적화만으로도 대규모 환경에서 막대한 비용을 절감할 수 있으며, 수천 명의 엔지니어가 안전하고 비용 효율적으로 인사이트를 추출할 수 있게 됩니다. 벤치마킹은 제안된 솔루션의 효율성을 검증하는 데 핵심적이며, 시스템에 큰 변경이 있을 때마다 꾸준히 반복되어야 합니다.
벤치마크 설정
벤치마크 데이터 세트에는 21대의 개별 테스트 차량에서 수집된 측정 데이터가 포함되어 있으며, 각 차량에는 측정 데이터 수집을 위한 최신 차량용 로거가 장착되어 있습니다. 수집된 데이터에는 차량당 30,000개에서 60,000개 사이의 기록된 신호가 포함되어 분석을 위한 광범위한 데이터 포인트를 제공합니다. 데이터 세트는 총 40,000시간 분량의 기록으로, 그중 12,500시간은 차량이 작동 중(시동 켜짐)일 때 캡처된 데이터입니다. 이 데이터 세트를 통해 다양한 차량과 운행 조건에 걸친 자동차 동작 및 성능의 여러 측면을 연구할 수 있습니다.
벤치마크의 일부로 다음과 같은 네 가지 분석 쿼리 카테고리가 실행되었습니다.
- 신호 분포 분석 - 주요 신호에 대한 1차원 히스토그램을 생성했��습니다(예: 차량 속도)를 사용하여 데이터 분포 및 빈도 패턴을 평가합니다.
- 신호 산술 연산 - 기본적인 계산을 수행했습니다(예: 뺄셈, 비율)을 수개에서 수천 개의 신호에 대해 수행했습니다.
- 테스트 사례 식별 – 쿼리는 데이터세트 내에서 주어진 순서로 발생하는 일련의 이벤트로 정의된 사전 정의된 운영 시나리오를 식별하고 검증합니다.
- 자동 차선 변경 보조 시스템의 준비 상태 감지 - 이 쿼리는 실제 기반이 되는 시계열 데이터를 쿼리하기 전에 메타데이터 테이블을 광범위하게 활용합니다.
다른 카테고리의 결과는 비슷한 성능을 보이며 추가적인 인사이트를 제공하지 않으므로, 이 블로그 게시물에서는 카테고리 1과 4의 결과만 제시합니다.
솔루션의 확장성을 벤치마킹하기 위해 네 가지 다른 클러스터 크기를 사용했습니다. 메모리에 최적화된 Standard_E8d_v4 노드 유형은 델타 캐시 기능과 핵심 메타데이터를 저장할 수 있는 더 큰 메모리 때문에 선택되었습니다. Databricks 런타임의 경우, 15.4 LTS가 사용 가능한 최신 장기 지원 런타임이었습니다. 이전 조사에서 Photon 기능은 더 높은 DBU 비용에도 불구하고 더 비용 효율적인 것으로 입증되었으므로 모든 벤치마크에서 Photon을 활용했습니다. 표 1에서 선택된 Databricks 클러스터의 세부 정보를 확인할 수 있습니다.
| 티셔츠 사이즈 | 노드 유형 | DBR | #노드(드라이버 + 워커) | Photon |
|---|---|---|---|---|
| X-Small | Standard_E8d_v4 | 15.4 LTS | 1 + 2 | 예 |
| Small | Standard_E8d_v4 | 15.4 LTS | 1 + 4 | 예 |
| Medium | Standard_E8d_v4 | 15.4 LTS | 1 + 8 | 예 |
| Large | Standard_E8d_v4 | 15.4 LTS | 1 + 16 | 예 |
표 1 벤치마크 클러스터 설정
벤치마크 결과
벤치마크는 두 가지 주요 버전의 데이터 모델에서 실행되었습니다. 첫 번째 버전은 실행 길이 인코딩(RLE)된 샘플 데이터를 사용하며(핵심 데이터 모델 섹션 참조), 두 번째 버전은 RLE를 사용하지 않습니다. 또한 두 버전의 데이터 모델 모두에 두 가지 다른 데이터 레이아웃 최적화를 적용했습니다. 첫 번째 최적화에서는 하이브 스타일 파티셔닝을 사용하여 measurement_session_id 열을 기준으로 측정 신호 데이터 테이블을 분할하고 signal_id 열에 Z-Ordering 기법을 적용했습니다. 두 번째 최적화에서는 Liquid Clustering을 사용하여 measurement_session_id 와 signal_id를 기준으로 측정 신호 데이터 테이블을 클러스터링했습니다.
런타임 성능
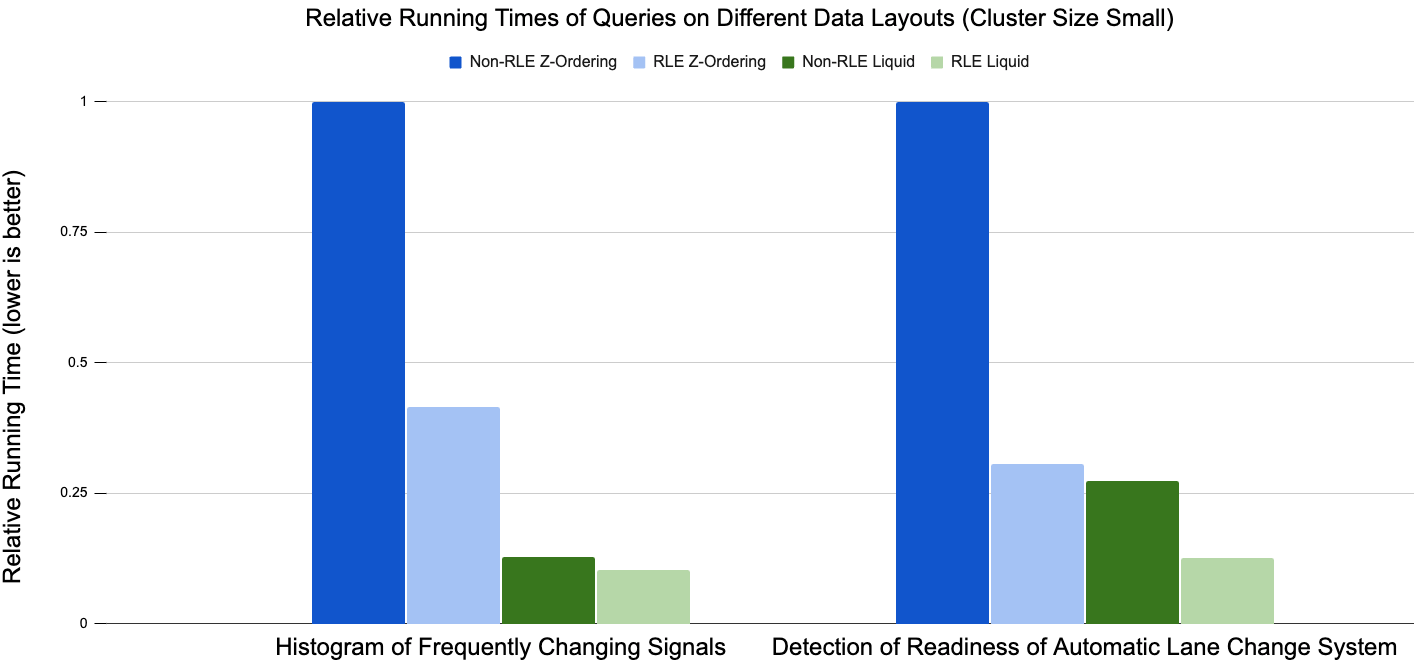
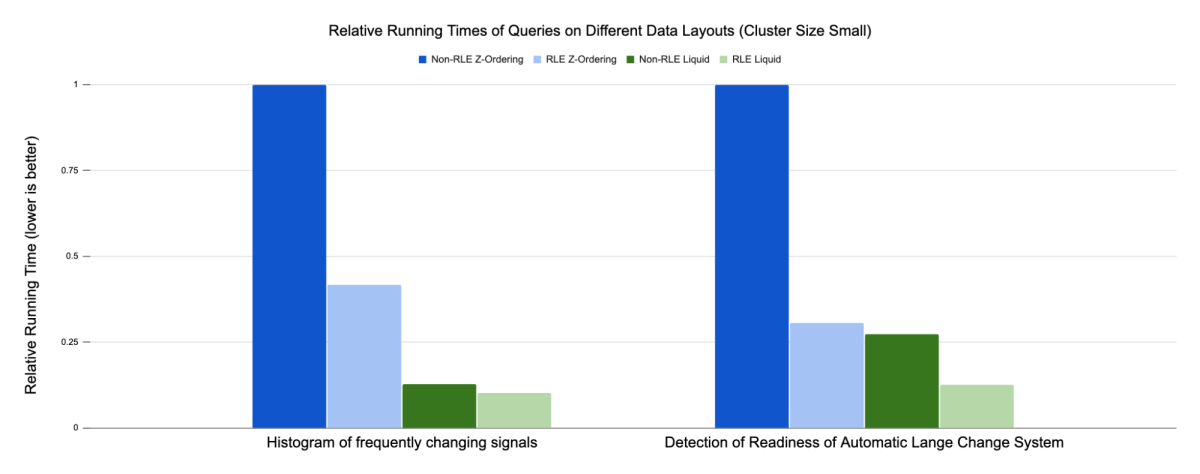
벤치마크된 설정 간 절대 실행 시간의 차이가 커서, RLE를 적용하지 않은 Z-Ordering 결과를 기준으로 한 상대 실행 시간을 사용하여 결과를 시각화하기로 했습니다. 일반적으로 수행한 모든 테스트에서 Liquid Clustering(녹색 막대)이 hive 스타일 파티셔닝 +Z-Ordering(파란색 막대)보다 뛰어난 성능을 보입니다. 자주 변경되는 신호의 히스토그램의 경우, RLE 최적화는 Z-Ordering의 런타임을 약 60% 단축하는 반면 Liquid Clustering의 런타임은 10% 미만으로 단축하는 데 그쳤습니다.
두 번째 사용 사례인 자동 차선 변경 시스템의 준비 상태 감지에서는 RLE를 통해 Z-Ordering의 런타임이 약 70%, Liquid Clustering의 런타임이 50% 이상 단축되었습니다. 시연된 사용 사례의 전반적인 결과에 따르면 데이터 모델에서 RLE와 Liquid Clustering의 조합이 가장 우수한 성능을 보입니다.
{kind=link}
확장성
솔루션의 확장성을 평가하기 위해 다양한 클러스터 크기를 사용하여 고정된 데이터 세트에서 네 가지 분석 쿼리를 모두 실행했습니다. 실제로 벤치마킹을 실행할 때마다 이전 실행에 비해 클러스터 크기를 두 배로 늘렸습니다. 이상적으로는 완벽하게 확장되는 솔루션의 경우 클러스터 크기가 두 배로 증가할 때마다 쿼리 런타임이 2배씩 감소해야 합니다. 그러나 기술적 한계로 인해 완벽한 확장이 어려운 경우가 많습니다.
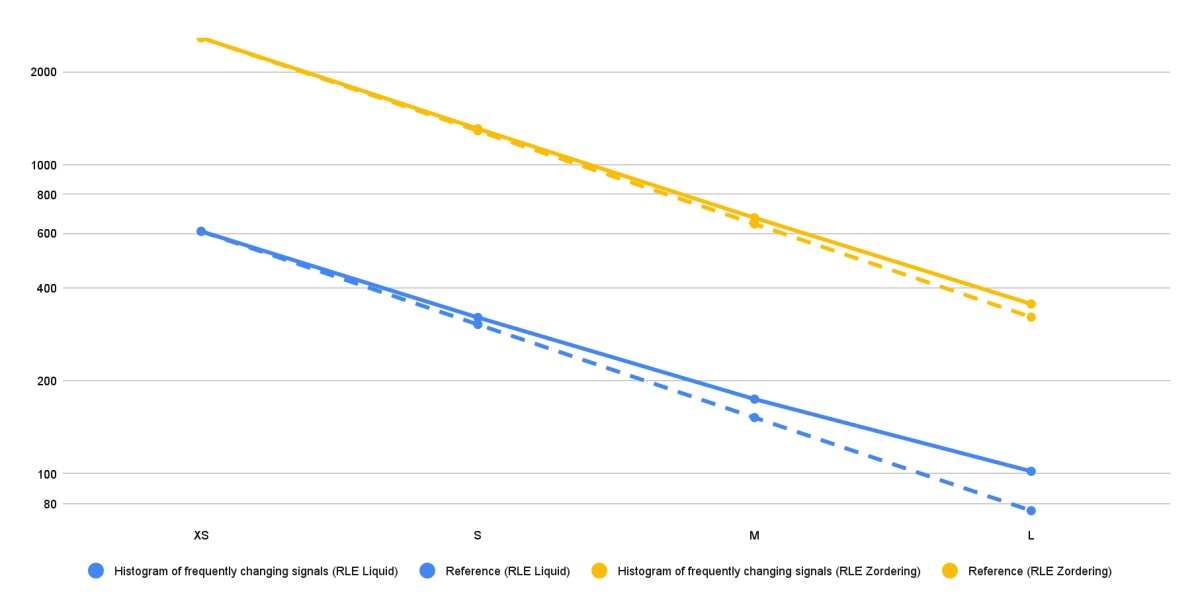
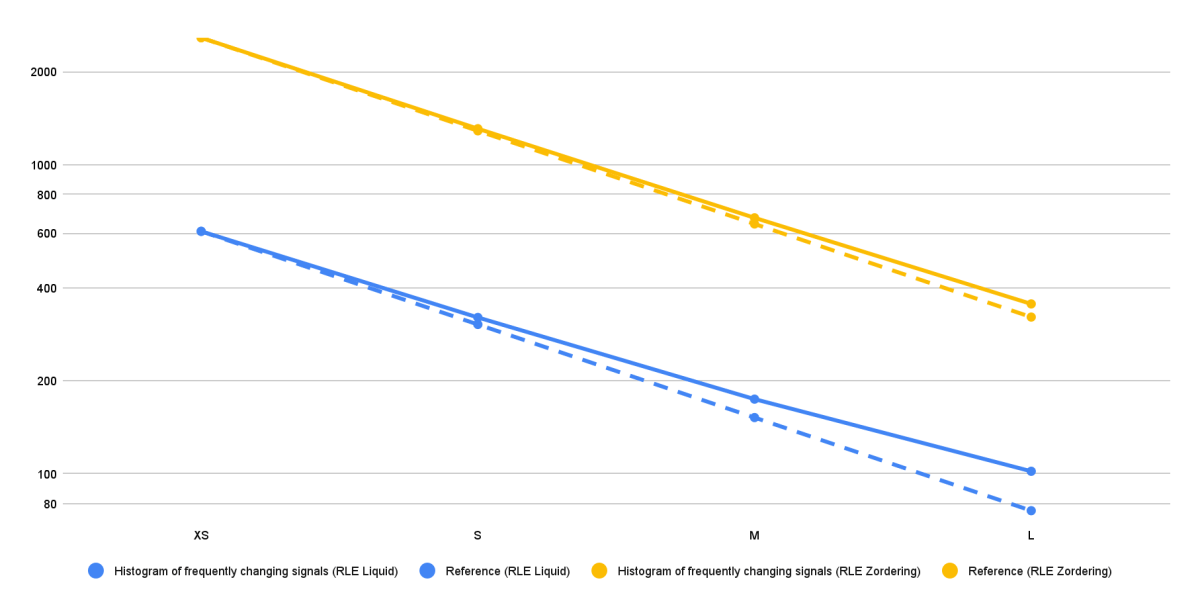
그림 5는 다른 모든 사용 사례에서도 동일한 패턴이 관찰되었지만, 한 가지 사용 사례에 대한 다양한 벤치마크 설정의 결과를 절대 실행 시간(초)으로 보여줍니다. 참조선(노란색과 파란색 점선)은 두 가지 다른 벤치마크 설정에 대한 실행 시간의 하한(완벽한 확장성)을 나타냅니다. 표시된 사용 사례의 경우 클러스터 크기가 X-Small에서 Large로 증가함에 따라 실행 시간은 일반적으로 거의 완벽하게 감소합니다. 이는 데이터 모델과 최적화 전략이 확장 가능하��며 추가 노드와 처리 능력의 이점을 활용할 수 있음을 나타냅니다.
그럼에도 불구하고 RLE Liquid Clustering 솔루션(파란색 선)의 실행 시간은 중간(Medium) 크기 클러스터부터 완벽한 확장성 참조선에서 벗어나기 시작하는 것을 볼 수 있습니다. 이 격차는 대형(Large) 클러스터 크기에서 더욱 두드러집니다. 하지만 RLE Liquid Clustering 솔루션의 절대 실행 시간은 RLE Z-Ordering의 실행 시간보다 훨씬 짧다는 점에 유의해야 합니다. 따라서 RLE Liquid Clustering 솔루션은 해당 단계에서 기준 실행 시간이 이미 매우 낮기 때문에 더 큰 클러스터 크기에서는 확장성 개선 효과가 감소할 것으로 예상됩니다.
{kind=link}
스토리지 크기
벤치마크 데이터는 5개월의 테스트 기간 동안 21대의 Mercedes-Benz MB.OS 테스트 차량에서 수집된 64.55TB의 독점 MDF 파일에서 생성되었습니다. 허용 가능한 스토리지 크기를 유지하면서 쿼리 성능을 극대화하기 위해 이전 조사 결과를 바탕으로 Parquet 파일에 zstd 압축을 사용하고 DELTA 대상 파일 크기를 32MB로 설정합니다. 이 시나리오에서는 너무 많은 신호를 동일한 물리적 파일에 저장하는 것을 방지하여 선택성이 높은 쿼리에 대한 동적 파일 가지치기(dynamic file pruning)의 효율성을 높일 수 있으므로 작은 파일 크기가 바람직합니다.
모든 데이터 레이아웃은 독점 MDF 데이터와 크기가 비슷한 델타 테이블을 생성했습니다(표 2 참조). 일반적으로 원시 파일 형식에서 델타 테이블로의 압축률은 MF4 파일의 다양한 특성에 따라 크게 달라집니다. 기본 데이터 세트에는 차량당 최대 60,000개의 신호가 포함되며, 그중 다수는 값 변경 시에만 기록되었습니다. 이러한 신호의 경우 RLE와 같은 압축 기술은 효과가 없습니다. 수천 개의 신호만 있지만 지속적으로 기록되는 다른 데이터 세트의 경우, 원시 MDF 파일에 비해 저장 공간 크기가 >50% 감소한 것을 확인했습니다.
연구 결과, Liquid Clustering 테이블은 Z-Ordered 테이블에 비해 크기가 훨씬 더 컸습니다(RLE 데이터 레이아웃의 경우 +14%). 그러나 위에 제시된 실행 시간 성능 벤치마크 결과를 고려할 때 RLE Liquid Clustering 레이아웃에 필요한 추가 스토리지 크기는 우수한 성능으로 인해 정당화됩니다.
| 형식 | 독점 MDF 파일 | RLE Z-Ordering | RLE Liquid Clustering |
|---|---|---|---|
| 스토리지 크기[TB] | 64.55 | 67.43 | 77.05 |
표 2 원시 데이터 및 다양한 RLE 데이터 레이아웃의 스토리지 크기
결론
Databricks Intelligence Platform에서 커넥티드 카로부터 수집된 페타바이트 규모의 시계열 데이터를 효율적으로 저장하고 분석하기 위해 계층적 시맨틱 데이터 모델을 개발했습니다. 비용 효율적이고 확장 가능한 액세스, 사용성, 강력한 거버넌스를 위해 설계된 이 모델은 원시 원격 측정 데이��터를 실행 가능한 인사이트로 전환할 수 있는 길을 열어줍니다.
실제 Mercedes-Benz 데이터를 사용하여 계층적 메타데이터 테이블이 다단계 필터링을 통해 어떻게 분석 성능을 개선하는지 보여주었습니다. 자동 차선 변경 준비 상태(Automatic Lane Change Readiness) 예시에서 이 구조는 관련 세션과 신호를 신속하게 식별할 수 있게 하여 처리 시간을 대폭 단축했습니다.
벤치마킹 결과, RLE(Run-Length Encoding)와 Liquid Clustering을 결합하는 것이 분석 쿼리 유형 전반에서 최고의 성능을 제공했으며, 특히 런타임 측면에서 RLE와 Z-Ordering을 사용하는 것보다 뛰어난 것으로 나타났습니다. 더 많은 저장 공간이 필요했지만, 쿼리 속도가 크게 향상되어 그만큼의 가치가 있었습니다. 확장성 테스트 결과 데이터 볼륨이 증가하더라도 강력한 성능이 유지되는 것으로 확인되었습니다.
향후 Databricks 팀은 다음 솔루션을 발표할 예정입니다. 1) Databricks Jobs로 MDF 파일을 새로운 데이터 모델로 변환하는 방법, 2) Unity Catalog를 사용해 복잡한 데이터 세트를 관리하고 쉽게 검색하면서 개인 정보 보호, 보안, 복잡성 문제를 해결하는 방법, 3) SQL/Python 경험이 적은 엔지니어가 직접 데이터에서 인사이트를 얻을 수 있도록 지원하는 프레임워크.
요약하자면, RLE 및 Liquid Clustering을 사용하는 계층적 시맨틱 데이터 모델은 자동차 시계열 분석을 위한 강력하고 통제되며 확장 가능한 솔루션을 제공하여 Mercedes-Benz의 개발을 가속화하고 보다 지속 가능하고 효율적인 미래를 향한 데이터 기반 협업을 촉진합니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.