Unity Catalog의 공유 클러스터: 클러스터 라이브러리, Python UDF, Scala, 머신러닝 등을 소개합니다.
작성자: Jakob Mund, Stefania Leone, Martin Grund, Herman van Hövell, Andrew Li , Sven Wagner-Boysen
Databricks의 고효율 다중 사용자 클러스터에서 더 많은 워크로드를 실행할 수 있게 되었음을 기쁘게 알려드립니다. Unity Catalog의 새로운 보안 및 거버넌스 기능 덕분입니다. 이제 데이터 팀은 공유 컴퓨팅 리소스에서 안전하게 SQL, Python 및 Scala 워크로드를 개발하고 실행할 수 있습니다. 이를 통해 Databricks는 Scala, Python 및 SQL Spark 워크로드를 위한 공유 컴퓨팅에 대한 세분화된 액세스 제어를 제공하는 업계 유일의 플랫폼이 되었습니다.
Databricks Runtime 13.3 LTS부터 다음 기능을 공유 클러스터에서 사용할 수 있으므로 워크로드를 공유 클러스터로 원활하게 이전할 수 있습니다.
- 클러스터 라이브러리 및 초기화 스크립트: 보안 및 거버넌스가 강화된 상태로 클러스터 라이브러리를 설치하고 시작 시 초기화 스크립트를 실행하여 클러스터 설정을 간소화하고 누가 무엇을 설치할 수 있는지 정의할 수 있습니다.
- Scala: 동시 사용자 간의 완전한 사용자 코드 격리와 Unity Catalog 권한을 강제 적용하여 Python 및 SQL과 함께 다중 사용자 Scala 워크로드를 안전하게 실행할 수 있습니다.
- Python 및 Pandas UDF: 동시 사용자 간의 완전한 사용자 코드 격리를 통해 Python 및 (스칼라) Pandas UDF를 안전하게 실행할 수 있습니다.
- 단일 노드 머신러닝: Spark 드라이버 노드를 사용하여 scikit-learn, XGBoost, prophet 및 기타 인기 있는 ML 라이브러리를 실행하고 MLflow를 사용하여 엔드투엔드 머신러닝 라이프사이클을 관리할 수 있습니다.
- 구조적 스트리밍: 구조적 스트리밍을 사용하여 실시간 데이터 처리 및 분석 솔루션을 개발할 수 있습니다.
Unity Catalog에서 더 쉬워진 데이터 액세스
Unity Catalog에서 관리하는 데이터와 함께 작업할 클러스터를 만들 때 두 가지 액세스 모드 중에서 선택할 수 있습니다.
- 공유 액세스 모드의 클러스터 – 또는 단순히 공유 클러스터 – 는 대부분의 워크로드에 권장되는 컴퓨팅 옵션입니다. 공유 클러스터를 사용하면 여러 사용자가 동일한 컴퓨팅 리소스에 연결하고 동시에 워크로드를 실행할 수 있어 상당한 비용 절감, 간소화된 클러스터 관리 및 세분화된 액세스 제어를 포함한 전체적인 데이터 거버넌스가 가능합니다. 이는 SQL, Python 및 Scala 사용자 코드를 하위 수준 리소스에 액세스하지 않고 완전히 격리된 상태로 실행하는 Unity Catalog의 사용자 워크로드 격리를 통해 달성됩니다.
- 단일 사용자 액세스 모드의 클러스터는 특권 머신 액세스가 필요하거나 RDD API, 분산 ML, GPU, Databricks Container Service 또는 R을 사용하는 워크로드에 권장됩니다.
단일 사용자 클러스터는 사용자 코드가 기본 머신에 대한 특권 액세스로 Spark에서 실행되는 기존 Spark 아키텍처를 따르는 반면, 공유 클러스터는 해당 코드의 사용자 격리를 보장합니다. 아래 그림은 공유 클러스터에 고유한 아키텍처 및 격리 기본 요소를 보여줍니다. 모든 클라이언트 측 사용자 코드(Python, Scala)는 완전히 격리되어 실행되며 Spark 실행기에서 실행되는 UDF는 격리된 환경에서 실행됩니다. 이 아키텍처를 통해 동일한 컴퓨팅 리소스에서 워크로드를 안전하게 다중화하고 동시에 협업적이고 비용 효율적이며 안전한 솔루션을 제공할 수 있습니다.
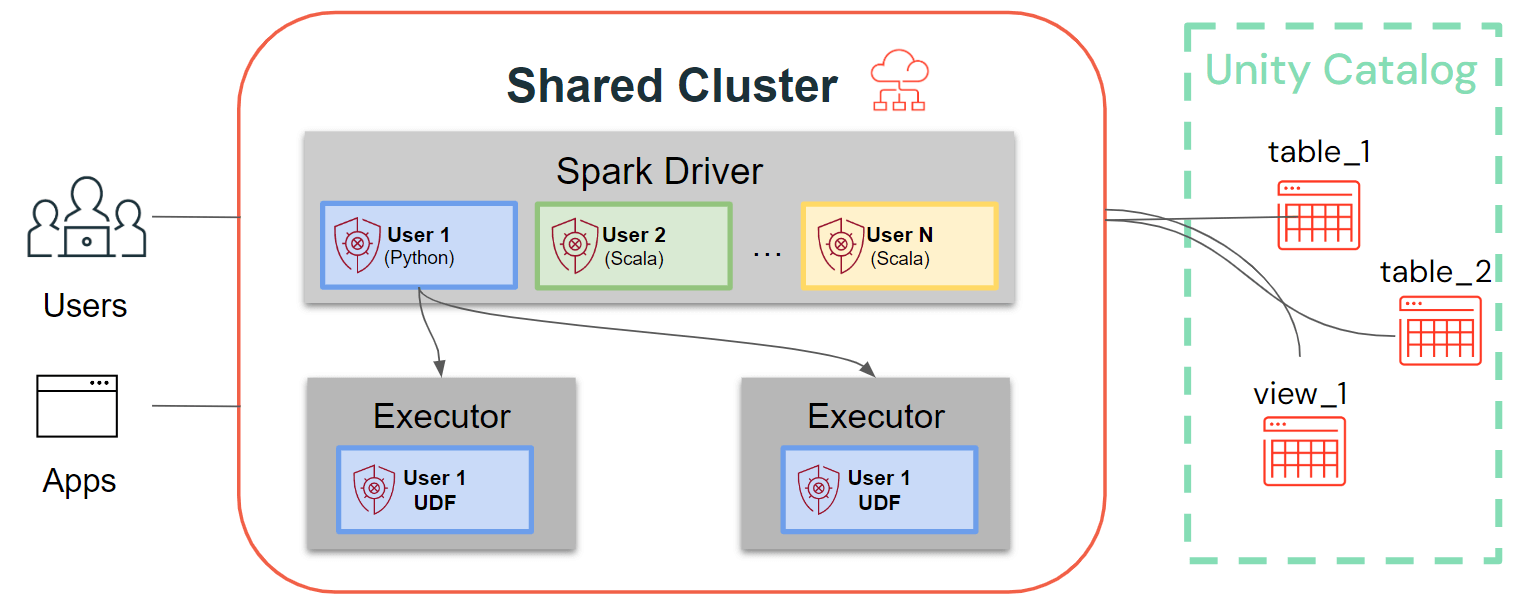
공유 클러스터에 대한 최신 개선 사항: 클러스터 라이브러리, 초기화 스크립트, Python UDF, Scala, ML 및 스트리밍 지원
클러스터 라이브러리 및 초기화 스크립트를 사용하여 공유 클러스터 구성
클러스터 라이브러리를 사용하면 클러스터 또는 여러 클러스터에 걸쳐 라이브러리를 원활하게 공유하고 관리하여 일관된 버전을 보장하고 반복적인 설치의 필요성을 줄일 수 있습니다. 머신러닝 프레임워크, 데이터베이스 커넥터 또는 기타 필수 구성 요소를 클러스터에 통합해야 하는 경우 클러스터 라이브러리는 공유 클러스터에서 사용할 수 있는 중앙 집중식의 쉬운 솔루션을 제공합니다.
기존 클러스터 UI 또는 API를 사용하여 Unity Catalog 볼륨(AWS, Azure, GCP), 작업 공간 파일(AWS, Azure, GCP), PyPI/Maven 및 클라우드 스토리지 위치에서 라이브러리를 설치할 수 있습니다.
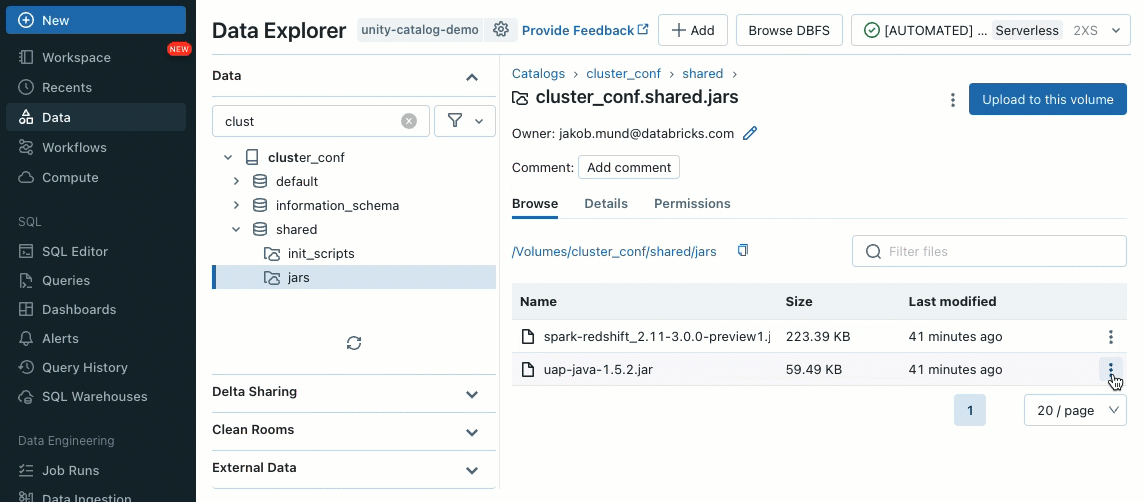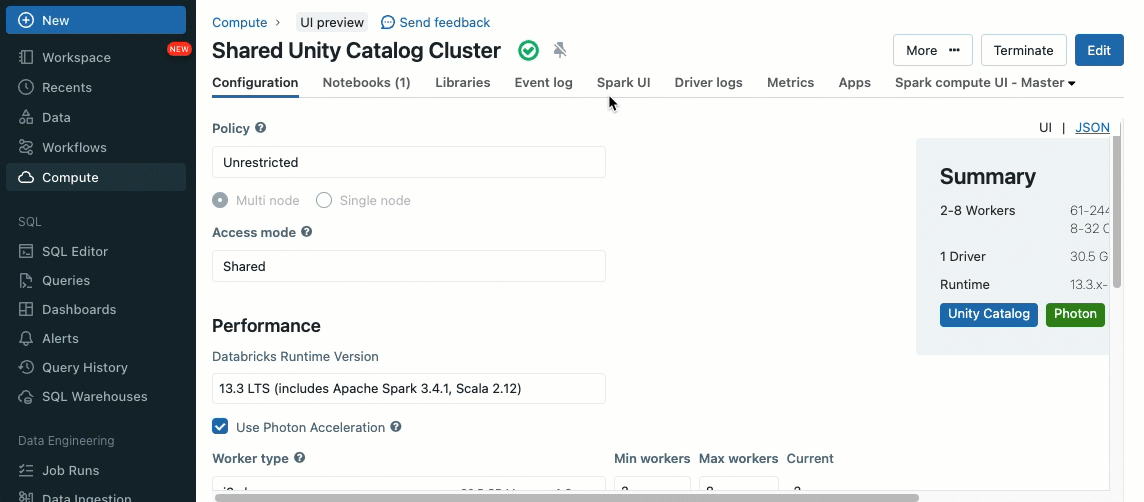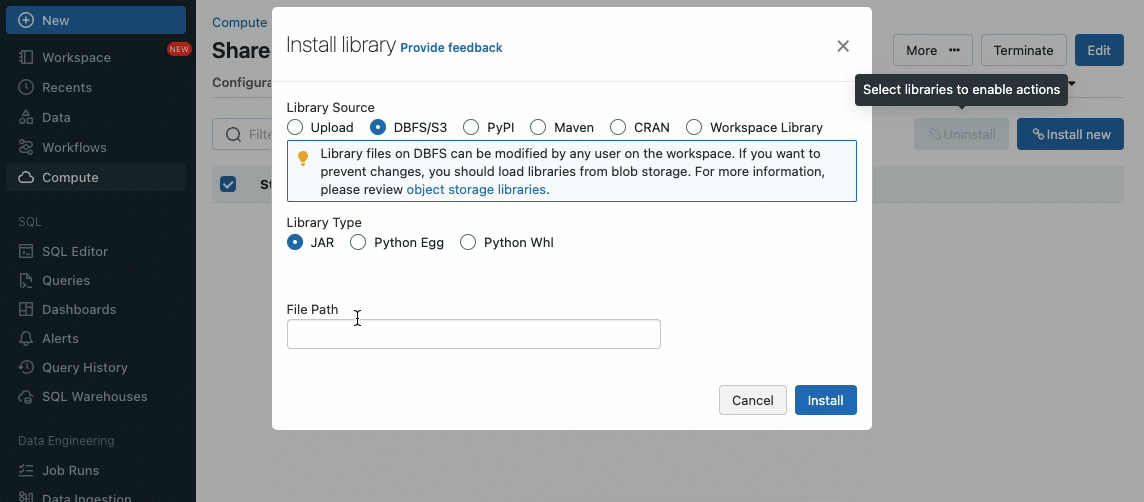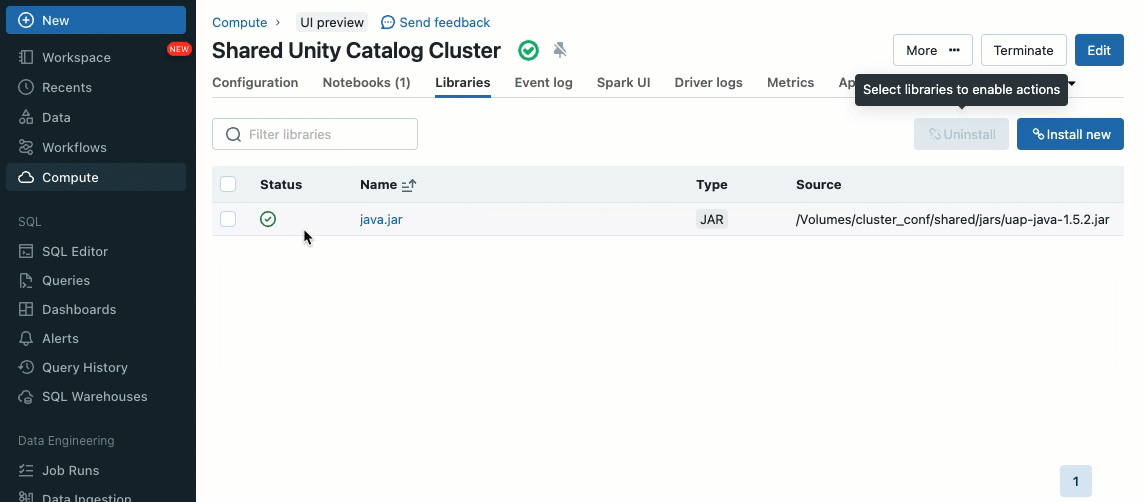
초기화 스크립트를 사용하면 클러스터 관리자는 클러스터 생성 프로세스 중에 사용자 지정 스크립트를 실행하여 인증 메커니즘 설정, 네트워크 설정 구성 또는 데이터 소스 초기화와 같은 작업을 자동화할 수 있습니다.
초기화 스크립트는 클러스터 생성 중에 직접 또는 클러스터 정책(AWS, Azure, GCP)을 사용하여 여러 클러스터에 대해 설치할 수 있습니다. 최대 유연성을 위해 Unity Catalog 볼륨(AWS, Azure, GCP) 또는 클라우드 스토리지에서 초기화 스크립트를 사용할지 여부를 선택할 수 있습니다.
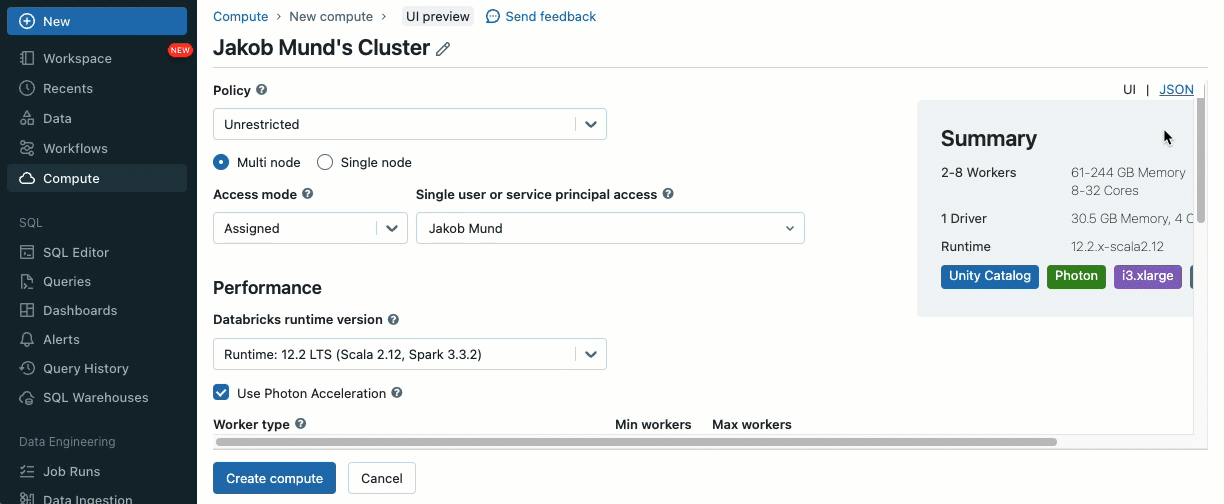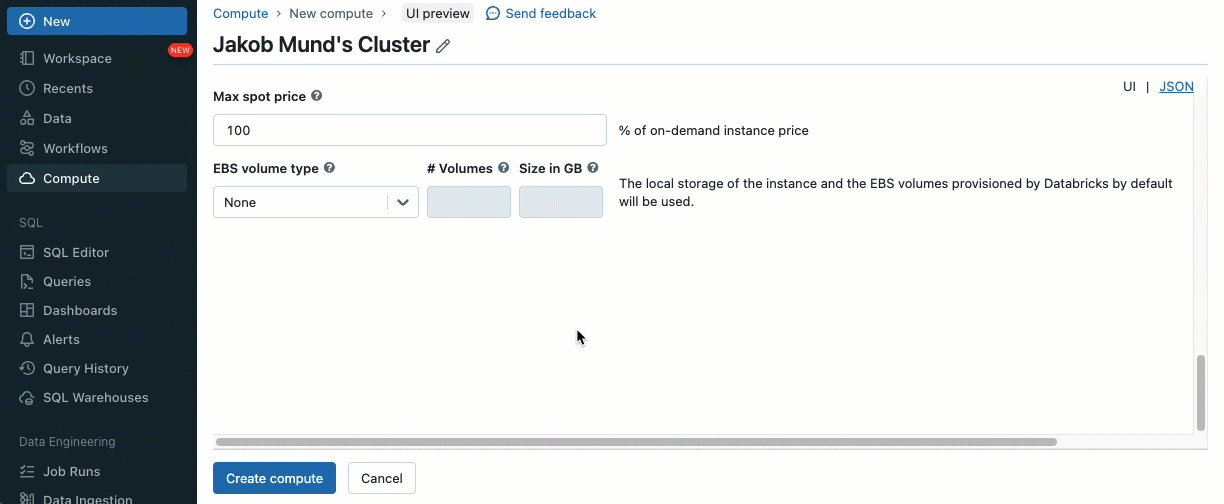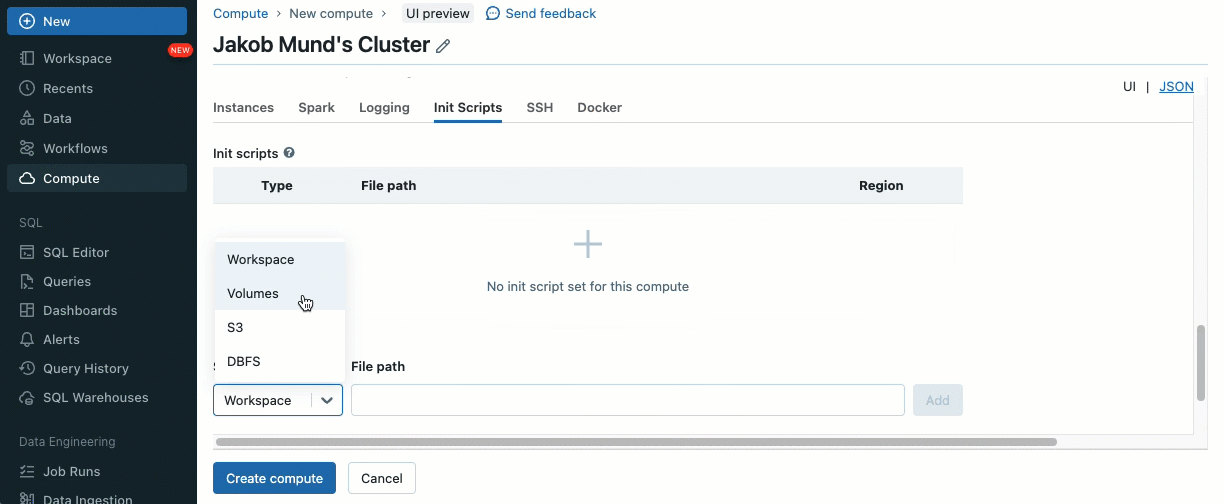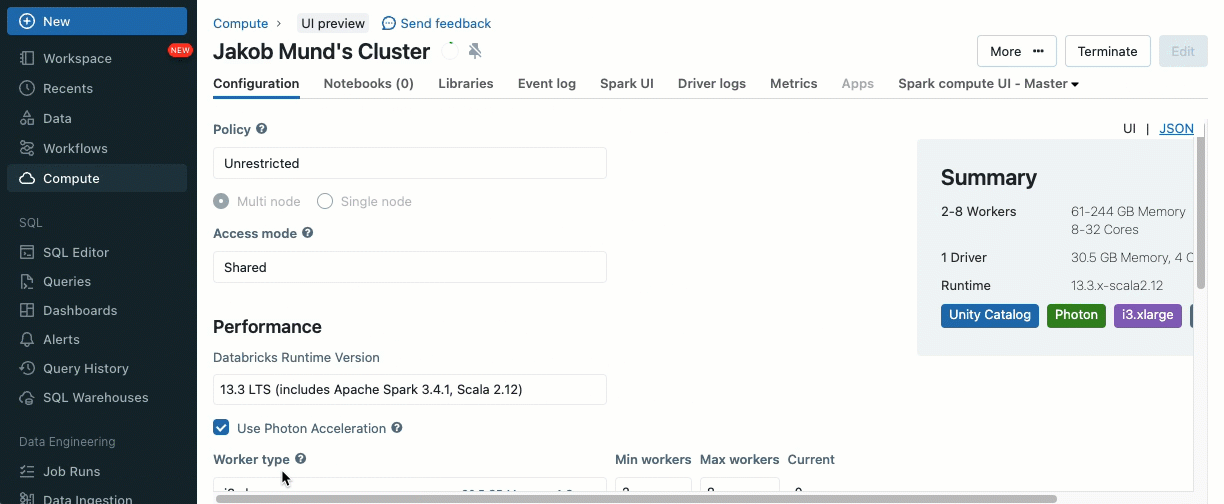
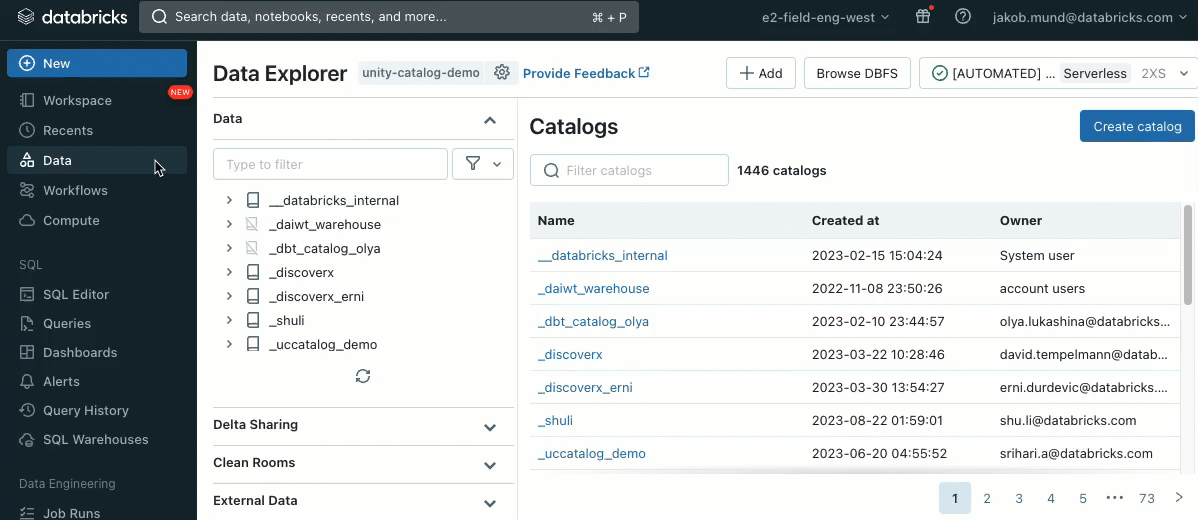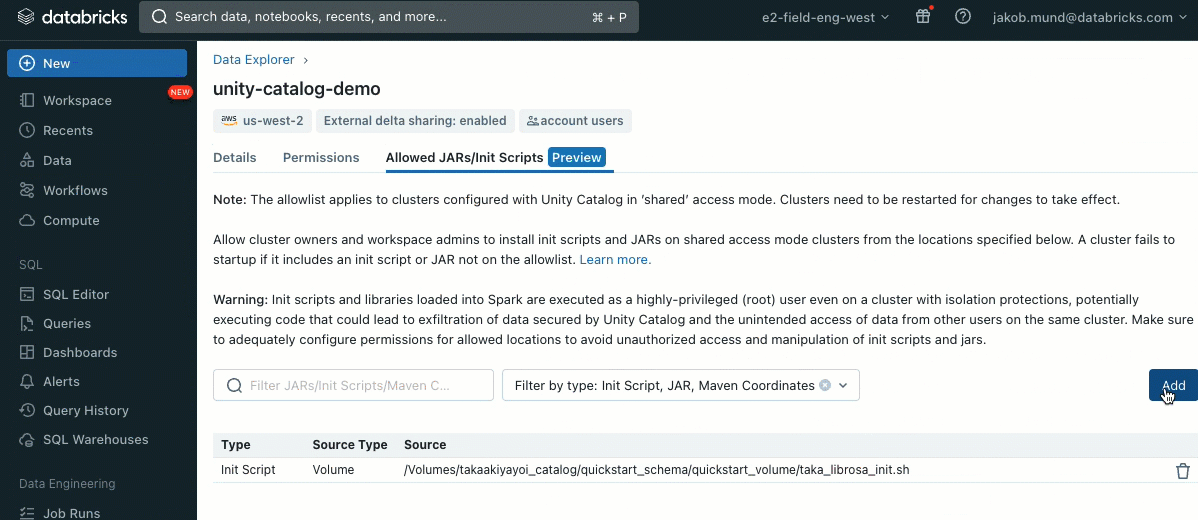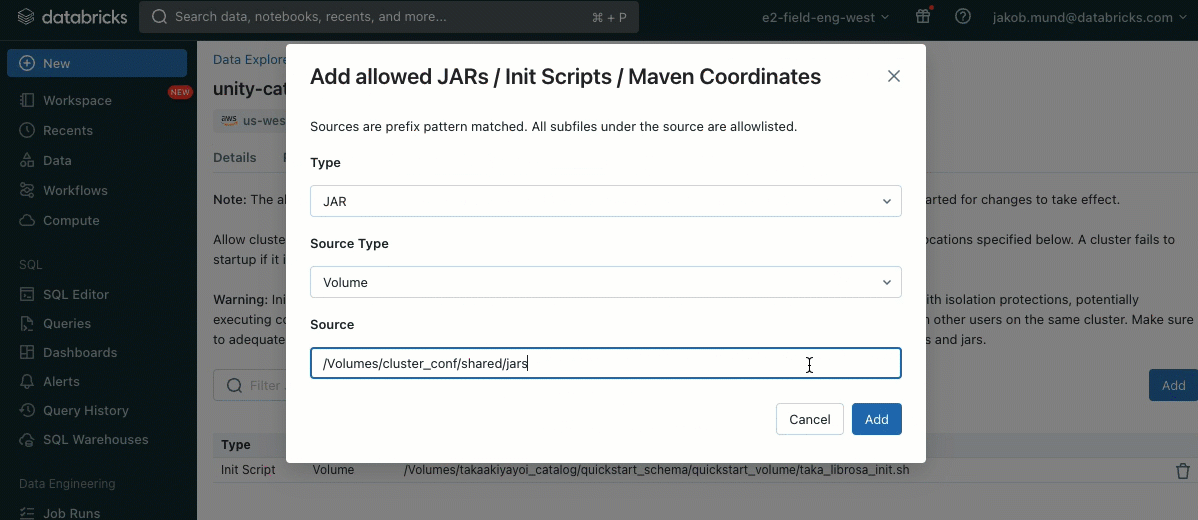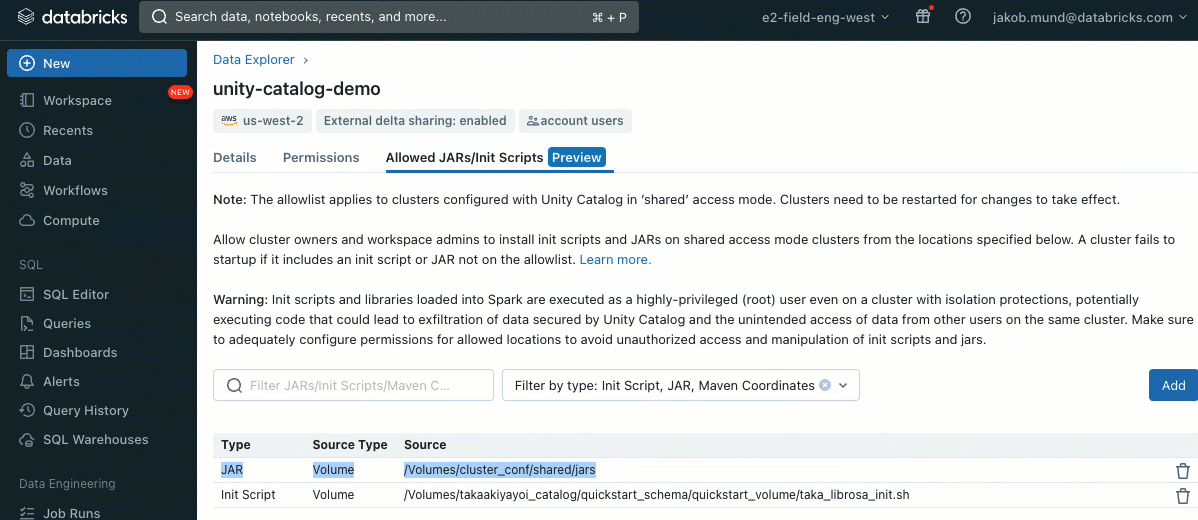
추가 보안 계층으로, 클러스터 라이브러리(jar) 및 초기화 스크립트 설치를 관리하는 허용 목록(AWS, Azure, GCP)을 도입했습니다. 이를 통해 관리자는 공유 클러스터에서 이를 관리할 수 있습니다. 각 메타스토어에 대해 메타스토어 관리자는 라이브러리(jar) 및 초기화 스크립트를 설치할 수 있는 볼륨 및 클라우드 스토리지 위치를 구성하여 신뢰할 수 있는 리소스의 중앙 집중식 저장소를 제공하고 무단 설치를 방지할 수 있습니다. 이를 통해 클러스터 구성에 대한 더 세분화된 제어가 가능하며 조직의 데이터 워크플로우 전반에 걸쳐 일관성을 유지하는 데 도움이 됩니다.
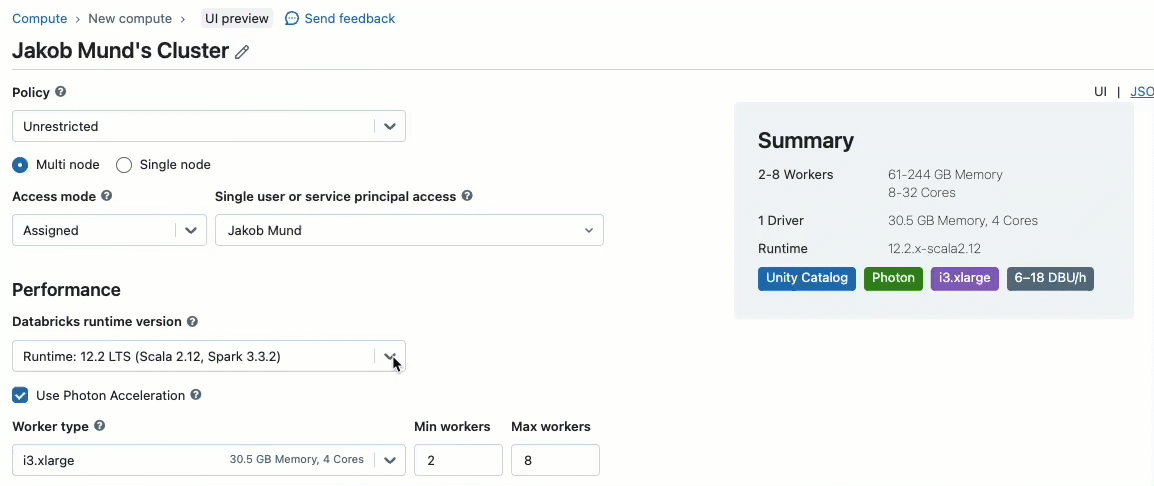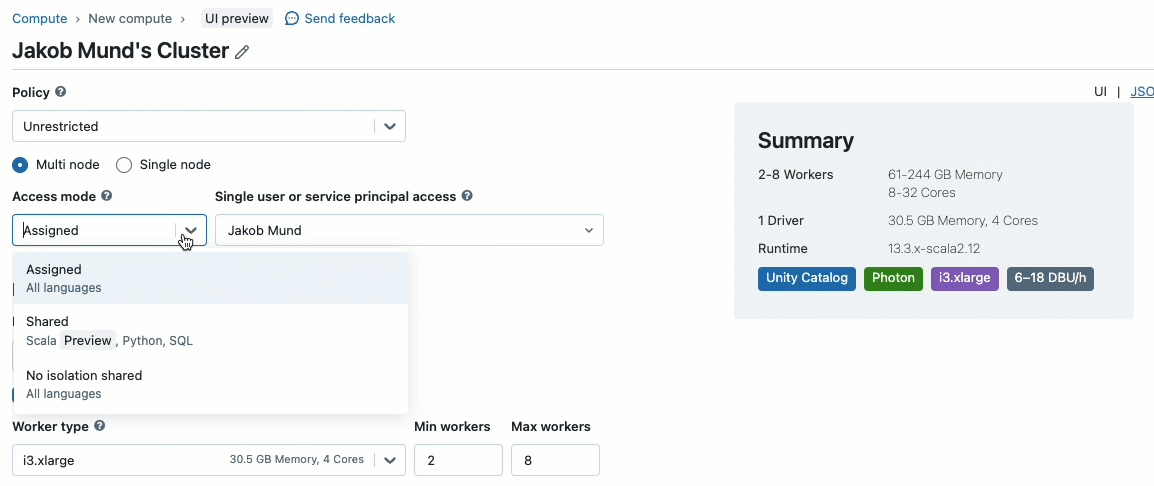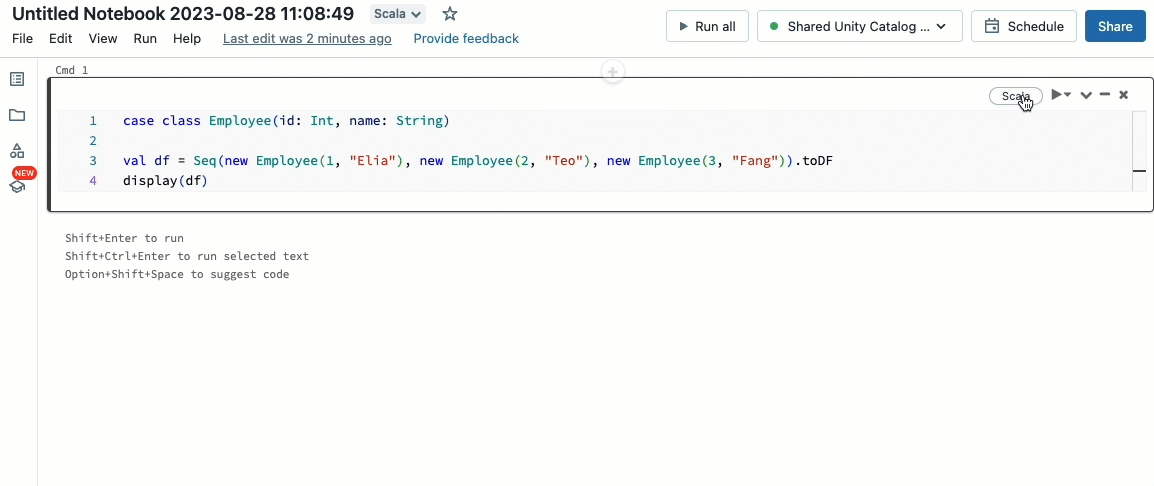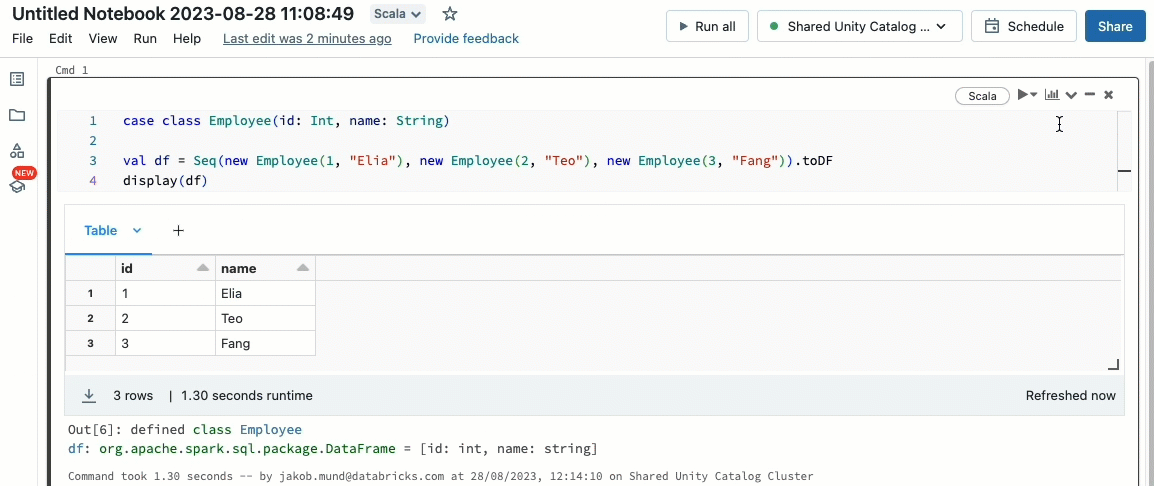
Scala 워크로드 가져오기
이제 Unity Catalog에서 관리하는 공유 클러스터에서 Scala를 지원합니다. 데이터 엔지니어는 Scala의 유연성과 성능을 활용하여 모든 종류의 빅데이터 문제를 동일한 클러스터에서 협업적으로 처리하고 Unity Catalog 거버넌스 모델의 이점을 누릴 수 있습니다.
기존 Databricks 워크플로우에 Scala를 통합하는 것은 매우 쉽습니다. 공유 클러스터를 만들 때 Databricks runtime 13.3 LTS 이상을 선택하기만 하면 다른 지원 언어와 함께 Scala 코드를 작성하고 실행할 준비가 된 것입니다.
사용자 정의 함수(UDF), 머신러닝 및 구조적 스트리밍 활용
그것만이 전부가 아닙니다! 공유 클러스터에 대한 더 많은 게임 체인저급 발전을 발표하게 되어 기쁩니다.
Python 및 Pandas 사용자 정의 함수(UDF) 지원: 이제 공유 클러스터에서도 Python 및 (스칼라) Pandas UDF의 강력한 기능을 활용할 수 있습니다. 코드 수정 없이 워크로드를 공유 클러스터로 원활하게 가져오기만 하면 됩니다. UDF 사용자 코드를 샌드박스 환경의 Spark 실행기에서 격리하여 실행함으로써 공유 클러스터는 데이터에 대한 추가적인 보호 계층을 제공하여 무단 액세스 및 잠재적 침해를 방지합니다.
Spark 드라이버 노드 및 MLflow를 사용한 모든 인기 ML 라이브러리 지원: Scikit-learn, XGBoost, prophet 및 기타 인기 있는 ML 라이브러리를 사용하든, 이제 공유 클러스터에서 직접 머신러닝 모델을 원활하게 빌드, 학습 및 배포할 수 있습니다. 모든 사용자를 위해 ML 라이브러리를 설치하려면 새 클러스터 라이브러리를 사용할 수 있습니다. MLflow(2.2.0 이상)와의 통합 지원을 통해 엔드투엔드 머신러닝 라이프사이클 관리가 그 어느 때보다 쉬워졌습니다.
구조적 스트리밍도 이제 Unity Catalog에서 관리하는 공유 클러스터에서 사용할 수 있습니다. 이 혁신적인 추가 기능은 실시간 데이터 처리 및 분석을 가능하게 하여 데이터 팀이 스트리밍 워크로드를 협업적으로 처리하는 방식을 혁신합니다.
지금 시작하세요, 앞으로 더 많은 좋은 소식이 있습니다
Databricks Runtime 13.3 LTS 이상을 사용하여 Scala, 클러스터 라이브러리, Python UDF, 단일 노드 ML 및 공유 클러스터에서의 스트리밍 기능을 지금 바로 알아보세요. 자세한 내용과 데이터 우수성을 향한 여정을 시작하려면 빠른 시작 가이드(AWS, Azure, GCP)를 참조하세요.
앞으로 몇 주 및 몇 달 동안 Unity Catalog의 컴퓨팅 아키텍처를 계속 통합하여 Unity Catalog를 더욱 쉽게 사용할 수 있도록 만들 것입니다!
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.