제조업을 위한 솔루션즈 액셀러레이터
작성자: 윌 블록, Ramdas Murali, 니콜 루 , Bala Amavasai

Google의 Vaswani et. al. 이 발표한 트랜스포머에 대한 획기적인 논문 이후, 대규모 언어 모델(LLM)이 생성형 AI 분야를 지배하게 되었습니다. 의심할 여지 없이 OpenAI의 ChatGPT 의 등장은 대중의 큰 관심을 불러일으켰으며, 개인용과 기업용 모두에서 LLM 사용에 대한 관심이 높아지는 계기가 되었습니다. 최근 몇 달 동안 Google은 Bard 를 출시했고 Meta는 Llama 2 모델을 출시하며 거대 기술 기업 간의 치열한 경쟁을 보여주고 있습니다.
제조 및 에너지 산업은 운영 비용 상승으로 인해 생산성을 더욱 높여야 하는 과제에 직면해 있습니다. 데이터를 중시하는 기업들은 AI에 투자하고 있으며, 최근에는 LLM에 투자하고 있습니다. 본질적으로 데이터를 중시하는 기업들은 이러한 투자를 통해 막대한 가치를 창출하고 있습니다.
Databricks는 AI 기술의 대중화를 믿습니다. 저희는 모든 기업이 자체 LLM을 훈련할 수 있는 능력을 갖추어야 하며, 자체 데이터와 모델을 소유해야 한다고 믿습니다. 제조 및 에너지 산업에서는 많은 프로세스가 독점적이며, 이러한 프로세스는 치열한 경쟁 속에서 선두를 유지하거나 운영 마진을 개선하는 데 매우 중요합니다. 핵심 비법은 특허나 출판물을 통해 공개되는 대신 영업 비밀로 유지되어 보호됩니다. 공개적으로 사용 가능한 많은 LLM은 지식의 양도를 요구하는 이러한 기본 요구 사항을 준수하지 않습니다.
사용 사례 측면에서 이 산업에서 자주 제기되는 질문은 더 많은 앱과 데이터로 부담을 주지 않으면서 현재 인력의 역량을 어떻게 강화할 것인가 하는 점입니다. 여기에 인력에게 더 많은 AI 기반 앱을 구축하고 제공해야 하는 과제가 있습니다. 하지만 생성형 AI와 LLM의 부상으로, 저희는 이러한 LLM 기반 앱이 여러 앱에 대한 의존도를 줄이고 지식 증강 기능을 더 적은 수의 앱으로 통합할 수 있다고 믿습니다.
산업의 여러 사용 사례에서 LLM을 활용할 수 있습니다. 예시는 다음과 같으며 이에 국한되지 않습니다.
- 고객 지원 상담원 역량 강화. 고객 지원 상담원은 해당 고객에게 어떤 미결/미해결 문제가 있는지 query하고 AI 기반 스크립트를 제공하여 고객을 지원하기를 원합니다.
- 대화형 교육을 통한 도메인 지식의 확보 및 전파. 이 산업은 흔히 "부족" 지식이라고 묘사되는 깊은 노하우에 의해 좌우됩니다. 인력의 고령화와 함께 이 도메인 지식을 영구적으로 확보해야 하는 과제가 따릅니다. LLM은 지식의 저장소 역할을 할 수 있으며, 이를 교육용으로 쉽게 전파할 수 있습니다.
- 현장 서비스 엔지니어의 진단 능력 강화. 현장 서비스 엔지니어는 서로 얽혀 있는 수많은 문서에 액세스하는 데 어려움을 겪는 경우가 많습니다. LLM을 사용하여 문제 진단에 걸리는 시간을 줄이면 결과적으로 효율성이 향상될 것입니다.
이 솔루션 액셀러레이터에서는 위의 (3)번 항목, 즉 대화형 컨텍스트 인식 Q&A 세션 형태의 기술 자료를 통해 현장 서비스 엔지니어의 역량을 강화하는 사용 사례에 중점을 둡니다. 제조업체가 직면한 과제는 독점 문서의 데이터를 LLM에 구축하고 통합하는 방법입니다. LLM을 처음부터 훈련시키는 것은 수십만 달러, 많게는 수백만 달러의 비용이 드는 매우 값비싼 작업입니다.
대신, 기업은 MosaicML의 MPT-7B 및 MPT-30B 와 같은 사전 훈련된 기본 LLM 모델을 활용하고, 자체 독점 데이터로 이러한 모델을 보강하고 미세 조정할 수 있습니다. 이를 통해 비용을 수십, 혹은 수백 달러로 낮출 수 있어 실질적으로 10,000배의 비용을 절감할 수 있습니다. 아래 그림 1에서 미세 조정을 위한 전체 경로는 왼쪽에서 오른쪽으로, Q/A 쿼리 경로는 오른쪽에서 왼쪽으로 표시됩니다.
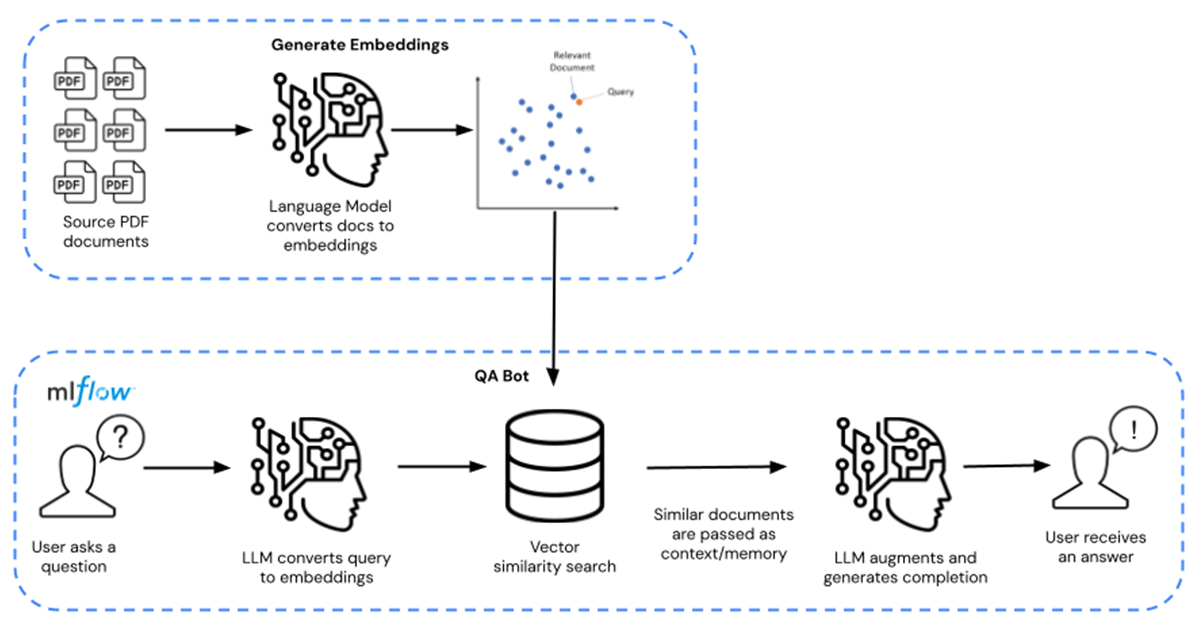
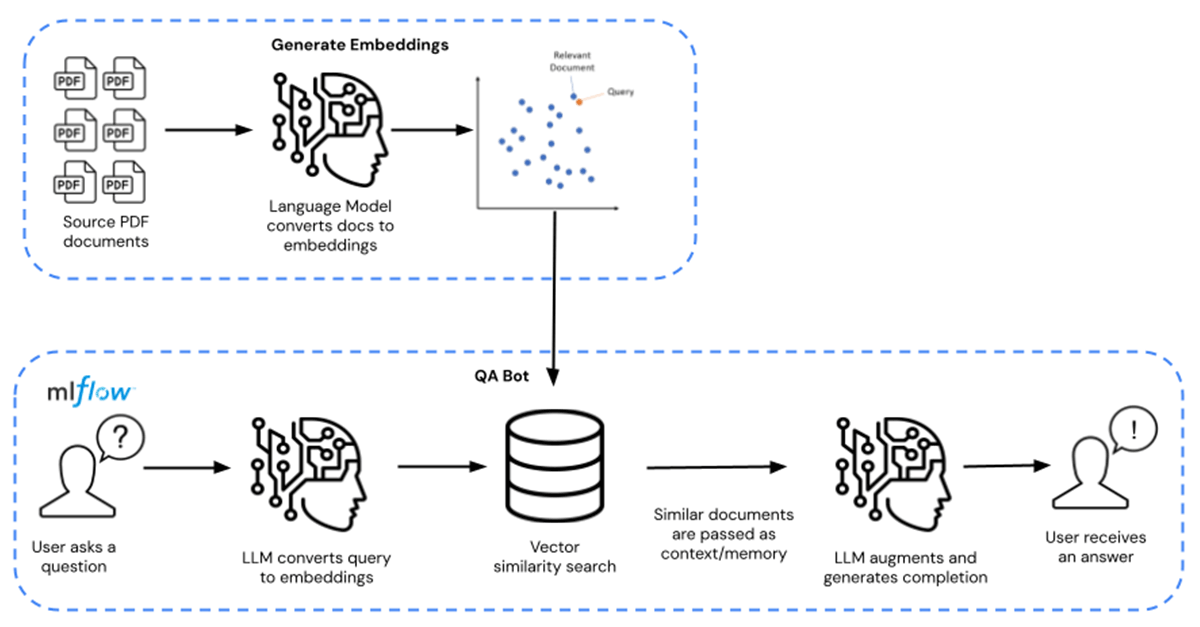{kind=link}
이 솔루션 액셀러레이터에서 LLM은 공개적으로 사용 가능한 PDF 문서 형태로 배포되는 화학 물질 자료표를 통해 보강됩니다. 원하는 모든 독점 데이터로 대체할 수 있습니다. 자료표는 임베딩으로 변환되어 모델의 리트리버로 사용됩니다. 그런 다음 Langchain 을 사용하여 모델을 컴파일했으며, 이 모델은 Databricks MLflow에서 호스팅됩니다. 배포는 GPU 추론 기능을 갖춘 Databricks 모델 서빙 엔드포인트 형태를 취합니다.
여기에서 이 자산을 다운로드하여 지금 바로 귀사의 역량을 강화하세요. Databricks 담당자에게 문의하여 Databricks가 LLM을 구축하고 제공하는 데 최적의 플랫폼인 이유를 자세히 알아보세요.
여기에서 솔루션 액셀러레이터를 살펴보세요.
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.