머신러닝 파이프라인이란 무엇인가요?
머신러닝 파이프라인이 데이터 전처리부터 모델 검증까지 머신러닝 워크플로우를 자동화하고 간소화하는 방법을 알아보세요.
작성자: Databricks 직원
- ML 파이프라인이 무엇이며, 전처리, 특징 추출, 모델 학습 및 검증을 하나의 통합 워크플로로 어떻게 연결하는지 이해합니다.
- 두 가지 핵심 파이프라인 단계 유형인 Transformer와 Estimator의 차이점을 알아봅니다.
- Spark ML Pipelines가 기본 제공되는 파이프라인 생성 및 튜닝 기능을 통해 확장 가능하고 분산된 머신 러닝을 어떻게 구현하는지 살펴봅니다.
머신 러닝 파이프라인이란 무엇인가요? 머신 러닝 파이프라인이란 무엇인가요? 일반적으로 머신 러닝 알고리즘을 실행할 때는 전처리, 기능 추출, 적합한 모델 찾기(model fitting) 검증 단계로 구성된 시퀀스를 거쳐야 합니다. 예를 들어 텍스트 문서를 분류하는 경우, 텍스트 조각화와 정리, 특징 추출, 교차 검증을 통한 분류 모델 교육 등의 작업을 거치게 됩니다. 각 단계에 사용할 수 있는 라이브러리는 많지만, 단편적인 정보를 연결해 결론을 내기란 보기보다 어려울 수 있습니다. 특히 대규모 Dataset인 경우 쉽지 않은 일입니다. 대부분의 ML 라이브러리는 분산형 연산을 염두에 두고 고안한 것이 아니거나, 파이프라인 만들기와 튜닝에 네이티브 지원을 제공하지 않습니다. 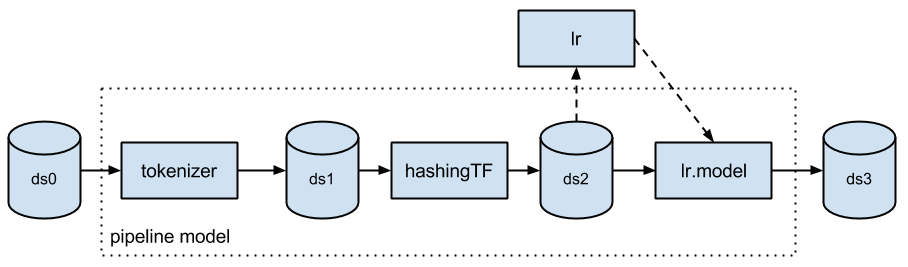 ML 파이프라인은 MLlib용 고수준 API로 "spark.ml" 패키지에 있습니다. 파이프라인은 여러 단계로 이루어진 시퀀스 하나로 구성됩니다. 파이프라인 단계에는 기본적으로 두 가지 유형이 있습니다. Transformer와 Estimator입니다. Transformer의 경우, Dataset를 입력으�로 취해 증강된 버전의 Dataset를 출력으로 내놓습니다. 예: tokenizer는 텍스트를 포함한 Dataset를 토큰화한 단어를 포함한 Dataset로 변환하는 Transformer입니다. Estimator의 경우, 우선 입력 Dataset에 맞아야 모델을 도출할 수 있는데, 이것은 입력 Dataset를 변환하는 Transformer의 일종입니다. 예: 논리적 회귀(logistic regression)는 레이블과 특징을 포함한 Dataset에서 학습하여 논리적 회귀 모델을 도출하는 Estimator입니다.
ML 파이프라인은 MLlib용 고수준 API로 "spark.ml" 패키지에 있습니다. 파이프라인은 여러 단계로 이루어진 시퀀스 하나로 구성됩니다. 파이프라인 단계에는 기본적으로 두 가지 유형이 있습니다. Transformer와 Estimator입니다. Transformer의 경우, Dataset를 입력으�로 취해 증강된 버전의 Dataset를 출력으로 내놓습니다. 예: tokenizer는 텍스트를 포함한 Dataset를 토큰화한 단어를 포함한 Dataset로 변환하는 Transformer입니다. Estimator의 경우, 우선 입력 Dataset에 맞아야 모델을 도출할 수 있는데, 이것은 입력 Dataset를 변환하는 Transformer의 일종입니다. 예: 논리적 회귀(logistic regression)는 레이블과 특징을 포함한 Dataset에서 학습하여 논리적 회귀 모델을 도출하는 Estimator입니다.
추가 자료
기업을 위한 에이전틱 AI 플레이북

최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.