람다 아키텍처란 무엇인가요?
배치 처리와 스트림 처리를 결합한 아키텍처로, 정확도를 위한 배치 계층, 실시간 결과를 위한 속도 계층, 그리고 이 둘을 통합하는 서비스 계층으로 구성됩니다.
작성자: Databricks 직원
- 배치 계층은 마스터 데이터셋을 변경 불가능한 추가 전용 형태로 저장하고, MapReduce 방식의 처리를 통해 배치 뷰를 미리 계산하여 정확하고 포괄적인 결과를 제공하지만, 몇 시간의 지연 시간이 발생합니다.
- 속도 계층은 Storm이나 Flink와 같은 저지연 시스템을 사용하여 최근 데이터 스트림만 처리하고, 배치 뷰가 업데이트될 때 최종 일관성을 유지하면서 배치 계층의 지연을 보완하는 실시간 뷰를 생성합니다.
- 서비스 계층은 배치 뷰와 속도 뷰를 인덱싱하여 두 가지 관점을 통합한 빠른 임시 쿼리를 가능하게 합니다. Apache Spark와 같은 스트리밍 시스템이 배치 및 실시간 기능을 모두 제공함에 따라 아키텍처 복잡성은 감소했습니다.
Lambda 아키텍처란 무엇입니까?
Lambda 아키텍처는 엄청난 대량의 데이터(즉 “빅데이터”)를 처리하는 방식의 일종으로, 하이브리드 방식으로 일괄 처리나 스트림 처리 방식을 이용할 수 있게 해줍니다. Lambda 아키텍처는 임의 함수 연산 문제를 해결하는 데 쓰입니다. Lambda 아키텍처 자체는 3개의 계층으로 이루어져 있습니다.
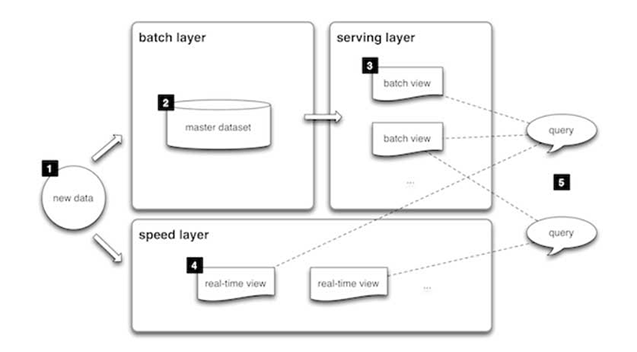
배치 계층
새로운 데이터는 데이터 시스템에 일종의 피드 형태로 끊임없이 유입됩니다. 이것을 배치 계층과 속도 계층에 동시에 주입합니다. 그러면 데이터 전체를 한꺼번에 조회하고 결과적으로는 스트림 계층에서 데이터를 수정합니다. 여기에는 ETL이 많고 일반적인 데이터 웨어하우스도 있습니다. 이 계층은 미리 정의한 일정을 사용해(보통 하루에 한두 번) 구축합니다. 배치 계층에는 두 가지 아주 중요한 기능이 있습니다.
- 마스터 Dataset 관리
- 배치 보기 사전 계산의 두 가지입니다.
서빙 계층
배치 계층에서 배치 보기 형식으로 도출한 출력과 속도 계층에서 거의 실시간 보기 형식으로 도출한 출력은 서빙 계층에 전달됩니다. 이 계층은 배치 보기를 인덱싱해 애드혹(ad-hoc) 방식으로, 짧은 레이턴시로 쿼리할 수 있게 해줍니다.
속도 계층(스트림 계층)
이 계층은 배치 계층의 레이턴시로 인해 이미 배치 보기로 전달되지 못한 데이터를 처리합니다. 또한 이 계층은 최신 데이터만 다루어서 실시간 보기를 생성해 사용자에게 완전한 데이터 보기를 제공합니다.
기업을 위한 에이전틱 AI 플레이북

Lambda 아키텍처의 장점
lambda 아키텍처의 주된 장점은 다음과 같습니다.
- 서버 관리 없음 – 소프트웨어 설치, 유지나 관리 필요가 전혀 없습니다.
- 유연한 확장 – 애플리케이션을 자동으로 확장할 수도 있고, 용량을 조정하여 확장할 수도 있습니다.
- 자동 고가용성 – 서버리스 애플리케이션에는 이미 기본 내장된 가용성과 내결함성이 있다는 사실을 가리킵니다. 이는 모든 요청에 대하여 요청이 성공했는지 아닌지 응답을 받도록 보장된다는 뜻입니다.
- 비즈니스 민첩성 – 변화하는 비즈니스/시장 상황에 따라 실시간으로 반응합니다.
Lambda 아키텍처의 문제점
- 복잡함 – lambda 아키텍처는 고도로 복잡할 수 있습니다. 보통 관리자가 배치 계층, 스트리밍 계층용으로 코드 베이스를 별도로 두 개 유지해야 하는데, 이 때문에 디버깅이 어렵습니다.
관련 콘텐츠
Delta Lake: 통합형 배치 및 스트리밍 소스와 싱크
추가 자료
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.