주요 컨텐츠로 이동
복원력 있는 분산 데이터셋(RDD)이란 무엇인가요?
분산형, 내결함성 병렬 처리를 위한 Spark의 기본 데이터 구조를 이해합니다.
작성자: Databricks 직원
- RDD가 무엇이며 Apache Spark에서 병렬 처리를 위한 불변의 파티션 데이터 모음으로 어떻게 사용되는지 이해합니다.
- 비정형 데이터 및 저수준 변환 제어를 포함하여 RDD를 선택해야 하는 다섯 가지 주요 시나리오를 알아봅니다.
- RDD가 DataFrame 및 DataSet과 어떤 관계가 있는지, 그리고 각 API를 언제 사용해야 하는지 살펴봅니다.
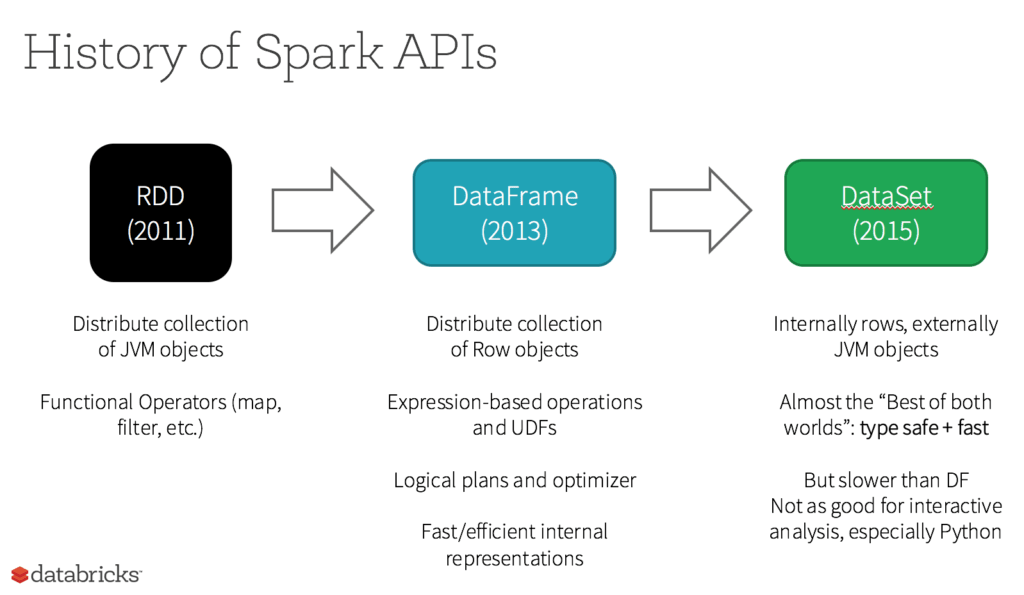
RDD는 처음 생겼을 때부터 Spar의 기본 사용자 대상(user-facing) API였습니다. RDD는 본질적으로 데이터의 여러 요소를 모은 변경 불가능한(immutable) 분산형 컬렉션입니다. 클러스터 내 여러 노드에 걸쳐 분할된 형태로 변환이나 작업을 제공하는 저수준 API와 동시에 작업할 수 있습니다.
RDD를 사용해야 할 때를 결정짓는 5가지 이유
- Dataset에서 저수준 변환, 작업과 제어를 원하는 경우.
- 데이터가 비구조적인 경우(미디어 스트림 또는 텍스트 스트림 등).
- 도메인별 표현식 말고 함수 프로그래밍 구조로 데이터를 조작하고자 하는 경우.
- 이름이나 열 기준으로 데이터 속성을 처리 또는 이에 액세스하면서 열 형식과 같은 스키마를 부여하는 데 관심이 없는 경우.
- 구조적, 비구조적 데이터에 대하여 DataFrame과 Dataset가 제공하는 최적화와 성능 면에서의 장점을 일부 포기할 수 있는 경우.
보고서
기업을 위한 에이전틱 AI 플레이북

Apache Spark 2.0에서 RDD에는 무슨 일이 일어납니까?
RDD는 2급 시민으로 강등됩니까? 사용이 중단됩니까? 이런 질문에 대한 답은 '아니요'입니다! 뿐만 아니라 단순한 API 메서드 호출을 통해 DataFrame이나 Dataset와 RDD 사이를 원활하게 이동할 수 있으며 DataFrame과 Dataset는 RDD 기반으로 구축되었습니다.
추가 자료
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.