하둡 생태계란 무엇인가요?
HDFS, MapReduce, YARN, Hive, Spark 등 방대한 데이터 세트를 저장, 처리 및 분석하기 위해 함께 작동하는 포괄적인 오픈 소스 도구 모음입니다.
작성자: Databricks 직원
- HDFS는 NameNode 및 DataNode 아키텍처를 사용하여 내결함성 분산 스토리지를 제공하고, YARN은 클러스터 리소스를 관리하며, MapReduce는 병렬 데이터 처리를 담당합니다.
- Apache Hive는 데이터 웨어하우스 운영을 위한 HiveQL을 통해 SQL과 유사한 쿼리 기능을 제공하고, Apache Spark는 실시간 분석 및 머신 러닝을 위한 인메모리 처리를 제공합니다.
- 이 에코시스템에는 스크립팅 도구인 Pig, NoSQL 스토리지 도구인 HBase, 워크플로 스케줄링 도구인 Oozie, Hadoop과 관계형 데이터베이스 간 데이터 전송 도구인 Sqoop과 같은 보완적인 도구들이 포함됩니다.
하둡 에코시스템이란 무엇입니까?
Apache Hadoop 에코시스템은 Hadoop 소프트웨어 라이브러리를 구성하는 다양한 오픈 소스 컴포넌트들의 집합입니다. 다양한 오픈 소스 프로젝트와 보조 도구들이 함께 포함되어 있습니다. 하둡 에코시스템 중에서 가장 잘 알려진 툴을 몇 가지만 예로 들면 HDFS, Hive, Pig, YARN, MapReduce, Spark, HBase , Oozie, Sqoop, Zookeeper 등이 있습니다. 개발자가 자주 사용하는 주요 하둡 에코시스템 구성 요소를 소개하면 다음과 같습니다.
HDFS란 무엇입니까?
Hadoop Distributed File System(HDFS)은 Apache에서 가장 큰 프로젝트 중 하나이며 하둡의 기본 스토리지 시스템입니다. NameNode와 DataNode 아키텍처를 사용합니다. 분산형 파일 시스템으로 상용 하드웨어 클러스터에서 실행되는 큰 파일을 저장할 수 있습니다.
Hive란 무엇입니까?
Hive는 하둡 에코시스템 내에 저장된 대형 Dataset를 쿼리하거나 분석하는 데 쓰이는 ETL 및 데이터 웨어하우징 툴입니다. Hive에는 크게 세 가지 기능이 있습니다. 데이터 요약, 쿼리, 그리고 하둡에 저장된 비구조적, 반구조적 데이터 분석입니다. 여기에는 SQL과 유사한 인터페이스, SQL과 작동 원리가 비슷한 HQL 언어가 있어 쿼리를 자동으로 MapReduce 작업으로 변환합니다.
Apache Pig란 무엇입니까?
하둡 내에서 쓰이는 크기가 큰 Dataset의 쿼리를 실행하는 데 쓰는 고수준 스크립팅 언어입니다. Pig의 단순하고 SQL과 비슷한 스크립팅 언어를 일명 Pig Latin이라고 하며, 이 언어의 주된 목표는 필요한 작업을 수행하고 최종 출력을 바람직한 형식으로 배열하는 데 있습니다.
기업을 위한 에이전틱 AI 플레이북

MapReduce란 무엇입니까?
 하둡의 데이터 처리 계층의 일종입니다. 여기에는 크기가 큰 구조적 데이터, 비구조적 데이터를 처리하는 기능도 있고 크기가 매우 큰 파일을 병렬식으로 관리할 수도 있습니다. 이를 위해 작업을 일련의 독립적 작업(sub-job, 하위 작업)으로 나눕니다.
하둡의 데이터 처리 계층의 일종입니다. 여기에는 크기가 큰 구조적 데이터, 비구조적 데이터를 처리하는 기능도 있고 크기가 매우 큰 파일을 병렬식으로 관리할 수도 있습니다. 이를 위해 작업을 일련의 독립적 작업(sub-job, 하위 작업)으로 나눕니다.
YARN이란 무엇입니까?
YARN은 Yet Another Resource Negotiator의 약어인데, 통상 약어만 써서 지칭합니다. 이것은 오픈 소스 Apache Hadoop의 핵심 구성 요소 중 하나로, 리소스 관리에 적합합니다. 워크로드 관리, 모니터링, 보안 관리 구현 등의 작업을 담당합니다. 또한 하둡 클러스터 내 여러 애플리케이션에 리소스를 배분하고, 각 노드의 작업 실행을 효율적으로 조정합니다. YARN은 크게 두 가지 구성 요소로 이루어져 있습니다.
- 리소스 관리자
- 노드 관리자
Apache Spark란 ?
Apache Spark는 무척 광범위한 상황에 사용하기 적합한 고속, 메모리 내 데이터 처리 엔진입니다. Spark는 Java, Python, Scala, R 등 다양한 언어를 지원하며, SQL 쿼리·스트리밍 데이터·머신러닝·그래프 분석을 단일 애플리케이션에서 통합 수행할 수 있습니다. 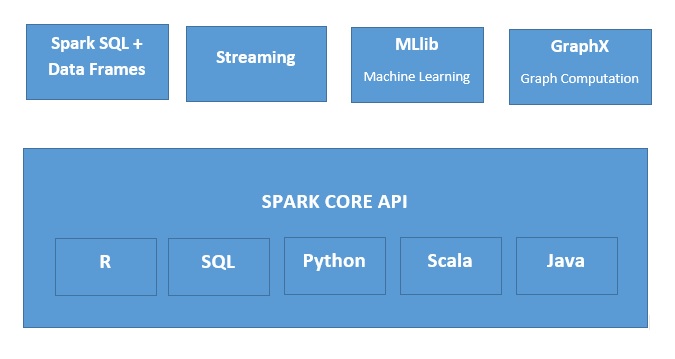
추가 자료
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.