Sparklyr란 무엇인가요?
R 패키지로, Apache Spark에서 dplyr 스타일 구문을 제공하여 R 사용자가 대규모 데이터 세트에 대한 분산 데이터 조작 및 머신 러닝을 수행할 수 있도록 합니다.
작성자: Databricks 직원
- 익숙한 tidyverse dplyr 구문(select, filter, mutate, group_by)을 제공하여 로컬 R 처리에 비해 너무 큰 데이터 세트에 대한 분산 Spark 작업으로 원활하게 변환할 수 있습니다.
- Spark MLlib 및 H2O SparkingWater와 통합되어 분산 머신 러닝을 지원하며, spark_apply를 통해 사용자 정의 함수를 지원하여 대규모 맞춤형 R 계산을 수행할 수 있습니다.
- spark_connect의 'databricks' 메서드를 통해 Databricks 클러스터에 연결되며, SparkR과 함께 작동하고 RStudio와 호환되어 대화형 개발 및 디버깅이 가능합니다.
Sparklyr이란 무엇입니까?
Sparklyr은 R과 Apache Spark 사이에서 인터페이스를 제공하는 오픈 소스 패키지입니다. 이제 Spark 기능을 최신 R 환경에서도 활용할 수 있습니다. Spark는 분산된 데이터와 상호작용할 수 있으면서도 레이턴시가 짧기 때문입니다. Sparklyr은 인터랙티브 환경에서 대규모 Dataset와 상호작용을 주고받는 데 효과적인 툴입니다. 이렇게 하면 R의 친숙한 툴을 이용해 Spark 데이터를 분석할 수 있으므로 두 분야의 가장 좋은 점만 활용할 수 있습니다. 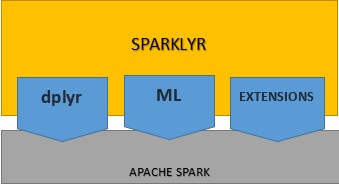 Sparklyr을 통해 Spark를 dplyr 백엔드로 사용할 수 있습니다. dplyr은 대중적인 데이터 조작 패키지입니다. Sparklyr에는 다양한 기능이 포함되어 있어 Spark 툴에 액세스하여 데이터를 변환/전처리할 수 있습니다. 그뿐만이 아니라, Spark의 분산형 머신 러닝 알고리즘에 인터페이스를 제공하며 이외에도 다양한 장점이 있습니다. 또한 Sparklyr은 확장할 수도 있습니다. 전체 Spark API를 호출하기 위해 Sparklyr에 종속되는 R 패키지를 생성할 수 있습니다. 그와 같은 확장 프로그램의 한 가지 예가 H2O의 Rsparkling으로, 이것은 H2O의 머신 러닝 알고리즘과 호환되는 R 패키지입니다.
Sparklyr을 통해 Spark를 dplyr 백엔드로 사용할 수 있습니다. dplyr은 대중적인 데이터 조작 패키지입니다. Sparklyr에는 다양한 기능이 포함되어 있어 Spark 툴에 액세스하여 데이터를 변환/전처리할 수 있습니다. 그뿐만이 아니라, Spark의 분산형 머신 러닝 알고리즘에 인터페이스를 제공하며 이외에도 다양한 장점이 있습니다. 또한 Sparklyr은 확장할 수도 있습니다. 전체 Spark API를 호출하기 위해 Sparklyr에 종속되는 R 패키지를 생성할 수 있습니다. 그와 같은 확장 프로그램의 한 가지 예가 H2O의 Rsparkling으로, 이것은 H2O의 머신 러닝 알고리즘과 호환되는 R 패키지입니다.
기업을 �위한 에이전틱 AI 플레이북

Sparklyr의 주요 하이라이트:
- 사용자는 SQL(DBI를 통함)은 물론 dplyr을 사용해서도 Spark 데이터를 대화형으로 조작할 수 있습니다.
- Spark Dataset는 필터링, 집계한 다음 R로 가져와 분석할 수 있습니다.
- R 환경에서 분산형 머신 러닝을 구성하고 실행하려면 Spark MLlib이나 H2O SparkingWater를 활용할 수 있습니다.
- Sparklyr 사용자는 확장 프로그램을 생성하여 전체 Spark API를 호출하고 Spark 패키지에 인터페이스를 제공할 수 있습니다.
- Sparklyr 툴이 완전한 dplyr 백엔드를 제공하여 데이터 조작, 분석 및 시각화에 유용하게 쓸 수 있습니다.
- 로컬 R 데이터 프레임, Hive 테이블, CSV, JSON과 Parquet 파일 등과 같은 다양한 위치에서 데이터를 Spark DataFrames로 로드합니다.
- Sparklyr은 Spark의 로컬 인스턴스는 물론 원격 Spark 클러스터에도 연결할 수 있습니다.
추가 자료
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.