Databricks에서 지능형 데이터 웨어하우징 - 복제됨
이 참조 아키텍처는 Databricks Data Intelligence Platform이 스트리밍 및 배치 수집, 거버넌스 스토리지, 확장 가능한 SQL 분석 및 통합 AI를 통합 레이크하우스에서 결합하여 최신 데이터 웨어하우징 및 BI를 가능하게 하는 방법을 보여줍니다.
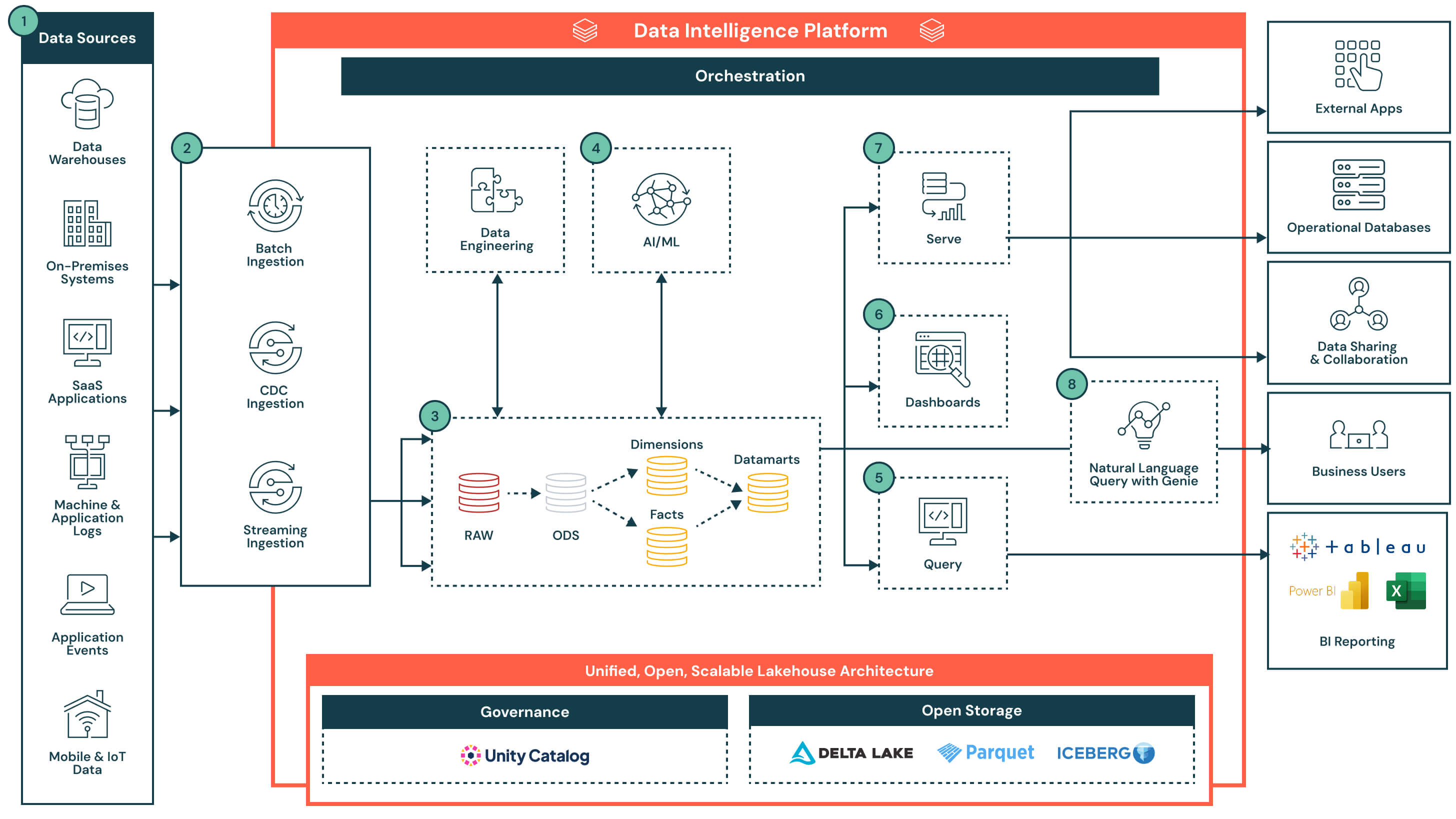
아키텍처 요약
이 아키텍처는 기존 보고, 실시간 대시보드, 예측 모델링 및 셀프 서비스 분석을 지원하며, 동시에 보안, 거버넌스 및 성능에 대한 기업 표준을 충족합니다.
이 솔루션은 Databricks Lakehouse 기반의 Databricks Data Intelligence Platform이 데이터 팀과 비즈니스 이해관계자 모두의 요구를 충족하면서 조직의 데이터 웨어하우징 전략을 현대화하는 데 어떻게 도움이 되는지 보여줍니다.
이 아키텍처는 Unity Catalog가 관리하는 개방적이고 거버넌스되는 레이크하우스로 시작합니다. 운영 데이터베이스, SaaS 앱, 이벤트 스트림 및 파일 시스템을 포함한 다양한 시스템에서 데이터가 수집되어 중앙 스토리지 계층에 저장됩니다. 플랫폼의 데이터 인텔리전스는 ETL 및 SQL 분석부터 대시보드 및 AI 사용 사례에 이르기까지 모든 것을 지원합니다. SQL, BI 도구 및 자연어 쿼리를 통한 유연한 액세스를 지원함으로써 플랫폼은 데이터 제품 제공을 가속화하고 조직 전체에서 인사이트에 접근할 수 있도록 합니다.
사용 사례
기술 사용 사례
- 다양한 소스에서 구조화된, 비구조화된, 배치 및 스트리밍 데이터 수집
- 강력한 선언적 ETL 파이프라인 구축
- 메달리온 아키텍처를 사용하여 팩트, 차원 및 데이터 마트 모델링
- 보고 및 대시보드 작성을 위한 고동시성 SQL 쿼리 실행
- 다운스트림 사용을 위해 ML 출력을 웨어하우스에 직접 통합
비즈니스 사용 사례
- 영업, 운영 또는 고객 지표에 대한 실시간 대시보드 제공
- Genie와 같은 자연어 인터페이스를 통한 즉석 탐색 지원
- 수요 예측 및 이탈 모델링과 같은 예측 사용 사례 지원
- 부서 간 또는 파트너와 거버넌스되는 데이터 제품 공유
- 재무, 마케팅 및 제품 팀을 위한 빠르고 신뢰할 수 있는 인사이트 제공
데이터 인텔리전스의 주요 기능
이 아키텍처의 데이터 인텔리전스 구성 요소는 플랫폼을 더욱 스마트하고 적응력 있게 만들며, 다양한 페르소나와 워크로드에서 사용하기 쉽게 합니다. 이는 시스템 전체에 AI 및 메타데이터 인식을 적용하여 경험을 단순화하고 의사 결정을 자동화합니다.
- 자연어 인터페이스 (Genie): 비즈니스 컨텍스트를 이해하고 사용자가 일반 언어로 데이터 질문을 할 수 있도록 합니다.
- 의미론적 인식: 테이블, 열 및 사용 패턴 간의 관계를 인식하여 조인, 필터 또는 계산을 제안합니다.
- 예측 최적화: 과거 워크로드를 기반으로 쿼리 성능 및 컴퓨팅 할당을 지속적으로 조정합니다.
- 통합 거버넌스: 데이터 자산의 태그 지정, 분류 및 사용 추적을 통해 검색을 더욱 직관적이고 안전하게 만듭니다.
- 주요 기능: 데이터와 사용자에게 적응하는 자체 최적화 플랫폼
- 차별점: 데이터 인텔리전스는 수집, 쿼리, 거버넌스 및 시각화 전반에 걸쳐 내장되어 있으며, 단순히 추가된 것이 아닙니다.
주요 기능 및 차별점을 포함한 데이터 흐름
- 데이터 소스: 데이터는 엔터프라이즈 앱(예: SAP, Salesforce), 데이터베이스, IoT 장치, 애플리케이션 로그 및 외부 API를 포함한 다양한 시스템에 저장됩니다. 이러한 소스는 구조화된, 반구조화된 또는 비구조화된 데이터를 생성할 수 있습니다.
- 데이터 수집: 배치 작업, 변경 데이터 캡처(CDC) 또는 스트리밍을 통해 데이터를 가져옵니다. 이러한 파이프라인은 소스 시스템 및 사용 사례에 따라 거의 실시간 또는 예약된 간격으로 레이크하우스 아키텍처에 데이터를 공급합니다.
- 주요 차별점: 별도의 인프라나 파이프라인 없이 배치, 스트리밍 및 CDC를 포함한 모든 방식에 대한 통합 수집
- 일단 수집된 데이터는 medallion architecture를 통해 변환되고 원시 데이터에서 큐레이션된 데이터로 점진적으로 정제됩니다.
- Raw 존에서 Bronze 존으로: 외부 소스 시스템에서 수집된 데이터로, 이 계층의 구조는 소스 시스템 테이블 구조와 “있는 그대로” 일치하며, 데이터에 대한 변환이나 업데이트는 없습니다.
- Bronze 존에서 Silver 존으로: 들어오는 데이터 표준화 및 정리
- Silver 존에서 Gold 존으로: 재사용 가능한 모델을 생성하기 위해 비즈니스 로직 적용
- 팩트 및 차원 → 데이터 마트: 다운스트림 분석을 위해 데이터 집계 및 큐레이션
- 주요 차별점: 내장된 계보, 관측 가능성 및 스키마 진화를 갖춘 선언적, 프로덕션급 파이프라인
- AI 사용 사례를 위한 큐레이션된 데이터: 데이터 마트에서 큐레이션된 데이터는 머신러닝 모델을 훈련하거나 적용하는 데 사용될 수 있습니다. 이러한 모델은 수요 예측, 이상 감지 및 고객 점수화와 같은 사용 사례를 지원합니다.
- 모델 출력은 SQL 또는 대시보드를 통해 쉽게 액세스할 수 있도록 기존 웨어하우스 데이터와 함께 저장됩니다.
- 결과는 요구 사항에 따라 예약된 일정에 따라 업데이트되거나 실시간으로 점수화될 수 있습니다.
- 주요 차별점: 동일한 플랫폼에서 분석 및 AI 워크로드를 함께 배치 — 데이터 이동이 필요 없습니다. 모델 출력은 기본적이고 쿼리 가능한 거버넌스 자산으로 취급됩니다.
- 내장된 쿼리 편집기 및 쿼리 기록
- 쿼리는 데이터 마트 또는 풍부한 모델 출력에서 거버넌스가 적용된 최신 결과를 반환합니다.
- 주요 차별점: Databricks Lakehouse는 BI 도구가 복제 없이 데이터를 직접 쿼리할 수 있도록 하여 복잡성을 줄이고, 추가 라이선스 비용을 피하며, 전반적인 TCO를 낮춥니다. 서버리스 컴퓨트 및 지능형 최적화와 결합하여 최소한의 튜닝으로 웨어하우스 수준의 성능을 제공합니다.
- 자연어 입력을 사용하여 시각화 생성
- 필터 및 드릴다운을 사용하여 대시보드를 대화형으로 수정 및 탐색
- Databricks 작업 공간 외부의 사용자를 포함하여 조직 전체에 대시보드를 게시하고 안전하게 공유
- 주요 차별점: 거버넌스가 적용된 실시간 데이터에서 대시보드를 구축하고 탐색하기 위한 로우 코드 및 AI 지원 경험을 제공합니다.
- 트랜잭션 의사 결정을 위해 다운스트림 애플리케이션 또는 운영 데이터베이스와 공유
- 분석을 위한 협업 노트북에서 사용
- 통합된 거버넌스를 통해 Delta Sharing을 통해 파트너, 팀 또는 외부 소비자에게 배포
- 대시보드에 미리 구축되지 않은 임시, 대화형, 실시간 질문 지원
- 시간이 지남에 따라 변화하는 비즈니스 용어 및 컨텍스트에 지능적으로 적응
- Unity Catalog를 통해 기존 데이터 거버넌스 및 액세스 제어 활용
- 규정 준수 및 투명성을 위한 자연어 쿼리의 감사 가능성 및 추적성 제공
- 주요 차별점: SQL 전문 지식 없이도 변화하는 비즈니스 개념에 지속적으로 적응하여 정확하고 컨텍스트를 인식하는 응답 제공
- 거버넌스: Unity Catalog는 모든 워크로드에 걸쳐 중앙 집중식 액세스 제어, 계보, 감사 및 데이터 분류를 제공합니다.
- 성능: Photon engine, 지능형 캐싱 및 워크로드 인식 최적화는 수동 튜닝 없이 빠른 쿼리를 제공합니다.
- 오케스트레이션: 내장된 오케스트레이션은 배치 및 스트리밍 워크로드 전반에 걸쳐 데이터 파이프라인, AI 워크플로 및 예약된 작업을 관리하며, 종속성 관리 및 오류 처리를 기본적으로 지원합니다.
- 개방형 스토리지: 데이터는 개방형 형식(Delta Lake, Parquet, Iceberg)으로 저장되어 도구 간 상호 운용성, 플랫폼 간 이식성 및 공급업체 종속성 없는 장기적인 내구성을 가능하게 합니다.
- 모니터링 및 감사 가능성: 쿼리 성능, 파이프라인 실행 및 사용자 액세스에 대한 종단 간 가시성을 통해 더 나은 제어 및 비용 관리를 제공합니다.
- 주요 차별점: 플랫폼 수준 서비스는 계층화되지 않고 통합되어 모든 데이터 워크플로, 클라우드 및 팀에서 거버넌스, 자동화 및 성능이 일관되게 유지됩니다.


