Schema-Entwicklung bei Merge-Operationen und operative Metriken in Delta Lake
Delta Lake 0.6.0 führt Schemaentwicklung und Leistungsverbesserungen bei Merge- und operativen Metriken in der Tabellenhistorie ein
von Tathagata Das und Denny Lee
Erhalten Sie eine frühe Vorschau von O'Reillys neuem E-Book für die Schritt-für-Schritt-Anleitung, die Sie benötigen, um mit Delta Lake zu beginnen.
Probieren Sie dieses Notebook aus, um die unten beschriebenen Schritte zu reproduzieren.
Wir haben kürzlich die Veröffentlichung von Delta Lake 0.6.0 angekündigt, das Schema-Evolution und Leistungsverbesserungen bei Merge-Operationen sowie operative Metriken in der Tabellenhistorie einführt. Die Hauptmerkmale dieser Version sind:
- Unterstützung für Schema-Evolution bei Merge-Operationen (#170) - Sie können das Schema der Tabelle jetzt automatisch mit der Merge-Operation weiterentwickeln. Dies ist nützlich in Szenarien, in denen Sie Änderungsdaten in eine Tabelle einfügen/aktualisieren möchten und sich das Schema der Daten im Laufe der Zeit ändert. Anstatt Schemaänderungen vor dem Einfügen/Aktualisieren zu erkennen und anzuwenden, kann Merge gleichzeitig das Schema weiterentwickeln und die Änderungen einfügen/aktualisieren.
- Verbesserte Merge-Leistung mit automatischer Repartitionierung (#349) - Beim Zusammenführen in partitionierte Tabellen können Sie die Daten vor dem Schreiben in die Tabelle automatisch nach den Partitionierungsspalten neu aufteilen. In Fällen, in denen die Merge-Operation auf einer partitionierten Tabelle langsam ist, da sie zu viele kleine Dateien generiert (#345), kann die Aktivierung der automatischen Repartitionierung (spark.delta.merge.repartitionBeforeWrite) die Leistung verbessern.
- Verbesserte Leistung, wenn keine INSERT-Klausel vorhanden ist (#342) - Sie können jetzt eine bessere Leistung bei einer Merge-Operation erzielen, wenn diese keine INSERT-Klausel enthält.
- Operative Metriken in DESCRIBE HISTORY (#312) - Sie können jetzt operative Metriken (z. B. Anzahl der geänderten Dateien und Zeilen) für alle Schreib-, Update- und Löschvorgänge in einer Delta-Tabelle in der Tabellenhistorie sehen.
- Unterstützung für das Lesen von Delta-Tabellen von jedem Dateisystem (#347) - Sie können jetzt Delta-Tabellen auf jedem Speichersystem mit einer Hadoop FileSystem-Implementierung lesen. Das Schreiben in Delta-Tabellen erfordert jedoch weiterhin die Konfiguration einer LogStore-Implementierung, die die notwendigen Garantien für das Speichersystem bietet.
Schema-Evolution bei Merge-Operationen
Wie in früheren Versionen von Delta Lake erwähnt, bietet Delta Lake die Möglichkeit, Merge-Operationen auszuführen, um Ihre INSERT/UPDATE/DELETE-Operationen in einer einzigen atomaren Operation zu vereinfachen, sowie die Möglichkeit, Ihr Schema zu erzwingen und weiterzuentwickeln (weitere Details finden Sie auch in diesem Tech Talk). Mit der Veröffentlichung von Delta Lake 0.6.0 können Sie Ihr Schema jetzt innerhalb einer Merge-Operation weiterentwickeln.
Lassen Sie uns dies anhand eines aktuellen Beispiels veranschaulichen. Den ursprünglichen Codeausschnitt finden Sie in diesem Notebook. Wir beginnen mit einer kleinen Teilmenge des 2019 Novel Coronavirus COVID-19 (2019-nCoV) Data Repository von Johns Hopkins CSSE, die wir in /databricks-datasets verfügbar gemacht haben. Dies ist ein Datensatz, der häufig von Forschern und Analysten verwendet wird, um Einblicke in die Anzahl der COVID-19-Fälle weltweit zu gewinnen. Eines der Probleme mit den Daten ist, dass sich das Schema im Laufe der Zeit ändert.
Beispielsweise haben die Dateien, die COVID-19-Fälle vom 1. März bis 21. März darstellen (Stand 30. April 2020), folgendes Schema:
Aber die Dateien ab dem 22. März (Stand 30. April) enthielten zusätzliche Spalten, darunter FIPS, Admin2, Active und Combined_Key.
In unserem Beispielcode haben wir einige der Spalten umbenannt (z. B. Long_ -> Longitude, Province/State -> Province_State usw.), da sie semantisch gleich sind. Anstatt das Tabellenschema weiterzuentwickeln, haben wir einfach die Spalten umbenannt.
Wenn die Hauptsorge nur das Zusammenführen der Schemata gewesen wäre, könnten wir die Schema-Evolution-Funktion von Delta Lake mit der Option „mergeSchema“ in DataFrame.write() verwenden, wie in der folgenden Anweisung gezeigt.
Aber was passiert, wenn Sie einen vorhandenen Wert aktualisieren und gleichzeitig das Schema zusammenführen müssen? Mit Delta Lake 0.6.0 kann dies durch Schema-Evolution für Merge-Operationen erreicht werden. Um dies zu veranschaulichen, beginnen wir mit der Überprüfung der alten Daten, die eine Zeile darstellen.
Als Nächstes simulieren wir einen Update-Eintrag, der dem Schema von new_data folgt.
und vereinigen simulated_update und new_data mit insgesamt 40 Zeilen.
Wir setzen den folgenden Parameter, um Ihre Umgebung für die automatische Schema-Evolution zu konfigurieren:
Jetzt können wir eine einzelne atomare Operation ausführen, um die Werte (vom 21.03.2020) zu aktualisieren und das neue Schema zusammenzuführen, mit der folgenden Anweisung.
Lassen Sie uns die Delta Lake-Tabelle mit der folgenden Anweisung überprüfen:
Betriebsmetriken
Sie können die Betriebsmetriken weiter untersuchen, indem Sie sich die Delta Lake Tabellenhistorie (Spalte operationMetrics) in der Spark UI ansehen, indem Sie die folgende Anweisung ausführen:
Unten sehen Sie eine gekürzte Ausgabe des vorherigen Befehls.
Sie werden zwei Versionen der Tabelle bemerken, eine für das alte Schema und eine weitere Version für das neue Schema. Bei der Überprüfung der Betriebsmetriken unten wird angemerkt, dass 39 Zeilen eingefügt und 1 Zeile aktualisiert wurden.
Sie können mehr über die Details hinter diesen Betriebsmetriken erfahren, indem Sie zum SQL-Tab in der Spark UI gehen.
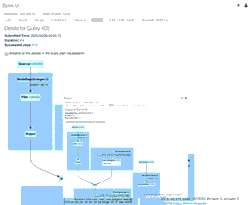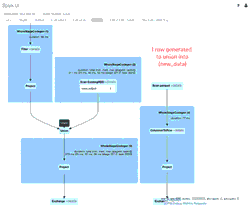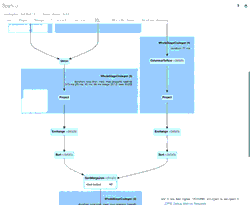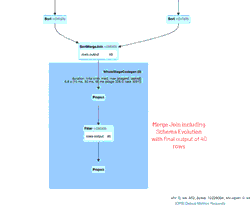
Die animierte GIF-Datei hebt die Hauptkomponenten der Spark UI für Ihre Überprüfung hervor.
- 39 anfängliche Zeilen aus einer Datei (für den 11.04.2020 mit dem neuen Schema), die den anfänglichen new_data DataFrame erstellten
- 1 simulierte Update-Zeile, die mit dem new_data DataFrame vereinigt würde
- 1 Zeile aus der einen Datei (für den 21.03.2020 mit dem alten Schema), die den old_data DataFrame erstellte.
- Ein SortMergeJoin, der verwendet wird, um die beiden DataFrames zu verbinden und in unserer Delta Lake-Tabelle zu speichern.
Um tiefer in die Interpretation dieser Betriebsmetriken einzutauchen, sehen Sie sich das Tech-Talk Diving into Delta Lake Part 3: How do DELETE, UPDATE, and MERGE work an.

Erste Schritte mit Delta Lake 0.6.0
Probieren Sie Delta Lake mit den vorherigen Code-Snippets auf Ihrer Apache Spark 2.4.5 (oder höher) Instanz aus (versuchen Sie dies auf Databricks mit DBR 6.6+). Delta Lake macht Ihre Data Lakes zuverlässiger (egal ob Sie einen neuen erstellen oder einen bestehenden Data Lake migrieren). Um mehr zu erfahren, siehe https://delta.io/ und treten Sie der Delta Lake Community über Slack und die Google Group bei. Sie können alle kommenden Releases und geplanten Features in den GitHub Milestones verfolgen. Sie können auch Managed Delta Lake auf Databricks mit einem kostenlosen Konto ausprobieren.
Danksagungen
Wir möchten den folgenden Mitwirkenden für Updates, Dokumentationsänderungen und Beiträge zu Delta Lake 0.6.0 danken: Ali Afroozeh, Andrew Fogarty, Anurag870, Burak Yavuz, Erik LaBianca, Gengliang Wang, IonutBoicuAms, Jakub Orłowski, Jose Torres, KevinKarlBob, Michael Armbrust, Pranav Anand, Rahul Govind, Rahul Mahadev, Shixiong Zhu, Steve Suh, Tathagata Das, Timothy Zhang, Tom van Bussel, Wesley Hoffman, Xiao Li, chet, Eugene Koifman, Herman van Hovell, hongdd, lswyyy, lys0716, Mahmoud Mahdi, Maryann Xue
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.