Einheitliche Governance für Daten, Apps und KI-Agenten
Sorgen Sie dafür, dass Daten, Modelle, KI-Agenten und Apps einfach auffindbar, zentral verwaltet
ERFOLGREICHE TEAMS SETZEN AUF EINHEITLICHE UND OFFENE GOVERNANCE

Von vertrauenswürdigen Daten zu verlässlicher KI – in einem einzigen Katalog
Schaffen Sie mit vertrauenswürdigen Daten und gemeinsamem Geschäftskontext die Grundlage für Ihre KI, steuern Sie die Fähigkeiten Ihrer Modelle und KI-Agenten zentral und führen Sie sie überall aus.Daten und KI-Assets an einem Ort
Verwalten Sie Daten, Modelle, KI-Agenten, KI-Anwendungen und MCPs in einem zentralen Katalog. Einheitliche Governance und konsistente Richtlinien sorgen cloud- und plattformübergreifend für Sicherheit und Kontrolle.
Kontext für fundierte Entscheidungen
Nutzen Sie eine gemeinsame Business-Semantik, damit Anwender und KI-Agenten vertrauenswürdige Daten und KI-Assets schneller finden, verstehen und sicher nutzen können.
KI-gestützte Governance
Integrierte KI automatisiert Zugriffsrichtlinien, schützt sensible Daten, überwacht die Datenqualität und optimiert die Performance Ihrer Plattform.
Ein zentraler Katalog für alle Daten und KI-Assets
Verwalten Sie Daten und KI-Assets, darunter Modelle, KI-Agenten und MCPs, cloud- und plattformübergreifend in einem Katalog.Steuern Sie über das Unity KI Gateway, worauf Agenten, Modelle und MCPs zugreifen und welche Aktionen sie ausführen können – mit denselben Governance-, Kosten- und Transparenzrichtlinien wie für Ihre Daten.

Arbeiten Sie mit offenen Datenformaten wie Delta, Iceberg und Parquet und greifen Sie über offene APIs plattformübergreifend auf Daten zu, ohne sie zu verschieben.

Erkennen, verwalten und greifen Sie Cloud- und regionsübergreifend zu – mit einer zentralen, vertrauenswürdigen Ansicht, integrierter Notfallwiederherstellung und optionaler globaler Compute-Leistung.
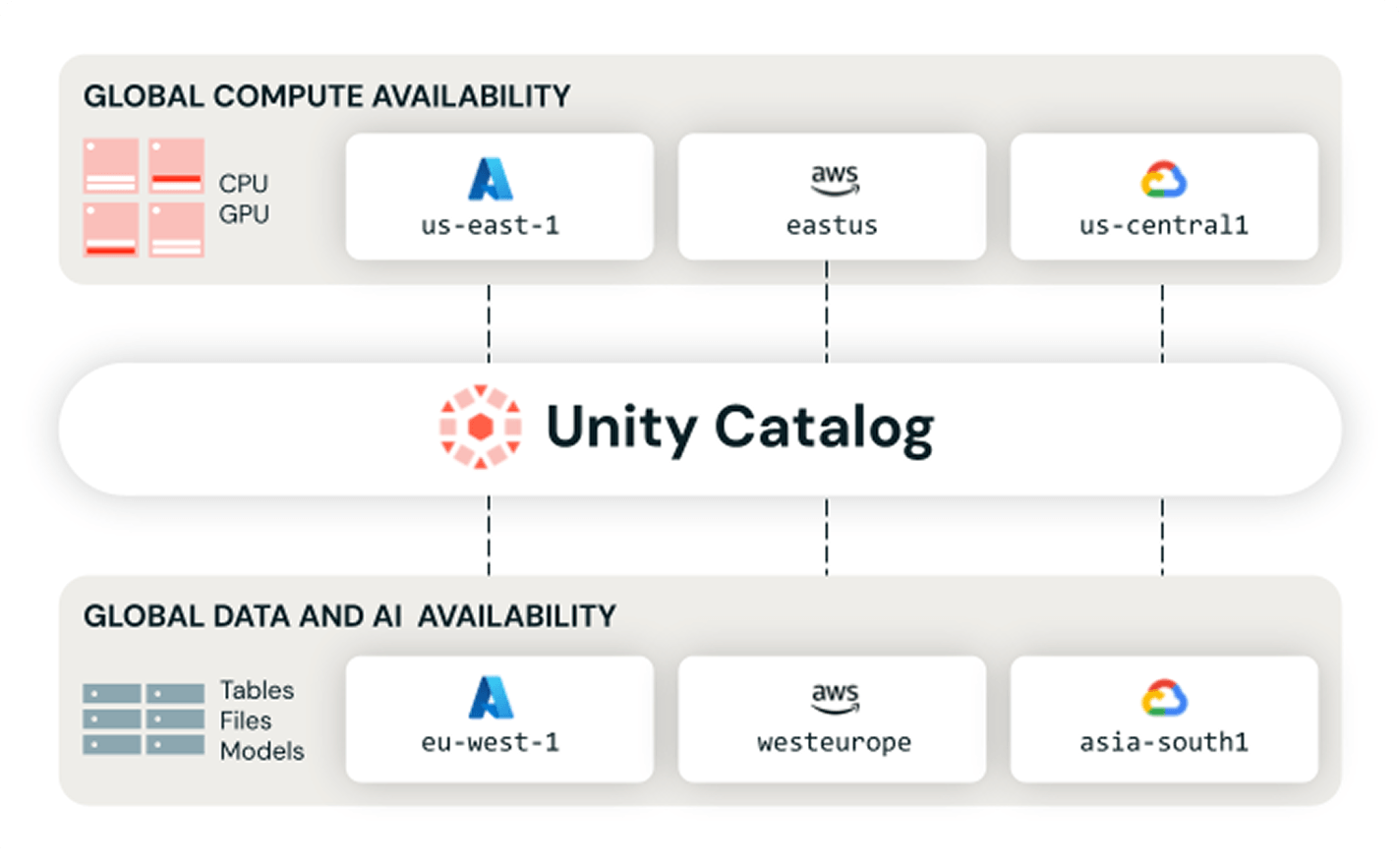
Vertrauenswürdige Discovery für Benutzer und Agenten
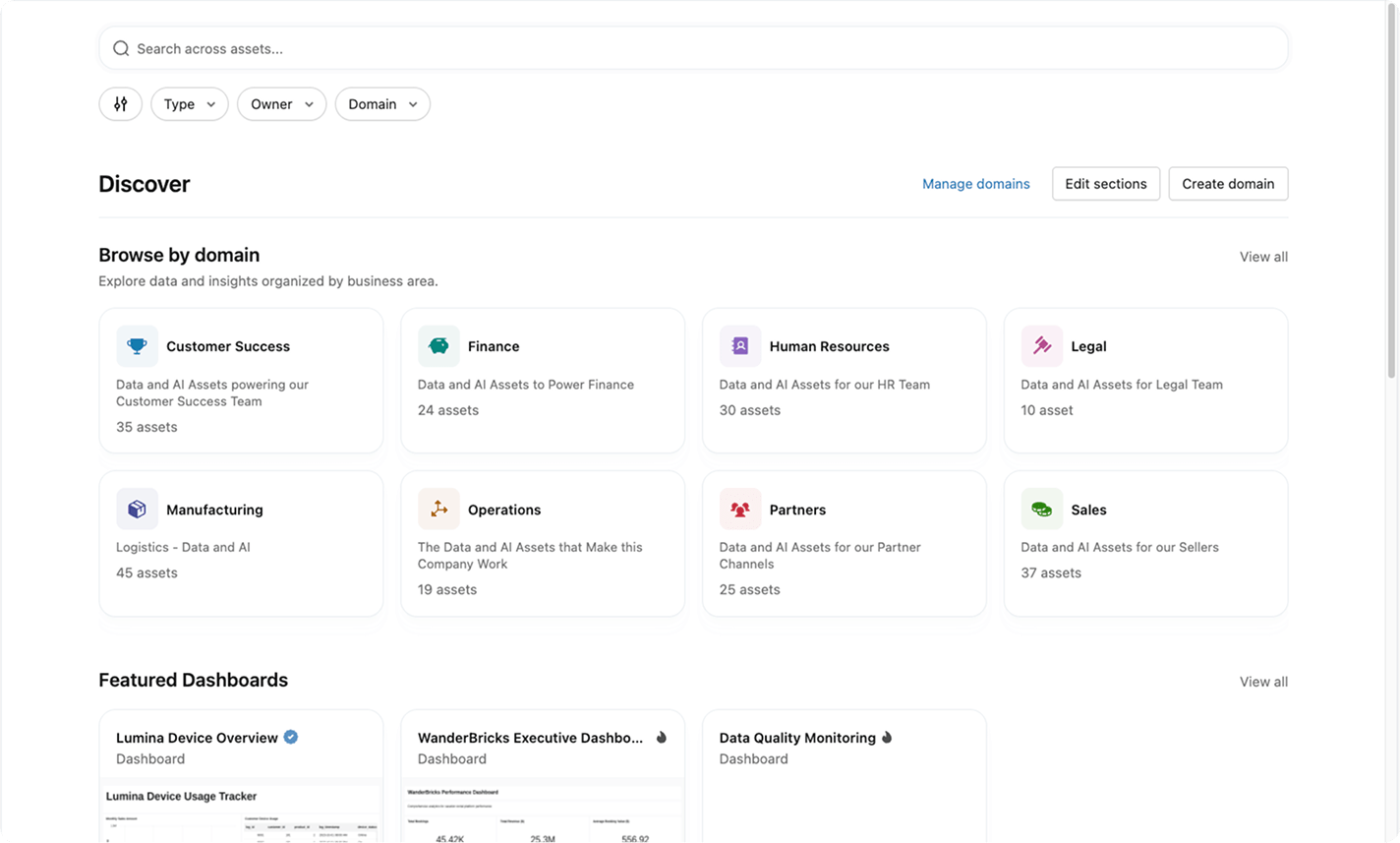
Helfen Sie Anwendern und KI-Agenten, die richtigen Daten und KI-Assets zu finden, zu verstehen und sicher zu nutzen – mit gemeinsamem Kontext, einheitlichen Definitionen und Qualitätssignalen in Ihrer gesamten Datenlandschaft.Unity Catalog kuratiert Ihre vertrauenswürdigsten Daten und KI-Assets mit KI und vereint Tabellen, Dashboards und Modelle mit gemeinsamem Geschäftskontext in einer einheitlichen Oberfläche.
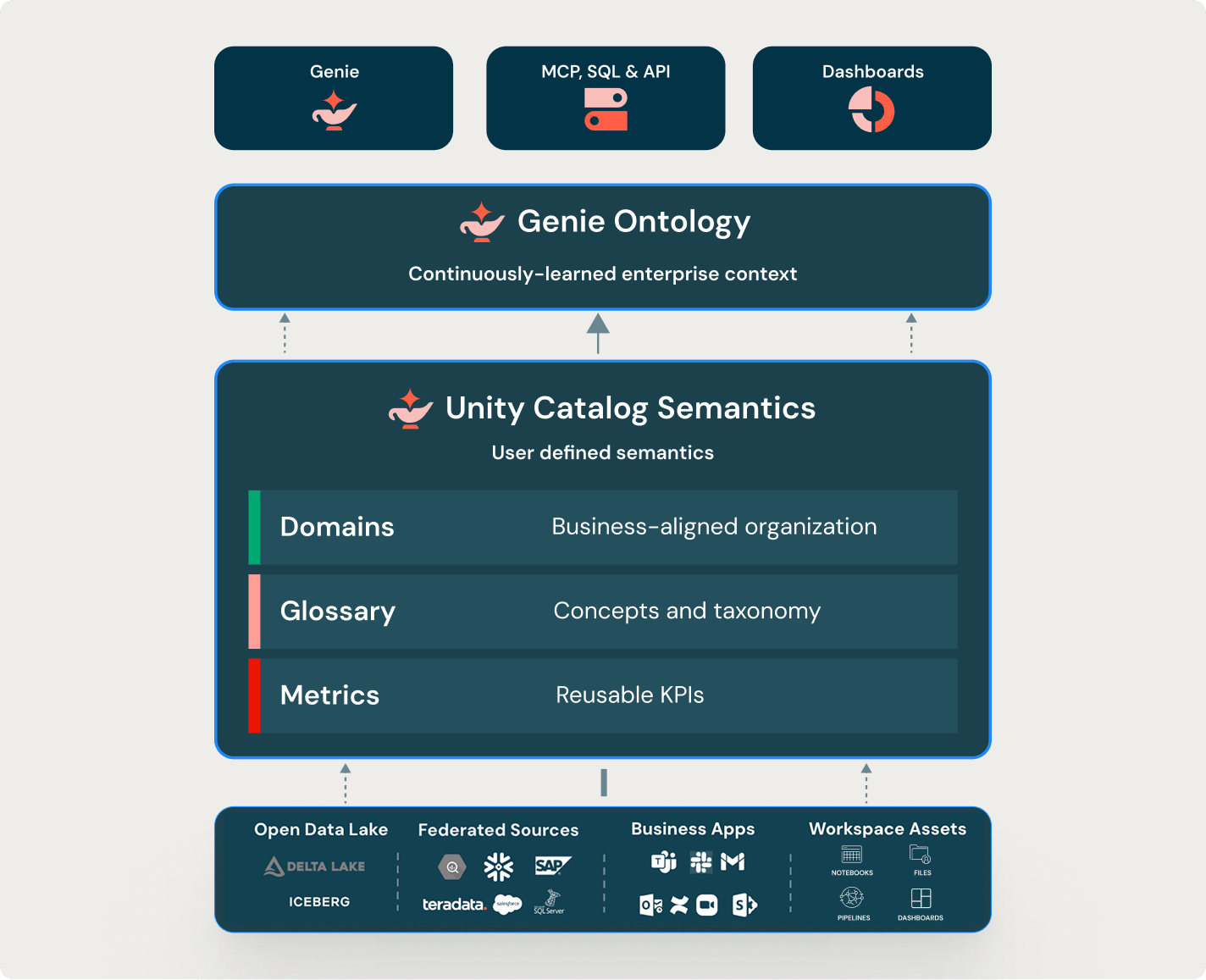
Unity Catalog schafft eine gemeinsame Datengrundlage mit einheitlichen Definitionen und Governance, damit Fachbereiche, technische Teams und KI-Agenten auf derselben Basis arbeiten und fundierte Erkenntnisse gewinnen.
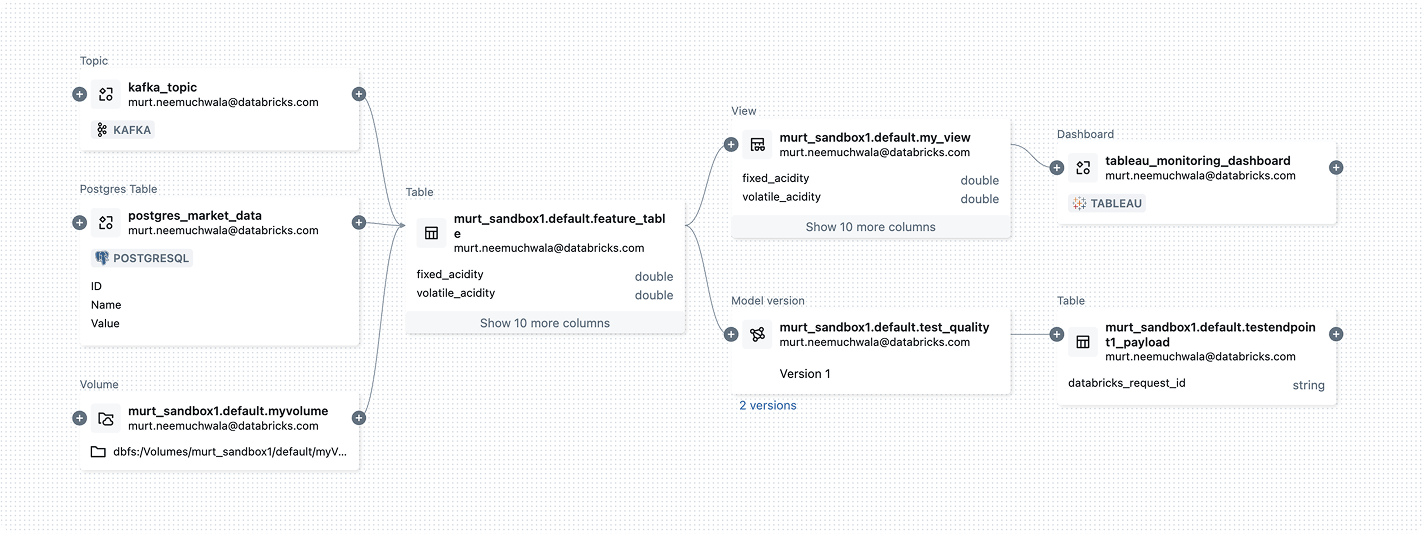
Durchgängige, automatisierte Herkunftsverfolgung auf Spaltenebene für Daten- und KI-Assets zur Vereinfachung von Impact-Analysen, Fehlerbehebung, Governance und KI-Audits.
Integrierte, automatisierte Governance
Skalieren Sie eine konsistente Governance über sämtliche Daten- und KI-Assets hinweg – automatisch, leistungsoptimiert und ohne manuellen Pflegeaufwand.Steuern Sie den Zugriff auf Ihre gesamte Datenlandschaft mit einem einzigen Richtlinienmodell. Attribute, Tags und automatische Klassifizierung ermöglichen feingranulare Zugriffsrichtlinien ganz ohne manuellen Aufwand.

Automatisierte, KI-gesteuerte Qualitätsüberwachung für alle Daten- und KI-Assets, die Echtzeit-Vertrauenssignale überall dort bereitstellt, wo Ihre Teams und KI-Agenten arbeiten.
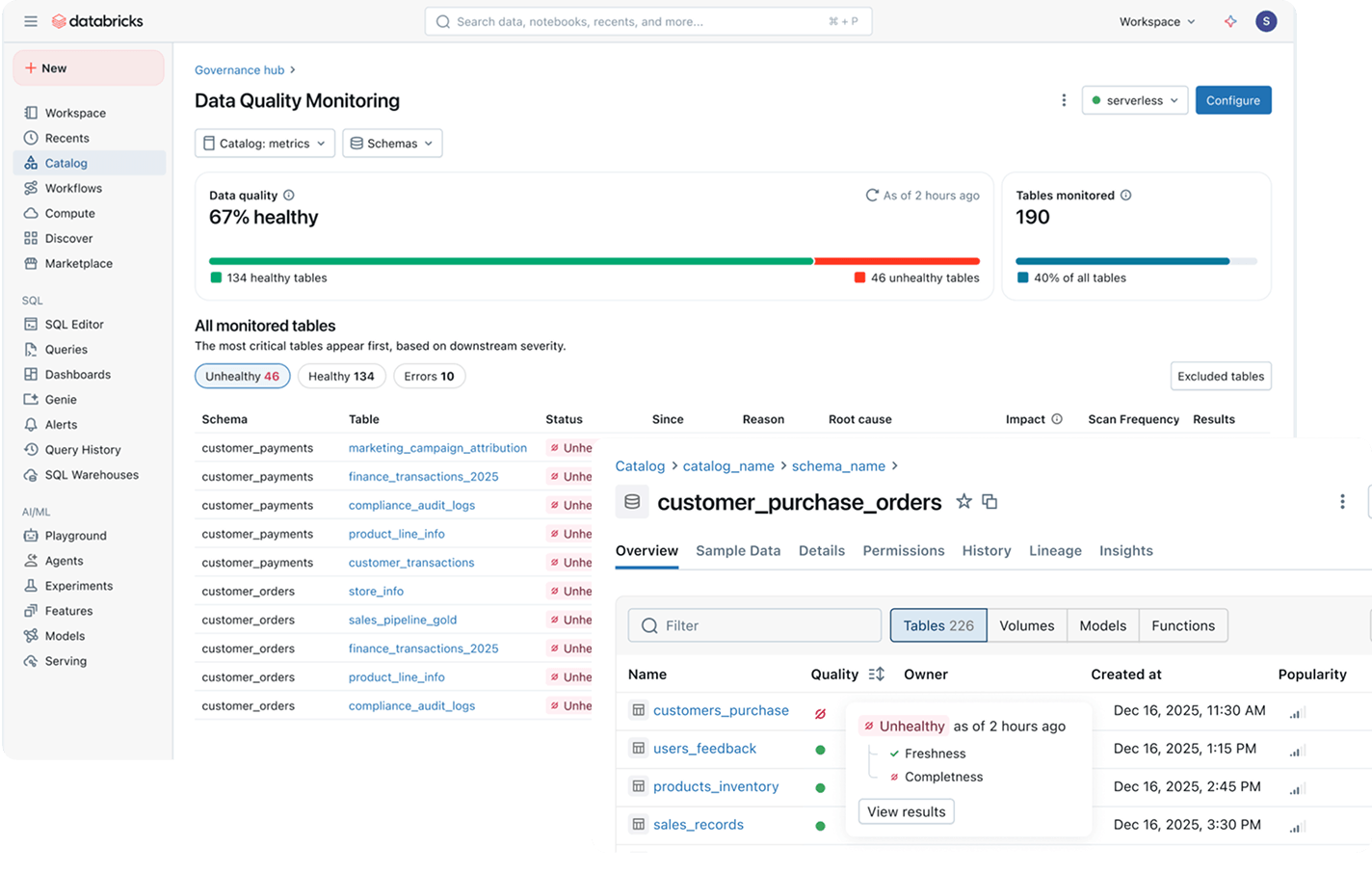
Überwachen Sie die Unternehmens-Governance, die Kosten und die KI-Nutzung in einer einzigen Ansicht, mit integrierten Einblicken in Lücken, riskante Zugriffsänderungen und Richtlinien-Drift.

Unity Catalog Managed Tables optimieren Abfragegeschwindigkeit und Kosten automatisch mit KI. Ein selbstoptimierendes Layout passt sich kontinuierlich an Ihre Nutzung an.
Maximieren Sie den Business Value Ihrer Daten durch konsistente, zentrale Governance.

Data Mesh und Datenprodukte mit einheitlicher Governance
Ermöglichen Sie Teams, hochwertige Datenprodukte eigenständig zu veröffentlichen, ohne auf zentrale Transparenz, Sicherheit und Governance zu verzichten.
- Setzen Sie konsistente Governance-Richtlinien für domänenübergreifende Datenprodukte und Plattformen durch.
- Machen Sie Datenprodukte mit zentralen Metadaten und Datenherkunft einfach auffindbar.
- Klassifizieren und taggen Sie sensible Daten automatisch, um eine skalierbare Zugriffskontrolle zu ermöglichen.
- Verwalten Sie föderierte Governance und Audits über eine zentrale Steuerungsebene.







Mehr entdecken
Erkunden Sie Produkte, die die Leistungsfähigkeit des Unity-Katalogs in den Bereichen Governance, Zusammenarbeit und Datenintelligenz erweitern.
Genie One
Ein konversationelles Erlebnis, das von generativer KI gesteuert wird, das es Business-Teams ermöglicht, Daten in Echtzeit per natürlicher Sprache zu durchsuchen und eigenständig Insights abzurufen.

Lakehouse-Speicherung
Beseitigen Sie die Komplexität im Datenmanagement mit offenen Tabellenformaten, zentraler Governance und automatischer Datenoptimierung.

OpenSharing
Ein Open-Source-Ansatz für die plattformübergreifende gemeinsame Daten- und KI-Nutzung. Geben Sie Livedaten mit zentralisierter Governance und ohne Replikation frei.

Databricks Clean Rooms
Analysieren Sie von mehreren Parteien freigegebene Daten, ohne direkten Zugriff auf die Rohdaten zu gewähren.

Databricks Marketplace
Ein offener Marktplatz für Daten sowie KI- und Analyseressourcen wie ML-Modelle oder Notebooks.
Wagen Sie den nächsten Schritt
Erkunden Sie die Dokumentation von Unity Catalog
Erhalten Sie detaillierte Anleitungen zu Funktionen, Einrichtung und Best Practices in der Unity Catalog-Dokumentation für AWS, Azure und GCP.
Erkunden Sie Produkt-Demos
Sehen Sie sich Demos zu Unity Catalog an, um zu erfahren, wie Sie Daten und AI-Assets in Ihrem gesamten Bestand steuern, entdecken und teilen können.




Unity Catalog FAQ
Möchten Sie ein Daten- und KI-Unternehmen werden?
Machen Sie die ersten Schritte Ihrer Datentransformation