Vorstellung von DBRX: Ein neues, hochmodernes Open LLM
Heute freuen wir uns, DBRX vorzustellen, ein offenes, universell einsetzbares LLM, das von Databricks entwickelt wurde. In einer Reihe von Standard-Benchmarks setzt DBRX einen neuen Stand der Technik für etablierte offene LLMs. Darüber hinaus bietet es der Open-Community und Unternehmen, die ihre eigenen LLMs entwickeln, Fähigkeiten, die bisher auf geschlossene Modell-APIs beschränkt waren; nach unseren Messungen übertrifft es GPT-3.5 und ist wettbewerbsfähig mit Gemini 1.0 Pro. Es ist ein besonders leistungsfähiges Code-Modell, das spezialisierte Modelle wie CodeLLaMA-70B in der Programmierung übertrifft, zusätzlich zu seiner Stärke als universell einsetzbares LLM.
Diese Spitzenqualität geht mit deutlichen Verbesserungen bei Trainings- und Inferenzleistung einher. DBRX treibt dank seiner feingranularen Mixture-of-Experts (MoE)-Architektur den Stand der Technik bei der Effizienz unter offenen Modellen voran. Die Inferenz ist bis zu 2x schneller als bei LLaMA2-70B, und DBRX ist etwa 40% so groß wie Grok-1, sowohl in Bezug auf die Gesamtzahl der Parameter als auch auf die aktiven Parameter. Wenn DBRX auf Databricks Model Serving gehostet wird, kann es Text mit bis zu 150 tok/s/Benutzer generieren. Unsere Kunden werden feststellen, dass das Training von MoEs bei gleicher Endmodellqualität auch etwa 2x FLOP-effizienter ist als das Training von dichten Modellen. Insgesamt kann unser gesamtes Rezept für DBRX (einschließlich der Vortrainingsdaten, der Modellarchitektur und der Optimierungsstrategie) die Qualität unserer MPT-Modelle der vorherigen Generation mit fast 4x weniger Rechenleistung erreichen.
Die Gewichte des Basismodells (DBRX Base) und des feinabgestimmten Modells (DBRX Instruct) sind auf Hugging Face unter einer offenen Lizenz verfügbar. Ab heute ist DBRX für Databricks-Kunden über APIs verfügbar, und Databricks-Kunden können ihre eigenen Modelle der DBRX-Klasse von Grund auf vortrainieren oder auf einem unserer Checkpoints mit denselben Tools und wissenschaftlichen Methoden, die wir zu seiner Entwicklung verwendet haben, weitertrainieren. DBRX wird bereits in unsere GenAI-gestützten Produkte integriert, wo frühe Rollouts in Anwendungen wie SQL GPT-3.5 Turbo übertroffen haben und GPT-4 Turbo herausfordern. Es ist auch ein führendes Modell unter den offenen Modellen und GPT-3.5 Turbo bei RAG-Aufgaben.
Das Training von Mixture-of-Experts-Modellen ist schwierig. Wir mussten eine Vielzahl von wissenschaftlichen und leistungsbezogenen Herausforderungen überwinden, um eine robuste Pipeline zu entwickeln, die Modelle der DBRX-Klasse effizient und wiederholbar trainieren kann. Jetzt, da wir dies getan haben, verfügen wir über einen einzigartigen Trainings-Stack, der es jedem Unternehmen ermöglicht, erstklassige MoE-Grundlagenmodelle von Grund auf zu trainieren. Wir freuen uns darauf, diese Fähigkeit mit unseren Kunden zu teilen und unsere gewonnenen Erkenntnisse mit der Community zu teilen.
Laden Sie DBRX noch heute von Hugging Face herunter (DBRX Base, DBRX Instruct), probieren Sie DBRX Instruct in unserem HF Space aus oder sehen Sie sich unser Modell-Repository auf GitHub an: databricks/dbrx.
Was ist DBRX?
DBRX ist ein Transformer-basiertes reines Decoder-großes Sprachmodell (LLM), das durch Next-Token-Prediction trainiert wurde. Es verwendet eine feingranulare Mixture-of-Experts (MoE)-Architektur mit insgesamt 132 Milliarden Parametern, von denen 36 Milliarden Parameter bei jeder Eingabe aktiv sind. Es wurde auf 12 Billionen Token Text- und Codedaten vortrainiert. Im Vergleich zu anderen offenen MoE-Modellen wie Mixtral und Grok-1 ist DBRX feingranular, d.h. es verwendet eine größere Anzahl kleinerer Experten. DBRX hat 16 Experten und wählt 4 aus, während Mixtral und Grok-1 8 Experten haben und 2 auswählen. Dies bietet 65x mehr mögliche Expertenkombinationen und wir haben festgestellt, dass dies die Modellqualität verbessert. DBRX verwendet Rotary Position Encodings (RoPE), Gated Linear Units (GLU) und Grouped Query Attention (GQA). Es verwendet den GPT-4-Tokenizer, wie er im tiktoken-Repository bereitgestellt wird. Wir haben diese Entscheidungen auf der Grundlage umfassender Evaluierungen und Skalierungsexperimente getroffen.
DBRX wurde auf 12 Billionen Token sorgfältig kuratierter Daten und einer maximalen Kontextlänge von 32.000 Token vortrainiert. Wir schätzen, dass diese Daten Token für Token mindestens 2x besser sind als die Daten, die wir zum Vortrainieren der MPT-Modellfamilie verwendet haben. Dieser neue Datensatz wurde mit der gesamten Suite von Databricks-Tools entwickelt, einschließlich Apache Spark™ und Databricks Notebooks für die Datenverarbeitung, Unity Catalog für Datenmanagement und Governance sowie MLflow für das Experiment-Tracking. Wir haben Curriculum Learning für das Vortraining verwendet und den Datenmix während des Trainings so geändert, dass die Modellqualität erheblich verbessert wurde.
Qualität bei Benchmarks im Vergleich zu führenden offenen Modellen
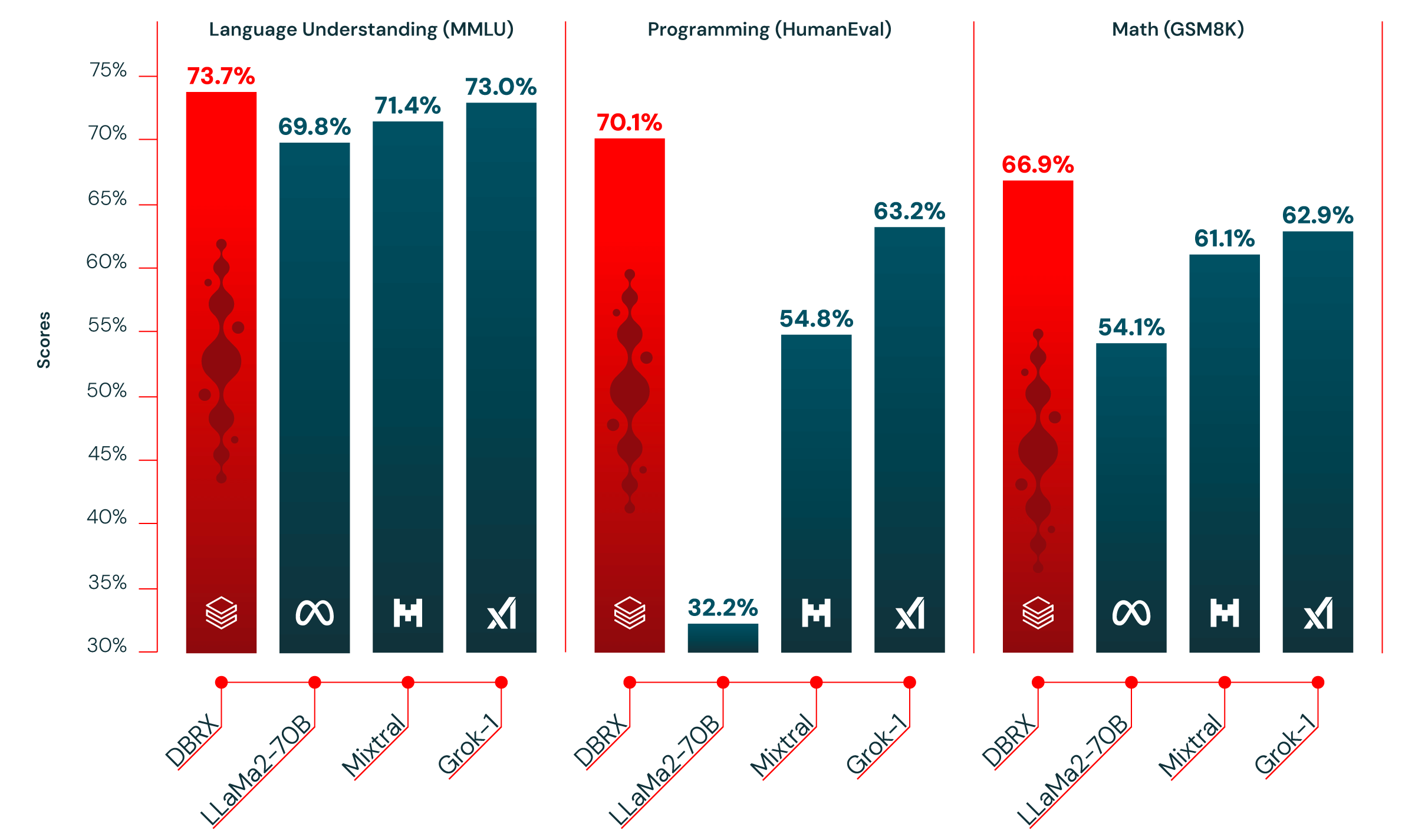
Tabelle 1 zeigt die Qualität von DBRX Instruct und führenden etablierten, offenen Modellen. DBRX Instruct ist das führende Modell bei zusammengesetzten Benchmarks, Programmier- und Mathematik-Benchmarks sowie MMLU. Es übertrifft alle Chat- oder Instruktions-feinabgestimmten Modelle bei Standard-Benchmarks.
Zusammengesetzte Benchmarks. Wir haben DBRX Instruct und seine Mitbewerber anhand von zwei zusammengesetzten Benchmarks evaluiert: dem Hugging Face Open LLM Leaderboard (der Durchschnitt von ARC-Challenge, HellaSwag, MMLU, TruthfulQA, WinoGrande und GSM8k) und dem Databricks Model Gauntlet (eine Suite von über 30 Aufgaben, die sechs Kategorien umfassen: Weltwissen, gesunder Menschenverstand, Sprachverständnis, Leseverständnis, symbolische Problemlösung und Programmierung).
Unter den von uns evaluierten Modellen erzielt DBRX Instruct die höchsten Punktzahlen bei zwei zusammengesetzten Benchmarks: dem Hugging Face Open LLM Leaderboard (74,5 % gegenüber 72,7 % für das nächsthöchste Modell, Mixtral Instruct) und dem Databricks Gauntlet (66,8 % gegenüber 60,7 % für das nächsthöchste Modell, Mixtral Instruct).
Programmierung und Mathematik. DBRX Instruct ist besonders stark in den Bereichen Programmierung und Mathematik. Es erzielt höhere Punktzahlen als die anderen von uns evaluierten offenen Modelle bei HumanEval (70,1 % gegenüber 63,2 % für Grok-1, 54,8 % für Mixtral Instruct und 32,2 % für die leistungsstärkste LLaMA2-70B-Variante) und GSM8k (66,9 % gegenüber 62,9 % für Grok-1, 61,1 % für Mixtral Instruct und 54,1 % für die leistungsstärkste LLaMA2-70B-Variante). DBRX übertrifft Grok-1, das nächstbeste Modell bei diesen Benchmarks, obwohl Grok-1 2,4x mehr Parameter hat. Bei HumanEval übertrifft DBRX Instruct sogar CodeLLaMA-70B Instruct, ein Modell, das speziell für die Programmierung entwickelt wurde, obwohl DBRX Instruct für den allgemeinen Gebrauch konzipiert ist (70,1 % gegenüber 67,8 % bei HumanEval, wie von Meta im CodeLLaMA-Blog berichtet).
MMLU. DBRX Instruct erzielt mit 73,7 % höhere Punktzahlen als alle anderen von uns betrachteten Modelle bei MMLU.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabelle 1. Qualität von DBRX Instruct und führenden Open-Source-Modellen. Details zur Datenerfassung finden Sie in den Fußnoten. Fett und unterstrichen ist der höchste Wert.
Qualität bei Benchmarks im Vergleich zu führenden Closed-Source-Modellen
Tabelle 2 zeigt die Qualität von DBRX Instruct und führenden Closed-Source-Modellen. Laut den von den jeweiligen Modellentwicklern gemeldeten Werten übertrifft DBRX Instruct GPT-3.5 (wie im GPT-4-Paper beschrieben) und ist wettbewerbsfähig mit Gemini 1.0 Pro und Mistral Medium.
Bei fast allen von uns berücksichtigten Benchmarks übertrifft DBRX Instruct GPT-3.5 oder erreicht zumindest dessen Niveau. DBRX Instruct übertrifft GPT-3.5 bei Allgemeinwissen, gemessen am MMLU (73,7 % vs. 70,0 %), und beim logischen Schlussfolgern, gemessen am HellaSwag (89,0 % vs. 85,5 %) und WinoGrande (81,8 % vs. 81,6 %). DBRX Instruct glänzt insbesondere bei der Programmierung und mathematischen Schlussfolgerung, gemessen am HumanEval (70,1 % vs. 48,1 %) und GSM8k (72,8 % vs. 57,1 %).
DBRX Instruct ist wettbewerbsfähig mit Gemini 1.0 Pro und Mistral Medium. Die Werte für DBRX Instruct sind höher als die von Gemini 1.0 Pro bei Inflection Corrected MTBench, MMLU, HellaSwag und HumanEval, während Gemini 1.0 Pro bei GSM8k stärker ist. Die Werte für DBRX Instruct und Mistral Medium sind bei HellaSwag ähnlich, während Mistral Medium bei Winogrande und MMLU stärker ist und DBRX Instruct bei HumanEval, GSM8k und Inflection Corrected MTBench stärker ist.
|
|
|
|
|
|
|
|
|
|
|
|
|
Inflection korrigiert, n=5) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabelle 2. Qualität von DBRX Instruct und führenden geschlossenen Modellen. Mit Ausnahme von Inflection Corrected MTBench (das wir selbst auf Modellendpunkten gemessen haben) wurden die Zahlen wie von den Erstellern dieser Modelle in ihren jeweiligen Whitepapers berichtet. Zusätzliche Details finden Sie in den Fußnoten.
Qualität bei Aufgaben mit langem Kontext und RAG
DBRX Instruct wurde mit einem Kontextfenster von bis zu 32.000 Token trainiert. Tabelle 3 vergleicht seine Leistung mit der von Mixtral Instruct und den neuesten Versionen der GPT-3.5 Turbo und GPT-4 Turbo APIs auf einer Reihe von Benchmarks für lange Kontexte (KV-Paare aus dem Paper Lost in the Middle und HotpotQAXL, einer modifizierten Version von HotPotQA, die die Aufgabe auf längere Sequenzlängen erweitert). GPT-4 Turbo ist im Allgemeinen das beste Modell für diese Aufgaben. Mit einer Ausnahme schneidet DBRX Instruct jedoch bei allen Kontextlängen und allen Teilen der Sequenz besser ab als GPT-3.5 Turbo. Die Gesamtleistung von DBRX Instruct und Mixtral Instruct ist ähnlich.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabelle 3. Durchschnittliche Leistung von Modellen auf den KV-Pairs- und HotpotQAXL-Benchmarks. Fett markiert ist der höchste Wert. Unterstrichen ist der höchste Wert außer GPT-4 Turbo. GPT-3.5 Turbo unterstützt eine maximale Kontextlänge von 16K, daher konnten wir es nicht bei 32K evaluieren. *Durchschnitte für den Anfang, die Mitte und das Ende der Sequenz für GPT-3.5 Turbo umfassen nur Kontexte bis 16K.
Eine der beliebtesten Methoden, um den Kontext eines Modells zu nutzen, ist Retrieval Augmented Generation (RAG). Bei RAG werden Inhalte, die für eine Eingabeaufforderung relevant sind, aus einer Datenbank abgerufen und zusammen mit der Eingabeaufforderung präsentiert, um dem Modell mehr Informationen zu geben, als es sonst hätte. Tabelle 4 zeigt die Qualität von DBRX bei zwei RAG-Benchmarks – Natural Questions und HotPotQA –, wenn dem Modell auch die 10 besten Passagen aus einem Korpus von Wikipedia-Artikeln, die mit dem Embedding-Modell bge-large-en-v1.5 abgerufen wurden, zur Verfügung gestellt werden. DBRX Instruct ist wettbewerbsfähig mit Open-Source-Modellen wie Mixtral Instruct und LLaMA2-70B Chat sowie der aktuellen Version von GPT-3.5 Turbo.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabelle 4. Die Leistung der Modelle, gemessen daran, wie gut jedes Modell die Top-10-Passagen aus einem Wikipedia-Korpus mit bge-large-en-v1.5 abruft. Die Genauigkeit wird durch den Abgleich innerhalb der Antwort des Modells gemessen. Fett gedruckt ist der höchste Wert. Unterstrichen ist der höchste Wert außer GPT-4 Turbo.
Trainingseffizienz
Die Modellqualität muss im Kontext der Effizienz des Trainings und der Nutzung betrachtet werden. Dies gilt insbesondere bei Databricks, wo wir Modelle wie DBRX entwickeln, um unseren Kunden einen Prozess für das Training ihrer eigenen Foundation-Modelle zu ermöglichen.
Wir haben festgestellt, dass das Training von Mixture-of-Experts-Modellen erhebliche Verbesserungen bei der Compute-Effizienz für das Training bietet (Tabelle 5). Beispielsweise erforderte das Training eines kleineren Mitglieds der DBRX-Familie namens DBRX MoE-B (23,5 Milliarden Gesamtparameter, 6,6 Milliarden aktive Parameter) 1,7-mal weniger FLOPs, um einen Score von 45,5 % im Databricks LLM Gauntlet zu erreichen, als LLaMA2-13B benötigte, um 43,8 % zu erreichen. DBRX MoE-B enthält auch halb so viele aktive Parameter wie LLaMA2-13B.
Ganzheitlich betrachtet ist unsere End-to-End-LLM-Pretraining-Pipeline in den letzten zehn Monaten fast 4-mal compute-effizienter geworden. Am 5. Mai 2023 haben wir MPT-7B veröffentlicht, ein Modell mit 7 Milliarden Parametern, das auf 1 Billion Tokens trainiert wurde und einen Databricks LLM Gauntlet-Score von 30,9 % erreichte. Ein Mitglied der DBRX-Familie namens DBRX MoE-A (7,7 Milliarden Gesamtparameter, 2,2 Milliarden aktive Parameter) erreichte einen Databricks Gauntlet-Score von 30,5 % mit 3,7-mal weniger FLOPs. Diese Effizienz ist das Ergebnis einer Reihe von Verbesserungen, darunter die Verwendung einer MoE-Architektur, weitere Architekturänderungen am Netzwerk, bessere Optimierungsstrategien, bessere Tokenisierung und – sehr wichtig – bessere Pretraining-Daten.
Für sich genommen hatte die Verbesserung der Vortrainingsdaten einen erheblichen Einfluss auf die Modellqualität. Wir haben ein 7B-Modell auf 1T Tokens (genannt DBRX Dense-A) unter Verwendung der DBRX-Vortrainingsdaten trainiert. Es erreichte 39,0 % auf dem Databricks Gauntlet im Vergleich zu 30,9 % für MPT-7B. Wir schätzen, dass unsere neuen Vortrainingsdaten Token für Token mindestens 2x besser sind als die Daten, die zum Trainieren von MPT-7B verwendet wurden. Mit anderen Worten, wir schätzen, dass nur halb so viele Tokens benötigt werden, um die gleiche Modellqualität zu erreichen. Dies haben wir ermittelt, indem wir DBRX Dense-A auf 500B Tokens trainiert haben; es übertraf MPT-7B auf dem Databricks Gauntlet und erreichte 32,1 %. Neben der besseren Datenqualität ist ein weiterer wichtiger Faktor für diese Token-Effizienz möglicherweise der GPT-4 Tokenizer, der ein großes Vokabular hat und als besonders Token-effizient gilt. Diese Erkenntnisse zur Verbesserung der Datenqualität lassen sich direkt in Praktiken und Tools umsetzen, die unsere Kunden zum Trainieren von Foundation Models auf ihren eigenen Daten verwenden.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabelle 5. Details zu mehreren Testartikeln, die wir zur Validierung der Trainingseffizienz der DBRX MoE-Architektur und der End-to-End-Trainingspipeline verwendet haben
Inferenz-Effizienz
Abbildung 2 zeigt die End-to-End-Inferenz-Effizienz des Servings von DBRX und ähnlichen Modellen mit NVIDIA TensorRT-LLM unter Verwendung unserer optimierten Serving-Infrastruktur und 16-Bit-Präzision. Wir streben danach, dass dieser Benchmark die reale Nutzung so genau wie möglich widerspiegelt, einschließlich mehrerer Benutzer, die gleichzeitig auf denselben Inferenzserver zugreifen. Wir starten einen neuen Benutzer pro Sekunde, jede Benutzeranfrage enthält einen Prompt von ungefähr 2000 Tokens und jede Antwort besteht aus 256 Tokens.
Im Allgemeinen sind MoE-Modelle bei der Inferenz schneller, als ihre Gesamtzahl an Parametern vermuten lässt. Dies liegt daran, dass sie für jede Eingabe relativ wenige Parameter verwenden. Wir stellen fest, dass DBRX hier keine Ausnahme darstellt. Der Inferenz-Durchsatz von DBRX ist 2-3x höher als bei einem 132B-Nicht-MoE-Modell.
Inferenz-Effizienz und Modellqualität stehen typischerweise im Widerspruch zueinander: größere Modelle erreichen in der Regel eine höhere Qualität, aber kleinere Modelle sind bei der Inferenz effizienter. Die Verwendung einer MoE-Architektur ermöglicht es, bessere Kompromisse zwischen Modellqualität und Inferenz-Effizienz zu erzielen, als dichte Modelle typischerweise erreichen. Zum Beispiel ist DBRX sowohl qualitativ hochwertiger als LLaMA2-70B als auch – dank etwa halb so vielen aktiven Parametern – ist der Inferenz-Durchsatz von DBRX bis zu 2x schneller (Abbildung 2). Mixtral ist ein weiterer Punkt auf der verbesserten Pareto-Grenze, die von MoE-Modellen erreicht wird: es ist kleiner als DBRX und entsprechend niedriger in Bezug auf die Qualität, erreicht aber einen höheren Inferenz-Durchsatz. Benutzer der Databricks Foundation Model APIs können bis zu 150 Tokens pro Sekunde für DBRX auf unserer optimierten Modell-Serving-Plattform mit 8-Bit-Quantisierung erwarten.

Wie wir DBRX gebaut haben
DBRX wurde auf 3072 NVIDIA H100s trainiert, die über 3,2 Tbps Infiniband verbunden sind. Der Hauptprozess des Baus von DBRX – einschließlich Pretraining, Post-Training, Evaluierung, Red-Teaming und Verfeinerung – dauerte drei Monate. Es war die Fortsetzung von Monaten der Wissenschaft, Datensatzforschung und Skalierungsexperimenten, ganz zu schweigen von jahrelanger LLM-Entwicklung bei Databricks, die die MPT und Dolly Projekte sowie die Tausenden von Modellen umfasst, die wir mit unseren Kunden gebaut und in Produktion gebracht haben.
Um DBRX zu bauen, haben wir die gleiche Suite von Databricks-Tools genutzt, die unseren Kunden zur Verfügung stehen. Wir haben unsere Trainingsdaten mit Unity Catalog verwaltet und gesteuert. Wir haben diese Daten mit dem neu erworbenen Lilac AI analysiert. Wir haben diese Daten mit Apache Spark™ und Databricks Notebooks verarbeitet und bereinigt. Wir haben DBRX mit optimierten Versionen unserer Open-Source-Trainingsbibliotheken trainiert: MegaBlocks, LLM Foundry, Composer und Streaming. Wir haben das groß angelegte Modelltraining und Finetuning auf Tausenden von GPUs mit unserem Databricks Training Service verwaltet. Wir haben unsere Ergebnisse mit MLflow protokolliert. Wir haben menschliches Feedback für Qualitäts- und Sicherheitsverbesserungen über Databricks Model Serving und Inference Tables gesammelt. Wir haben manuell mit dem Modell im Databricks Playground experimentiert. Wir fanden die Databricks-Tools für jeden ihrer Zwecke erstklassig und profitierten davon, dass sie alle Teil einer einheitlichen Produkterfahrung waren.
Starten Sie mit DBRX auf Databricks
Wenn Sie sofort mit DBRX arbeiten möchten, ist dies mit den Databricks Foundation Model APIs ganz einfach möglich. Sie können schnell mit unserer Pay-as-you-go-Preisgestaltung starten und das Modell über unsere AI Playground Chat-Oberfläche abfragen. Für Produktionsanwendungen bieten wir eine Provisioned Throughput-Option, um Leistungsgarantien zu bieten, Unterstützung für finetuned Modelle sowie zusätzliche Sicherheit und Compliance. Um DBRX privat zu hosten, können Sie das Modell vom Databricks Marketplace herunterladen und das Modell auf Model Serving bereitstellen.
Schlussfolgerungen
Bei Databricks glauben wir, dass jedes Unternehmen die Möglichkeit haben sollte, seine Daten und sein Schicksal in der aufkommenden Welt von GenAI zu kontrollieren. DBRX ist ein zentraler Pfeiler unserer nächsten Generation von GenAI-Produkten, und wir freuen uns auf die spannende Reise, die unsere Kunden erwartet, wenn sie die Fähigkeiten von DBRX und die Tools, mit denen wir es gebaut haben, nutzen. Im vergangenen Jahr haben wir Tausende von LLMs mit unseren Kunden trainiert. DBRX ist nur ein Beispiel für die leistungsstarken und effizienten Modelle, die bei Databricks für eine Vielzahl von Anwendungen gebaut werden, von internen Funktionen bis hin zu ambitionierten Anwendungsfällen für unsere Kunden.
Wie bei jedem neuen Modell ist die Reise mit DBRX gerade erst am Anfang, und die beste Arbeit wird von denen geleistet, die darauf aufbauen: Unternehmen und die Open-Community. Dies ist auch erst der Anfang unserer Arbeit an DBRX, und Sie sollten noch viel mehr erwarten.
Beiträge
Die Entwicklung von DBRX wurde vom Mosaic-Team geleitet, das zuvor die MPT-Modellfamilie entwickelt hatte, in Zusammenarbeit mit Dutzenden von Ingenieuren, Juristen, Beschaffungs- und Finanzspezialisten, Programmmanagern, Marketern, Designern und anderen Mitwirkenden aus ganz Databricks. Wir sind unseren Kollegen, Freunden, Familien und der Community für ihre Geduld und Unterstützung in den letzten Monaten dankbar.
Bei der Entwicklung von DBRX bauen wir auf den Erkenntnissen von Giganten aus der Open-Source- und akademischen Gemeinschaft auf. Indem wir DBRX offen zugänglich machen, beabsichtigen wir, in die Community zurückzuinvestieren, in der Hoffnung, dass wir in Zukunft noch größere Technologien gemeinsam entwickeln werden. In diesem Sinne danken wir Trevor Gale und seinem MegaBlocks Projekt (Trevor's Doktorvater ist Databricks CTO Matei Zaharia), dem PyTorch Team und dem FSDP Projekt, NVIDIA und dem TensorRT-LLM Projekt, dem vLLM Team und Projekt, EleutherAI und ihrem LLM evaluation Projekt, Daniel Smilkov und Nikhil Thorat bei Lilac AI sowie unseren Freunden am Allen Institute for Artificial Intelligence (AI2) für ihre Arbeit und Zusammenarbeit.
Über Databricks
Databricks ist das Data- and AI-Unternehmen. Mehr als 10.000 Organisationen weltweit – darunter Comcast, Condé Nast, Grammarly und über 50 % der Fortune 500 – verlassen sich auf die Databricks Data Intelligence Platform, um Daten, Analysen und KI zu vereinheitlichen und zu demokratisieren. Databricks hat seinen Hauptsitz in San Francisco, mit Niederlassungen auf der ganzen Welt, und wurde von den ursprünglichen Entwicklern von Lakehouse, Apache Spark™, Delta Lake und MLflow gegründet. Um mehr zu erfahren, folgen Sie Databricks auf LinkedIn, X und Facebook.
1 Zahlen laut xAI. Aufgrund fehlender Hugging Face-kompatibler Checkpoints zum Zeitpunkt der Veröffentlichung konnten wir Grok-1 nicht selbst auf unserer vollständigen Benchmark-Suite evaluieren.
2 DBRX wurde von uns mit dem EleutherAI Harness gemessen. Alle anderen Zahlen wurden auf der Hugging Face Open LLM Leaderboard gemeldet.
3 DBRX wurde von uns mit dem EleutherAI Harness unter Verwendung desselben älteren Commits gemessen, der auch von der Hugging Face Open LLM Leaderboard verwendet wird. Alle anderen Zahlen wurden auf der Hugging Face Open LLM Leaderboard gemeldet. Beachten Sie, dass bei Verwendung des neuesten Commits des EleutherAI Harness, der mehrere Parsing-Korrekturen enthält, DBRX's 5-Shot-Score auf GSM8k auf 72,8 % steigt, wie in Tabelle 2 berichtet. LLaMA2-70B Chat steigt ebenfalls auf 48,4 %.
4 Gemessen von Databricks unter Verwendung von Gauntlet v0.3.0 in LLM Foundry.
5 Sofern nicht anders angegeben, gemessen von Databricks.
6 Diese Zahl stammt aus dem Mixtral Arxiv Paper. Wir berichten diese Zahl, da sie höher ist als die, die wir bei der eigenen Evaluierung des Modells gemessen haben (36,7 %).
7 Alle Scores wie im GPT-4 Paper berichtet. Wir konnten Inflection Corrected MTBench nicht erfassen, da diese Version von GPT-3.5 nicht verfügbar ist. Wir haben festgestellt, dass die aktuelle Version von GPT-3.5 Turbo auf Inflection Corrected MTBench 8,58 ± 0,04 im Vergleich zu 8,39 +/- 0,08 für DBRX Instruct erzielt.
8 Alle Scores wie im GPT-4 Paper berichtet. Wir konnten Inflection Corrected MTBench nicht erfassen, da diese Version von GPT-4 nicht verfügbar ist. Wir haben festgestellt, dass die aktuelle Version von GPT-4 Turbo auf Inflection Corrected MTBench 9,27 ± 0,10 im Vergleich zu 8,39 +/- 0,08 für DBRX Instruct erzielt.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.