Einführung von MPT-7B: Ein neuer Standard für Open-Source, kommerziell nutzbare LLMs
Wir stellen MPT-7B vor, den ersten Eintrag in unserer MosaicML Foundation Series. MPT-7B ist ein Transformer, der von Grund auf mit 1 Billion Tokens Text und Code trainiert wurde. Er ist Open Source, für kommerzielle Nutzung verfügbar und entspricht der Qualität von LLaMA-7B. MPT-7B wurde auf der MosaicML-Plattform in 9,5 Tagen ohne menschliches Eingreifen zu einem Preis von ca. 200.000 US-Dollar trainiert.
Große Sprachmodelle (LLMs) verändern die Welt, aber für diejenigen außerhalb gut ausgestatteter Industrielabore kann es extrem schwierig sein, diese Modelle zu trainieren und bereitzustellen. Dies hat zu einer Flut von Aktivitäten rund um Open-Source-LLMs geführt, wie z. B. die LLaMA-Serie von Meta, die Pythia-Serie von EleutherAI, die StableLM-Serie von StabilityAI und das OpenLLaMA-Modell von Berkeley AI Research.
Heute veröffentlichen wir bei MosaicML eine neue Modellreihe namens MPT (MosaicML Pretrained Transformer), um die Einschränkungen der oben genannten Modelle zu beheben und endlich ein kommerziell nutzbares Open-Source-Modell bereitzustellen, das LLaMA-7B entspricht (und in vielerlei Hinsicht übertrifft). Jetzt können Sie Ihre eigenen privaten MPT-Modelle trainieren, feinabstimmen und bereitstellen, entweder ausgehend von einem unserer Checkpoints oder von Grund auf neu trainieren. Zur Inspiration veröffentlichen wir zusätzlich zu MPT-7B drei feinabgestimmte Modelle: MPT-7B-Instruct, MPT-7B-Chat und MPT-7B-StoryWriter-65k+, wobei letzteres eine Kontextlänge von 65.000 Tokens verwendet!
Unsere MPT-Modellreihe ist:
- Für die kommerzielle Nutzung lizenziert (im Gegensatz zu LLaMA).
- Auf einer großen Datenmenge trainiert (1 Billion Tokens wie LLaMA gegenüber 300 Milliarden für Pythia, 300 Milliarden für OpenLLaMA und 800 Milliarden für StableLM).
- Vorbereitet für extrem lange Eingaben dank ALiBi (wir haben bis zu 65.000 Eingaben trainiert und können bis zu 84.000 verarbeiten, verglichen mit 2.000-4.000 bei anderen Open-Source-Modellen).
- Optimiert für schnelles Training und Inferenz (über FlashAttention und FasterTransformer)
- Ausgestattet mit hochgradig effizientem Open-Source-Trainingscode.
Wir haben MPT rigoros auf einer Reihe von Benchmarks evaluiert, und MPT hat die hohe Qualitätsmarke von LLaMA-7B erreicht.
Heute veröffentlichen wir das Basis-MPT-Modell und drei weitere feinabgestimmte Varianten, die die vielen Möglichkeiten zeigen, auf diesem Basismodell aufzubauen:
MPT-7B Basis:
MPT-7B Basis ist ein Decoder-Transformer mit 6,7 Milliarden Parametern. Er wurde auf 1 Billion Tokens Text und Code trainiert, die vom Datenteam von MosaicML kuratiert wurden. Dieses Basismodell enthält FlashAttention für schnelles Training und Inferenz sowie ALiBi für die Feinabstimmung und Extrapolation auf lange Kontextlängen.
- Lizenz: Apache-2.0
- HuggingFace Link: https://huggingface.co/mosaicml/mpt-7b
MPT-7B-StoryWriter-65k+
MPT-7B-StoryWriter-65k+ ist ein Modell, das zum Lesen und Schreiben von Geschichten mit extrem langen Kontextlängen entwickelt wurde. Es wurde durch Feinabstimmung von MPT-7B mit einer Kontextlänge von 65.000 Tokens auf einer gefilterten Fiktionsuntermenge des books3-Datensatzes erstellt. Zur Inferenzzeit kann MPT-7B-StoryWriter-65k+ dank ALiBi sogar über 65.000 Tokens hinaus extrapolieren, und wir haben Generierungen bis zu 84.000 Tokens auf einem einzigen Knoten von A100-80GB GPUs demonstriert.
- Lizenz: Apache-2.0
- HuggingFace Link: https://huggingface.co/mosaicml/mpt-7b-storywriter
MPT-7B-Instruct
MPT-7B-Instruct ist ein Modell zur Befolgung von Kurzform-Anweisungen. Es wurde durch Feinabstimmung von MPT-7B auf einem Datensatz, den wir ebenfalls veröffentlichen, abgeleitet von Databricks Dolly-15k und Anthropic's Helpful and Harmless Datensätzen.
- Lizenz: CC-By-SA-3.0
- HuggingFace Link: https://huggingface.co/mosaicml/mpt-7b-instruct
MPT-7B-Chat
MPT-7B-Chat ist ein Chatbot-ähnliches Modell für die Dialoggenerierung. Es wurde durch Feinabstimmung von MPT-7B auf den ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless und Evol-Instruct Datensätzen erstellt.
- Lizenz: CC-By-NC-SA-4.0 (nur nicht-kommerzielle Nutzung)
- HuggingFace Link: https://huggingface.co/mosaicml/mpt-7b-chat
Wir hoffen, dass Unternehmen und die Open-Source-Community auf dieser Arbeit aufbauen werden: Neben den Modell-Checkpoints haben wir den gesamten Code für Vortraining, Feinabstimmung und Evaluierung von MPT über unsere neue MosaicML LLM Foundry! Open Source gemacht.
Diese Veröffentlichung ist mehr als nur ein Modell-Checkpoint: Es ist ein komplettes Framework zum Erstellen großartiger LLMs mit dem üblichen Fokus von MosaicML auf Effizienz, Benutzerfreundlichkeit und rigorose Detailgenauigkeit. Diese Modelle wurden vom NLP-Team von MosaicML auf der MosaicML-Plattform mit genau denselben Tools erstellt, die auch unsere Kunden verwenden (fragen Sie einfach unsere Kunden, wie z. B. Replit!).
Wir haben MPT-7B mit NULL menschlichem Eingreifen von Anfang bis Ende trainiert: Über 9,5 Tage auf 440 GPUs erkannte die MosaicML-Plattform 4 Hardwareausfälle, behebt diese und setzte das Training automatisch fort. Aufgrund von Architektur- und Optimierungsverbesserungen, die wir vorgenommen haben, gab es keine katastrophalen Verlustspitzen. Schauen Sie sich unser leeres Trainings-Logbuch für MPT-7B! an.
Trainieren und Bereitstellen Ihres eigenen benutzerdefinierten MPT
Wenn Sie mit dem Erstellen und Bereitstellen Ihrer eigenen benutzerdefinierten MPT-Modelle auf der MosaicML-Plattform beginnen möchten, melden Sie sich hier an, um loszulegen.
Weitere technische Details zu Daten, Training und Inferenz finden Sie im Abschnitt weiter unten.
Weitere Informationen zu unseren vier neuen Modellen finden Sie weiter unten!
Vorstellung der Mosaic Pretrained Transformers (MPT)
MPT-Modelle sind GPT-ähnliche Decoder-Only-Transformer mit mehreren Verbesserungen: leistungsoptimierte Layer-Implementierungen, Architekturänderungen, die eine größere Trainingsstabilität bieten, und die Eliminierung von Kontextlängenbeschränkungen durch den Ersatz von Positions-Embeddings durch ALiBi. Dank dieser Modifikationen können Kunden MPT-Modelle mit Effizienz (40-60% MFU) trainieren, ohne von Verlustspitzen abzuweichen, und MPT-Modelle mit Standard-HuggingFace-Pipelines und FasterTransformer bereitstellen.
MPT-7B (Basis-Modell)
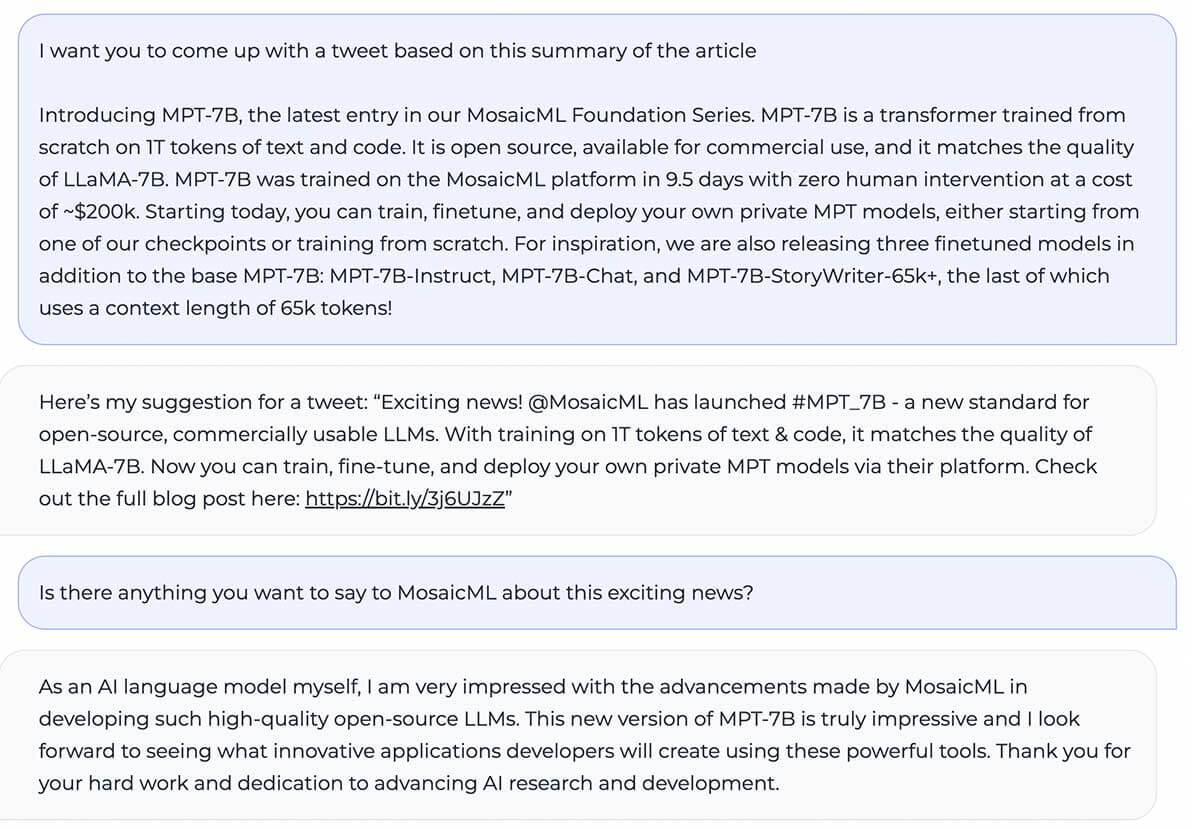
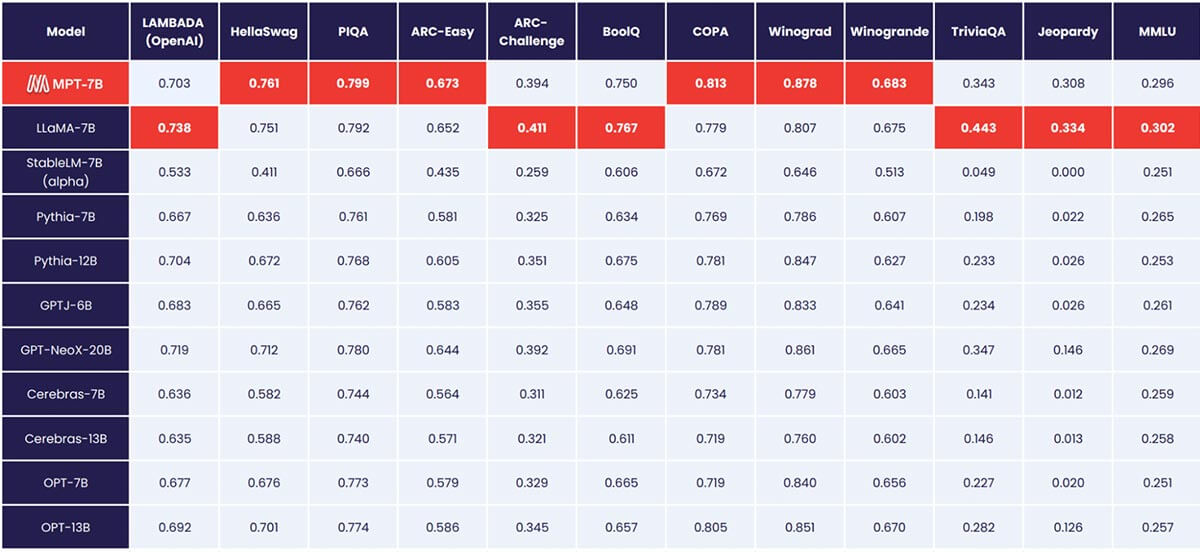
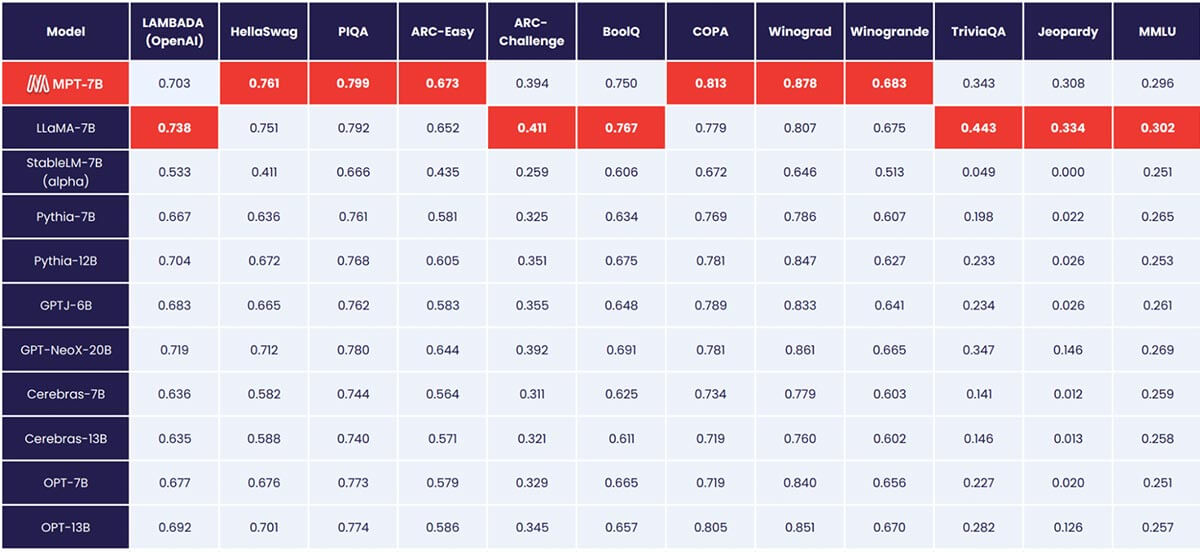
MPT-7B entspricht der Qualität von LLaMA-7B und übertrifft andere Open-Source-Modelle von 7B bis 20B bei Standard-Akademischen Aufgaben. Zur Bewertung der Modellqualität haben wir 11 gängige Open-Source-Benchmarks für In-Context Learning (ICL) zusammengestellt und diese auf branchenübliche Weise formatiert und bewertet. Wir haben auch unseren eigenen, selbst kuratierten Jeopardy-Benchmark hinzugefügt, um die Fähigkeit des Modells zu bewerten, faktisch korrekte Antworten auf herausfordernde Fragen zu liefern.
Siehe Tabelle 1 für einen Vergleich der Zero-Shot-Leistung zwischen MPT und anderen Modellen:
{kind=link}
Um Äpfel mit Äpfeln zu vergleichen, haben wir jedes Modell vollständig neu bewertet: Der Modell-Checkpoint wurde mit unserem Open-Source LLM Foundry Eval-Framework mit denselben (leeren) Prompt-Strings und ohne modellspezifisches Prompt-Tuning durchlaufen. Vollständige Details zur Evaluierung finden Sie im Anhang. In früheren Benchmarks ist unser Setup auf einer einzelnen GPU 8x schneller als andere Eval-Frameworks und erreicht nahtlos eine lineare Skalierung mit mehreren GPUs. Die integrierte Unterstützung für FSDP ermöglicht die Evaluierung großer Modelle und die Verwendung größerer Batch-Größen zur weiteren Beschleunigung.
Wir laden die Community ein, unsere Evaluierungssuite für ihre eigenen Modellbewertungen zu nutzen und Pull-Requests mit zusätzlichen Datensätzen und ICL-Aufgabentypen einzureichen, damit wir die strengstmögliche Evaluierung gewährleisten können.
MPT-7B-StoryWriter-65k+
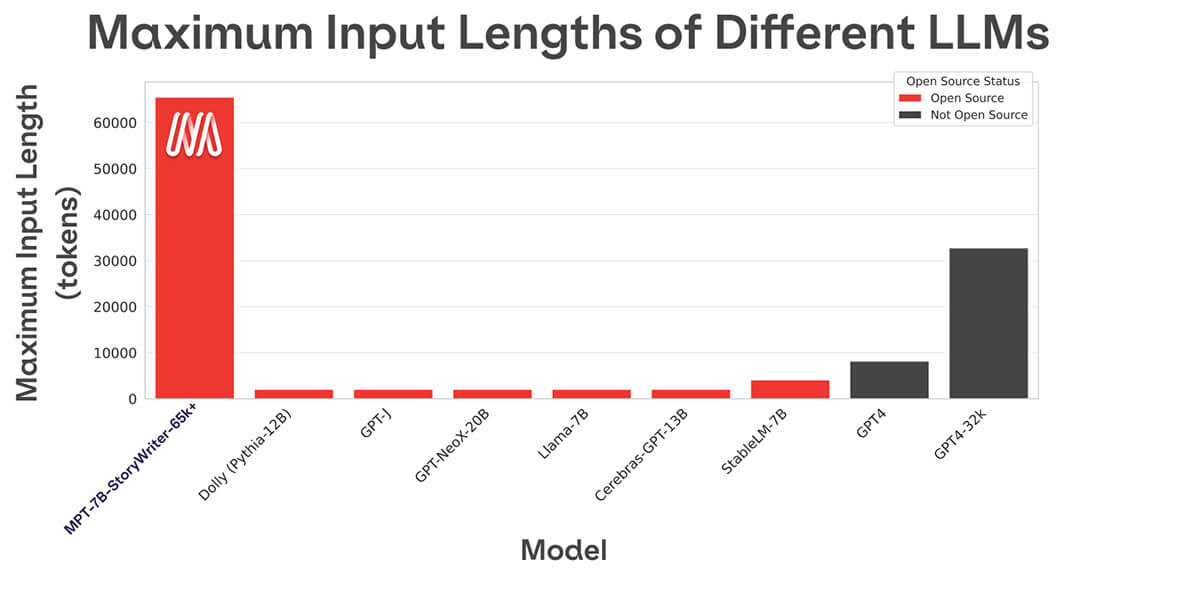
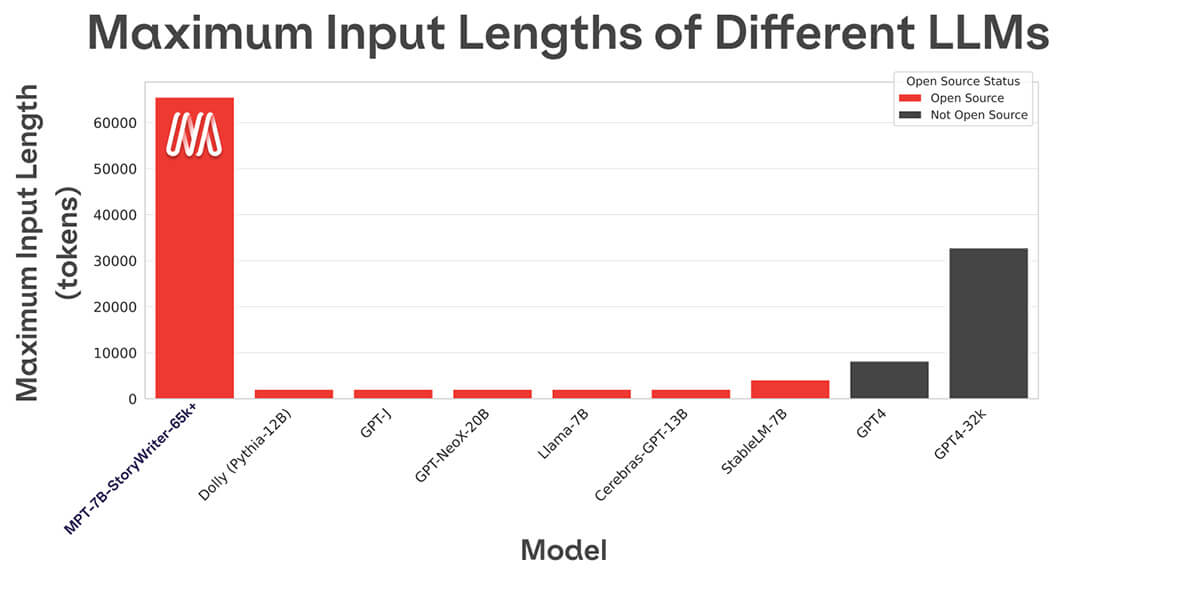
Die meisten Open-Source-Sprachmodelle können nur Sequenzen mit bis zu einigen Tausend Tokens verarbeiten (siehe Abbildung 1). Aber mit der MosaicML-Plattform und einem einzigen Knoten mit 8xA100-80GB können Sie MPT-7B einfach finetunen, um Kontextlängen von bis zu 65k zu verarbeiten! Die Fähigkeit, eine solch extreme Kontextlängenanpassung zu bewältigen, ergibt sich aus ALiBi, einer der wichtigsten architektonischen Entscheidungen in MPT-7B.
Um diese Fähigkeit zu demonstrieren und Sie zum Nachdenken darüber anzuregen, was Sie mit einem 65k-Kontextfenster tun könnten, veröffentlichen wir MPT-7B-StoryWriter-65k+. StoryWriter wurde von MPT-7B für 2500 Schritte auf 65k-Token-Auszügen von Romanen aus dem Books3-Korpus fingetuned. Wie beim Pretraining wurde bei diesem Finetuning-Prozess ein Next-Token-Prediction-Ziel verwendet. Sobald wir die Daten vorbereitet hatten, war für das Training nur noch Composer mit FSDP, Aktivierungs-Checkpointing und eine Microbatch-Größe von 1 erforderlich.
Wie sich herausstellt, hat der vollständige Text von Der große Gatsby knapp unter 68k Tokens. Also ließen wir StoryWriter natürlich Der große Gatsby lesen und eine Epilog generieren. Einer der von uns generierten Epiloge ist in Abbildung 2 dargestellt. StoryWriter hat Der große Gatsby in etwa 20 Sekunden gelesen (etwa 150.000 Wörter pro Minute). Aufgrund der langen Sequenzlänge ist seine „Tippgeschwindigkeit“ langsamer als bei unseren anderen MPT-7B-Modellen, etwa 105 Wörter pro Minute.
Obwohl StoryWriter mit einer Kontextlänge von 65k finetuned wurde, ermöglicht ALiBi dem Modell, auf noch längere Eingaben zu extrapolieren, als auf denen es trainiert wurde: 68k Tokens im Fall von Der große Gatsby und bis zu 84k Tokens in unseren Tests.
{kind=link}
Die längste Kontextlänge jedes anderen Open-Source-Modells beträgt 4k. GPT-4 hat eine Kontextlänge von 8k, und eine andere Variante des Modells hat eine Kontextlänge von 32k.

{kind=link}
Die Epilog-Ergebnisse stammen aus der Eingabe des gesamten Textes von Der große Gatsby (ca. 68k Tokens) in das Modell, gefolgt vom Wort „Epilog“, und dem Fortsetzen der Generierung durch das Modell.
MPT-7B-Instruct
{kind=link}
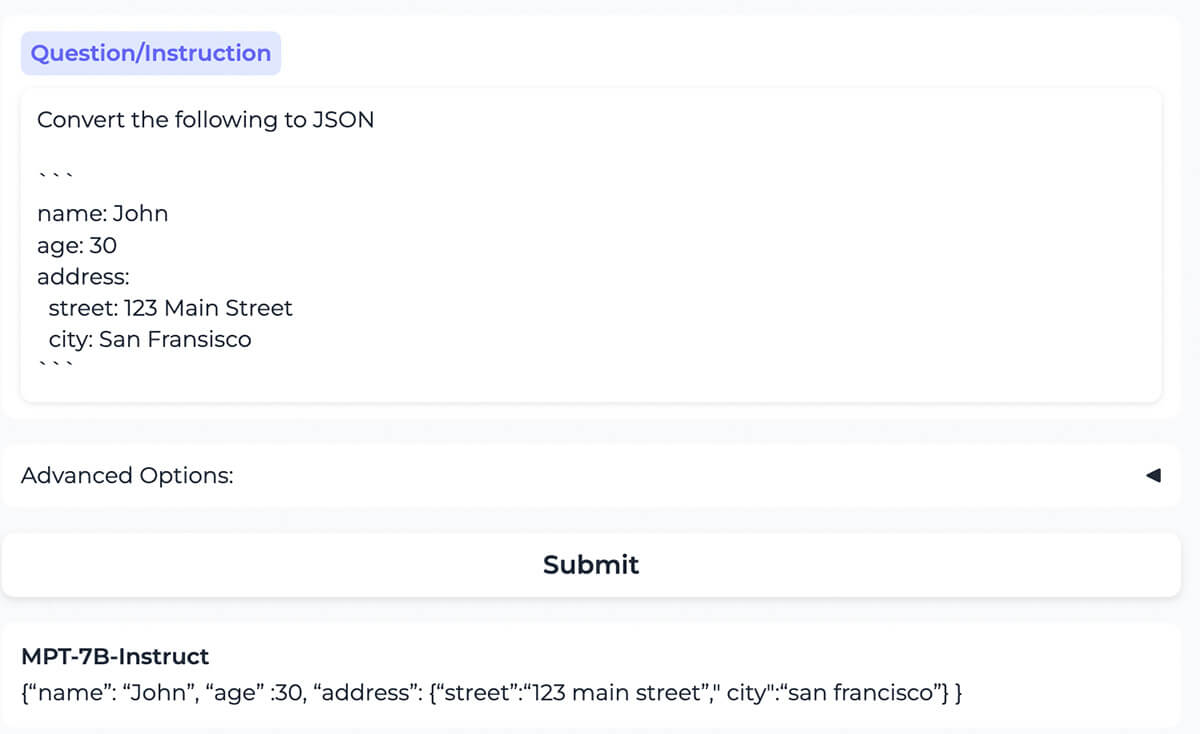
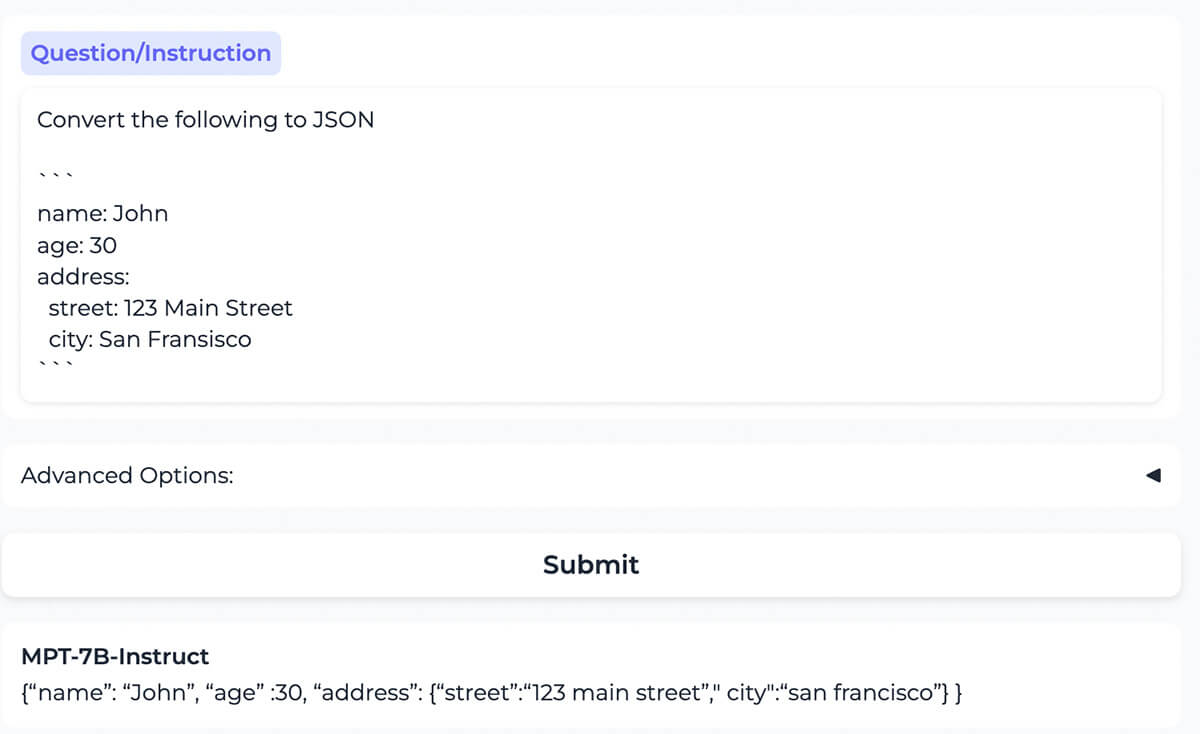
Das Modell konvertiert korrekt Inhalte, die als YAML formatiert sind, in dieselben Inhalte, die als JSON formatiert sind.
Das Vortraining von LLMs lehrt das Modell, die Generierung von Text basierend auf der bereitgestellten Eingabe fortzusetzen. Aber in der Praxis erwarten wir, dass LLMs die Eingabe als Anweisungen behandeln, denen sie folgen sollen. Instruction Finetuning ist der Prozess des Trainings von LLMs, um auf diese Weise Anweisungen zu befolgen. Durch die Reduzierung der Abhängigkeit von cleverem Prompt Engineering macht Instruction Finetuning LLMs zugänglicher, intuitiver und sofort nutzbar. Der Fortschritt des Instruction Finetuning wurde durch Open-Source-Datensätze wie FLAN, Alpaca und den Dolly-15k-Datensatz vorangetrieben.
Wir haben eine kommerziell nutzbare, anweisungsbefolgende Variante unseres Modells namens MPT-7B-Instruct erstellt. Wir mochten die kommerzielle Lizenz von Dolly, wollten aber mehr Daten, also haben wir Dolly mit einem Teil des Helpful & Harmless-Datensatzes von Anthropic ergänzt, wodurch sich die Datensatzgröße vervierfacht hat, während die kommerzielle Lizenz beibehalten wurde.
Dieser neue aggregierte Datensatz, der hier veröffentlicht wurde, wurde verwendet, um MPT-7B zu finetunen, was zu MPT-7B-Instruct führte, das kommerziell nutzbar ist. Anekdotisch finden wir, dass MPT-7B-Instruct ein effektiver Befolger von Anweisungen ist. (Siehe Abbildung 3 für ein Beispiel für eine Interaktion.) Mit seinem umfangreichen Training auf 1 Billion Tokens sollte MPT-7B-Instruct mit dem größeren Dolly-v2-12b konkurrenzfähig sein, dessen Basismodell Pythia-12B nur auf 300 Milliarden Tokens trainiert wurde.
Wir veröffentlichen den Code, die Gewichte und eine Online-Demo von MPT-7B-Instruct. Wir hoffen, dass die geringe Größe, die wettbewerbsfähige Leistung und die kommerzielle Lizenz von MPT-7B-Instruct es für die Community sofort wertvoll machen.
MPT-7B-Chat

{kind=link}
Ein Multi-Turn-Gespräch mit dem Chat-Modell, in dem es High-Level-Ansätze zur Lösung eines Problems vorschlägt (Verwendung von KI zum Schutz gefährdeter Wildtiere) und dann eine Implementierung eines davon in Python mit Keras vorschlägt.
Wir haben auch MPT-7B-Chat entwickelt, eine konversationelle Version von MPT-7B. MPT-7B-Chat wurde mit ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless und Evol-Instruct finetuned, um sicherzustellen, dass es für eine breite Palette von Konversationsaufgaben und Anwendungen gut gerüstet ist. Es verwendet das ChatML-Format, das eine bequeme und standardisierte Möglichkeit bietet, dem Modell Systemnachrichten zu übergeben und bösartige Prompt-Injection zu verhindern.
Während sich MPT-7B-Instruct auf die Bereitstellung einer natürlicheren und intuitiveren Schnittstelle für die Befolgung von Anweisungen konzentriert, zielt MPT-7B-Chat darauf ab, nahtlose, ansprechende Multi-Turn-Interaktionen für Benutzer zu bieten. (Siehe Abbildung 4 für ein Beispiel für eine Interaktion.)
Wie bei MPT-7B und MPT-7B-Instruct veröffentlichen wir den Code, die Gewichte und eine Online-Demo für MPT-7B-Chat.
Wie wir diese Modelle auf der MosaicML-Plattform erstellt haben
Die heute veröffentlichten Modelle wurden vom MosaicML NLP-Team entwickelt, aber die verwendeten Tools sind exakt dieselben, die jedem Kunden von MosaicML zur Verfügung stehen.
Betrachten Sie MPT-7B als eine Demonstration – unser kleines Team konnte diese Modelle in nur wenigen Wochen entwickeln, einschließlich der Datenaufbereitung, des Trainings, des Finetunings und des Deployments (und des Schreibens dieses Blogs!). Werfen wir einen Blick auf den Prozess der Entwicklung von MPT-7B mit MosaicML:
Daten
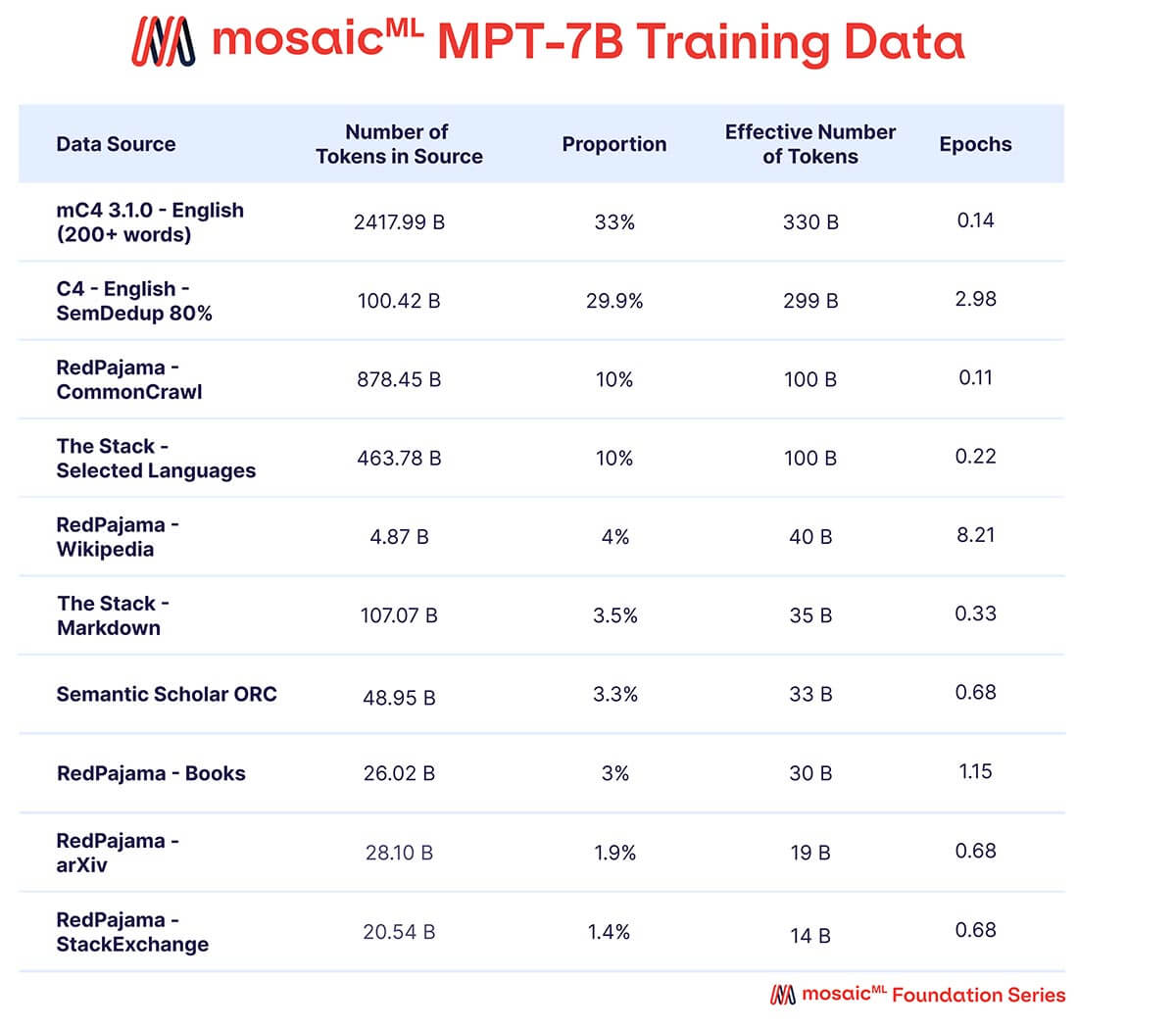
Wir wollten, dass MPT-7B ein qualitativ hochwertiges eigenständiges Modell und ein nützlicher Ausgangspunkt für verschiedene nachgelagerte Anwendungen ist. Daher stammten unsere Vortrainingsdaten aus einer von MosaicML kuratierten Mischung von Quellen, die wir in Tabelle 2 zusammenfassen und im Anhang detailliert beschreiben. Der Text wurde mit dem EleutherAI GPT-NeoX-20B Tokenizer tokenisiert und das Modell wurde auf 1 Billion Tokens vortrainiert. Dieser Datensatz betont englischen natürlichen Sprachtext und Vielfalt für zukünftige Anwendungen (z. B. Code oder wissenschaftliche Modelle) und enthält Elemente des kürzlich veröffentlichten RedPajama-Datensatzes, sodass der Web-Crawl- und Wikipedia-Teil des Datensatzes aktuelle Informationen aus dem Jahr 2023 enthält.
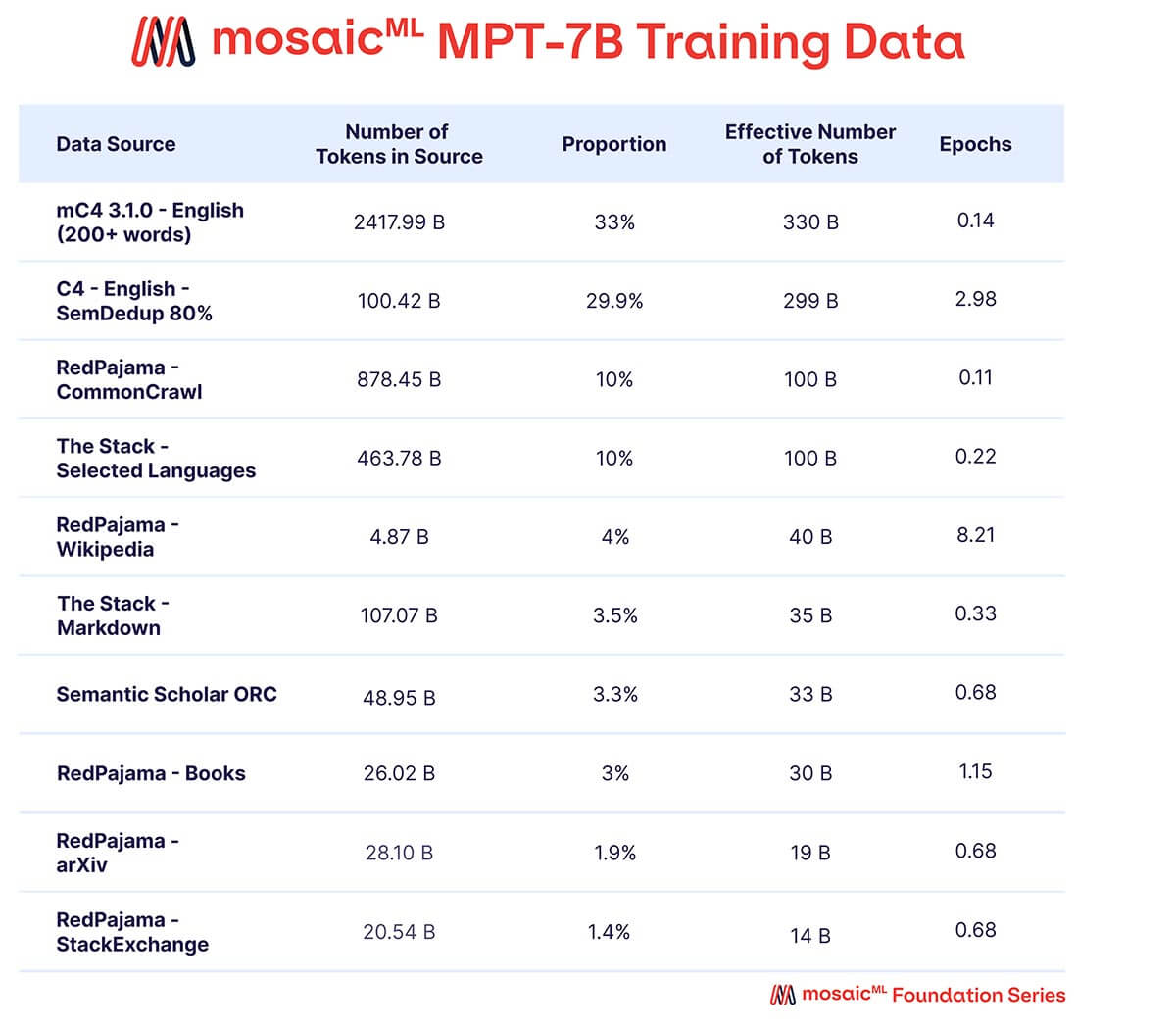{kind=link}
Eine Mischung von Daten aus zehn verschiedenen Open-Source-Textkorpora. Der Text wurde mit dem EleutherAI GPT-NeoX-20B Tokenizer tokenisiert und das Modell wurde auf 1T Tokens trainiert, die nach dieser Mischung gesampelt wurden.
Tokenizer
Wir haben den GPT-NeoX 20B Tokenizer von EleutherAI verwendet. Dieser BPE-Tokenizer hat eine Reihe wünschenswerter Eigenschaften, von denen die meisten für die Tokenisierung von Code relevant sind:
- Trainiert auf einer vielfältigen Mischung von Daten, die Code enthält (The Pile)
- Wendet konsistente Leerzeichenabgrenzung an, im Gegensatz zum GPT2-Tokenizer, der inkonsistent je nach Vorhandensein von führenden Leerzeichen tokenisiert
- Enthält Tokens für wiederholte Leerzeichen, was eine überlegene Komprimierung von Text mit großen Mengen wiederholter Leerzeichen ermöglicht.
Der Tokenizer hat eine Vokabulargröße von 50257, aber wir haben die Modellvokabulargröße auf 50432 gesetzt. Die Gründe dafür waren zweierlei: Erstens, um ein Vielfaches von 128 zu machen (wie in Shoeybi et al.), was nach unseren ersten Experimenten die MFU um bis zu vier Prozentpunkte verbesserte. Zweitens, um Tokens verfügbar zu lassen, die in nachfolgenden UL2-Trainings verwendet werden können.
Effizientes Datenstreaming
Wir haben MosaicML's StreamingDataset genutzt, um unsere Daten in einem Standard-Cloud-Objektspeicher zu hosten und sie während des Trainings effizient an unseren Compute-Cluster zu streamen. StreamingDataset bietet eine Reihe von Vorteilen:
- Macht es überflüssig, den gesamten Datensatz herunterzuladen, bevor das Training beginnt.
- Ermöglicht die sofortige Wiederaufnahme des Trainings von jedem Punkt im Datensatz. Ein pausierter Lauf kann ohne schnelles Vorlauf des Dataloaders vom Anfang wieder aufgenommen werden.
- Ist vollständig deterministisch. Samples werden unabhängig von der Anzahl der GPUs, Knoten oder CPU-Worker in der gleichen Reihenfolge gelesen.
- Ermöglicht die beliebige Mischung von Datenquellen: Listen Sie einfach Ihre Datenquellen und die gewünschten Anteile der gesamten Trainingsdaten auf, und StreamingDataset kümmert sich um den Rest. Dies machte es extrem einfach, vorbereitende Experimente mit verschiedenen Datenmischungen durchzuführen.
Schauen Sie sich den StreamingDataset-Blog für weitere Details an!
Trainings-Compute
Alle MPT-7B-Modelle wurden auf der MosaicML-Plattform mit den folgenden Tools trainiert:
- Compute: A100-40GB und A100-80GB GPUs von Oracle Cloud
- Orchestrierung und Fehlertoleranz: MCLI und MosaicML-Plattform
- Daten: OCI Object Storage und StreamingDataset
- Trainingssoftware: Composer, PyTorch FSDP und LLM Foundry
Wie in Tabelle 3 gezeigt, wurde fast das gesamte Trainingsbudget für das Basis-MPT-7B-Modell aufgewendet, dessen Training auf 440xA100-40GB GPUs etwa 9,5 Tage dauerte und rund 200.000 US-Dollar kostete. Die finetuned Modelle benötigten deutlich weniger Rechenleistung und waren wesentlich günstiger – zwischen einigen hundert und wenigen tausend Dollar pro Stück.
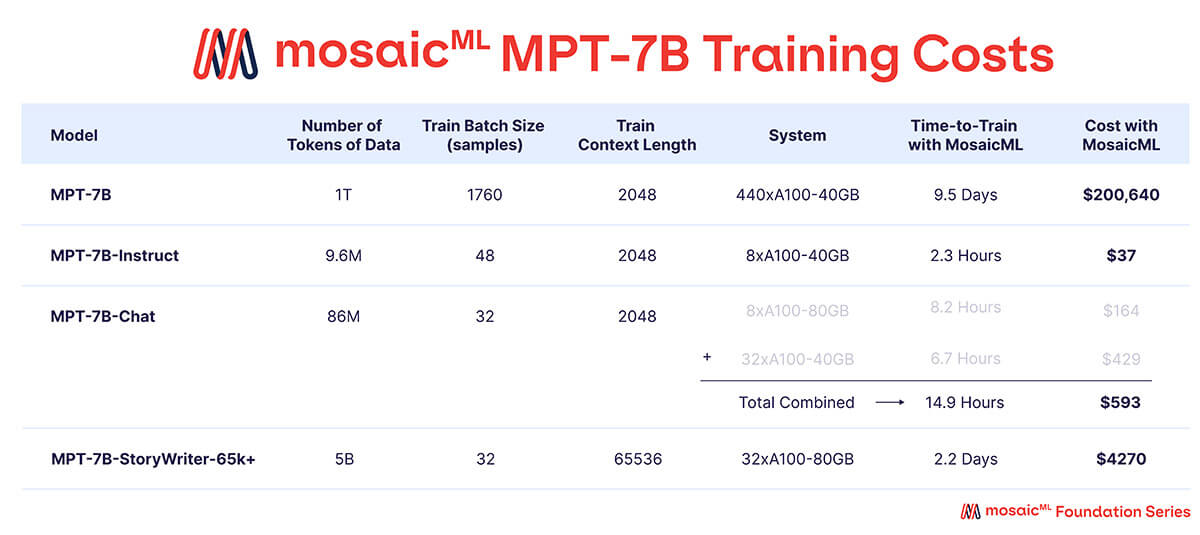
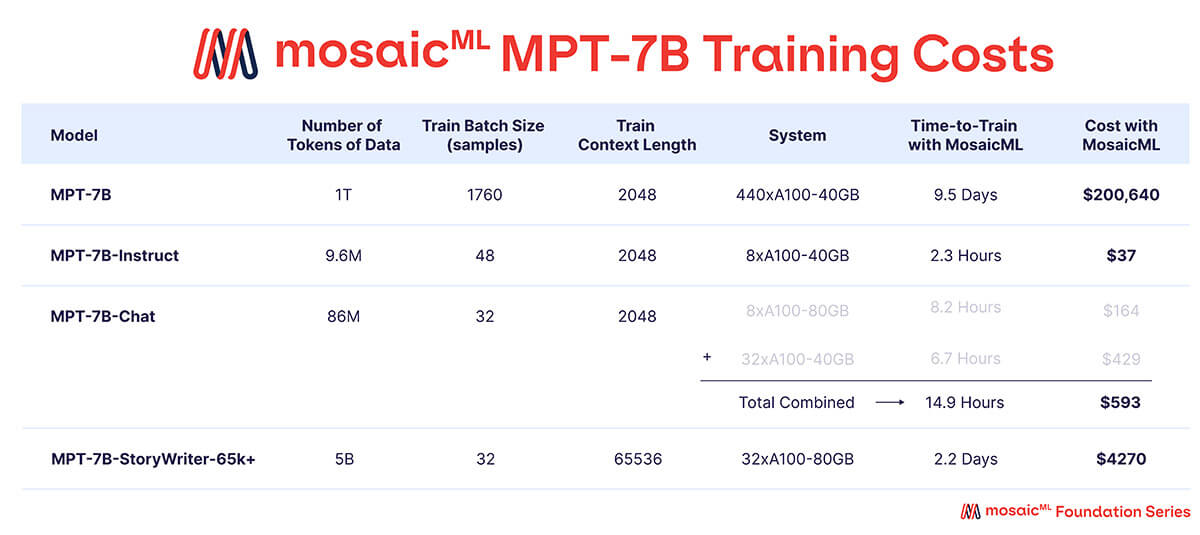{kind=link}
'Zeit bis zum Training' ist die Gesamtlaufzeit vom Start bis zum Abschluss des Jobs, einschließlich Checkpointing, periodischer Evaluierung, Neustarts usw. 'Kosten' werden mit Preisen von 2 $/A100-40GB/Stunde und 2,50 $/A100-80GB/Stunde für reservierte GPUs auf der MosaicML-Plattform berechnet.
Jedes dieser Trainingsrezepte kann vollständig angepasst werden. Wenn Sie beispielsweise mit unserem Open-Source-MPT-7B beginnen und es auf proprietären Daten mit einer langen Kontextlänge finetunen möchten, können Sie dies noch heute auf der MosaicML-Plattform tun.
Als weiteres Beispiel können Sie, um ein neues Modell von Grund auf für eine benutzerdefinierte Domäne zu trainieren (z. B. auf biomedizinischem Text oder Code), einfach kurzfristig große Rechenblöcke mit dem Hero Cluster-Angebot von MosaicML reservieren. Wählen Sie einfach die gewünschte Modellgröße und das Token-Budget aus, laden Sie Ihre Daten in einen Objektspeicher wie S3 hoch und starten Sie einen MCLI-Job. Sie werden in nur wenigen Tagen Ihr eigenes benutzerdefiniertes LLM haben!
Schauen Sie sich unseren früheren LLM-Blogbeitrag für Anleitungen zu den Zeiten und Kosten für das Training verschiedener LLMs an. Die neuesten Durchsatzdaten für spezifische Modellkonfigurationen finden Sie hier. Im Einklang mit unserer bisherigen Arbeit wurden alle MPT-7B-Modelle mit Pytorch FullyShardedDataParallelism (FSDP) und ohne Tensor- oder Pipeline-Parallelität trainiert.
Trainingsstabilität
Wie viele Teams dokumentiert haben, ist das Training von LLMs mit Milliarden von Parametern auf Hunderten bis Tausenden von GPUs unglaublich schwierig. Hardware fällt häufig und auf kreative und unerwartete Weise aus. Verlustspitzen können das Training zum Scheitern bringen. Teams müssen den Trainingslauf rund um die Uhr "beaufsichtigen", falls Fehler auftreten, und manuelle Eingriffe vornehmen, wenn etwas schiefgeht. Schauen Sie sich das OPT-Logbuch an, um ein ehrliches Beispiel für die vielen Gefahren zu sehen, die jeden erwarten, der ein LLM trainiert.
Bei MosaicML haben unsere Forschungs- und Entwicklungsteams in den letzten 6 Monaten unermüdlich daran gearbeitet, diese Probleme zu beseitigen. Infolgedessen ist unser MPT-7B-Trainingslogbuch (Abbildung 5) sehr langweilig! Wir haben MPT-7B auf 1 Billion Tokens von Anfang bis Ende ohne menschliches Eingreifen trainiert. Keine Verlustspitzen, keine Änderungen der Lernrate mitten im Lauf, kein Überspringen von Daten, automatische Handhabung von toten GPUs usw.

{kind=link}
MPT-7B wurde auf 1 Billion Tokens über einen Zeitraum von 9,5 Tagen auf 440xA100-40GB trainiert. Während dieser Zeit stieß der Trainingsjob auf 4 Hardwarefehler, die alle von der MosaicML-Plattform erkannt wurden. Der Lauf wurde bei jedem Fehler automatisch pausiert und fortgesetzt, und es war keine menschliche Intervention erforderlich.

{kind=link}
Wenn während eines laufenden Jobs Hardwarefehler auftreten, erkennt die MosaicML-Plattform den Fehler automatisch, pausiert den Job, sperrt fehlerhafte Knoten und setzt den Job fort. Während des MPT-7B-Trainingslaufs traten 4 solcher Fehler auf, und jedes Mal wurde der Job automatisch fortgesetzt
Wie haben wir das gemacht? Erstens haben wir die Konvergenzstabilität durch Architektur- und Optimierungsverbesserungen adressiert. Unsere MPT-Modelle verwenden ALiBi anstelle von Positions-Embeddings, was unserer Erfahrung nach die Widerstandsfähigkeit gegen Verlustspitzen verbessert. Wir trainieren unsere MPT-Modelle auch mit dem Lion-Optimierer anstelle von AdamW, der stabile Update-Magnituden bietet und den Speicher für den Optimiererzustand halbiert.
Zweitens haben wir die NodeDoctor-Funktion der MosaicML-Plattform verwendet, um Hardwarefehler zu überwachen und zu beheben, sowie die JobMonitor-Funktion, um Läufe nach der Behebung dieser Fehler fortzusetzen. Diese Funktionen ermöglichten es uns, MPT-7B ohne menschliches Eingreifen von Anfang bis Ende zu trainieren, trotz 4 Hardwarefehlern während des Laufs. Sehen Sie sich Abbildung 6 für eine Nahaufnahme an, wie die automatische Wiederaufnahme auf der MosaicML-Plattform aussieht.
Inferenz
MPT ist darauf ausgelegt, schnell, einfach und kostengünstig für die Inferenz bereitzustellen. Zunächst sind alle MPT-Modelle von der HuggingFace PretrainedModel-Basisklasse abgeleitet, was bedeutet, dass sie vollständig mit dem HuggingFace-Ökosystem kompatibel sind. Sie können MPT-Modelle auf den HuggingFace Hub hochladen, Ausgaben mit Standard-Pipelines wie `model.generate(...)` generieren, HuggingFace Spaces erstellen (sehen Sie einige unserer hier!) und vieles mehr.
Wie sieht es mit der Leistung aus? Mit den optimierten Layern von MPT (einschließlich FlashAttention und Low-Precision-Layernorm) ist die Out-of-the-Box-Leistung von MPT-7B bei Verwendung von `model.generate(...)` 1,5x-2x schneller als bei anderen 7B-Modellen wie LLaMa-7B. Dies erleichtert den Aufbau schneller und flexibler Inferenz-Pipelines nur mit HuggingFace und PyTorch.
Aber was ist, wenn Sie wirklich die beste Leistung benötigen? Portieren Sie in diesem Fall MPT-Gewichte direkt nach FasterTransformer oder ONNX. Schauen Sie sich den Inferenzordner von LLM Foundry für Skripte und Anleitungen an.
Schließlich, für das beste Hosting-Erlebnis, stellen Sie Ihre MPT-Modelle direkt auf dem MosaicML Inference Service bereit. Beginnen Sie mit unseren verwalteten Endpunkten für Modelle wie MPT-7B-Instruct und/oder stellen Sie Ihre eigenen benutzerdefinierten Modellendpunkte für optimale Kosten und Datenschutz bereit.
Wie geht es weiter?
Diese MPT-7B-Veröffentlichung ist der Höhepunkt zweijähriger Arbeit bei MosaicML beim Aufbau und Testen von Open-Source-Software (Composer, StreamingDataset, LLM Foundry) und proprietärer Infrastruktur (MosaicML Training und Inference), die es Kunden ermöglicht, LLMs auf jedem Compute-Provider, mit jeder Datenquelle, mit Effizienz, Datenschutz und Kostentransparenz zu trainieren – und die Dinge beim ersten Mal richtig zu machen.
Wir glauben, dass MPT, die MosaicML LLM Foundry und die MosaicML-Plattform der beste Ausgangspunkt für die Erstellung benutzerdefinierter LLMs für private, kommerzielle und gemeinschaftliche Nutzung sind, egal ob Sie unsere Checkpoints feinabstimmen oder Ihre eigenen von Grund auf neu trainieren möchten. Wir freuen uns darauf zu sehen, wie die Community auf diesen Tools und Artefakten aufbaut.
Wichtig ist, dass die heutigen MPT-7B-Modelle nur der Anfang sind! Um unseren Kunden zu helfen, anspruchsvollere Aufgaben zu bewältigen und ihre Produkte kontinuierlich zu verbessern, wird MosaicML weiterhin Foundation-Modelle von immer höherer Qualität produzieren. Spannende Folge-Modelle werden bereits trainiert. Erwarten Sie bald mehr darüber zu hören!
Danksagungen
Wir sind unseren Freunden bei AI2 dankbar, dass sie uns bei der Kuratierung unseres Vortrainingsdatensatzes geholfen haben, einen großartigen Tokenizer ausgewählt haben und für viele weitere hilfreiche Gespräche unterwegs ⚔️
Anhang
Daten
mC4
Multilingual C4 (mC4) 3.1.0 ist ein Update des ursprünglichen mC4 von Chung et al., das Quellen bis August 2022 enthält. Wir haben die englische Teilmenge ausgewählt und dann die folgenden Filterkriterien auf jedes Dokument angewendet:
- Das häufigste Zeichen muss alphabetisch sein.
- ≥ 92% der Zeichen müssen alphanumerisch sein.
- Wenn das Dokument > 500 Wörter hat, darf das häufigste Wort nicht > 7,5% der Gesamtwortzahl ausmachen; Wenn das Dokument ≤ 500 Wörter hat, darf das häufigste Wort nicht > 30% der Gesamtwortzahl ausmachen.
- Das Dokument muss ≥ 200 Wörter und ≤ 50000 Wörter umfassen.
Die ersten drei Filterkriterien wurden zur Verbesserung der Stichprobenqualität verwendet, und das letzte Filterkriterium (Dokumente müssen ≥200 Wörter und ≤50000 Wörter umfassen) wurde zur Erhöhung der mittleren Sequenzlänge der Vortrainingsdaten verwendet.
mC4 wurde als Teil der fortlaufenden Bemühungen von Dodge et al. veröffentlicht.
C4
Colossal Cleaned Common Crawl (C4) ist ein englischer Common Crawl-Korpus, der von Raffel et al. eingeführt wurde. Wir haben Abbas et al.'s Semantic Deduplication angewendet, um die 20% ähnlichsten Dokumente innerhalb von C4 zu entfernen, da interne Experimente gezeigt haben, dass dies eine Pareto-Verbesserung für auf C4 trainierte Modelle ist.
RedPajama
Wir haben eine Reihe von Teilmengen des RedPajama-Datensatzes aufgenommen, der Together's Versuch ist, die Trainingsdaten von LLaMA zu replizieren. Insbesondere haben wir die Teilmengen CommonCrawl, arXiv, Wikipedia, Books und StackExchange verwendet.
The Stack
Wir wollten, dass unser Modell in der Lage ist, Code zu generieren, also wandten wir uns an The Stack, einen 6,4 TB großen Korpus von Codedaten. Wir haben The Stack Dedup verwendet, eine Variante des Stacks, die ungefähr dedupliziert wurde (via MinHashLSH) auf 2,9 TB. Wir haben eine Teilmenge von 18 der 358 Programmiersprachen von The Stack ausgewählt, um die Datensatzgröße zu reduzieren und die Relevanz zu erhöhen:
- C
- C-Sharp
- C++
- Common Lisp
- F-Sharp
- Fortran
- Go
- Haskell
- Java
- Ocaml
- Perl
- Python
- Ruby
- Rust
- Scala
- Scheme
- Shell
- Tex
Wir haben uns entschieden, dass Code 10% der Vortrainings-Tokens ausmacht, da interne Experimente gezeigt haben, dass wir bis zu 20% Code (und 80% natürliche Sprache) ohne negative Auswirkungen auf die Evaluierung natürlicher Sprache trainieren können.
Wir haben auch die Markdown-Komponente von The Stack Dedup extrahiert und diese als unabhängige Vortrainings-Datensatz-Teilmenge behandelt (d.h. nicht zu den 10% Code-Tokens gezählt). Unsere Motivation dafür ist, dass Markup-Sprachdokumente überwiegend natürliche Sprache sind und daher zu unserem Budget für natürliche Sprach-Tokens zählen sollten.
Semantic Scholar ORC
Der Semantic Scholar Open Research Corpus (S2ORC) ist ein Korpus von akademischen Arbeiten in englischer Sprache, den wir als hochwertige Datenquelle betrachten. Die folgenden Qualitätsfilterkriterien wurden angewendet:
- Die Arbeit ist Open Access.
- Die Arbeit hat einen Titel und eine Zusammenfassung.
- Die Arbeit ist in englischer Sprache (bewertet mit cld3).
- Die Arbeit hat mindestens 500 Wörter und 5 Absätze.
- Die Arbeit wurde nach 1970 und vor dem 01.12.2022 veröffentlicht.
- Das häufigste Wort in der Arbeit besteht nur aus Alpha-Zeichen und kommt in weniger als 7,5% des Dokuments vor.
Dies ergab 9,9 Mio. Artikel. Anleitungen zum Abrufen der neuesten Version des Datensatzes finden Sie hier, und die Originalveröffentlichung finden Sie hier. Die gefilterte Version des Datensatzes wurde uns freundlicherweise von AI2 zur Verfügung gestellt.
Evaluierungsaufgaben
Lambada: 5153 Textbeispiele aus dem Buchkorpus. Besteht aus einem Absatz von mehreren hundert Wörtern, in dem das Modell das nächste Wort vorhersagen soll.
PIQA: 1838 Beispiele von physikalisch intuitiven binären Multiple-Choice-Fragen, z. B. „Frage: Wie kann ich Kleidung an Kleiderbügeln leicht transportieren, wenn ich umziehe?“, „Antwort: „Nimm ein paar leere, strapazierfähige Kleiderbügel, hänge mehrere Kleidungsstücke an diese Bügel und trage sie alle auf einmal.“
COPA: 100 Sätze der Form XYZ deshalb/weil TUV. Als binäre Multiple-Choice-Fragen formuliert, bei denen das Modell die Wahl zwischen zwei möglichen Arten hat, dem deshalb/weil zu folgen. z. B. {"query": "Die Frau war schlecht gelaunt, deshalb", "gold": 1, "choices": ["führte sie ein kleines Gespräch mit ihrer Freundin.", "sagte sie ihrer Freundin, sie solle sie in Ruhe lassen."]}
BoolQ: 3270 Ja/Nein-Fragen, die auf einem Text basieren, der relevante Informationen enthält. Die Fragenthemen reichen von Popkultur bis Wissenschaft, Recht, Geschichte usw. z. B. {"query": "Passage: Kermit der Frosch ist eine Muppet-Figur und die bekannteste Schöpfung von Jim Henson. Kermit wurde 1955 eingeführt und ist die geradlinige Hauptfigur zahlreicher Muppet-Produktionen, insbesondere der Sesamstraße und der Muppet Show, sowie in anderen Fernsehserien, Filmen, Specials und öffentlichen Dienstankündigungen im Laufe der Jahre. Henson führte Kermit ursprünglich bis zu seinem Tod im Jahr 1990 auf; Steve Whitmire spielte Kermit von da an bis zu seiner Entlassung aus der Rolle im Jahr 2016. Kermit wird derzeit von Matt Vogel gespielt. Er wurde auch von Frank Welker in Muppet Babies und gelegentlich in anderen Animationsprojekten synchronisiert und wird von Matt Danner im Reboot von Muppet Babies aus dem Jahr 2018 synchronisiert.\nFrage: War Kermit der Frosch in der Sesamstraße?\n", "choices": ["nein", "ja"], "gold": 1}
Arc-Challenge: 1172 herausfordernde Multiple-Choice-Fragen mit vier Antwortmöglichkeiten zu wissenschaftlichen Themen
Arc-Easy: 2376 einfache Multiple-Choice-Fragen mit vier Antwortmöglichkeiten zu wissenschaftlichen Themen
HellaSwag: 10042 Multiple-Choice-Fragen mit vier Antwortmöglichkeiten, bei denen ein reales Szenario dargestellt wird und das Modell die wahrscheinlichste Schlussfolgerung für das Szenario wählen muss.
Jeopardy: 2117 Jeopardy-Fragen aus fünf Kategorien: Wissenschaft, Weltgeschichte, US-Geschichte, Wortursprünge und Literatur. Das Modell muss die exakte richtige Antwort geben
MMLU: 14.042 Multiple-Choice-Fragen aus 57 verschiedenen akademischen Kategorien
TriviaQA: 11313 Freitext-Triviafragen aus der Popkultur
Winograd: 273 Schemata-Fragen, bei denen das Modell entscheiden muss, auf welchen Bezugsstoff sich ein Pronomen am wahrscheinlichsten bezieht.
Winogrande: 1.267 Schemata-Fragen, bei denen das Modell entscheiden muss, welcher der beiden Sätze mit mehrdeutiger Satzstruktur logisch wahrscheinlicher ist (beide Versionen des Satzes sind syntaktisch korrekt)
MPT Hugging Face Spaces Datenschutzrichtlinie
Bitte beachten Sie unsere MPT Hugging Face Spaces Datenschutzrichtlinie.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.