Ein umfassender Blick auf Daten und Zeitstempel in Apache Spark™ 3.0
von Maxim Gekk, Wenchen Fan und Hyukjin Kwon
Apache Spark ist ein sehr beliebtes Werkzeug zur Verarbeitung von strukturierten und unstrukturierten Daten. Wenn es um die Verarbeitung von strukturierten Daten geht, unterstützt es viele grundlegende Datentypen wie Integer, Long, Double, String usw. Spark unterstützt auch komplexere Datentypen wie Date und Timestamp, die für Entwickler oft schwer zu verstehen sind. In diesem Blogbeitrag tauchen wir tief in die Datums- und Zeitstempeltypen ein, um Ihnen zu helfen, deren Verhalten vollständig zu verstehen und häufige Probleme zu vermeiden. Zusammenfassend behandelt dieser Blog vier Teile:
- Die Definition des Date-Typs und des zugehörigen Kalenders. Es wird auch auf den Kalenderwechsel in Spark 3.0 eingegangen.
- Die Definition des Timestamp-Typs und seine Beziehung zu Zeitzonen. Es wird auch das Detail der Zeitzonen-Offset-Auflösung erklärt und die subtilen Verhaltensänderungen in der neuen Zeit-API in Java 8, die von Spark 3.0 verwendet wird.
- Die gängigen APIs zum Erstellen von Datums- und Zeitstempelwerten in Spark.
- Die häufigsten Fallstricke und Best Practices zum Sammeln von Datums- und Zeitstempelobjekten auf dem Spark-Treiber.
Datum und Kalender
Die Definition eines Date ist sehr einfach: Es ist eine Kombination aus den Feldern Jahr, Monat und Tag, wie (Jahr=2012, Monat=12, Tag=31). Die Werte für Jahr, Monat und Tag unterliegen jedoch Einschränkungen, sodass der Datumswert ein gültiger Tag in der realen Welt ist. Zum Beispiel muss der Wert des Monats von 1 bis 12 reichen, der Wert des Tages muss von 1 bis 28/29/30/31 reichen (abhängig vom Jahr und Monat) und so weiter.
Diese Einschränkungen werden durch einen von vielen möglichen Kalendern definiert. Einige davon werden nur in bestimmten Regionen verwendet, wie der Mondkalender. Einige davon werden nur in der Geschichte verwendet, wie der Julianische Kalender. Der Gregorianische Kalender ist derzeit der De-facto-Internationale Standard und wird für zivile Zwecke fast überall auf der Welt verwendet. Er wurde 1582 eingeführt und wurde erweitert, um auch Daten vor 1582 zu unterstützen. Dieser erweiterte Kalender wird als Proleptischer Gregorianischer Kalender bezeichnet.
Ab Version 3.0 verwendet Spark den Proleptischen Gregorianischen Kalender, der bereits von anderen Datensystemen wie pandas, R und Apache Arrow verwendet wird. Vor Spark 3.0 wurde eine Kombination aus Julianischem und Gregorianischem Kalender verwendet: Für Daten vor 1582 wurde der Julianische Kalender verwendet, für Daten nach 1582 der Gregorianische Kalender. Dies wurde von der älteren java.sql.Date API übernommen, die in Java 8 durch java.time.LocalDate abgelöst wurde, welche ebenfalls den Proleptischen Gregorianischen Kalender verwendet.
Bemerkenswerterweise berücksichtigt der Date-Typ keine Zeitzonen.
Zeitstempel und Zeitzone
Der Timestamp-Typ erweitert den Date-Typ um neue Felder: Stunde, Minute, Sekunde (mit Bruchteilen) und zusammen mit einer globalen (sitzungsbezogenen) Zeitzone. Er definiert einen konkreten Zeitpunkt auf der Erde. Zum Beispiel (Jahr=2012, Monat=12, Tag=31, Stunde=23, Minute=59, Sekunde=59.123456) mit der Sitzungszeitzone UTC+01:00. Beim Schreiben von Zeitstempelwerten in nicht-textuelle Datenquellen wie Parquet sind die Werte nur Zeitpunkte (wie Zeitstempel in UTC), die keine Zeitzoneninformationen enthalten. Wenn Sie einen Zeitstempelwert mit unterschiedlichen Sitzungszeitzonen schreiben und lesen, sehen Sie möglicherweise unterschiedliche Werte für die Stunden/Minuten/Sekunden-Felder, aber es handelt sich tatsächlich um denselben konkreten Zeitpunkt.
Die Felder Stunde, Minute und Sekunde haben Standardbereiche: 0–23 für Stunden und 0–59 für Minuten und Sekunden. Spark unterstützt Bruchteile von Sekunden mit bis zu Mikrosekundenpräzision. Der gültige Bereich für Bruchteile liegt zwischen 0 und 999.999 Mikrosekunden.
Zu jedem konkreten Zeitpunkt können wir je nach Zeitzone viele verschiedene Werte von Wanduhren beobachten.
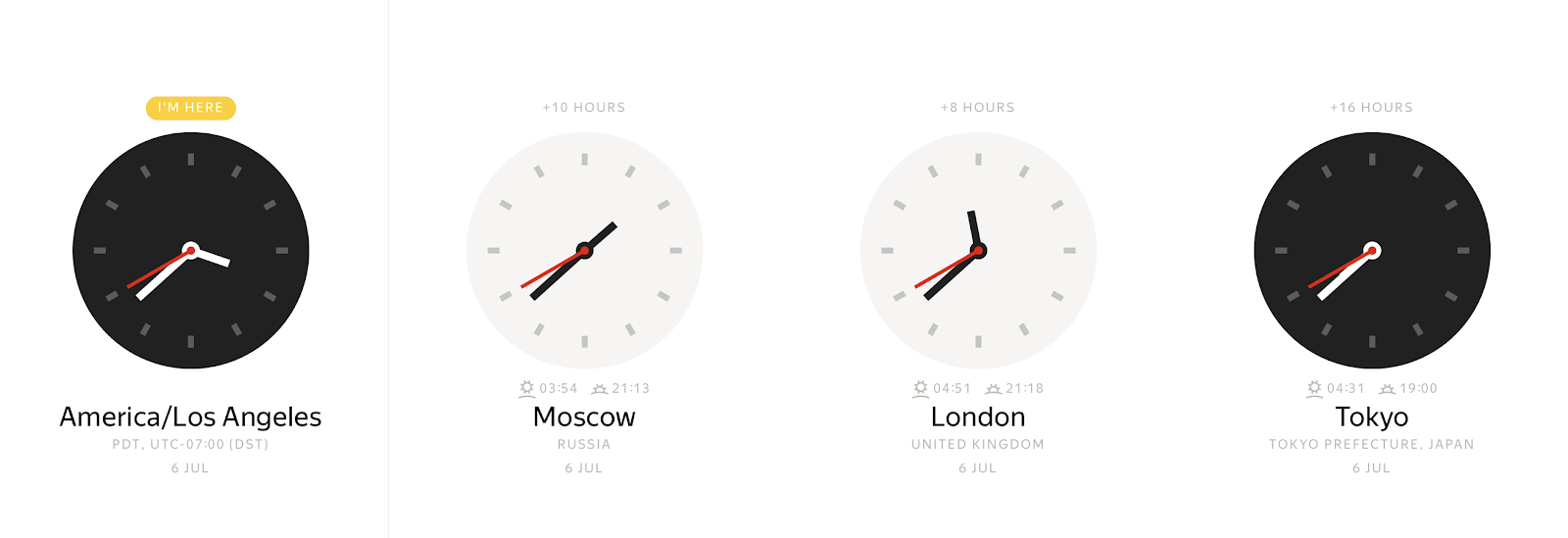
Umgekehrt kann jeder Wert auf Wanduhren viele verschiedene Zeitpunkte darstellen. Der Zeitzonen-Offset ermöglicht es uns, einen lokalen Zeitstempel eindeutig an einen Zeitpunkt zu binden. Normalerweise werden Zeitzonen-Offsets als Stundenversätze gegenüber Greenwich Mean Time (GMT) oder UTC+0 (Koordinierte Weltzeit) definiert. Eine solche Darstellung von Zeitzoneninformationen beseitigt Mehrdeutigkeiten, ist aber für Endbenutzer umständlich. Benutzer bevorzugen es, einen Ort auf der Welt anzugeben, wie z. B. America/Los_Angeles oder Europe/Paris.
Diese zusätzliche Abstraktionsebene von Zonen-Offsets erleichtert das Leben, bringt aber eigene Probleme mit sich. Zum Beispiel müssen wir eine spezielle Zeitzonen-Datenbank pflegen, um Zeitzonennamen auf Offsets abzubilden. Da Spark auf der JVM läuft, delegiert es die Zuordnung an die Java-Standardbibliothek, die Daten aus der Internet Assigned Numbers Authority Time Zone Database (IANA TZDB) lädt. Darüber hinaus haben die Zuordnungsmechanismen in der Java-Standardbibliothek einige Nuancen, die das Verhalten von Spark beeinflussen. Wir konzentrieren uns im Folgenden auf einige dieser Nuancen.
Seit Java 8 bietet die JDK eine neue API für die Datums-/Zeitmanipulation und die Auflösung von Zeitzonen-Offsets, und Spark hat in Version 3.0 auf diese neue API umgestellt. Obwohl die Zuordnung von Zeitzonennamen zu Offsets dieselbe Quelle hat, IANA TZDB, ist sie in Java 8 und höher anders implementiert als in Java 7.
Als Beispiel betrachten wir einen Zeitstempel vor dem Jahr 1883 in der Zeitzone 
America/Los_Angeles: 1883-11-10 00:00:00. Dieses Jahr sticht aus anderen hervor, da am 18. November 1883 alle nordamerikanischen Eisenbahnen auf ein neues Standardzeitsystem umgestellt haben, das fortan ihre Fahrpläne bestimmte.
Mit der Java 7 Zeit-API können wir den Zeitzonen-Offset zum lokalen Zeitstempel als -08:00 erhalten:
Java 8 API-Funktionen liefern ein anderes Ergebnis:
Vor dem 18. November 1883 war die Tageszeit eine lokale Angelegenheit, und die meisten Städte und Gemeinden nutzten eine Form der lokalen Sonnenzeit, die von einer bekannten Uhr (z. B. auf einem Kirchturm oder im Schaufenster eines Juweliers) angezeigt wurde. Deshalb sehen wir einen so seltsamen Zeitzonen-Offset.
Das Beispiel zeigt, dass die Java 8-Funktionen präziser sind und historische Daten von IANA TZDB berücksichtigen. Nach der Umstellung auf die Java 8 Zeit-API profitierte Spark 3.0 automatisch von der Verbesserung und wurde präziser bei der Auflösung von Zeitzonen-Offsets.
Wie bereits erwähnt, hat Spark 3.0 auch auf den Proleptischen Gregorianischen Kalender für den Date-Typ umgestellt. Dasselbe gilt für den Timestamp-Typ. Der ISO SQL:2016-Standard erklärt den gültigen Bereich für Zeitstempel von 0001-01-01 00:00:00 bis 9999-12-31 23:59:59.999999. Spark 3.0 entspricht vollständig dem Standard und unterstützt alle Zeitstempel in diesem Bereich. Im Vergleich zu Spark 2.4 und früher sollten wir die folgenden Teilbereiche hervorheben:
0001-01-01 00:00:00..1582-10-03 23:59:59.999999. Spark 2.4 verwendet den Julianischen Kalender und entspricht nicht dem Standard. Spark 3.0 behebt das Problem und wendet den Proleptischen Gregorianischen Kalender in internen Operationen mit Zeitstempeln an, wie z. B. dem Abrufen von Jahr, Monat, Tag usw. Aufgrund unterschiedlicher Kalender existieren einige Daten in Spark 2.4 nicht in Spark 3.0. Zum Beispiel ist der 1000-02-29 kein gültiges Datum, da 1000 kein Schaltjahr im Gregorianischen Kalender ist. Außerdem löst Spark 2.4 für diesen Zeitstempelbereich Zeitzonen-Namen falsch in Zonen-Offsets auf.1582-10-04 00:00:00..1582-10-14 23:59:59.999999. Dies ist ein gültiger Bereich von lokalen Zeitstempeln in Spark 3.0, im Gegensatz zu Spark 2.4, wo solche Zeitstempel nicht existierten.1582-10-15 00:00:00..1899-12-31 23:59:59.999999. Spark 3.0 löst Zeitzonen-Offsets mithilfe historischer Daten von IANA TZDB korrekt auf. Im Vergleich zu Spark 3.0 kann Spark 2.4 Zonen-Offsets von Zeitzonen-Namen in einigen Fällen falsch auflösen, wie wir oben im Beispiel gezeigt haben.1900-01-01 00:00:00..2036-12-31 23:59:59.999999. Sowohl Spark 3.0 als auch Spark 2.4 entsprechen dem ANSI SQL-Standard und verwenden den gregorianischen Kalender für Datums- und Zeitoperationen wie die Ermittlung des Tages des Monats.2037-01-01 00:00:00..9999-12-31 23:59:59.999999. Spark 2.4 kann Zeitzonen-Offsets und insbesondere Sommerzeit-Offsets aufgrund eines JDK-Fehlers (#8073446) falsch auflösen. Spark 3.0 ist von diesem Defekt nicht betroffen.
Ein weiterer Aspekt der Zuordnung von Zeitzonennamen zu Offsets ist die Überlappung lokaler Zeitstempel, die aufgrund der Sommerzeit (DST) oder des Wechsels zu einer anderen Standard-Zeitzone auftreten kann. Zum Beispiel wurden am 3. November 2019, 02:00:00 die Uhren um 1 Stunde zurück auf 01:00:00 gestellt. Der lokale Zeitstempel 
2019-11-03 01:30:00 America/Los_Angeles kann entweder zu 2019-11-03 01:30:00 UTC-08:00 oder 2019-11-03 01:30:00 UTC-07:00 zugeordnet werden. Wenn Sie den Offset nicht angeben und nur den Zeitzonennamen verwenden (z. B. '2019-11-03 01:30:00 America/Los_Angeles'), verwendet Spark 3.0 den früheren Offset, der typischerweise der "Sommerzeit" entspricht. Das Verhalten weicht von Spark 2.4 ab, das den "Winter"-Offset verwendet. Im Falle einer Lücke, in der die Uhren vorwärts springen, gibt es keinen gültigen Offset. Bei einer typischen einstündigen Sommerzeitumstellung verschiebt Spark solche Zeitstempel auf den nächsten gültigen Zeitstempel, der der "Sommerzeit" entspricht.
Wie wir aus den obigen Beispielen sehen können, ist die Zuordnung von Zeitzonennamen zu Offsets mehrdeutig und keine Eins-zu-Eins-Beziehung. Wenn möglich, empfehlen wir, beim Erstellen von Zeitstempeln genaue Zeitzonen-Offsets anzugeben, z. B. timestamp '2019-11-03 01:30:00 UTC-07:00'.
Lassen Sie uns von der Zuordnung von Zeitzonennamen zu Offsets weggehen und uns dem ANSI SQL-Standard zuwenden. Er definiert zwei Arten von Zeitstempeln:
TIMESTAMP WITHOUT TIME ZONEoderTIMESTAMP– Lokaler Zeitstempel als (JAHR, MONAT, TAG, STUNDE, MINUTE, SEKUNDE). Diese Arten von Zeitstempeln sind an keine Zeitzone gebunden und sind tatsächlich Wanduhren-Zeitstempel.TIMESTAMP WITH TIME ZONE– Zeitzonen-Zeitstempel als (JAHR, MONAT, TAG, STUNDE, MINUTE, SEKUNDE, ZEITZONEN_STUNDE, ZEITZONEN_MINUTE). Die Zeitstempel stellen einen Zeitpunkt in der UTC-Zeitzone plus einen Zeitzonen-Offset (in Stunden und Minuten) dar, der jedem Wert zugeordnet ist.
Der Zeitzonen-Offset eines TIMESTAMP WITH TIME ZONE beeinflusst nicht den physischen Zeitpunkt, den der Zeitstempel darstellt, da dieser vollständig durch den UTC-Zeitpunkt, der durch die anderen Zeitstempelkomponenten gegeben ist, repräsentiert wird. Stattdessen beeinflusst der Zeitzonen-Offset nur das Standardverhalten eines Zeitstempelwerts für die Anzeige, die Extraktion von Datums-/Zeitkomponenten (z. B. EXTRACT) und andere Operationen, die die Kenntnis einer Zeitzone erfordern, wie z. B. das Hinzufügen von Monaten zu einem Zeitstempel.
Spark SQL definiert den Zeitstempeltyp als TIMESTAMP WITH SESSION TIME ZONE, was eine Kombination aus den Feldern (JAHR, MONAT, TAG, STUNDE, MINUTE, SEKUNDE, SESSION TZ) ist, wobei die Felder JAHR bis SEKUNDE einen Zeitpunkt in der UTC-Zeitzone identifizieren und wobei SESSION TZ aus der SQL-Konfiguration spark.sql.session.timeZone übernommen wird. Die Sitzungszeitzone kann wie folgt festgelegt werden:
- Offset-Zeitzone
'(+|-)HH:mm'. Dieses Format ermöglicht es uns, einen physischen Zeitpunkt eindeutig zu definieren. - Zeitzonenname in Form einer Region-ID
'area/city', wie z. B.'America/Los_Angeles'. Diese Form der Zeitzoneninformation leidet unter einigen der Probleme, die wir oben beschrieben haben, wie z. B. Überlappungen lokaler Zeitstempel. Jede UTC-Zeitpunkt ist jedoch eindeutig mit einem Zeitzonen-Offset für jede Region-ID verbunden, und infolgedessen kann jeder Zeitstempel mit einer Region-ID-basierten Zeitzone eindeutig in einen Zeitstempel mit einem Zonen-Offset konvertiert werden.
Standardmäßig ist die Sitzungszeitzone auf die Standardzeitzone der Java Virtual Machine eingestellt.
Spark's TIMESTAMP WITH SESSION TIME ZONE unterscheidet sich von:
TIMESTAMP WITHOUT TIME ZONE, da ein Wert dieses Typs mehreren physischen Zeitpunkten zugeordnet werden kann, aber jeder Wert vonTIMESTAMP WITH SESSION TIME ZONEein konkreter physischer Zeitpunkt ist. Der SQL-Typ kann durch die Verwendung eines festen Zeitzonen-Offsets über alle Sitzungen hinweg emuliert werden, z. B. UTC+0. In diesem Fall könnten wir Zeitstempel in UTC als lokale Zeitstempel betrachten.TIMESTAMP WITH TIME ZONE, da gemäß dem SQL-Standard Spaltenwerte dieses Typs unterschiedliche Zeitzonen-Offsets haben können. Dies wird von Spark SQL nicht unterstützt.
Wir sollten beachten, dass Zeitstempel, die mit einer globalen (sitzungsbezogenen) Zeitzone verknüpft sind, nichts Neues sind, das von Spark SQL erfunden wurde. RDBMS wie Oracle bieten ebenfalls einen ähnlichen Typ für Zeitstempel: TIMESTAMP WITH LOCAL TIME ZONE.
Erstellen von Datums- und Zeitstempeln
Spark SQL bietet einige Methoden zum Erstellen von Datums- und Zeitstempelwerten:
- Standardkonstruktoren ohne Parameter:
CURRENT_TIMESTAMP()undCURRENT_DATE(). - Aus anderen primitiven Spark SQL-Typen wie
INT,LONGundSTRING. - Aus externen Typen wie Python
datetimeoder Java-Klassenjava.time.LocalDate/Instant. - Deserialisierung aus Datenquellen CSV, JSON, Avro, Parquet, ORC oder anderen.
Die Funktion MAKE_DATE, die in Spark 3.0 eingeführt wurde, nimmt drei Parameter entgegen: JAHR, MONAT des Jahres und TAG des Monats und erstellt einen DATE-Wert. Alle Eingabeparameter werden implizit in den Typ INT konvertiert, wenn möglich. Die Funktion prüft, ob die resultierenden Daten gültige Daten im Proleptischen Gregorianischen Kalender sind, andernfalls gibt sie NULL zurück. Zum Beispiel in PySpark:
Um den DataFrame-Inhalt anzuzeigen, rufen wir die Aktion show() auf, die Daten in Strings auf den Executoren konvertiert und die Strings an den Treiber überträgt, um sie auf der Konsole auszugeben:
Ähnlich können wir Zeitstempelwerte über die Funktionen MAKE_TIMESTAMP erstellen. Wie MAKE_DATE führt sie die gleiche Validierung für Datumsfelder durch und akzeptiert zusätzlich Zeitfelder STUNDE (0-23), MINUTE (0-59) und SEKUNDE (0-60). SEKUNDE hat den Typ Decimal(Präzision = 8, Skala = 6), da Sekunden mit dem Bruchteil bis zur Mikrosekundenpräzision übergeben werden können. Zum Beispiel in PySpark:
Wie wir es für Daten getan haben, lassen Sie uns den Inhalt des ts DataFrames mit der Aktion show() anzeigen. Auf ähnliche Weise konvertiert show() Zeitstempel in Strings, berücksichtigt aber nun die durch die SQL-Konfiguration spark.sql.session.timeZone definierte Sitzungszeitzone. Dies werden wir in den folgenden Beispielen sehen.
Spark kann den letzten Zeitstempel nicht erstellen, da dieses Datum ungültig ist: 2019 ist kein Schaltjahr.
Sie bemerken vielleicht, dass wir im obigen Beispiel keine Zeitzoneninformationen angegeben haben. In diesem Fall übernimmt Spark eine Zeitzone aus der SQL-Konfiguration spark.sql.session.timeZone und wendet sie auf Funktionsaufrufe an. Sie können auch eine andere Zeitzone auswählen, indem Sie sie als letzten Parameter von MAKE_TIMESTAMP übergeben. Hier ist ein Beispiel in PySpark:
Wie das Beispiel zeigt, berücksichtigt Spark die angegebenen Zeitzonen, passt aber alle lokalen Zeitstempel an die Sitzungszeitzone an. Die ursprünglichen Zeitzonen, die an die MAKE_TIMESTAMP-Funktion übergeben werden, gehen verloren, da der Typ TIMESTAMP WITH SESSION TIME ZONE davon ausgeht, dass alle Werte zu einer Zeitzone gehören, und er speichert nicht einmal eine Zeitzone pro Wert. Gemäß der Definition von TIMESTAMP WITH SESSION TIME ZONE speichert Spark lokale Zeitstempel in der UTC-Zeitzone und verwendet die Sitzungszeitzone beim Extrahieren von Datums-/Zeitfeldern oder beim Konvertieren von Zeitstempeln in Zeichenfolgen.
Zeitstempel können auch durch Typumwandlung aus dem LONG-Typ erstellt werden. Wenn eine LONG-Spalte die Anzahl der Sekunden seit der Epoche 1970-01-01 00:00:00Z enthält, kann sie in Spark SQLs TIMESTAMP umgewandelt werden:
Leider erlaubt dieser Ansatz nicht die Angabe des Bruchteils von Sekunden. In Zukunft wird Spark SQL spezielle Funktionen bereitstellen, um Zeitstempel aus Sekunden, Millisekunden und Mikrosekunden seit der Epoche zu erstellen: timestamp_seconds(), timestamp_millis() und timestamp_micros().
Eine andere Möglichkeit ist, Daten und Zeitstempel aus Werten vom Typ STRING zu erstellen. Wir können Literale mit speziellen Schlüsselwörtern erstellen:
oder durch Typumwandlung, die wir auf alle Werte in einer Spalte anwenden können:
Die eingegebenen Zeitstempel-Zeichenfolgen werden als lokale Zeitstempel in der angegebenen Zeitzone oder in der Sitzungszeitzone interpretiert, wenn in der Eingabezeichenfolge keine Zeitzone angegeben ist. Zeichenfolgen mit ungewöhnlichen Mustern können mit der Funktion to_timestamp() in Zeitstempel umgewandelt werden. Die unterstützten Muster sind in Datetime Patterns for Formatting and Parsing beschrieben:
Die Funktion verhält sich ähnlich wie CAST, wenn kein Muster angegeben wird.
Zur besseren Handhabung erkennt Spark SQL spezielle Zeichenfolgenwerte in allen oben genannten Methoden, die eine Zeichenfolge akzeptieren und einen Zeitstempel und ein Datum zurückgeben:
- epoch ist ein Alias für date '1970-01-01' oder timestamp
'1970-01-01 00:00:00Z' - now ist der aktuelle Zeitstempel oder das aktuelle Datum in der Sitzungszeitzone. Innerhalb einer einzelnen Abfrage liefert es immer dasselbe Ergebnis.
- today ist der Beginn des aktuellen Tages für den Typ
TIMESTAMPoder einfach das aktuelle Datum für den TypDATE. - tomorrow ist der Beginn des nächsten Tages für Zeitstempel oder einfach der nächste Tag für den Typ
DATE. - yesterday ist der Tag vor dem aktuellen oder dessen Beginn für den Typ
TIMESTAMP.
Zum Beispiel:
Eine der großartigen Funktionen von Spark ist das Erstellen von Datasets aus vorhandenen Sammlungen externer Objekte auf der Treiberseite und das Erstellen von Spalten entsprechender Typen. Spark konvertiert Instanzen externer Typen in semantisch äquivalente interne Darstellungen. PySpark ermöglicht die Erstellung eines Dataset mit DATE- und TIMESTAMP-Spalten aus Python-Sammlungen, zum Beispiel:
PySpark konvertiert Pythons datetime-Objekte auf der Treiberseite mithilfe der Systemzeitzone in interne Spark SQL-Darstellungen, die sich von den Sitzungszeitzoneneinstellungen von Spark spark.sql.session.timeZone unterscheiden kann. Die internen Werte enthalten keine Informationen über die ursprüngliche Zeitzone. Zukünftige Operationen mit den parallelisierten Datums- und Zeitstempelwerten berücksichtigen nur die Spark SQL-Sitzungszeitzone gemäß der Definition des Typs TIMESTAMP WITH SESSION TIME ZONE.
Auf ähnliche Weise, wie wir oben für Python-Sammlungen gezeigt haben, erkennt Spark die folgenden Typen als externe Datums-/Zeit-Typen in Java/Scala-APIs:
- java.sql.Date und java.time.LocalDate als externe Typen für den DATE-Typ von Spark SQL
- java.sql.Timestamp und java.time.Instant für den TIMESTAMP-Typ.
Es gibt einen Unterschied zwischen java.sql.* und java.time.*-Typen. java.time.LocalDate und java.time.Instant wurden in Java 8 hinzugefügt, und die Typen basieren auf dem Proleptischen Gregorianischen Kalender – demselben Kalender, der von Spark ab Version 3.0 verwendet wird. java.sql.Date und java.sql.Timestamp haben darunter einen anderen Kalender – den hybriden Kalender (Julian + Gregorian seit 1582-10-15), der derselbe ist wie der Legacy-Kalender, der von Spark-Versionen vor 3.0 verwendet wurde. Aufgrund unterschiedlicher Kalendersysteme muss Spark zusätzliche Operationen bei der Konvertierung in interne Spark SQL-Darstellungen durchführen und Eingabedaten/Zeitstempel von einem Kalender in einen anderen umwandeln. Die Umwandlungsoperation hat einen geringen Overhead für moderne Zeitstempel nach dem Jahr 1900, und sie kann für alte Zeitstempel erheblicher sein.
Das folgende Beispiel zeigt die Erstellung von Zeitstempeln aus Scala-Sammlungen. Im ersten Beispiel erstellen wir ein java.sql.Timestamp-Objekt aus einer Zeichenfolge. Die Methode valueOf interpretiert die Eingabezeichenfolgen als lokalen Zeitstempel in der Standard-JVM-Zeitzone, die sich von der Spark-Sitzungszeitzone unterscheiden kann. Wenn Sie Instanzen von java.sql.Timestamp oder java.sql.Date in einer bestimmten Zeitzone erstellen müssen, empfehlen wir, sich java.text.SimpleDateFormat (und seine Methode setTimeZone) oder java.util.Calendar anzusehen.
Ähnlich können wir eine DATE-Spalte aus Sammlungen von java.sql.Date oder java.LocalDate erstellen. Die Parallelisierung von java.LocalDate-Instanzen ist vollständig unabhängig von der Spark-Sitzungszeitzone oder der Standard-JVM-Zeitzone. Dies gilt jedoch nicht für die Parallelisierung von java.sql.Date-Instanzen. Es gibt Nuancen:
java.sql.Date-Instanzen stellen lokale Daten in der Standard-JVM-Zeitzone auf dem Treiber dar- Für korrekte Konvertierungen in Spark SQL-Werte müssen die Standard-JVM-Zeitzone auf dem Treiber und den Exekutoren gleich sein.
Um Probleme mit Kalendern und Zeitzonen zu vermeiden, empfehlen wir Java 8-Typen java.LocalDate/Instant als externe Typen bei der Parallelisierung von Java/Scala-Sammlungen von Zeitstempeln oder Daten.
Sammeln von Daten und Zeitstempeln
Die umgekehrte Operation zur Parallelisierung ist das Sammeln von Daten und Zeitstempeln von den Exekutoren zurück zum Treiber und die Rückgabe einer Sammlung externer Typen. Im obigen Beispiel können wir das DataFrame über die collect()-Aktion zurück zum Treiber ziehen:
Spark überträgt interne Werte von Datums- und Zeitstempelspalten als Zeitpunkte in der UTC-Zeitzone von den Executoren zum Treiber und führt Konvertierungen in Python-datetime-Objekte in der Systemzeitzone auf dem Treiber durch, nicht unter Verwendung der Spark SQL-Sitzungszeitzone. collect() unterscheidet sich von der show()-Aktion, die im vorherigen Abschnitt beschrieben wurde. show() verwendet die Sitzungszeitzone bei der Konvertierung von Zeitstempeln in Zeichenfolgen und sammelt die resultierenden Zeichenfolgen auf dem Treiber.
In Java- und Scala-APIs führt Spark standardmäßig folgende Konvertierungen durch:
- Spark SQL
DATE-Werte werden in Instanzen vonjava.sql.Datekonvertiert. - Zeitstempel werden in Instanzen von
java.sql.Timestampkonvertiert.
Beide Konvertierungen werden in der Standard-JVM-Zeitzone auf dem Treiber durchgeführt. Auf diese Weise sollten die Datums-/Zeitfelder, die wir über Date.getDay(), getHour() usw. und über Spark SQL-Funktionen DAY, HOUR erhalten, mit der Standard-JVM-Zeitzone auf dem Treiber und der Sitzungszeitzone auf den Executoren übereinstimmen.
Ähnlich wie bei der Erstellung von Datums-/Zeitstempeln aus java.sql.Date/Timestamp führt Spark 3.0 eine Neuzuordnung vom Proleptischen Gregorianischen Kalender zum hybriden Kalender (Julianisch + Gregorianisch) durch. Dieser Vorgang ist für moderne Datumsangaben (nach 1582) und Zeitstempel (nach 1900) fast kostenlos, kann aber für alte Datumsangaben und Zeitstempel einen gewissen Mehraufwand bedeuten.
Wir können solche kalenderbezogenen Probleme vermeiden und Spark bitten, java.time-Typen zurückzugeben, die seit Java 8 hinzugefügt wurden. Wenn wir die SQL-Konfiguration spark.sql.datetime.java8API.enabled auf true setzen, gibt die Dataset.collect()-Aktion Folgendes zurück:
java.time.LocalDatefür denDATE-Typ von Spark SQLjava.time.Instantfür denTIMESTAMP-Typ von Spark SQL
Jetzt leiden die Konvertierungen nicht mehr unter kalenderbezogenen Problemen, da Java 8-Typen und Spark SQL 3.0 beide auf dem Proleptischen Gregorianischen Kalender basieren. Die collect()-Aktion hängt nicht mehr von der Standard-JVM-Zeitzone ab. Die Zeitstempelkonvertierungen hängen überhaupt nicht von der Zeitzone ab. Bei der Datumskonvertierung wird die Sitzungszeitzone aus der SQL-Konfiguration spark.sql.session.timeZone verwendet. Betrachten wir zum Beispiel ein Dataset mit DATE- und TIMESTAMP-Spalten, setzen wir die Standard-JVM-Zeitzone auf Europa/Moskau, aber die Sitzungszeitzone auf America/Los_Angeles.
Die show()-Aktion gibt den Zeitstempel in der Sitzungszeit America/Los_Angeles aus, aber wenn wir das Dataset sammeln, wird es in java.sql.Timestamp konvertiert und von der toString-Methode in Europe/Moscow ausgegeben:
Tatsächlich ist der lokale Zeitstempel 2020-07-01 00:00:00 UTC 2020-07-01T07:00:00Z. Das können wir beobachten, wenn wir die Java 8 API aktivieren und das Dataset sammeln:
Das java.time.Instant-Objekt kann später unabhängig von der globalen JVM-Zeitzone in jeden lokalen Zeitstempel konvertiert werden. Dies ist einer der Vorteile von java.time.Instant gegenüber java.sql.Timestamp. Ersteres erfordert die Änderung der globalen JVM-Einstellung, die sich auf andere Zeitstempel in derselben JVM auswirkt. Wenn Ihre Anwendungen also Datums- oder Zeitstempel in verschiedenen Zeitzonen verarbeiten und die Anwendungen sich nicht gegenseitig behindern dürfen, wenn Daten über die Java/Scala Dataset.collect() API an den Treiber gesammelt werden, empfehlen wir den Wechsel zur Java 8 API über die SQL-Konfiguration spark.sql.datetime.java8API.enabled.
Fazit
In diesem Blogbeitrag haben wir die Spark SQL DATE- und TIMESTAMP-Typen beschrieben. Wir haben gezeigt, wie Datums- und Zeitstempelspalten aus anderen primitiven Spark SQL-Typen und externen Java-Typen konstruiert werden und wie Datums- und Zeitstempelspalten als externe Java-Typen zurück an den Treiber gesammelt werden. Seit Version 3.0 hat Spark vom hybriden Kalender, der Julianischen und Gregorianischen Kalender kombiniert, zum Proleptischen Gregorianischen Kalender gewechselt (siehe SPARK-26651 für weitere Details). Dies ermöglichte es Spark, viele Probleme zu beseitigen, wie wir zuvor gezeigt haben. Für die Abwärtskompatibilität mit früheren Versionen gibt Spark Zeitstempel und Daten weiterhin im hybriden Kalender (java.sql.Date und java.sql.Timestamp) von Collect-ähnlichen Aktionen zurück. Um Probleme bei der Auflösung von Kalendern und Zeitzonen bei der Verwendung von Java/Scala's Collect-Aktionen zu vermeiden, kann die Java 8 API über die SQL-Konfiguration spark.sql.datetime.java8API.enabled aktiviert werden. Probieren Sie es noch heute kostenlos auf Databricks als Teil unseres Databricks Runtime 7.0 aus.

O'Reilly Learning Spark Buch
Die kostenlose 2. Ausgabe enthält Updates zu Spark 3.0, einschließlich der neuen Python-Typ-Hints für Pandas UDFs, der neuen Datums-/Zeitimplementierung usw.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.