Teil 1: Implementierung von CI/CD auf Databricks mit Databricks Notebooks und Azure DevOps
von Michael Shtelma und Piotr Majer
Der besprochene Code kann hier gefunden werden.
Dies ist der erste Teil einer zweiteiligen Blog-Post-Reihe, die zeigt, wie Sie End-to-End-MLOps-Lösungen auf Databricks mit Notebooks und der Repos API konfigurieren und erstellen. Dieser Beitrag stellt ein CI/CD-Framework auf Databricks vor, das auf Notebooks basiert. Die Pipeline integriert sich für den Continuous Integration (CI)-Teil in das Microsoft Azure DevOps-Ökosystem und für die Continuous Delivery (CD) in die Repos API. Im zweiten Beitrag zeigen wir, wie Sie die Funktionalität der Repos API nutzen, um einen vollständigen CI/CD-Lebenszyklus auf Databricks zu implementieren und ihn zu einer vollwertigen MLOps-Lösung zu erweitern.
CI/CD mit Databricks Repos
Dank der neuen Funktionalität von Databricks Repos und der Repos API sind wir nun gut gerüstet, um alle wichtigen Aspekte der Versionskontrolle, des Testens und der Pipelines abzudecken, die MLOps-Ansätzen zugrunde liegen. Databricks Repos ermöglicht das Klonen ganzer Git-Repositories in Databricks, und mit Hilfe der Repos API können wir diesen Prozess automatisieren, indem wir zuerst ein Git-Repository klonen und dann den gewünschten Branch auschecken. ML-Praktiker können nun eine Repository-Struktur verwenden, die aus IDEs bekannt ist, um ihr Projekt zu strukturieren, und sich dabei auf Notebooks oder .py-Dateien zur Implementierung von Modulen verlassen (mit Unterstützung für beliebige Dateiformate in Repos, die auf der Roadmap stehen). Daher wird das gesamte Projekt von einem Tool Ihrer Wahl (Github, Gitlab, Azure Repos, um nur einige zu nennen) versioniert und lässt sich sehr gut in gängige CI/CD-Pipelines integrieren. Die Databricks Repos API ermöglicht es uns, ein Repo (als Repo in Databricks ausgechecktes Git-Projekt) auf die neueste Version eines bestimmten Git-Branches zu aktualisieren.
Die Teams können während der Entwicklung dem klassischen Git Flow oder GitHub Flow folgen. Das gesamte Git-Repository kann mit Databricks Repos ausgecheckt werden. Benutzer können Notebooks sowie reine Python-Dateien oder andere Textdateitypen mit beliebiger Dateisupport verwenden und bearbeiten. Dies ermöglicht uns die Verwendung einer klassischen Projektstruktur, den Import von Modulen aus Python-Dateien und deren Kombination mit Notebooks:
- Entwickeln Sie einzelne Features in einem Feature-Branch und testen Sie sie mit Unit-Tests (z. B. implementierte Notebooks).
- Pushen Sie Änderungen in den Feature-Branch, wo die CI/CD-Pipeline den Integrationstest ausführt.
- CI/CD-Pipelines in Azure DevOps können die Databricks Repos API auslösen, um dieses Testprojekt auf die neueste Version zu aktualisieren.
- CI/CD-Pipelines lösen den Integrationstest-Job über die Jobs API aus. Integrationstests können als einfaches Notebook implementiert werden, das zunächst die zu testenden Pipelines mit Testkonfigurationen ausführt. Dies kann durch einfaches Ausführen eines entsprechenden Notebooks mit entsprechenden Modulen oder durch Auslösen des eigentlichen Jobs über die Jobs API erfolgen.
- Untersuchen Sie die Ergebnisse, um den gesamten Testlauf als bestanden oder fehlgeschlagen zu kennzeichnen.
Untersuchen wir nun, wie wir den oben beschriebenen Ansatz implementieren können. Als beispielhaften Workflow konzentrieren wir uns auf Daten aus dem Kaggle Lending Club Wettbewerb. Ähnlich wie viele Finanzinstitute möchten wir individuelle Einkommensdaten verstehen und vorhersagen, z. B. um den Kredit-Score einer Bewerbung zu bewerten. Dazu analysieren wir verschiedene Bewerbermerkmale und -attribute, die von der aktuellen Tätigkeit, dem Wohneigentum, der Ausbildung bis hin zu Standortdaten, Familienstand und Alter reichen. Dies sind Informationen, die eine Bank gesammelt hat (z. B. aus früheren Kreditanträgen) und die nun verwendet werden, um ein Regressionsmodell zu trainieren.
Darüber hinaus wissen wir, dass sich unser Geschäft dynamisch ändert und täglich eine große Menge neuer Beobachtungen hinzukommt. Bei der regelmäßigen Aufnahme neuer Daten ist das Neutrainieren des Modells entscheidend. Daher liegt der Fokus auf der vollständigen Automatisierung der Retraining-Jobs sowie der gesamten Continuous-Deployment-Pipeline. Um qualitativ hochwertige Ergebnisse und die hohe Vorhersagekraft eines neu trainierten Modells zu gewährleisten, fügen wir nach jedem trainierten Job einen Evaluationsschritt hinzu. Hier wird das ML-Modell auf einem kuratierten Datensatz bewertet und mit der aktuell bereitgestellten Produktionsversion verglichen. Daher kann die Modellförderung nur erfolgen, wenn die neue Iteration eine hohe Vorhersagekraft aufweist.
Da ein Projekt aktiv entwickelt und bearbeitet wird, nutzt das vollautomatisierte Testen neuer Codes und die Beförderung zur nächsten Stufe des Lebenszyklus das Azure DevOps Framework für die Unit-/Integrationsbewertung bei Push-/Pull-Anfragen. Die Tests werden über das Azure DevOps Framework orchestriert und auf der Databricks-Plattform ausgeführt. Dies deckt den CI-Teil des Prozesses ab und gewährleistet eine hohe Testabdeckung unseres Codes, wodurch die menschliche Überwachung minimiert wird.
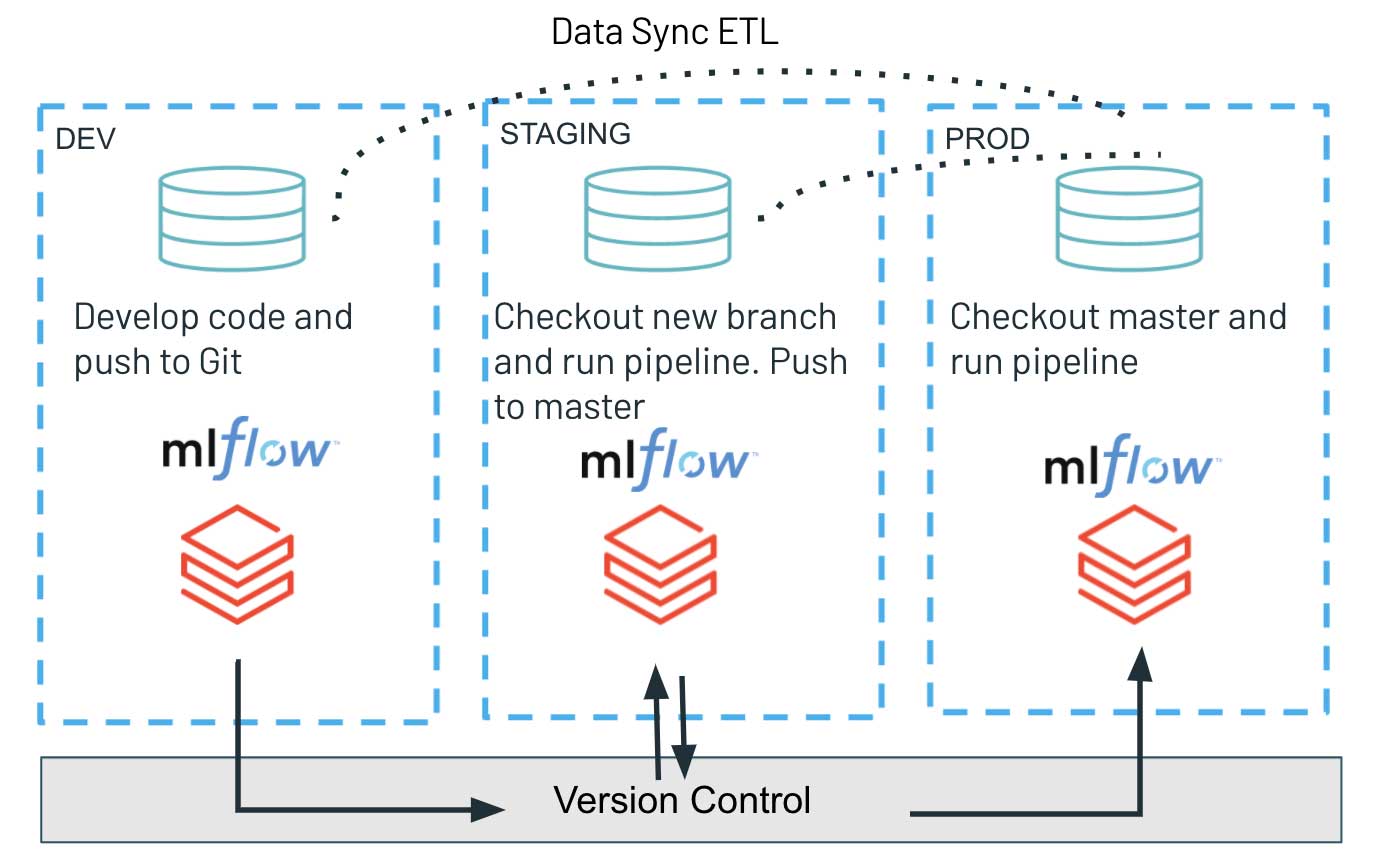
Der Continuous-Delivery-Teil stützt sich ausschließlich auf die Repos API, wo wir die programmatische Schnittstelle nutzen, um die neueste Version unseres Codes im Git-Branch auszuchecken und die neuesten Skripte zur Ausführung der Workloads bereitzustellen. Dies ermöglicht uns, den Artefaktbereitstellungsprozess zu vereinfachen und die getestete Codeversion einfach von der Entwicklung über Staging bis zur Produktionsumgebung zu befördern. Eine solche Architektur garantiert die vollständige Isolation verschiedener Umgebungen und wird typischerweise in Umgebungen mit erhöhter Sicherheit bevorzugt. Die verschiedenen Stufen: Entwicklung, Staging und Produktion teilen sich nur das Versionskontrollsystem, wodurch potenzielle Störungen kritischer Produktions-Workloads minimiert werden. Gleichzeitig sind explorative Arbeiten und Innovationen entkoppelt, da die Entwicklungsumgebung möglicherweise lockerere Zugriffskontrollen hat.
CI/CD-Pipeline mit Azure DevOps und Databricks implementieren
Im folgenden Code-Repository haben wir das ML-Projekt mit einer CI/CD-Pipeline implementiert, die von Azure DevOps angetrieben wird. In diesem Projekt verwenden wir Notebooks für die Datenaufbereitung und das Modelltraining.
Sehen wir uns an, wie wir diese Notebooks auf Databricks testen können. Azure DevOps ist ein sehr beliebtes Framework für vollständige CI/CD-Workflows, die in Azure verfügbar sind. Weitere Informationen finden Sie in der Übersicht über die bereitgestellten Funktionalitäten und Continuous Integrations mit Databricks.
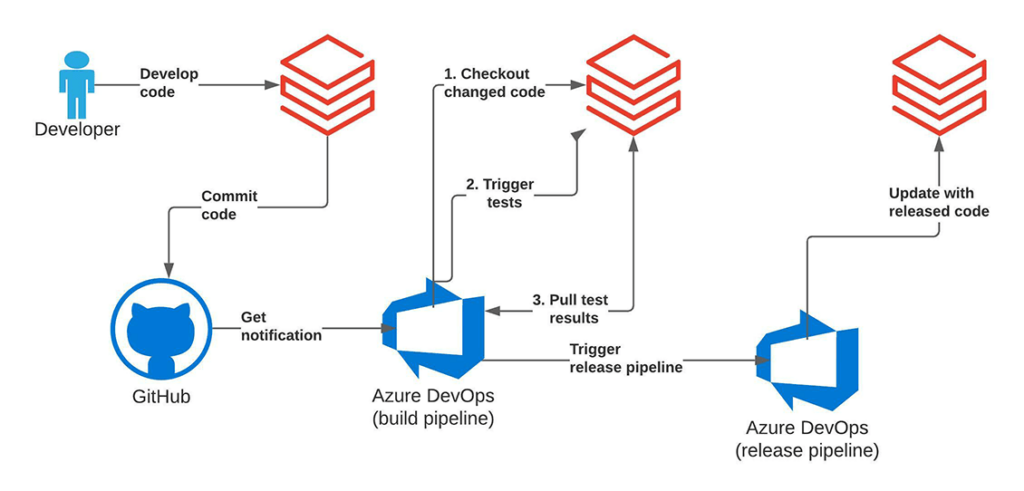
Wir verwenden die Azure DevOps-Pipeline als YAML-Datei. Die Pipeline behandelt Databricks-Notebooks wie einfache Python-Dateien, sodass wir sie innerhalb unserer CI/CD-Pipeline ausführen können. Wir haben eine YAML-Datei für unsere Azure CI/CD-Pipeline in azure-pipelines.yml abgelegt. Der interessanteste Teil dieser Datei ist ein Aufruf an die Databricks Repos API, um den Zustand des CI/CD-Projekts auf Databricks zu aktualisieren, und ein Aufruf an die Databricks Jobs API, um die Ausführung des Integrationstest-Jobs auszulösen. Wir haben beide Elemente in einem deploy.py-Skript/Notebook entwickelt. Wir können es in der Azure DevOps-Pipeline wie folgt aufrufen:
DATABRICKS_HOST und DATABRICKS_TOKEN Umgebungsvariablen werden vom databricks_cli-Paket benötigt, um uns gegen den verwendeten Databricks-Workspace zu authentifizieren. Diese Variablen können über Azure DevOps-Variablengruppen verwaltet werden.
Untersuchen wir nun das deploy.py-Skript. Innerhalb des Skripts verwenden wir die databricks_cli API, um mit der Databricks Jobs API zu arbeiten. Zuerst müssen wir einen API-Client erstellen:
Danach können wir ein neues temporäres Repo auf Databricks für unser Projekt erstellen und die neueste Revision aus unserem neu erstellten Repo ziehen:
Als Nächstes können wir die Ausführung des Integrationstest-Jobs auf Databricks starten:
Schließlich warten wir auf den Abschluss des Jobs und untersuchen das Ergebnis:
Arbeiten mit mehreren Workspaces
Die Verwendung der Databricks Repos API für CD kann besonders nützlich für Teams sein, die eine vollständige Isolation zwischen ihren Entwicklungs-/Staging- und Produktionsumgebungen anstreben. Die neue Funktion ermöglicht es Datenteams, über Quellcode auf Databricks, die aktualisierte Codebasis und Artefakte einer Workload über eine einfache Befehlsschnittstelle in mehreren Umgebungen bereitzustellen. Die Möglichkeit, programmatisch die neueste Codebasis im Versionskontrollsystem auszuchecken, gewährleistet einen zeitnahen und einfachen Release-Prozess.
Für MLOps-Praktiken gibt es zahlreiche wichtige Überlegungen zur richtigen Architektur zwischen verschiedenen Umgebungen. In dieser Studie konzentrieren wir uns nur auf das Paradigma der vollständigen Isolation, das auch mehrere MLflow-Instanzen im Zusammenhang mit Entwicklung/Staging/Produktion umfassen würde. In diesem Sinne würden die in einer Entwicklungsumgebung trainierten Modelle nicht als serialisierte Objekte in die nächste Stufe verschoben, die über eine einzige gemeinsame Model Registry geladen werden. Das einzige bereitgestellte Artefakt ist die neue Trainingspipeline-Codebasis, die in der STAGING-Umgebung veröffentlicht und ausgeführt wird, was zu einem neuen Modell führt, das mit MLflow trainiert und registriert wird.
Dieses Shared-Nothing-Prinzip, zusammen mit strengem Berechtigungsmanagement in der Produktions-/Staging-Umgebung, aber eher entspannten Zugriffsmustern in der Entwicklung, ermöglicht eine robuste und qualitativ hochwertige Softwareentwicklung. Gleichzeitig bietet es mehr Freiheit in der Entwicklungsumgebung und beschleunigt Innovation und Experimente im Datenteam.
Zusammenfassung
In diesem Blogbeitrag haben wir einen End-to-End-Ansatz für CI/CD-Pipelines auf Databricks mit Notebook-basierten Projekten vorgestellt. Dieser Workflow basiert auf der Funktionalität der Repos API, die es Datenteams nicht nur ermöglicht, ihre Projekte auf praktischere Weise zu strukturieren und versionskontrolliert zu verwalten, sondern auch die Implementierung und Ausführung von CI/CD-Tools erheblich vereinfacht. Wir haben eine Architektur gezeigt, in der alle operativen Umgebungen vollständig isoliert sind, was ein hohes Maß an Sicherheit für produktionsgestützte Workloads gewährleistet.
Die CI/CD-Pipelines werden von einem Framework der Wahl angetrieben und lassen sich nahtlos in die Databricks Unified Analytics Platform integrieren, wodurch die Ausführung des Codes und die Infrastrukturbereitstellung End-to-End ausgelöst werden. Die Repos API vereinfacht nicht nur das Versionsmanagement, die Code-Strukturierung und die Entwicklung im Projektlebenszyklus radikal, sondern auch die kontinuierliche Bereitstellung, indem sie die Bereitstellung von Produktionsartefakten und Code zwischen Umgebungen ermöglicht. Dies ist eine wichtige Verbesserung, die zur Gesamteffizienz und Skalierbarkeit von Databricks beiträgt und die Erfahrung der Softwareentwickler erheblich verbessert.
Der diskutierte Code kann hier gefunden werden.
Referenzen:
- https://www.databricks.com/blog/2021/06/23/need-for-data-centric-ml-platforms.html
- Continuous Delivery for Machine Learning, Martin Fowler, https://martinfowler.com/articles/cd4ml.html,
- Overview of MLOps, https://www.kdnuggets.com/2021/03/overview-mlops.htm Introducing Azure DevOps, https://azure.microsoft.com/en-us/blog/introducing-azure-devops/
- Continuous integration and delivery on Azure Databricks using Azure DevOps, https://docs.microsoft.com/en-us/azure/databricks/dev-tools/ci-cd/ci-cd-azure-devops
- Lending club Kaggle data set https://www.kaggle.com/wordsforthewise/lending-club
- Repos for Git integration https://docs.databricks.com/repos.html
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.