Modellbewertung in MLflow
von Mark Zhang
Viele Data Scientists und ML-Ingenieure verwenden heute MLflow, um ihre Modelle zu verwalten. MLflow ist eine Open-Source-Plattform, die es Benutzern ermöglicht, alle Aspekte des ML-Lebenszyklus zu steuern, einschließlich, aber nicht beschränkt auf Experimente, Reproduzierbarkeit, Bereitstellung und Modellregistrierung. Ein kritischer Schritt bei der Entwicklung von ML-Modellen ist die Bewertung ihrer Leistung auf neuen Datensätzen.
Motivation
Warum bewerten wir Modelle?
Die Modellbewertung ist ein integraler Bestandteil des ML-Lebenszyklus. Sie ermöglicht es Data Scientists, die Leistung ihrer Modelle zu messen, zu interpretieren und zu erklären. Sie beschleunigt den Entwicklungszeitraum für Modelle, indem sie Einblicke gibt, wie und warum Modelle so funktionieren, wie sie funktionieren. Insbesondere mit zunehmender Komplexität von ML-Modellen ist die Fähigkeit, die Leistung von ML-Modellen schnell zu beobachten und zu verstehen, für eine erfolgreiche ML-Entwicklungsreise unerlässlich.
Stand der Modellbewertung in MLflow
Derzeit bewerten viele Benutzer die Leistung ihres MLflow-Modells des python_function (pyfunc) Model Flavor über die API mlflow.evaluate, die die Bewertung von Klassifikations- und Regressionsmodellen unterstützt. Sie berechnet und protokolliert eine Reihe von integrierten aufgabenspezifischen Leistungskennzahlen, Modellleistungskurven und Modellerklärungen auf dem MLflow Tracking-Server.
Um MLflow-Modelle anhand benutzerdefinierter Metriken zu bewerten, die nicht in der integrierten Metrikmenge enthalten sind, müssten Benutzer ein benutzerdefiniertes Model-Evaluator-Plugin definieren. Dies würde die Erstellung einer benutzerdefinierten Evaluator-Klasse beinhalten, die die ModelEvaluator-Schnittstelle implementiert, und dann einen Evaluator-Einstiegspunkt als Teil eines MLflow-Plugins registriert. Diese Starrheit und Komplexität könnte für Benutzer abschreckend sein.
Laut einer internen Kundenumfrage geben 75 % der Befragten an, dass sie neben grundlegenden Metriken wie Genauigkeit und Verlust häufig oder immer spezialisierte, geschäftsorientierte Metriken verwenden. Data Scientists nutzen diese benutzerdefinierten Metriken oft, da sie geschäftliche Ziele besser beschreiben (z. B. Konversionsrate) und zusätzliche Heuristiken enthalten, die von der Modellvorhersage selbst nicht erfasst werden.
In diesem Blog stellen wir eine einfache und bequeme Möglichkeit vor, MLflow-Modelle anhand benutzerdefinierter Metriken zu bewerten. Mit dieser Funktionalität kann ein Data Scientist diese Logik einfach in die Modellbewertungsphase integrieren und schnell das leistungsstärkste Modell ohne weitere nachgelagerte Analysen ermitteln.
*Hinweis: In MLflow 2.4 wird mlflow.evaluate erweitert, um LLM-Text-, Textzusammenfassungs- und Frage-Antwort-Modelle zu unterstützen
Nutzung
Integrierte Metriken
MLflow integriert eine Reihe von gängigen Leistungs- und Modell-Erklärbarkeitsmetriken für Klassifikations- und Regressionsmodelle. Die Bewertung von Modellen anhand dieser Metriken ist unkompliziert. Alles, was wir brauchen, ist die Erstellung eines Bewertungsdatensatzes, der die Testdaten und Ziele enthält, und ein Aufruf von mlflow.evaluate.
Abhängig vom Modelltyp werden unterschiedliche Metriken berechnet. Informationen zu den integrierten Metriken finden Sie im Abschnitt Verhalten des Standard-Evaluators in der API-Dokumentation von mlflow.evaluate für die aktuellsten Informationen.
Beispiel
Unten sehen Sie ein einfaches Beispiel, wie ein Klassifikations-MLflow-Modell mit integrierten Metriken bewertet wird.
Importieren Sie zuerst die notwendigen Bibliotheken
Teilen Sie dann den Datensatz auf, passen Sie das Modell an und erstellen Sie unseren Bewertungsdatensatz
Starten Sie schließlich einen MLflow-Lauf und rufen Sie mlflow.evaluate auf
Die protokollierten Metriken und Artefakte finden wir in der MLflow-UI:
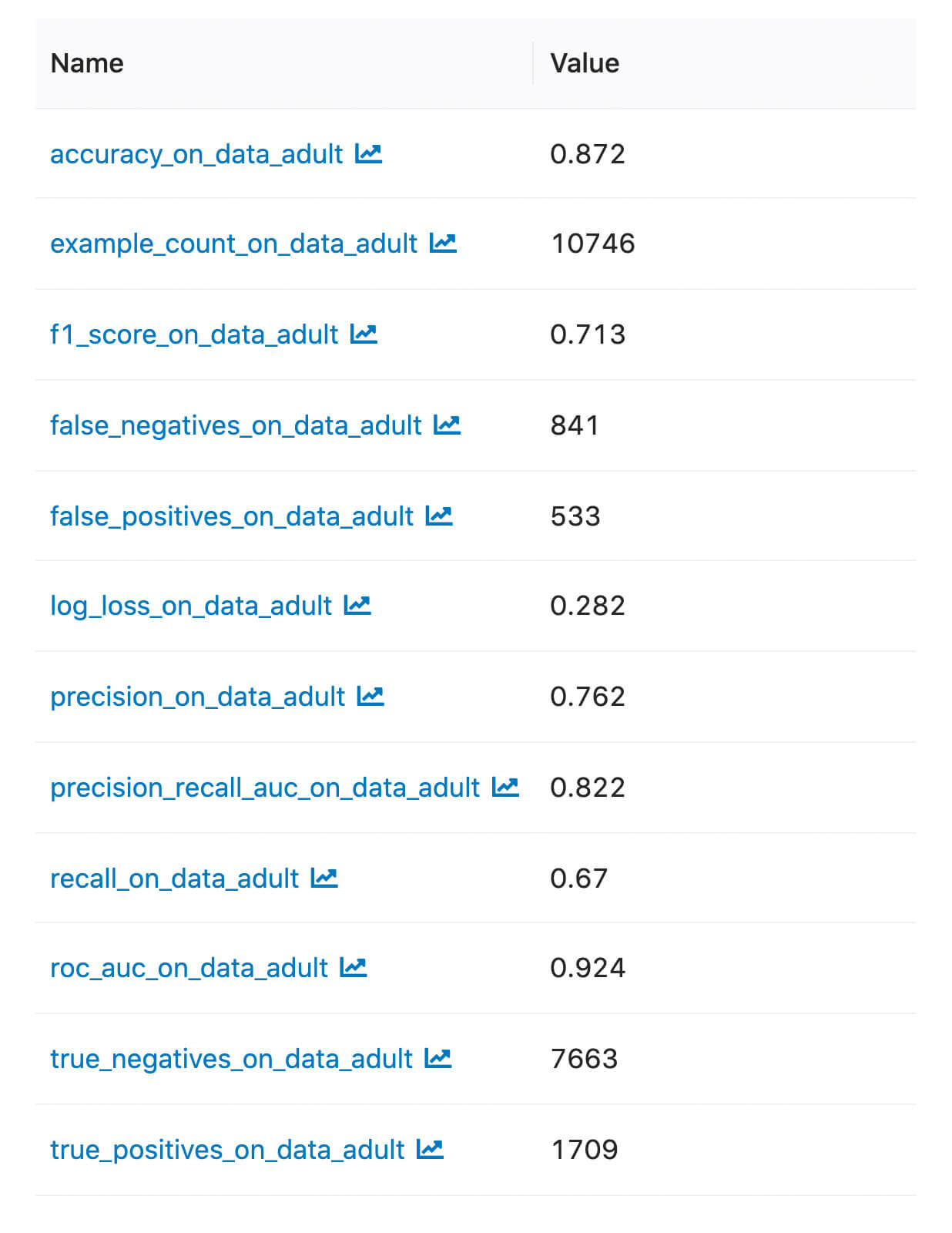
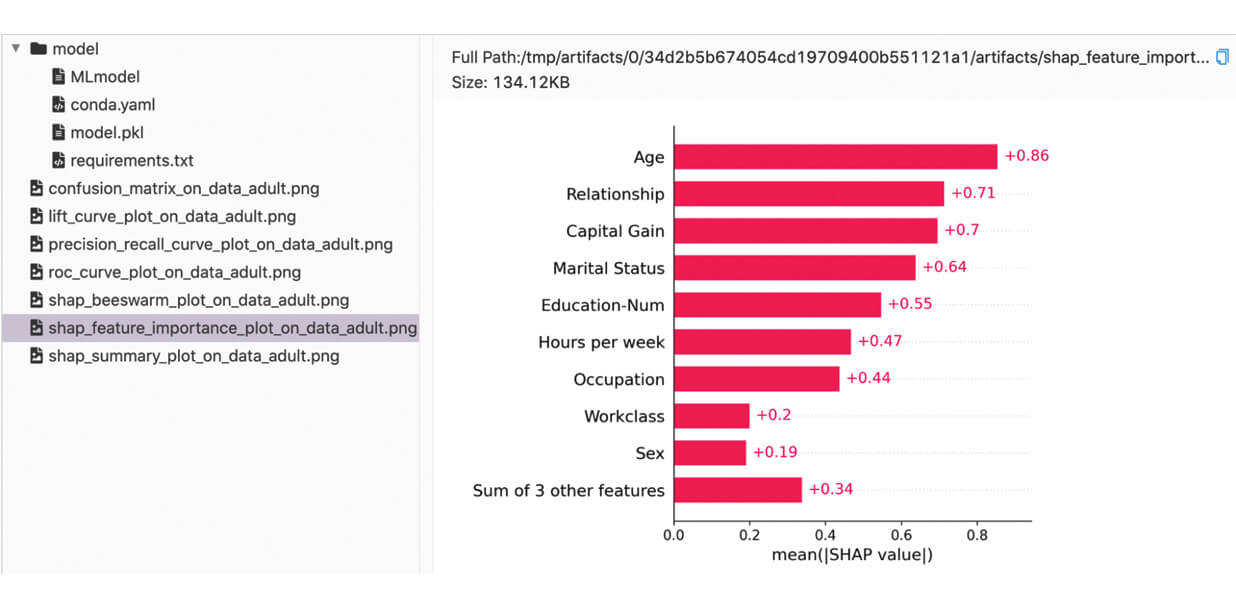
Benutzerdefinierte Metriken
Um ein Modell anhand benutzerdefinierter Metriken zu bewerten, übergeben wir einfach eine Liste von benutzerdefinierten Metrikfunktionen an die API mlflow.evaluate.
Anforderungen an die Funktionsdefinition
Benutzerdefinierte Metrikfunktionen sollten zwei erforderliche Parameter und einen optionalen Parameter in der folgenden Reihenfolge akzeptieren:
eval_df: ein Pandas- oder Spark-DataFrame, das eineprediction- und einetarget-Spalte enthält.Z. B. Wenn die Ausgabe des Modells ein Vektor aus drei Zahlen ist, würde der
eval_df-DataFrame etwa so aussehen: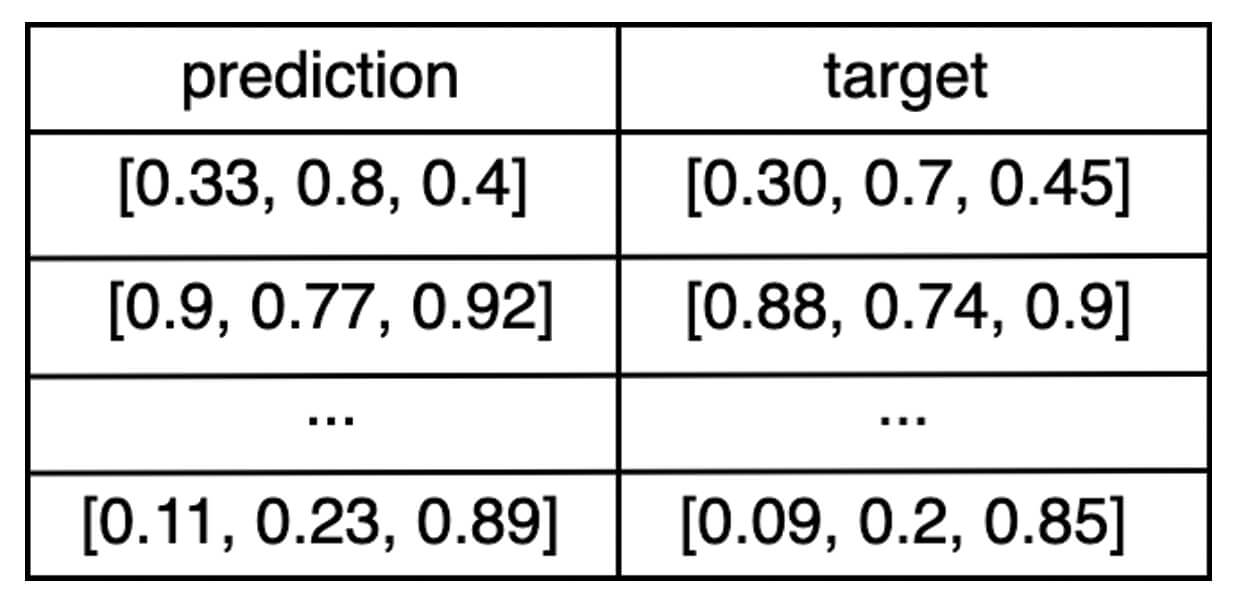
builtin_metrics: ein Wörterbuch, das die integrierten Metriken enthältZ. B. Für ein Regressionsmodell würde
builtin_metricsetwa so aussehen:- (Optional)
artifacts_dir: Pfad zu einem temporären Verzeichnis, das von der benutzerdefinierten Metrikfunktion verwendet werden kann, um produzierte Artefakte vor dem Protokollieren in MLflow vorübergehend zu speichern.Z. B. Beachten Sie, dass dies je nach spezifischer Umgebungseinstellung unterschiedlich aussehen wird. Auf MacOS könnte es beispielsweise so aussehen:
Wenn Dateiartefakte an einem anderen Ort als
artifacts_dirgespeichert werden, stellen Sie sicher, dass sie bis nach der vollständigen Ausführung vonmlflow.evaluatebestehen bleiben.
Anforderungen an den Rückgabewert
Die Funktion sollte ein Wörterbuch zurückgeben, das die produzierten Metriken darstellt, und kann optional ein zweites Wörterbuch zurückgeben, das die produzierten Artefakte darstellt. Für beide Wörterbücher stellt der Schlüssel für jeden Eintrag den Namen der entsprechenden Metrik oder des entsprechenden Artefakts dar.
Während jede Metrik ein Skalar sein muss, gibt es verschiedene Möglichkeiten, Artefakte zu definieren:
- Der Pfad zu einer Artefaktdatei
- Die Zeichenkettendarstellung eines JSON-Objekts
- Ein Pandas DataFrame
- Ein Numpy-Array
- Eine Matplotlib-Figur
- Andere Objekte werden versucht, mit dem Standardprotokoll gepickelt zu werden
Weitere Details zur Definition finden Sie in der Dokumentation von mlflow.evaluate.
Beispiel
Sehen wir uns ein konkretes Beispiel mit benutzerdefinierten Metriken an. Dazu erstellen wir ein Spielzeugmodell aus dem California Housing-Datensatz.
Richten Sie dann unseren Datensatz und unser Modell ein
Hier kommt der spannende Teil: Definieren unserer benutzerdefinierten Metrikfunktion und eines benutzerdefinierten Artefakts!!
Schließlich, um all dies zu verbinden, starten wir einen MLflow-Lauf und rufen mlflow.evaluate auf:
Protokollierte benutzerdefinierte Metriken und Artefakte finden Sie neben den Standardmetriken und -artefakten. Die rot umrandeten Bereiche zeigen die protokollierten benutzerdefinierten Metriken und Artefakte auf der Laufseite.
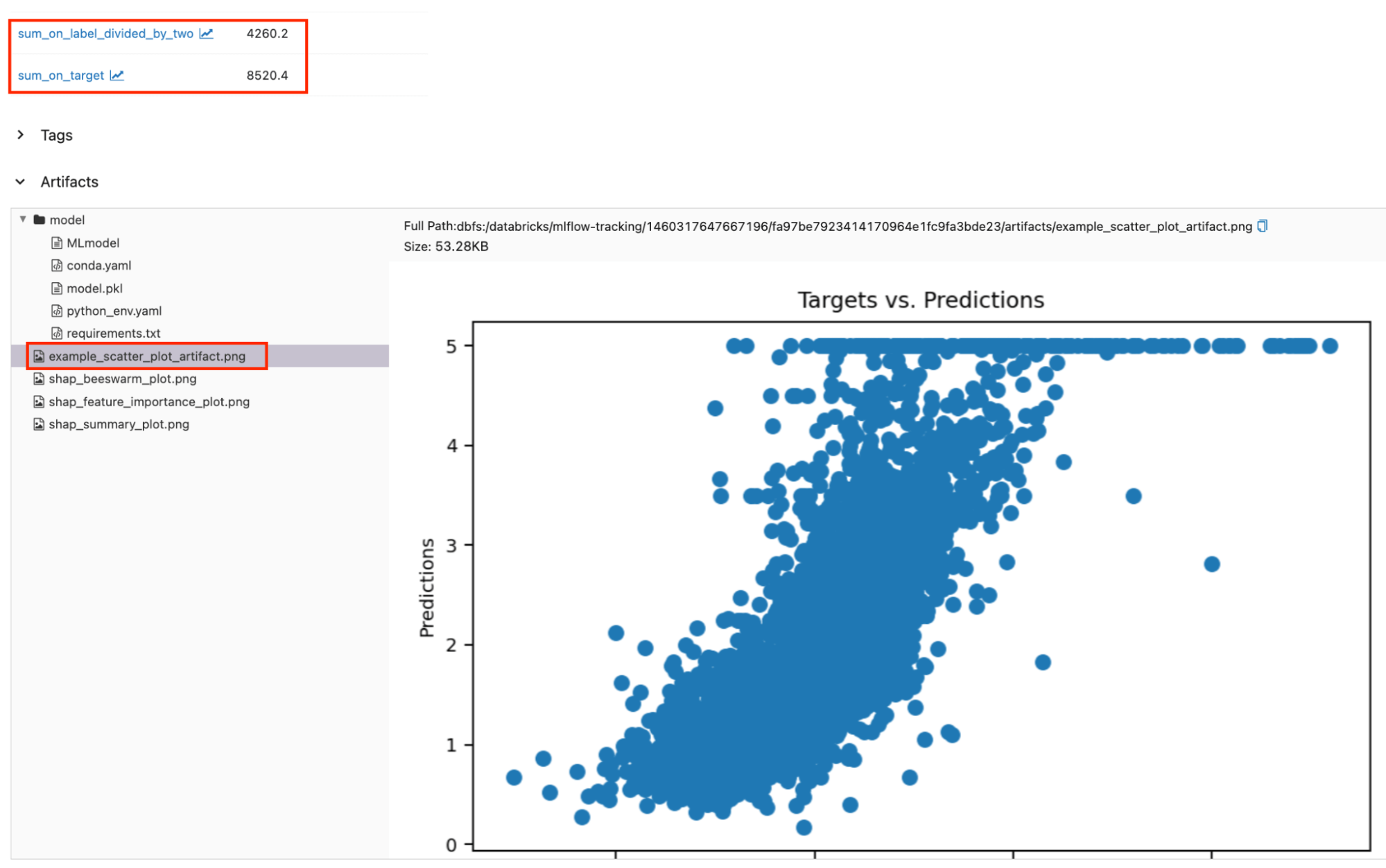
Zugriff auf Auswertungsergebnisse per Programm
Bisher haben wir die Auswertungsergebnisse für integrierte und benutzerdefinierte Metriken in der MLflow-Benutzeroberfläche untersucht. Wir können jedoch auch per Programm über das EvaluationResult-Objekt darauf zugreifen, das von mlflow.evaluate zurückgegeben wird. Fahren wir mit unserem obigen Beispiel für benutzerdefinierte Metriken fort und sehen wir uns an, wie wir per Programm auf seine Auswertungsergebnisse zugreifen können. (Vorausgesetzt, result ist ab hier unsere EvaluationResult-Instanz).
Wir können auf den Satz berechneter Metriken über das result.metrics-Dictionary zugreifen, das sowohl den Namen als auch die Skalarwerte der Metriken enthält. Der Inhalt von result.metrics sollte etwa so aussehen:
Ebenso ist der Satz von Artefakten über das result.artifacts-Dictionary zugänglich. Die Werte jedes Eintrags sind ein EvaluationArtifact-Objekt. result.artifacts sollte etwa so aussehen:
Beispiel-Notebooks
Unter der Haube
Das folgende Diagramm veranschaulicht, wie dies alles unter der Haube funktioniert:
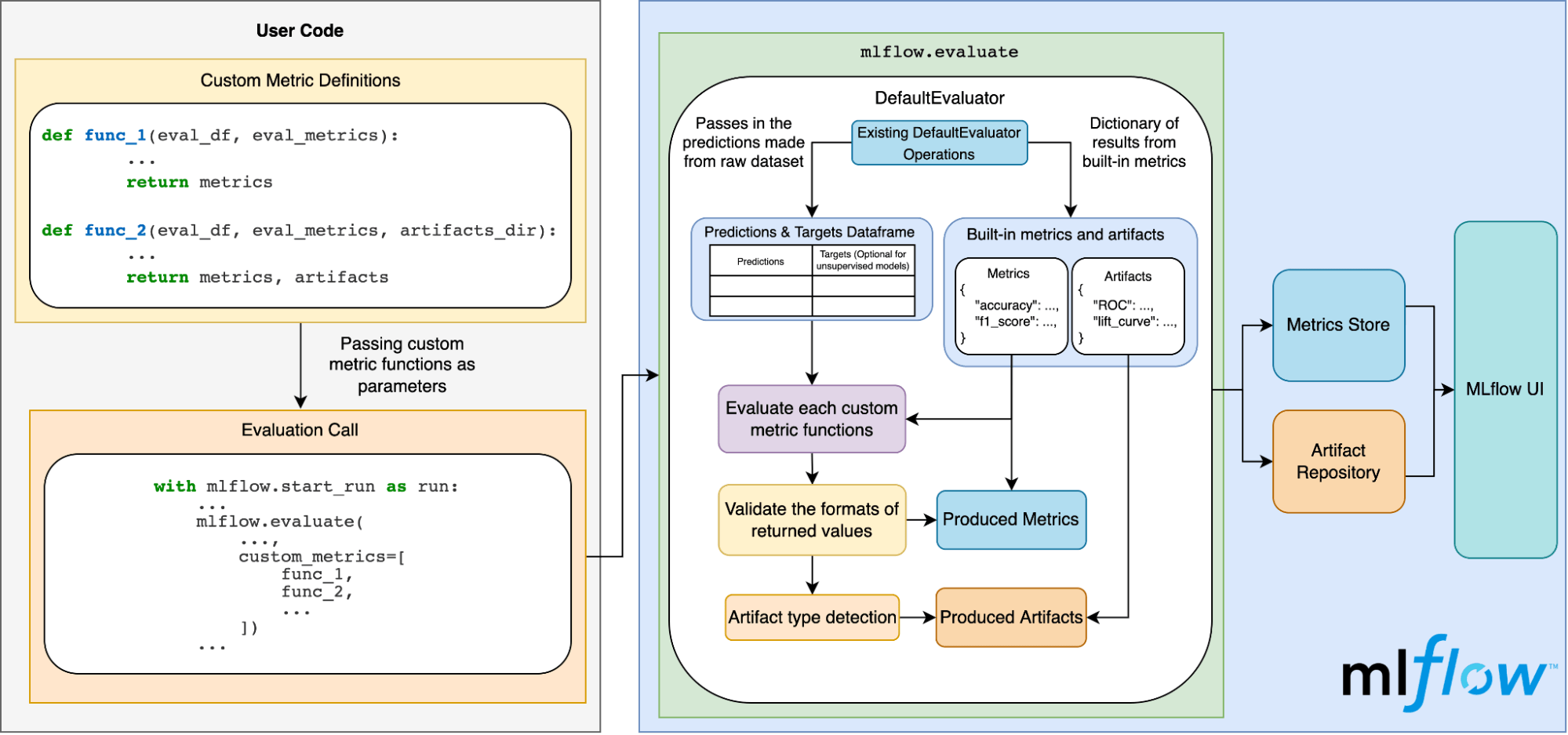
Fazit
In diesem Blogbeitrag haben wir behandelt:
- Die Bedeutung der Modellbewertung und was derzeit in MLflow unterstützt wird.
- Warum es für MLflow-Benutzer wichtig ist, benutzerdefinierte Metriken einfach in ihre MLflow-Modelle integrieren zu können.
- Wie Modelle mit Standardmetriken bewertet werden.
- Wie Modelle mit benutzerdefinierten Metriken bewertet werden.
- Wie MLflow die Modellbewertung im Hintergrund handhabt.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.