Identitätsspalten zur Generierung von Surrogatschlüsseln sind jetzt in einem Lakehouse in Ihrer Nähe verfügbar!
von Franco Patano
Was ist eine Identitätsspalte?
Eine Identitätsspalte ist eine Spalte in einer Datenbank, die automatisch eine eindeutige ID-Nummer für jede neue Datenzeile generiert. Diese Nummer hat keinen Bezug zum Inhalt der Zeile.
Identitätsspalten sind eine Form von Surrogatschlüsseln. In Data Warehouses ist es üblich, einen zusätzlichen Schlüssel, den sogenannten Surrogatschlüssel, zu verwenden, um jede Zeile eindeutig zu identifizieren und Änderungen an den Daten im Laufe der Zeit zu verfolgen. Darüber hinaus wird empfohlen, Surrogatschlüssel gegenüber natürlichen Schlüsseln zu verwenden. Surrogatschlüssel werden vom System generiert und sind nicht auf mehrere Felder angewiesen, um die Einzigartigkeit der Zeile zu identifizieren.
Identitätsspalten werden also zur Erstellung von Surrogatschlüsseln verwendet, die als Primär- und Fremdschlüssel in dimensionalen Modellen für Data Warehouses und Datamarts dienen können. Wie unten gezeigt, sind dies die Spalten, die verschiedene Tabellen in einem traditionellen dimensionalen Modell wie einem Sternschema miteinander verbinden.
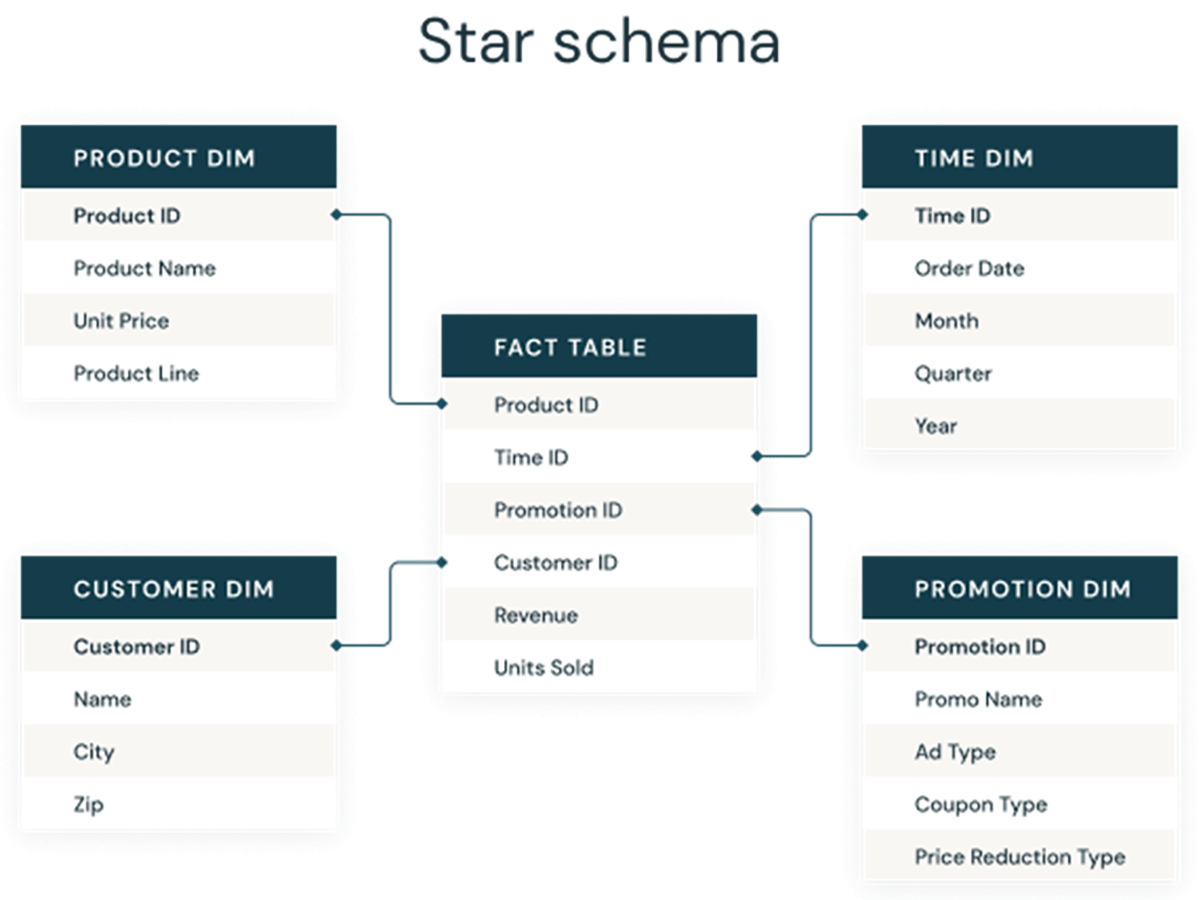
Traditionelle Ansätze zur Generierung von Surrogatschlüsseln auf Data Lakes
Die meisten Big-Data-Technologien nutzen Parallelität, d. h. die Fähigkeit, eine Aufgabe in kleinere Teile zu zerlegen, die gleichzeitig ausgeführt werden können, um die Leistung zu verbessern. In den frühen Tagen von Data Lakes gab es keine einfache Möglichkeit, eindeutige Sequenzen über eine Gruppe von Maschinen hinweg zu erstellen. Dies führte dazu, dass einige Dateningenieure weniger zuverlässige Methoden zur Generierung von Surrogatschlüsseln ohne eine entsprechende Funktion verwendeten, wie zum Beispiel:
monotonically_increasing_id(),row_number(),Rank OVER,ZipWithIndex(),ZipWithUniqueIndex(),- Zeilen-Hash mit
hash(),und - Zeilen-Hash mit
md5().
Während diese Funktionen unter bestimmten Umständen die Aufgabe erfüllen können, sind sie oft mit vielen Warnungen und Vorbehalten verbunden, was die spärliche Besetzung der Sequenzen, Leistungsprobleme bei Skalierung und Probleme mit gleichzeitigen Transaktionen betrifft.
Datenbanken können seit den Anfängen Sequenzen generieren, um Surrogatschlüssel zu erzeugen und eine Datenzeile mit Hilfe eines zentralisierten Transaktionsmanagers eindeutig zu identifizieren. Typische Implementierungen erfordern jedoch Sperren und Transaktions-Commits, was schwierig zu verwalten sein kann.
Identitätsspalten auf Delta Lake vereinfachen die Generierung von Surrogatschlüsseln
Identitätsspalten lösen die oben genannten Probleme und bieten eine einfache, performante Lösung zur Generierung von Surrogatschlüsseln. Delta Lake ist das erste Data-Lake-Protokoll, das Identitätsspalten für die Generierung von Surrogatschlüsseln ermöglicht.
Delta Lake unterstützt jetzt die Erstellung von IDENTITY-Spalten, die automatisch eindeutige, inkrementelle ID-Nummern generieren können, wenn neue Zeilen geladen werden. Obwohl diese ID-Nummern möglicherweise nicht fortlaufend sind, unternimmt Delta sein Bestes, um die Lücke so klein wie möglich zu halten. Sie können diese Funktion verwenden, um auf einfache Weise Surrogatschlüssel für Ihre Data-Warehousing-Workloads zu erstellen.
So erstellen Sie einen Surrogatschlüssel mit einer Identitätsspalte mithilfe von SQL und Delta Lake
[Empfohlen] Immer als Identität generieren
Das Erstellen einer Identitätsspalte in SQL ist so einfach wie das Erstellen einer Delta Lake-Tabelle. Deklarieren Sie beim Deklarieren Ihrer Spalten eine Spalte namens id oder wie auch immer Sie möchten, mit dem Datentyp BIGINT und geben Sie dann GENERATED ALWAYS AS IDENTITY ein.
Jedes Mal, wenn Sie eine Operation auf dieser Tabelle ausführen, bei der Sie Daten einfügen, lassen Sie diese Spalte beim Einfügen weg, und Delta Lake generiert automatisch einen eindeutigen Wert für die IDENTITY-Spalte für jede Zeile, die in die Delta Lake-Tabelle eingefügt wird.
Hier ist ein einfaches Beispiel für die Verwendung von Identitätsspalten in Delta Lake:
Zukünftig wird die Identitätsspalte mit dem Titel "id" automatisch hochgezählt, wenn Sie neue Datensätze in die Tabelle einfügen. Sie können dann neue Daten wie folgt einfügen:
Beachten Sie, wie die Surrogatschlüsselspalte mit dem Titel "id" im INSERT-Teil der Anweisung fehlt. Delta Lake wird die Surrogatschlüssel beim Schreiben der Tabelle in den Cloud-Objektspeicher (z. B. AWS S3, Azure Data Lake Storage oder Google Cloud Storage) ausfüllen. Erfahren Sie mehr in der Dokumentation.
Standardmäßig generieren
Es gibt auch die Option GENERATED BY DEFAULT AS IDENTITY, die das Einfügen von Identitäten überschreiben lässt, während die Option ALWAYS nicht überschrieben werden kann.
Es gibt ein paar Vorbehalte, die Sie bei der Übernahme dieser neuen Funktion beachten sollten. Identitätsspalten können nicht zu vorhandenen Tabellen hinzugefügt werden; die Tabellen müssen mit der hinzugefügten neuen Identitätsspalte neu erstellt werden. Erstellen Sie dazu einfach eine neue Tabellen-DDL mit der Identitätsspalte und fügen Sie die vorhandenen Spalten in die neue Tabelle ein, und Surrogatschlüssel werden für die neue Tabelle generiert.
Starten Sie noch heute mit Identitätsspalten mit Delta Lake auf Databricks SQL
Identitätsspalten sind jetzt GA (Generally Available) in Databricks Runtime 10.4+ und in Databricks SQL 2022.17+. Mit Identitätsspalten können Sie jetzt alle Ihre Data-Warehousing-Workloads mit allen Vorteilen einer Lakehouse-Architektur aktivieren, beschleunigt durch Photon. Probieren Sie Identitätsspalten auf Databricks SQL noch heute aus.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.